

前文回顾
上一篇文章介绍了朴素贝叶斯算法的相关知识,包括以下几方面:
- 朴素贝叶斯算法的基本原理
- 公式推导贝叶斯准则(条件概率公式)
- 构建训练、测试简易文本分类算法
- 拉普拉斯平滑修正
其中公式推导这一部分较为重要,利用条件概率解决问题也是朴素贝叶斯的基本思想,所以理解贝叶斯准则如何得到,以及如何应用十分重要,也是后期构建算法的基础。
现实生活中朴素贝叶斯算法应用广泛,如文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等等;就文本分类而言,在众多分类算法,朴素贝叶斯分类算法也是学习效率和分类效果较好的分类器之一,因为朴素贝叶斯原理简单,构建算法相对容易,并且具有很好的可解释性。
但是朴素贝叶斯算法特点是假设所有特征的出现相互独立互不影响,每一特征都同等重要。但事实上这个假设在现实世界中并不成立:首先,相邻的两个词之间的必然联系,不能独立;其次,对一篇文章来说,其中的某一些代表词就确定它的主题,不需要通读整篇文章、查看所有词。所以需要采用合适的方法进行特征选择,这样朴素贝叶斯分类器才能达到更高的分类效率。
本文背景
本文利用朴素贝叶斯方法构建一个情感分类器,用于判断一个未知的语句,其所表达的是正面情绪or负面情绪,并通过比对预测结果和真实结果,得到该分类器的准确率。
最近在抖音上偶然看了一部电影的片段——饥饿站台,背景是在未来的反乌托邦国度中,囚犯们被关押在垂直堆叠的牢房里,饥肠辘辘地看着食物从上层落下,靠近顶层的人吃得饱饱的,而位于底层的人则因饥饿而变得激进,主要讲述了人性黑暗和饥渴的一面。个人认为这部电影还是不错的,所以我选择了豆瓣上这部电影的短评作为本文数据,但是比较遗憾的是爬取的数据并不多,但主要是讲述的是思想嘛。
豆瓣爬虫相对容易,所以爬虫部分不过多概述,我这里用的是requests和BeautifulSoup结合,但需要注意的是模拟登陆部分,如果不进行模拟登陆只能获取前10页的短评,而模拟登陆后可获取共24页短评。小Tip:热门短评和最新短评是不冲突的,最新短评可获取100条,这样数据样本能多一些。
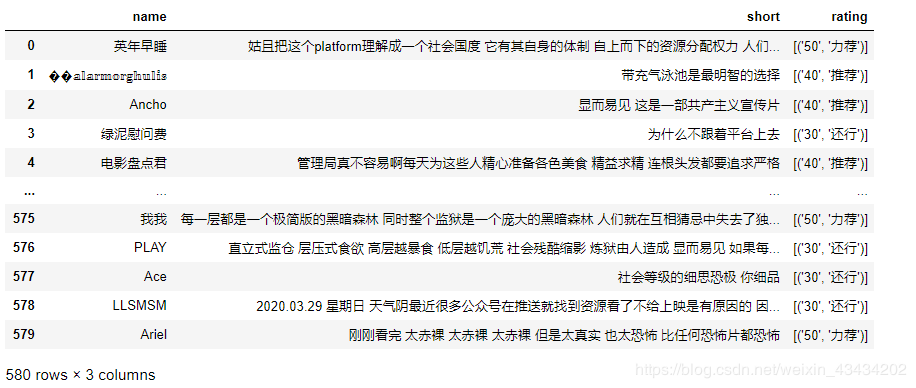
最后得到的数据集共580个样本、三个属性,截图如下:
文本预处理
在这个构建情感分类器的小实战中,算法部分并不是很复杂,很大一部分都是上文提及过的,而更多操作是在预处理数据集。如果是公共数据源上获取的数据集,可能只需要进行简单处理,因为大部分问题数据集的作者已经解决,但是个人爬虫得到的数据集,存在的问题相对较多,我们希望的是将所有短评文本转化成以词汇组成的列表格式,下面对文本进行预处理。
在原始数据集中,rating这一列是由评分+推荐指数构成,格式不是我们需要的,所以这里利用一个自定义函数,将其划分成1-5五个等级,我们可以将评分等级视为其对应短评的情感分类。
#将评分划分成1-5五个等级
def rating(e):
if '50' in e:
return 5
elif '40' in e:
return 4
elif '30' in e:
return 3
elif '20' in e:
return 2
elif '10' in e:
return 1
else:
return 'none'
# 利用map方法依据rating函数创建新一列
data['new_rating'] = data['rating'].map(rating)
划分等级之后,我们需要对每一条短评情感标注,这里选择删去评分等级为3的短评,原因是无法确定其短评情绪的类别。然后将评分等级为4、5的短评用1标注,视为正面情绪;将评分等级为1、2的短评用0标注,视为负面情绪。
# 删去评分为3的短评,判定评分为3的情感持中性
data = data[data['new_rating'] != 3]
