

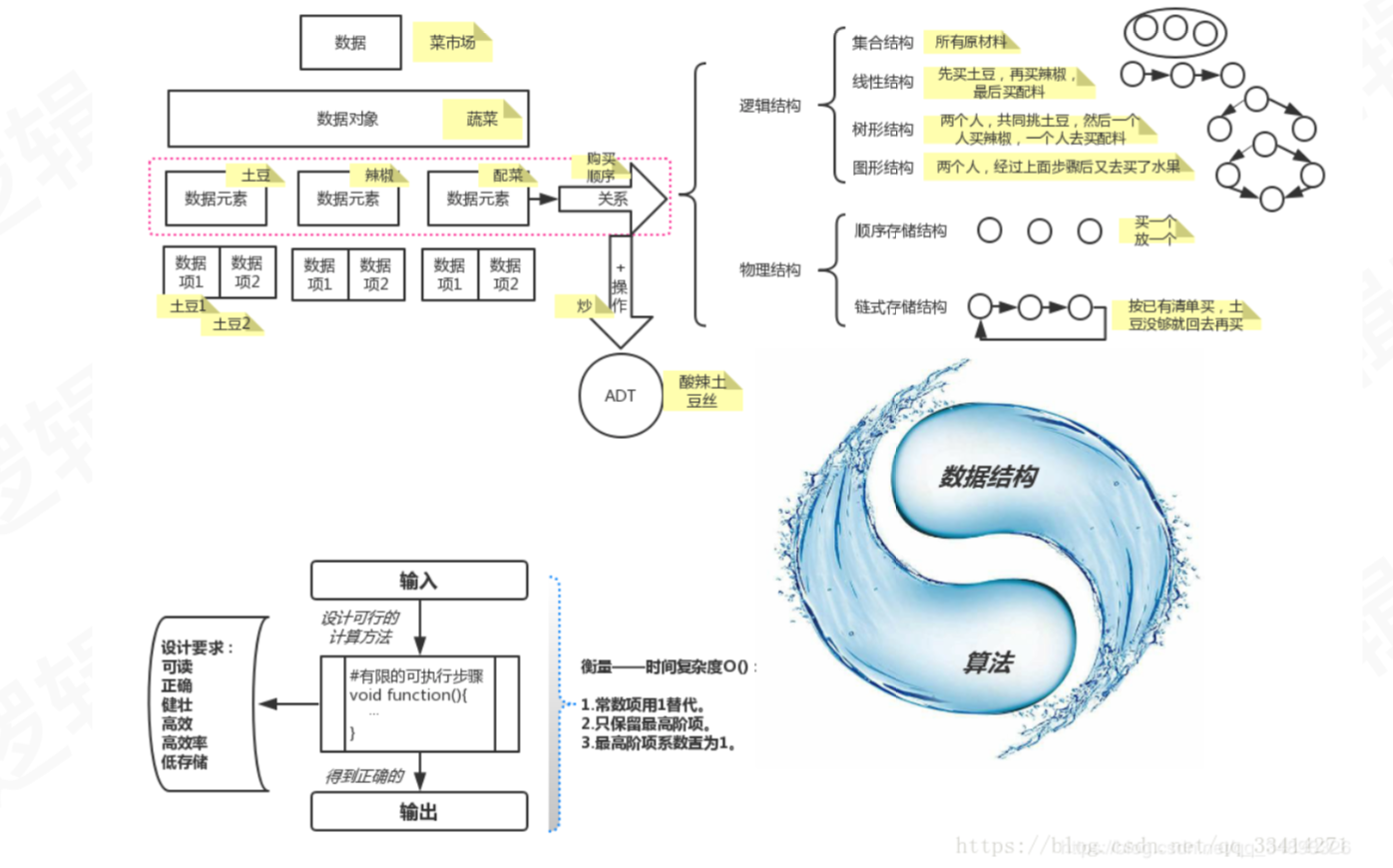
一、基本数据单位
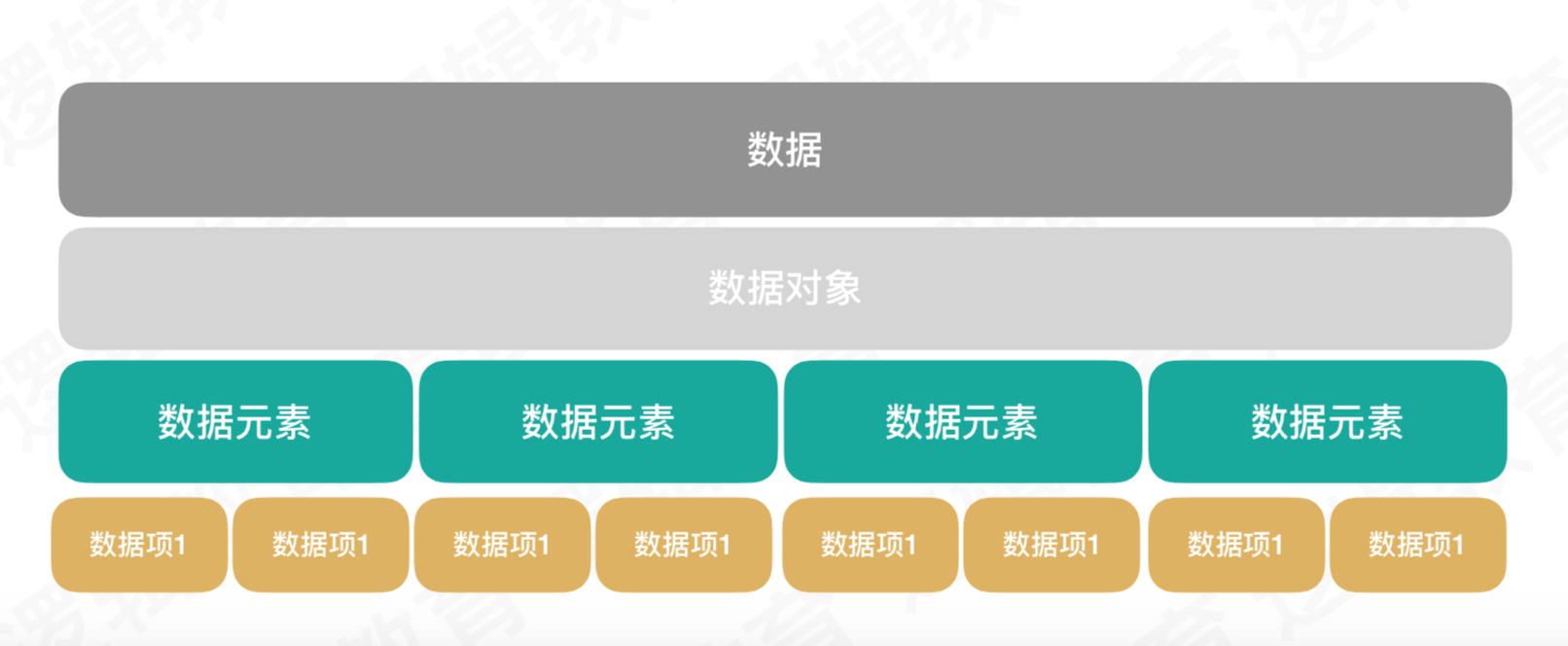
数据:程序的操作对象,用于描述客观事物
数据的特点:
- 1、可以输入到计算机
- 2、可以被计算机处理
数据对象:性质相同的数据元素的集合(类似数组)
数据元素:组成数据对象的基本单位
数据项:一个数据元素由若干数据项组成
可以根据下图来说明数据的组成:
二、数据结构
1、定义
数据元素之间不是独立的,存在特定的关系,这些关系就是结构
而数据结构值得是数据对象中的数据元素之间的关系
举个例子:
//声明一个结构体类型
struct Teacher{ //一种数据结构
char *name; //数据项--名字
char *title; //数据项--职称
int age; //数据项--年龄
};
int main(int argc, const char * argv[]) {
struct Teacher t1; //数据元素;
struct Teacher tArray[10]; //数据对象;
t1.age = 18; //数据项
t1.name = "CC"; //数据项
t1.title = "讲师"; //数据项
printf("老师姓名:%s\n",t1.name);
printf("老师年龄:%d\n",t1.age);
printf("老师职称:%s\n",t1.title);
return 0;
}
2、逻辑结构
a、集合结构
类似于字典、NSSet,无序的,如图

b、线性结构
有序的集合,例如数组、栈、队列等,如图

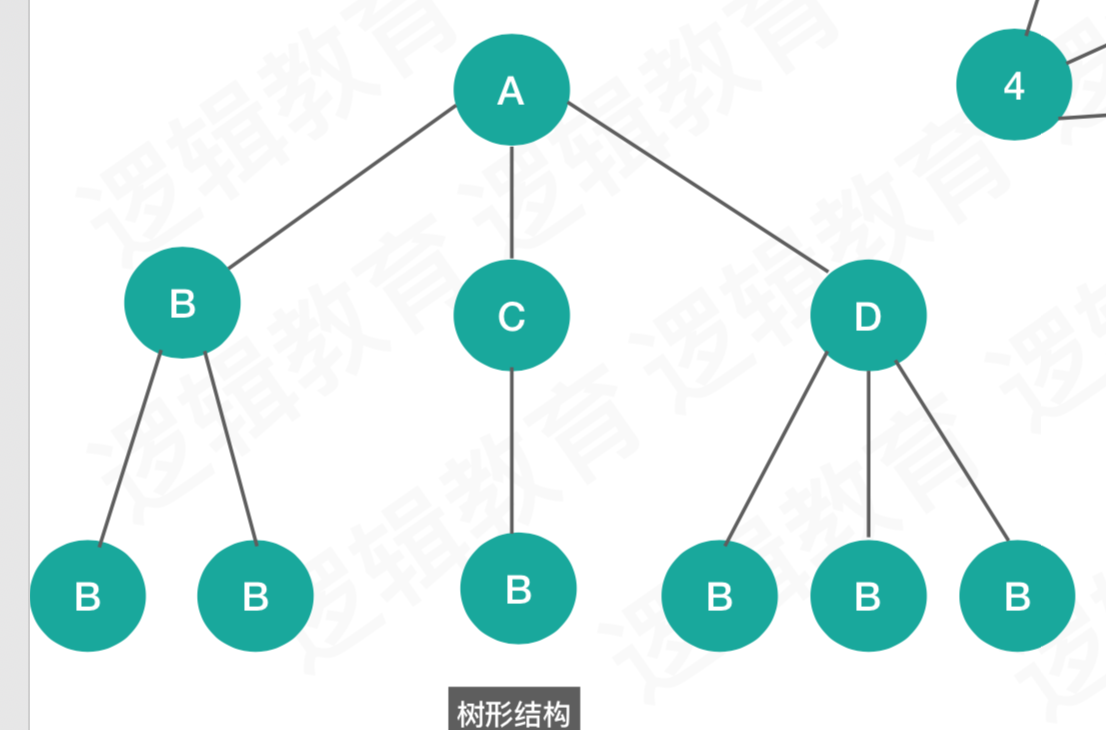
c、数组结构
一对多的,例如二叉树,红黑树,如图
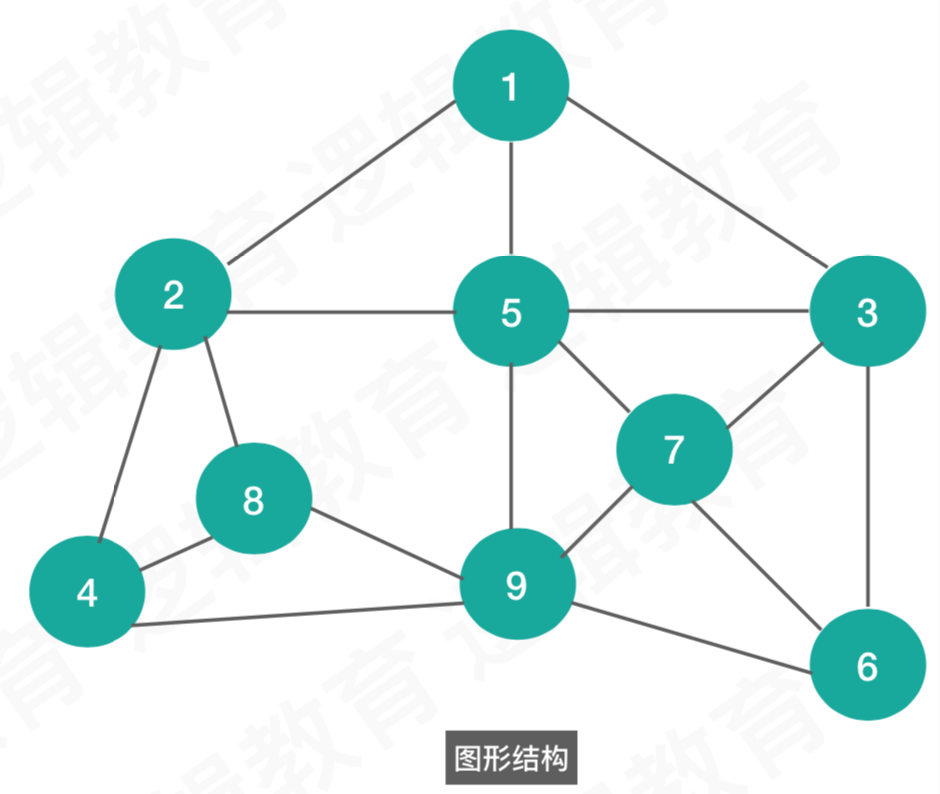
d、图形结构
多对多的结构,如图
3、物理结构
物理结构就是按照存储在内存中的状态形成的结构
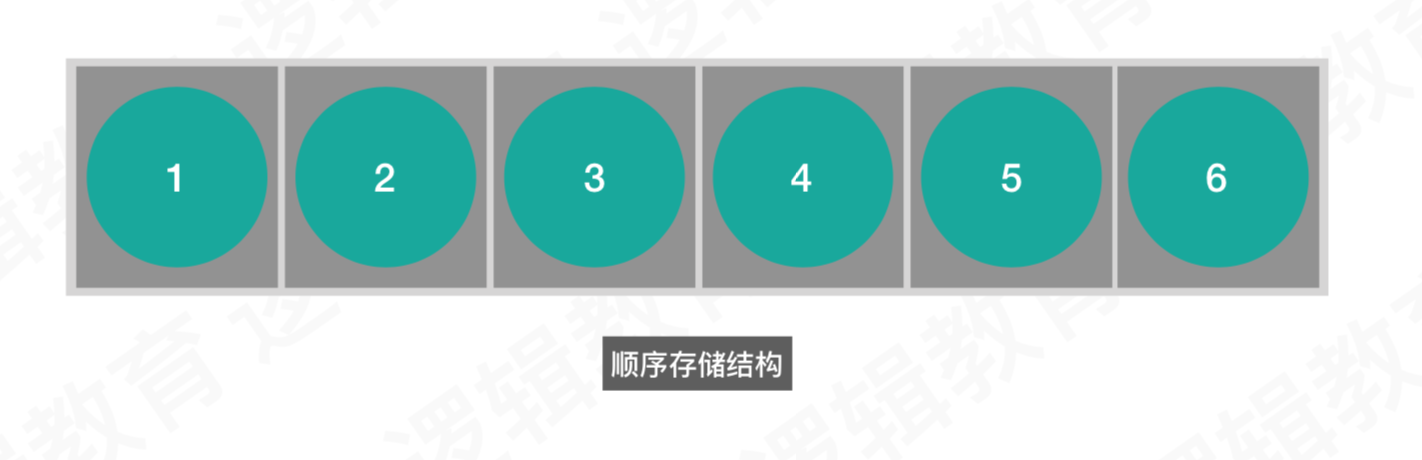
