


1、Transformations 分类
Flink 的 Transformations 操作主要用于将一个和多个 DataStream 按需转换成新的 DataStream。它主要分为以下三类:
- DataStream Transformations:进行数据流相关转换操作;
- Physical partitioning:物理分区。Flink 提供的底层 API ,允许用户定义数据的分区规则;
- Task chaining and resource groups:任务链和资源组。允许用户进行任务链和资源组的细粒度的控制。
以下分别对其主要 API 进行介绍:
2、DataStream Transformations
2.1 Map [DataStream → DataStream]
对一个 DataStream 中的每个元素都执行特定的转换操作:
DataStream<Integer> integerDataStream = env.fromElements(1, 2, 3, 4, 5);
integerDataStream.map((MapFunction<Integer, Object>) value -> value * 2).print();
// 输出 2,4,6,8,10
2.2 FlatMap [DataStream → DataStream]
FlatMap 与 Map 类似,但是 FlatMap 中的一个输入元素可以被映射成一个或者多个输出元素,示例如下:
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val source = env.fromElements("You go first","Life was like a box of chocolates")
source.flatMap(perEle=>perEle.split(" ")).print()
env.execute()
}
// 输出每一个独立的单词
2> You
3> Life
2> go
3> was
2> first
3> like
3> a
3> box
3> of
3> chocolates
2.3 Filter [DataStream → DataStream]
用于过滤符合条件的数据:
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val source = env.fromElements(1,2,3,4,5)
source.filter(x => x>3).print()
env.execute()
}
2.4 KeyBy 和 Reduce
KeyBy [DataStream → KeyedStream] :用于将相同 Key 值的数据分到相同的分区中;
Reduce [KeyedStream → DataStream] :对数据进行聚合(sum,max,min等)操作,结合当前元素和上一次reduce返回的值进行聚合操作,然后返回一个新的值
案例
求出安放在北京西站各个位置的红外测温仪迄今为止所测得的最早时间,以及测得的最高温度。
思路:
1.根据红外测温仪的id进行分组
2.对分组之后的结果进行聚合操作
最早的时间--> 求最小值
测得的最高温度---> 求最大值
package com.jd.unbounded.transformation_reduce
import com.jd.unbounded.Raytek
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
/**
* Description 求出安放在北京西站各个位置的红外测温仪迄今为止所测得的最早时间,以及测得的最高温度。
* @author lijun
* @create 2020-03-24
*/
object ReduceTest {
def main(args: Array[String]): Unit = {
//步骤:
//1.环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.实时读取流数据,计算,并显示结果
env.readTextFile("/Users/lijun/Downloads/flink_input/raytek")
.map(perInfo=>{
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id,temperature,name,timestamp,location)
}).keyBy("id")//根据红外测温仪的id进行分组
.reduce((before:Raytek,after:Raytek)=>{
val maxTemperature = Math.max(before.temperature,after.temperature)
val minTimestamp = Math.min(before.timestamp,after.timestamp)
Raytek(before.id,maxTemperature,"",minTimestamp,"")
}).print("迄今为止最高的体温,最早的时间")//求各个分组中的最早的时间,以及最高的温度
//3.启动
env.execute(this.getClass.getSimpleName)
}
}
KeyBy 操作存在以下两个限制:
KeyBy 操作用于用户自定义的 POJOs 类型时,该自定义类型必须重写 hashCode 方法;
KeyBy 操作不能用于数组类型。
2.5 Union [DataStream* → DataStream]
用于连接两个或者多个元素类型相同的 DataStream 。当然一个 DataStream 也可以与其本身进行连接,此时该 DataStream 中的每个元素都会被获取两次:
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val sourceStream1 = env.fromElements(("a",1),("a",2))
val sourceStream2 = env.fromElements(("b",1),("b",2))
sourceStream1.union(sourceStream2).print("合并后-->")
env.execute()
}
控制台输出
合并后-->:8> (b,1)
合并后-->:2> (a,2)
合并后-->:1> (a,1)
合并后-->:1> (b,2)
2.6 Connect [DataStream,DataStream → ConnectedStreams]
Connect 操作用于连接两个或者多个类型不同的 DataStream ,其返回的类型是 ConnectedStreams ,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立
Connect与union区别:
connect只能连接两个数据流,union可以连接多个数据流。
connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致
两个dataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
代码
package com.jd.unbounded.transformation_connect
import com.jd.unbounded.Raytek
import org.apache.flink.streaming.api.scala.{ConnectedStreams, SplitStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
/**
* Description:使用DataStream的算子connect将两个类型不同的流合并在一起,分别单独处理
*
* @author lijun
* @create 2020-03-26 08:16
*/
object ConnectionStreamTest {
def main(args: Array[String]): Unit = {
//1.环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.实时读取流数据,计算,并显示结果
val splitStream: SplitStream[Raytek] = env.readTextFile("/Users/lijun/Downloads/flink_input/raytek")
.map(perInfo => {
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).split(rayteck => if (rayteck.temperature >= 36.3 && rayteck.temperature <= 37.2) Seq("正常") else Seq("异常"))
//从流中取出所有体温正常的旅客信息,进行处理
val normalStream = splitStream.select("正常").map(perEle=>(perEle.id,s"名字为[${perEle.name}]的旅客体温正常哦!..."))
//从流中取出所有体温民异常的旅客信息,进行处理
val exceptionStream = splitStream.select("异常").map(perEle=>(perEle.id,perEle.name,perEle.temperature,s"旅客体温异常哦,需要隔离..."))
val connectedStream: ConnectedStreams[(String, String), (String, String, Double, String)] = normalStream.connect(exceptionStream)
connectedStream.map(normal=>("红外测温仪的id->"+normal._1,"旅客的信息是->"+normal._2),exception=>("红外测温仪的id->"+exception._1,"旅客的名字是->"+exception._2,"旅客的温度->"+exception._3,"警报信息是->"+exception._4))
.print()
//3.启动
env.execute(this.getClass.getSimpleName)
}
}
效果
5> (红外测温仪的id->raytek_2,旅客的信息是->名字为[leon]的旅客体温正常哦!...)
3> (红外测温仪的id->raytek_1,旅客的信息是->名字为[jack]的旅客体温正常哦!...)
3> (红外测温仪的id->raytek_3,旅客的信息是->名字为[john]的旅客体温正常哦!...)
1> (红外测温仪的id->raytek_2,旅客的名字是->bush,旅客的温度->37.4,警报信息是->旅客体温异常哦,需要隔离...)
4> (红外测温仪的id->raytek_9,旅客的信息是->名字为[tom]的旅客体温正常哦!...)
8> (红外测温仪的id->raytek_3,旅客的名字是->jerry,旅客的温度->37.8,警报信息是->旅客体温异常哦,需要隔离...)
7> (红外测温仪的id->raytek_3,旅客的信息是->名字为[alice]的旅客体温正常哦!...)
6> (红外测温仪的id->raytek_3,旅客的信息是->名字为[kate]的旅客体温正常哦!...)