#将4、5评分标注成1,视为正面情绪;将1、2评分标注成0,视为负面情绪
data['sentiment'] = data['new_rating'].apply(lambda x: +1 if x > 3 else 0)
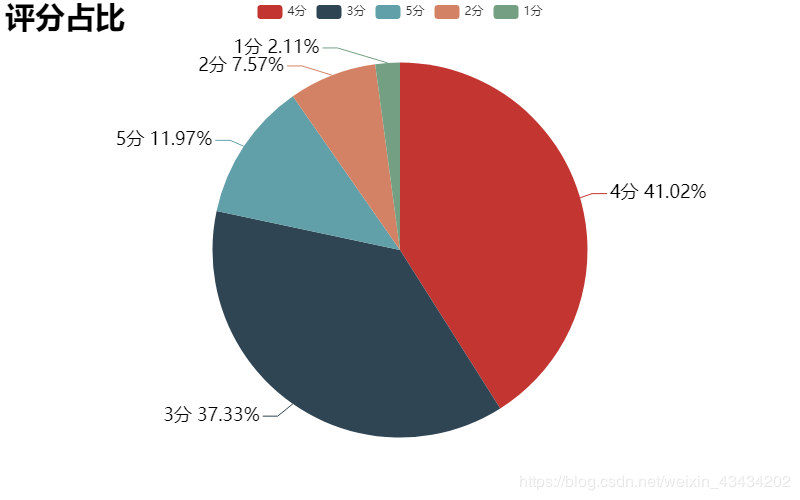
下图为五个评分等级的占比饼图,可以看出3分的占比是比较大的,所以删去评分为3的操作让数据集损失很多数据样本;4分、5分的占比要远多于1分、2分,所以数据集中正面情绪占比极大,电影可能是真不错,但是也凸显出了数据比例不均衡的问题。
 爬虫获取的短评可能包含很多英文符号、单词、字母,这些对于中文情感分析是没有任何帮助的,所以在分词之前,利用两个自定义函数删去短评中的符号和英文字母,这里没有对数字操作是因为下文停用词中包含了删去数字的操作,jieba分词模式选择默认的精准模式,精准模式可以将句子精确地切开,比较适合文本分析。
爬虫获取的短评可能包含很多英文符号、单词、字母,这些对于中文情感分析是没有任何帮助的,所以在分词之前,利用两个自定义函数删去短评中的符号和英文字母,这里没有对数字操作是因为下文停用词中包含了删去数字的操作,jieba分词模式选择默认的精准模式,精准模式可以将句子精确地切开,比较适合文本分析。
# 删去短评中的符号、英文字母
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}'
def remove_fuhao(e):
return re.sub(r"[%s]+" % punc, " ", e)
def remove_letter(new_short):
return re.sub(r'[a-zA-Z]+', '', new_short)
# 利用jieba切割文本
def cut_word(text):
text = jieba.cut(str(text))
return ' '.join(text)
# 同apply方法依据以上三个自定义函数为依据创建新一列
data['new_short'] = data['short'].apply(remove_fuhao).apply(remove_letter).apply(cut_word)
短评切分后一定会产生许多无关情感的词汇,例如一个、这个、人们等等,所以停用词函数的作用就是将此类词汇从短评中过滤掉。该函数主要思想是将短评按空格切分成词汇,然后遍历这个词汇列表,如果一个词汇未出现在停用词表中、词汇长度大于1、词汇不为Tab,则将连接至字符串outstr中;如果某个词汇已经存在于outstr,则不再添加,达到去重的效果。
文末提供中文停用词表获取方式
# 读取停用词表函数
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 将短评中的停用词删去
def sentence_div(text):
# 将短评按空格划分成单词并形成列表
sentence = text.strip().split()
# 加载停用词的路径
stopwords = stopwordslist(r'中文停用词表.txt')
#创建一个空字符串
outstr = ' '
# 遍历短评列表中每个单词
for word in sentence:
if word not in stopwords: # 判断词汇是否在停用词表里
if len(word) > 1: # 单词长度要大于1
if word != '\t': # 单词不能为tab
if word not in outstr: # 去重:如果单词在outstr中则不加入
outstr += ' ' # 分割
outstr += word # 将词汇加入outstr
#返回字符串
return outstr
data['the_short'] = data['new_short'].apply(sentence_div)