a、顺序存储结构
存储在一片连续的内存中,并且是按照顺序依次存储的,需要提前开辟连续的内存空间,存储起来麻烦,查找起来简单,如图
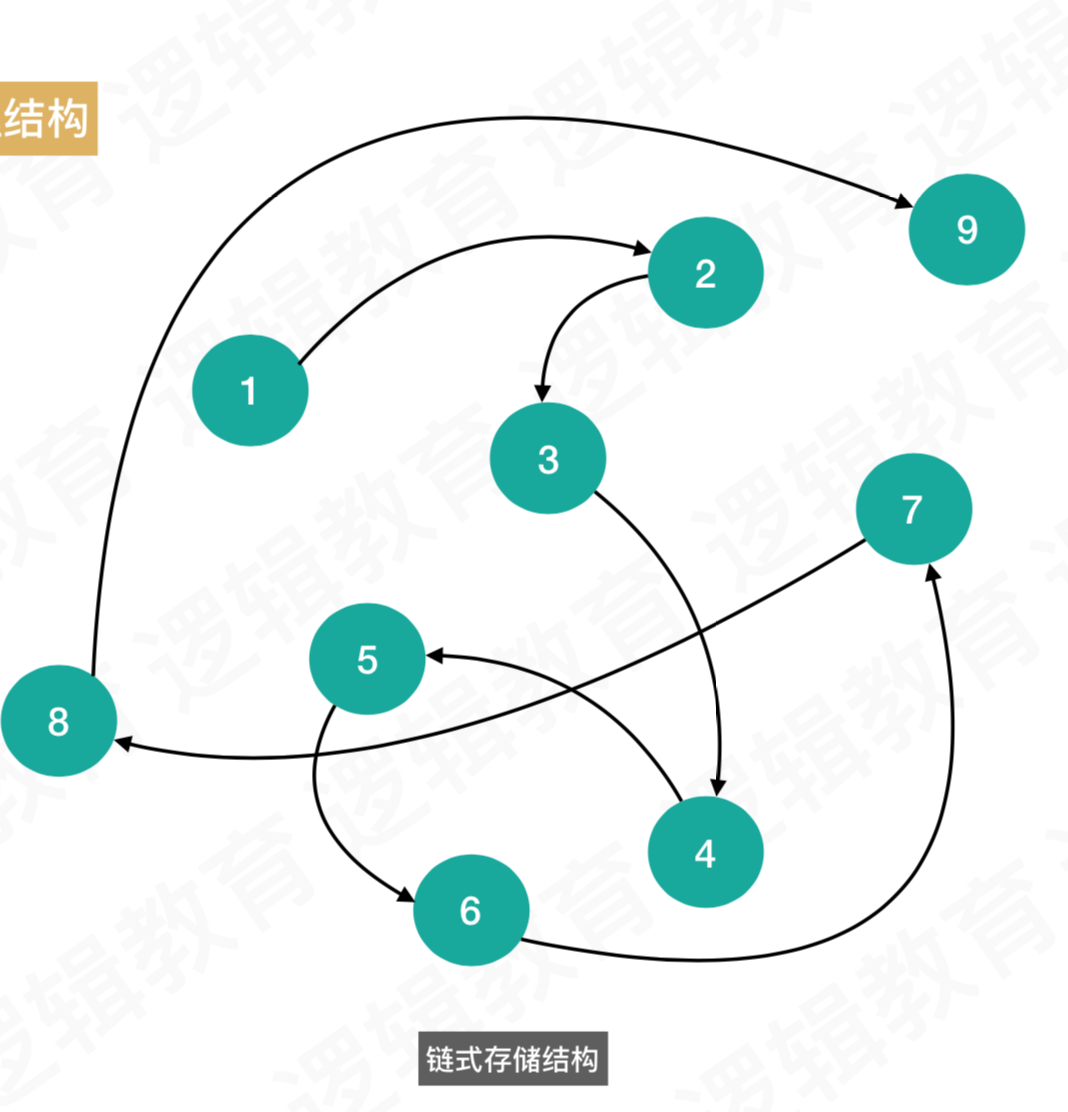
b、链式存储结构
存在不连续的内存中,通过指针进行查找的,不需要提前开辟,存储起来简单,查询时候麻烦,如图
三、数据结构和算法
不可分割的,算法是解决数据存储的方法,数据结构和算法的关系用一个图概括一下
1、算法
算法是解决特定问题求解步骤的描述,在计算机汇总表现为指令的有限序列,并且每个指令表示一个或多个操作
a、算法的特性
- 输入输出:输入代表初始条件,输出代表结果
- 有穷性:执行次数与执行时间有限
- 确定性:每一步的执行都是唯一的
- 可行性:每个操作切实可行
b、算法设计要求
- 正确性:执行结果正确
- 可读性:阅读的传播难易程度
- 健壮性:异常情况处理
- 时间效率高和存储量低:执行算法需要消耗的时间少和占用空间资源少
c、时间复杂度
大O表示法的规则:
-
- 用常数1取代运行时间中所有常数 3->1 O(1)
-
- 在修改运行次数函数中,只保留最高阶项 n^3+2n^2+5 -> O(n^3)
-
- 如果在最高阶存在且不等于1,则去除这个项目相乘的常数 2n^3 -> n^3
时间复杂度术语和例子:

其中指数阶(不考虑) O(2^n)或者O(n!) 除非是非常小的n,否则会造成噩梦般的时间消耗. 这是一种不切实际的算法时间复杂度. 一般不考虑!
因为时间复杂度不是让精确到每分每秒,只是为了通过大O表示法表示出来
我们各种复杂度举个例子
1、常数阶:
//1+1+1 = 3 O(1)
void testSum1(int n){
int sum = 0; //执行1次
sum = (1+n)*n/2; //执行1次
printf("testSum1:%d\n",sum);//执行1次
}
//1+1+1+1+1+1+1 = 7 O(1)
void testSum2(int n){
int sum = 0; //执行1次
sum = (1+n)*n/2; //执行1次
sum = (1+n)*n/2; //执行1次
sum = (1+n)*n/2; //执行1次
sum = (1+n)*n/2; //执行1次
sum = (1+n)*n/2; //执行1次
printf("testSum2:%d\n",sum);//执行1次
}
因为上面函数不管传进来的n是多少,程序执行的代码行数都是固定的,所以是时间复杂度是常数阶,O(1)
2、线性阶:
//x=x+1; 执行n次 O(n)
void add2(int x,int n){
for (int i = 0; i < n; i++) {
x = x+1;
}
}
//1+(n+1)+n+1 = 3+2n -> O(n)
void testSum3(int n){
int i,sum = 0; //执行1次
for (i = 1; i <= n; i++) { //执行n+1次
sum += i; //执行n次
}
printf("testSum3:%d\n",sum); //执行1次
}
上面函数程序执行的次数是根据传进来的n的数组大小来决定的,所以时间复杂度是线性阶,O(n)
3、对数阶:
/*2的x次方等于n x = log2n ->O(logn)*/
void testA(int n){
int count = 1; //执行1次
//n = 10
while (count < n) {
count = count * 2;
}
}
上面函数程序执行的次数是根据log2n,根据大O表示法所有的常量都改为1,所以时间复杂度是线性阶,O(logn)
4、平方阶:
//x=x+1; 执行n*n次 ->O(n^2)
void add3(int x,int n){
for (int i = 0; i< n; i++) {
for (int j = 0; j < n ; j++) {
x=x+1;
}
}
}
//n+(n-1)+(n-2)+...+1 = n(n-1)/2 = n^2/2 + n/2 = O(n^2)
//sn = n(a1+an)/2