可能有一条短评说的很多都是是废话,恰巧都被停用词函数过滤了,剩下的词汇较少对这条短评的情感分析帮助很小,所以这里将词汇数量少于4个的短评删去;由于上面依据自定义函数创建了许多新的属性,内容过于冗杂,所以选出情感分析需要的两列(处理后的短评和标注)合并成一个新的DataFrame。
data['split'] = data['the_short'].apply(lambda x: 1 if len(x.split()) > 3 else 0)
data = data[~data['split'].isin(['0'])]
# 将需要的两列数据索引出,合并成一个新的DataFrame
new_data1 = data.iloc[:, 3]
new_data2 = data.iloc[:, 5]
new_data = pd.DataFrame({'short': new_data2, 'sentiment': new_data1})
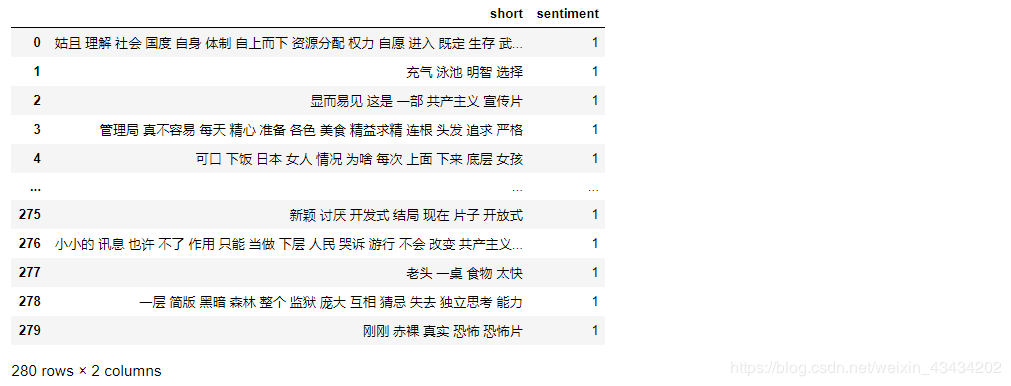
经过预处理的数据集只剩下了280个样本,截图如下:
 上文提及过一个问题,短评正面情绪所占比例要远大于负面情绪,为了避免测试数据集中的样本全为正面情绪,所以这里采用随机选择的方式划分数据集。利用random库中的sample方法随机选择**10%**的数据的索引作为测试数据集的索引,剩下的部分作为训练数据集的索引;然后按照两类索引将数据集切割成两部分,并分别保存。
上文提及过一个问题,短评正面情绪所占比例要远大于负面情绪,为了避免测试数据集中的样本全为正面情绪,所以这里采用随机选择的方式划分数据集。利用random库中的sample方法随机选择**10%**的数据的索引作为测试数据集的索引,剩下的部分作为训练数据集的索引;然后按照两类索引将数据集切割成两部分,并分别保存。
def splitDataSet(new_data):
# 获取数据集中随机的10%作为测试集,获取测试数据集的索引
test_index = random.sample(new_data.index.tolist(), int(len(new_data.index.tolist()) * 0.10))
# 剩下的部分作为训练集,获取训练数据集的索引
train_index = [i for i in new_data.index.tolist() if i not in test_index]
#分别索引出训练集和测试集
test_data = new_data.iloc[test_index]
train_data = new_data.iloc[train_index]
# 分别保存为csv文件
train_data.to_csv('bayes_train.csv', encoding='utf_8_sig', index=False)
test_data.to_csv('bayes_test.csv', encoding='utf_8_sig', index=False)
构建分类器
构建分类器部分与上一篇文章的代码会冲突,所以下面的算法部分不会过多讲述其原理;如果你刚接触朴素贝叶斯或者想了解其原理,推荐先观看上一篇文章:机器学习笔记(五)——轻松看透朴素贝叶斯;如果你对朴素贝叶斯原理已经足够理解了,若只对源码和数据感兴趣可以直接跳过此部分划到文末哟。
构建词向量
loadDataSet函数的作用是将短评转化成所需要的词条向量格式,即每一条短评的词汇构成一个列表,再将所有列表添加至一个列表中,构成一个词条集合,classVec是由短评对应的情感标注构成的列表。
def loadDataSet(filename):
data = pd.read_csv(filename)
postingList = []
#文本语句切分