void testSum4(int n){
int sum = 0;
for(int i = 0; i < n;i++)
for (int j = i; j < n; j++) {
sum += j;
}
printf("textSum4:%d",sum);
}
//1+(n+1)+n(n+1)+n^2+n^2 = 2+3n^2+2n -> O(n^2)
void testSum5(int n){
int i,j,x=0,sum = 0; //执行1次
for (i = 1; i <= n; i++) { //执行n+1次
for (j = 1; j <= n; j++) { //执行n(n+1)
x++; //执行n*n次
sum = sum + x; //执行n*n次
}
}
printf("testSum5:%d\n",sum);
}
上面程序循环次数里面都有一个常量*n^2,依据大O表示法,只保留最高阶,并且常数全用1取代,所以上面函数的时间复杂度是O(n^2)
5、立方阶:
void testB(int n){
int sum = 1; //执行1次
for (int i = 0; i < n; i++) { //执行n次
for (int j = 0 ; j < n; j++) { //执行n*n次
for (int k = 0; k < n; k++) {//执行n*n*n次
sum = sum * 2; //执行n*n*n次
}
}
}
}
上面函数执行次数是n^3,所以时间复杂度是立方阶,O(n^3)
由于指数阶和nlogn阶用的很少,所以就不举例
d、空间复杂度
算法的空间复杂度通过计算算法所需要的存储空间实现,算法空间复杂度的计算公式记做:S(n)= n(f(n)),其中n为问题的规模,f(n)为语句关于n所占存储空间的函数
程序空间计算因素:
- 寄存本身的指令
- 常数
- 变量
- 输入
- 对数据进行操作的辅助空间
在考量算法的空间复杂度上,主要考虑算法执行时所需要的辅助空间
问题: 数组逆序,将一维数组a中的n个数逆序存放在原数组中.
算法1:
int n = 5;
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int temp;
for(int i = 0; i < n/2 ; i++){
temp = a[i];
a[i] = a[n-i-1];
a[n-i-1] = temp;
}
因为上面用到的辅助空间只有一个,所以空间复杂度是O(1)
e、最好情况和最坏情况
因为通过大O表示法,我们展现的是最坏的情况,但是有时候不同算法虽然复杂度一样,但也是有好坏之分,这个就需要通过算法的平均值来比较两个算法的优劣
时间换空间,空间换时间--这句话是错的
算法2:
//算法实现(2)
int b[10] = {0};
for(int i = 0; i < n;i++){
b[i] = a[n-i-1];
}
for(int i = 0; i < n; i++){
a[i] = b[i];
}
因为上面用到的辅助空间跟元素个数相关,所以空间复杂度是O(n)
四、线性表
对应非空的线性表和线性结构,其特点如下:
- 存在唯一的一个被称作“第一个”的数据元素
- 存在唯一的一个被称作“最后一个”的数据元素
- 除了第一个之外,结构中的每个数据元素都有一个前驱
- 除了最后一个之外,结构中每个数据元素都有一个后继
1、线性顺序表
我们来自己创建一个线性结构顺序表:
#define MAXSIZE 100
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
/* ElemType类型根据实际情况而定,这里假设为int */
typedef int ElemType;
/* Status是函数的类型,其值是函数结果状态代码,如OK等 */
typedef int Status;
/*线性结构使用顺序表的方式存储*/
//顺序表结构设计
typedef struct {
ElemType *data;
int length;
}Sqlist;
//1.1 顺序表初始化
Status InitList(Sqlist *L){
//为顺序表分配一个大小为MAXSIZE 的数组空间
L->data = malloc(sizeof(ElemType) * MAXSIZE);
//存储分配失败退出
if(!L->data) exit(ERROR);
//空表长度为0
L->length = 0;
return OK;
}
//1.2 顺序表的插入
/*
初始条件:顺序线性表L已存在,1≤i≤ListLength(L);
操作结果:在L中第i个位置之前插入新的数据元素e,L的长度加1
*/
Status ListInsert(Sqlist *L,int i,ElemType e){
//i值不合法判断
if((i<1) || (i>L->length+1)) return ERROR;
//存储空间已满
if(L->length == MAXSIZE) return ERROR;
//插入数据不在表尾,则先移动出空余位置
if(i <= L->length){
for(int j = L->length-1; j>=i-1;j--){
//插入位置以及之后的位置后移动1位
L->data[j+1] = L->data[j];
}
}
//将新元素e 放入第i个位置上
L->data[i-1] = e;
//长度+1;
++L->length;
return OK;
}
//1.3 顺序表的取值
Status GetElem(Sqlist L,int i, ElemType *e){
//判断i值是否合理, 若不合理,返回ERROR
if(i<1 || i > L.length) return ERROR;
//data[i-1]单元存储第i个数据元素.
*e = L.data[i-1];
return OK;
}
//1.4 顺序表删除
/*
初始条件:顺序线性表L已存在,1≤i≤ListLength(L)
操作结果: 删除L的第i个数据元素,L的长度减1
*/
Status ListDelete(Sqlist *L,int i){
//线性表为空
if(L->length == 0) return ERROR;
//i值不合法判断
if((i<1) || (i>L->length+1)) return ERROR;
for(int j = i; j < L->length;j++){
//被删除元素之后的元素向前移动
L->data[j-1] = L->data[j];
}
//表长度-1;
L->length --;
return OK;
}
//1.5 清空顺序表
/* 初始条件:顺序线性表L已存在。操作结果:将L重置为空表 */
Status ClearList(Sqlist *L)
{
L->length=0;
return OK;
}
//1.6 判断顺序表清空
/* 初始条件:顺序线性表L已存在。操作结果:若L为空表,则返回TRUE,否则返回FALSE */
Status ListEmpty(Sqlist L)
{
if(L.length==0)
return TRUE;
else
return FALSE;
}
//1.7 获取顺序表长度ListEmpty元素个数 */
int ListLength(Sqlist L)
{
return L.length;
}
//1.8 顺序输出List
/* 初始条件:顺序线性表L已存在 */
/* 操作结果:依次对L的每个数据元素输出 */
Status TraverseList(Sqlist L)
{
int i;
for(i=0;i<L.length;i++)
printf("%d\n",L.data[i]);
printf("\n");
return OK;
}
//1.9 顺序表查找元素并返回位置
/* 初始条件:顺序线性表L已存在 */
/* 操作结果:返回L中第1个与e满足关系的数据元素的位序。 */
/* 若这样的数据元素不存在,则返回值为0 */
int LocateElem(Sqlist L,ElemType e)
{
int i;
if (L.length==0) return 0;
for(i=0;i<L.length;i++)
{
if (L.data[i]==e)
break;
}
if(i>=L.length) return 0;
return i+1;
}
int main(int argc, const char * argv[]) {
// insert code here...