for sentence in data['short']:
word = sentence.strip().split()# split方法返回一个列表
postingList.append(word)# 将每个词汇列表添至一个列表中
#类别标签的向量
classVec = data['sentiment'].values.tolist()
return postingList,classVec
createVocabList函数的作用是通过set方法已经取并集的方式返回一个包含文本中所有出现的不重复词的集合。
#创建词汇表
def createVocabList(dataSet):
#创建一个空的不重复列表
vocabSet = set([])
for document in dataSet:
#取两者并集
vocabSet = vocabSet | set(document)
return list(vocabSet)
setOfWords2Vec函数的作用是将短评向量化,输入参数为总词汇表和某个短评,输出的是文本向量,向量的元素包括1或0,分别表示词汇表中的单词是否出现在输入的文本中,思路是首先创建一个同词汇表等长的向量,并将其元素都设置为0,然后遍历输入文本的单词,若词汇表中出现了本文的单词,则将其对应位置上的0置换为1。
#词条向量化函数
def setOfWords2Vec(vocabList, inputSet):
#创建一个元素都为0的向量
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
#若词汇表包含该词汇,则将该位置的0变为1
returnVec[vocabList.index(word)] = 1
return returnVec
getMat函数的作用是将所有处理后的词条向量汇总合并成一个词条向量矩阵,方便测试算法时调用。
#词条向量汇总
def getMat(inputSet):
trainMat = []
vocabList = createVocabList(inputSet)
for Set in inputSet:
returnVec = setOfWords2Vec(vocabList,Set)
trainMat.append(returnVec)
return trainMat
训练算法
trainNB函数的输入参数包括短评矩阵trainMatrix和每个词条的情感标注所构成的向量trainCategory。首先短评属于正面情绪的概率只需要将正面情绪短评的个数除以总词条个数即可;计算P(W | C1)和P(W | C0)时,需要将其分子和分母初始化,遍历输入文本时,一旦某个词语(正面情绪or负面情绪)在某一文档中出现,则该词对应的个数(p1Num或p0Num)就加1,并且在总文本中,该词条的总次数也相应加1。
def trainNB(trainMatrix,trainCategory):
#训练文本数量
numTrainDocs = len(trainMatrix)
#每篇文本的词条数
numWords = len(trainMatrix[0])
#文档属于正面情绪(1)的概率
pAbusive = sum(trainCategory)/float(numTrainDocs)
#创建两个长度为numWords的零数组
p0Num = np.ones(numWords)
p1Num = np.ones(numWords)
#分母初始化
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
#统计正面情绪的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
#print(p1Num)
p1Denom += sum(trainMatrix[i])