printf("Hello, Data Structure!\n");
Sqlist L;
Sqlist Lb;
ElemType e;
Status iStatus;
//1.1 顺序表初始化
iStatus = InitList(&L);
printf("初始化L后: L.Length = %d\n", L.length);
//1.2 顺序表数据插入
for(int j=1; j <= 5;j++){
iStatus = ListInsert(&L, 1, j);
}
printf("插入数据L长度: %d\n",L.length);
//1.3 顺序表取值
GetElem(L, 5, &e);
printf("顺序表L第5个元素的值为:%d\n",e);
//1.4 顺序表删除第2个元素
ListDelete(&L, 2);
printf("顺序表删除第%d元素,长度为%d\n",2,L.length);
//1.5 清空顺序表
iStatus = ClearList(&L);
printf("清空后,L.length = %d\n",L.length);
//1.6 判断List是否为空
iStatus=ListEmpty(L);
printf("L是否空:i=%d(1:是 0:否)\n",iStatus);
//1.8 TraverseList
for(int j=1; j <= 5;j++){
iStatus = ListInsert(&L, 1, j);
}
TraverseList(L);
return 0;
}
2、线性单链表
a、创建
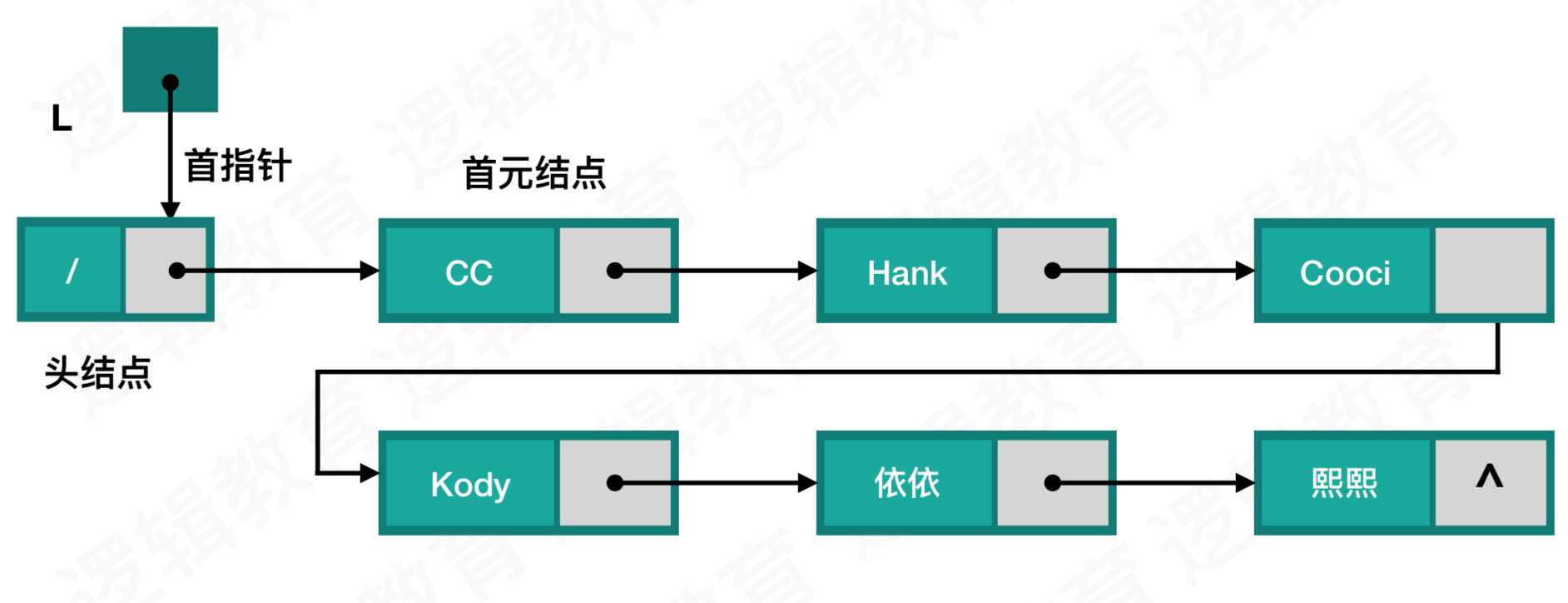
对于链表来说,都是由一个个节点组成,而单链表的节点分为数据域和指针域,其中数据域是存储数据的地方,指针域是存储指针的地方

我们可以根据下图来看看单链表逻辑状态:

为了操作方便,我们可以在链表头部增加一个头结点,好处:
- 便于首元结点处理
- 便于空表和非空表的统一处理
代码:
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define OK 1
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;/* Status是函数的类型,其值是函数结果状态代码,如OK等 */
typedef int ElemType;/* ElemType类型根据实际情况而定,这里假设为int */
//定义结点
typedef struct Node{
ElemType data;
struct Node *next;
}Node;
typedef struct Node * LinkList;
//2.1 初始化单链表线性表--新创建一个单链表线性表