#print(p1Denom)
else:
#统计负面情绪的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
#计算词条出现的概率
p1Vect = np.log(p1Num/p1Denom)
p0Vect = np.log(p0Num/p0Denom)
#print("\n",p0Vect,"\n\n",p1Vect,"\n\n",pAbusive)
return p1Vect,p0Vect,pAbusive
测试算法
classifyNB函数是一个判断类别的函数,输入参数为向量格式的测试数据和训练函数trainNB的三个返回值,如p1的概率大于p0的概率则代表该测试数据为正面情绪,返回值为1;返之则是负面情绪,返回值为0。
def classifyNB(ClassifyVec, p1V,p0V,pAb):
#将对应元素相乘
print(pAb)
p1 = sum(ClassifyVec * p1V) + np.log(pAb)
p0 = sum(ClassifyVec * p0V) + np.log(1.0 - pAb)
print('p1:',p1)
print('p0:',p0)
if p1 > p0:
return 1
else:
return 0
testNB为测试函数,通过调用上述函数对测试集进行预测,并通过比较真实结果和测试结果以得到分类器的准确率。
def testNB():
#加载训练集数据
train_postingList,train_classVec = loadDataSet('bayes_train4.csv')
#创建词汇表
vocabSet = createVocabList(train_postingList)
#将训练样本词条向量汇总
trainMat = getMat(train_postingList)
#训练算法
p1V,P0V,PAb = trainNB(trainMat,train_classVec)
#加载测试集数据
test_postingList,test_classVec = loadDataSet('bayes_test4.csv')
# 将测试文本向量化
predict = []
for each_test in test_postingList:
testVec = setOfWords2Vec(vocabSet,each_test)
#判断类别
if classifyNB(testVec,p1V,P0V,PAb):
print(each_test,"正面情绪")
predict.append(1)
else:
print(each_test,"负面情绪")
predict.append(0)
corr = 0.0
for i in range(len(predict)):
if predict[i] == test_classVec[i]:
corr += 1
print("朴素贝叶斯分类器准确率为:" + str(round((corr/len(predict)*100),2)) + "%")
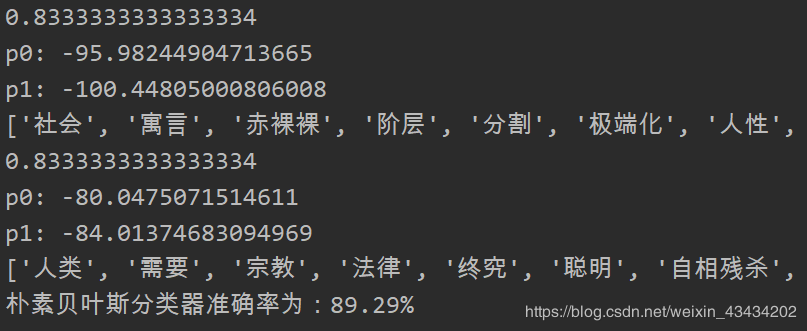
最后程序运行截图如下:
因为我们是利用随机选择的方法划分训练集与测试集,所以每次运行程序,朴素贝叶斯分类器的准确率都会改变,可以多运行几次取其平均值作为该模型的准确率。最后附上依据该数据集绘制的词云图,不知道这部电影的体裁能不能引起你的兴趣的呢?

总结
在利用朴素贝叶斯算法进行类似的情感分析或者文本分类时,尽可能要保持原始数据充足,像上文580条原始数据经过文本预处理之后只剩下280条。只有数据充足,模型才能有具有实用性,数据太少会导致模型的准确率浮动较大,并且也具有极高的偶然性。
关注公众号【奶糖猫】后台回复“饥饿站台”可获取源码和数据供参考,感谢阅读。