Status InitList(LinkList *L){
//产生头结点,并使用L指向此头结点
*L = (LinkList)malloc(sizeof(Node));
//存储空间分配失败
if(*L == NULL) return ERROR;
//将头结点的指针域置空
(*L)->next = NULL;
return OK;
}
/* 初始条件:顺序线性表L已存在。操作结果:将L重置为空表 */
Status ClearList(LinkList *L)
{
LinkList p,q;
p=(*L)->next; /* p指向第一个结点 */
while(p) /* 没到表尾 */
{
q=p->next;
free(p);
p=q;
}
(*L)->next=NULL; /* 头结点指针域为空 */
return OK;
}
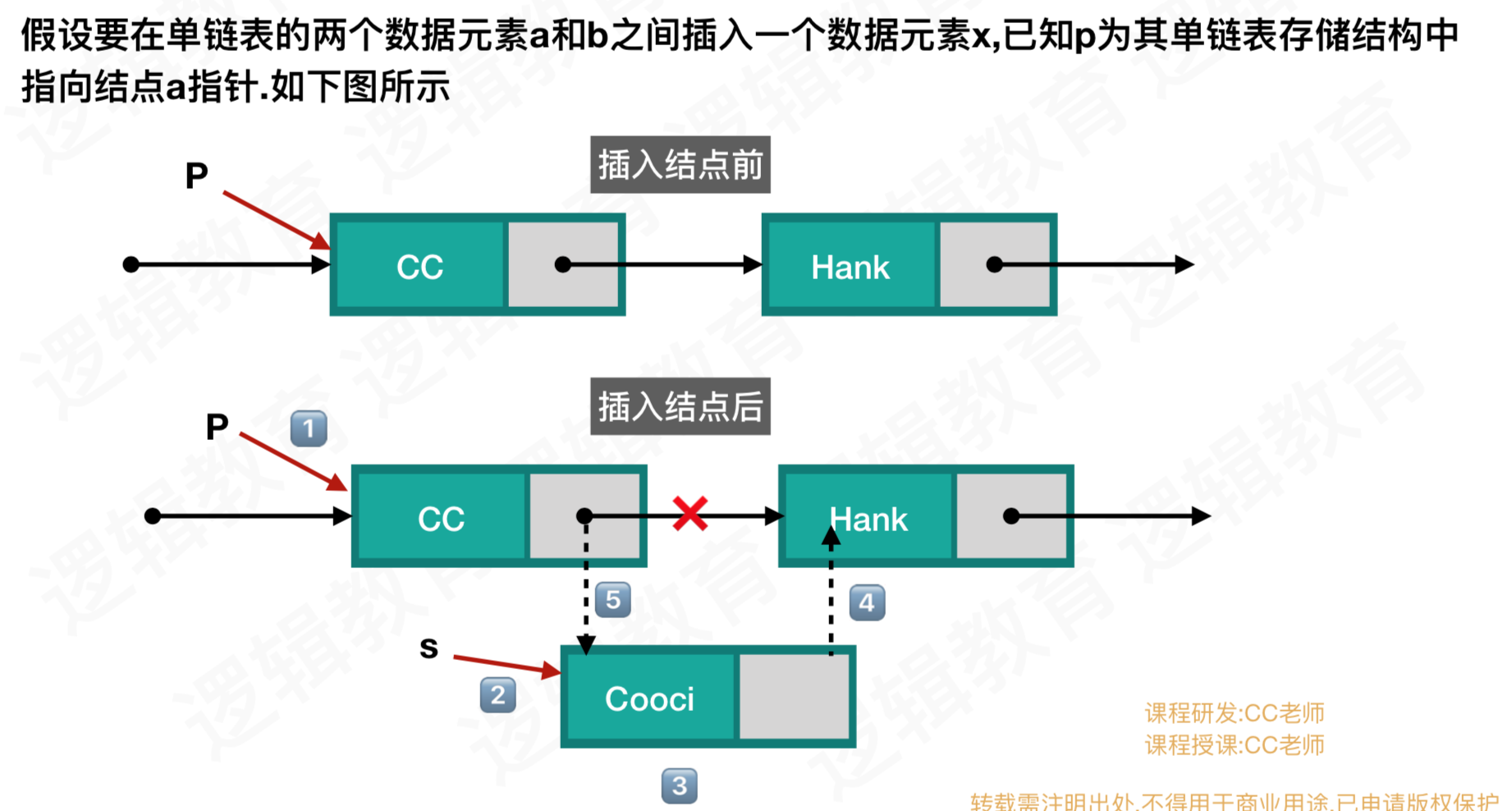
b、插入
单链表的插入流程:
//2.2 单链表插入
/*
初始条件:顺序线性表L已存在,1≤i≤ListLength(L);
操作结果:在L中第i个位置之后插入新的数据元素e,L的长度加1;
*/
Status ListInsert(LinkList *L,int i,ElemType e){
int j;
LinkList p,s;
p = *L;
j = 1;
//寻找第i-1个结点
while (p && j<i) {
p = p->next;
++j;
}
//第i个元素不存在
if(!p || j>i) return ERROR;
//生成新结点s
s = (LinkList)malloc(sizeof(Node));
//将e赋值给s的数值域
s->data = e;
//将p的后继结点赋值给s的后继
s->next = p->next;
//将s赋值给p的后继
p->next = s;
return OK;
}
c、删除
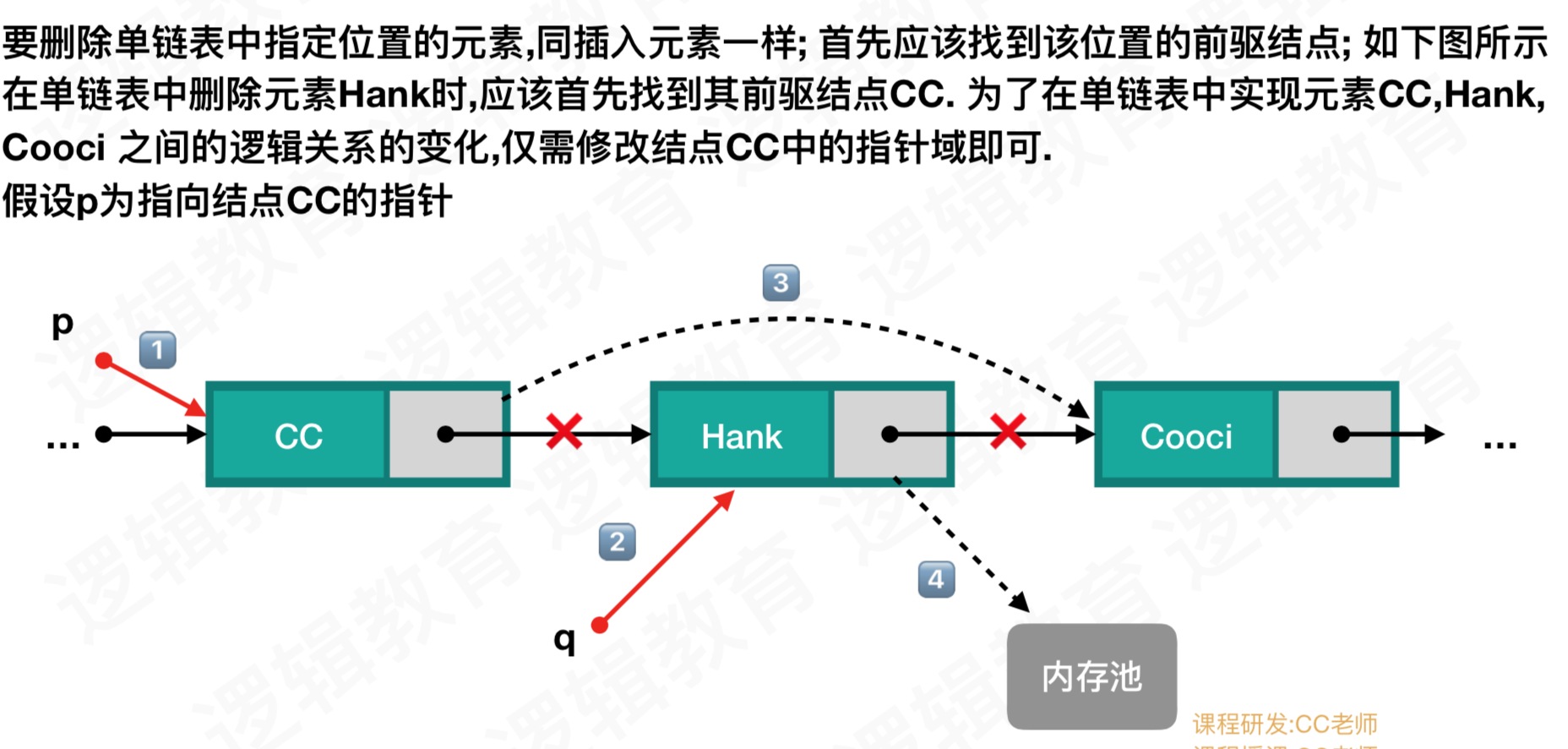
//2.4 单链表删除元素
/*
初始条件:顺序线性表L已存在,1≤i≤ListLength(L)
操作结果:删除L的第i个数据元素,并用e返回其值,L的长度减1
*/
Status ListDelete(LinkList *L,int i,ElemType *e){
int j;
LinkList p,q;
p = (*L)->next;
j = 1;
//查找第i-1个结点,p指向该结点
while (p->next && j<(i-1)) {
p = p->next;
++j;
}
//当i>n 或者 i<1 时,删除位置不合理
if (!(p->next) || (j>i-1)) return ERROR;
//q指向要删除的结点
q = p->next;
//将q的后继赋值给p的后继
p->next = q->next;
//将q结点中的数据给e
*e = q->data;
//让系统回收此结点,释放内存;
free(q);
return OK;
}
d、前插法
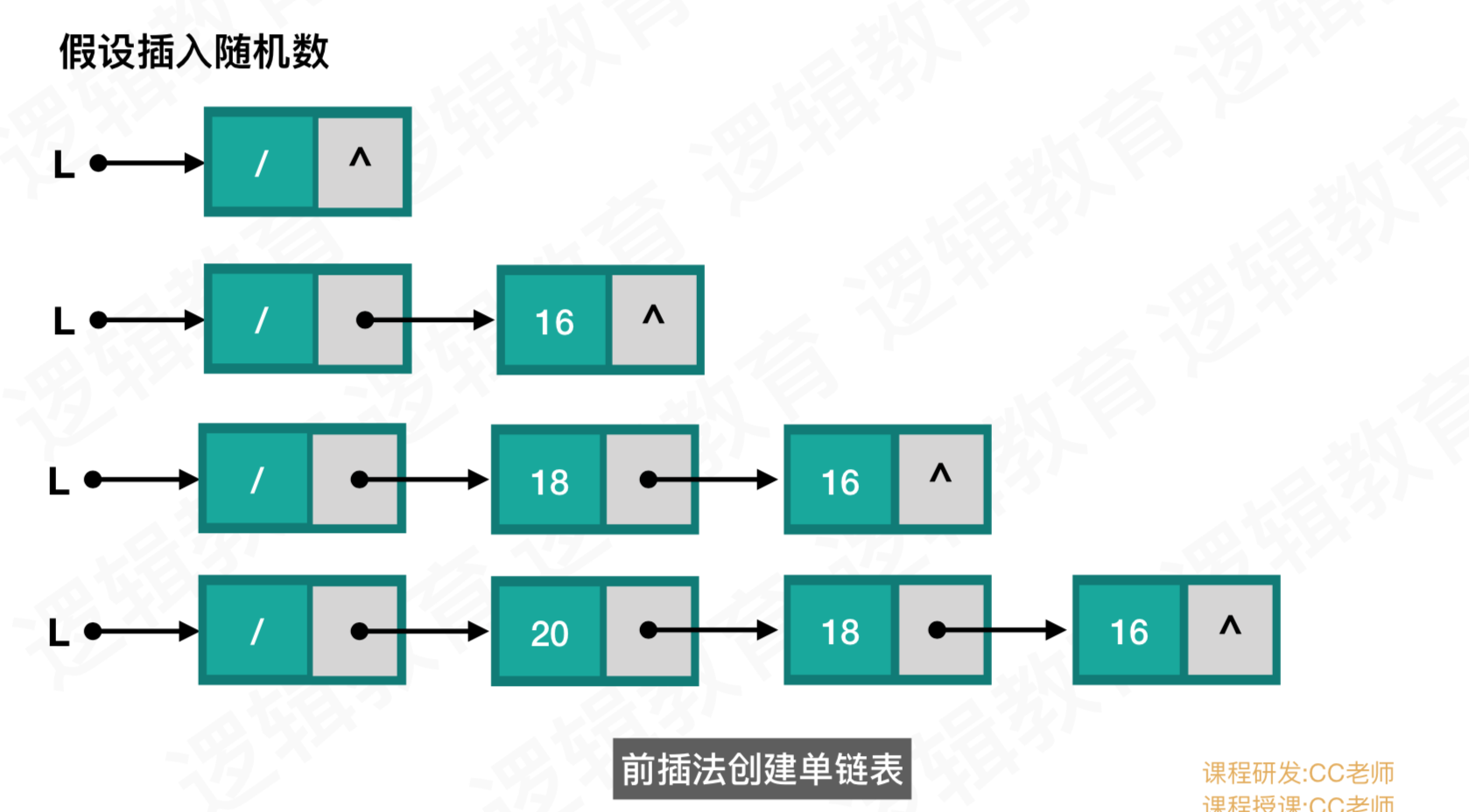
//3.1 单链表前插入法
/* 随机产生n个元素值,建立带表头结点的单链线性表L(前插法)*/
void CreateListHead(LinkList *L, int n){
LinkList p;
//建立1个带头结点的单链表
*L = (LinkList)malloc(sizeof(Node));
(*L)->next = NULL;
//循环前插入随机数据
for(int i = 0; i < n;i++)
{
//生成新结点
p = (LinkList)malloc(sizeof(Node));
//i赋值给新结点的data
p->data = i;
//p->next = 头结点的L->next
p->next = (*L)->next;
//将结点P插入到头结点之后;
(*L)->next = p;
}
}
e、后插法

//3.2 单链表后插入法
/* 随机产生n个元素值,建立带表头结点的单链线性表L(后插法)*/
void CreateListTail(LinkList *L, int n){
LinkList p,r;
//建立1个带头结点的单链表
*L = (LinkList)malloc(sizeof(Node));
//r指向尾部的结点
r = *L;
for (int i=0; i<n; i++) {
//生成新结点
p = (Node *)malloc(sizeof(Node));
p->data = i;
//将表尾终端结点的指针指向新结点
r->next = p;
//将当前的新结点定义为表尾终端结点
r = p;
}
//将尾指针的next = null
r->next = NULL;
}
d、取值
//2.3 单链表取值
/*
初始条件: 顺序线性表L已存在,1≤i≤ListLength(L);
操作结果:用e返回L中第i个数据元素的值
*/
Status GetElem(LinkList L,int i,ElemType *e){
//j: 计数.
int j;
//声明结点p;
LinkList p;
//将结点p 指向链表L的第一个结点;
p = L->next;
//j计算=1;
j = 1;
//p不为空,且计算j不等于i,则循环继续
while (p && j<i) {
//p指向下一个结点
p = p->next;
++j;
}
//如果p为空或者j>i,则返回error
if(!p || j > i) return ERROR;
//e = p所指的结点的data
*e = p->data;
return OK;
}