2.7 Split 和 Select
Split [DataStream → SplitStream]:用于将一个 DataStream 按照指定规则进行拆分为多个 DataStream,需要注意的是这里进行的是逻辑拆分,即 Split 只是将数据贴上不同的类型标签,但最终返回的仍然只是一个 SplitStream;
Select [SplitStream → DataStream]:想要从逻辑拆分的 SplitStream 中获取真实的不同类型的 DataStream,需要使用 Select 算子
示例如下:
高铁G66到了北京西站,旅客依次出站
出站口会有红外体温测量仪进行测温
将体温正常的旅客放行
将体温异常的旅客立马通知工作人员进行后续的处理
package com.jd.unbounded.transformation_split
import com.jd.unbounded.Raytek
import org.apache.flink.streaming.api.scala.{SplitStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
/**
* Description:高铁G66到了北京西站,旅客依次出站
* 出站口会有红外体温测量仪进行测温
* 将体温正常的旅客放行
* 将体温异常的旅客立马通知工作人员进行后续的处理
* @author lijun
* @create 2020-03-24
*/
object SplitStreamTest {
def main(args: Array[String]): Unit = {
//1.环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.实时读取流数据,计算,并显示结果
val splitStream: SplitStream[Raytek] = env.readTextFile("/Users/lijun/Downloads/flink_input/raytek")
.map(perInfo => {
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).split(rayteck => if (rayteck.temperature >= 36.3 && rayteck.temperature <= 37.2) Seq("正常") else Seq("异常"))
//从流中取出所有体温正常的旅客信息,进行处理
splitStream.select("正常").print("体温正常的旅客信息")
//从流中取出所有体温民异常的旅客信息,进行处理
splitStream.select("异常").print("体温异常的旅客信息")
//3.启动
env.execute(this.getClass.getSimpleName)
}
}
效果
体温正常的旅客信息:1> Raytek(raytek_3,36.4,kate,1582641128,北京西站-东5号停车场)
体温异常的旅客信息:4> Raytek(raytek_2,37.4,bush,15826411231,北京西站-北广场3号停车场)
体温异常的旅客信息:3> Raytek(raytek_3,37.8,jerry,1582641330,北京西站-地铁站)
体温正常的旅客信息:6> Raytek(raytek_1,36.3,jack,1582641121,北京西站-北广场)
体温正常的旅客信息:7> Raytek(raytek_9,36.3,tom,1582641124,北京西站-公交车站)
体温正常的旅客信息:6> Raytek(raytek_3,36.8,john,1582641323,北京西站-地铁站)
体温正常的旅客信息:8> Raytek(raytek_2,36.4,leon,1582641127,北京西站-北广场3号停车场)
体温正常的旅客信息:2> Raytek(raytek_3,36.8,alice,1582641129,北京西站-南广场-公交站)
2.8 使用侧输出流优化split算子
特别说明:
transformation算子之split已经过时了,在flink高版本的api中,建议使用"侧输出流"来代替
"侧输出流":其中放置的是主流之外的延迟或有异常的数据
主流: 存放的是正常抵达的数据
如何从当前的流中取出侧输出流中的数据?
DataStream实例.getSideOutput(OutputTag实例)
代码
package com.jd.unbounded.transformation_side
import com.jd.unbounded.Raytek
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala.{OutputTag, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
object SideOutputStreamTest {
def main(args: Array[String]): Unit = {
//1.环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//准备一个outputTag的实例,即为 侧输出流中每个元素的标识值,下述泛型表示侧输出流中每个元素的数据类型
val outputTag = new OutputTag[String]("体温偏高")
//2.实时读取流数据,计算,并显示结果
val totalStream = env.readTextFile("/Users/lijun/Downloads/flink_input/raytek")
.map(perInfo => {
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).process(new ProcessFunction[Raytek,Raytek] {
override def processElement(value: Raytek,
ctx: ProcessFunction[Raytek, Raytek]#Context,
out: Collector[Raytek]): Unit = {
if(value.temperature>=36.3 && value.temperature<=37.2){
//体温正常, 使用实例Collector直接输出到主输出流中
out.collect(value)
}else{
//体温异常,使用实例Context输出到侧输出流中
ctx.output(outputTag,"体温偏高-->"+value.toString)
}
}
})
//取出侧输出流中的旅客信息,进行处理
totalStream.getSideOutput(outputTag).print("体温异常的旅客信息是-->")
//取出主输出流中的旅客信息,进行处理
totalStream.print("体温正常的旅客信息是-->")
//3.启动
env.execute(this.getClass.getSimpleName)
}
}
效果
体温正常的旅客信息是-->:7> Raytek(raytek_1,36.3,jack,1582641121,北京西站-北广场)
体温正常的旅客信息是-->:7> Raytek(raytek_3,36.8,john,1582641323,北京西站-地铁站)
体温异常的旅客信息是-->:4> 体温偏高-->Raytek(raytek_3,37.8,jerry,1582641330,北京西站-地铁站)
体温正常的旅客信息是-->:2> Raytek(raytek_3,36.4,kate,1582641128,北京西站-东5号停车场)
体温异常的旅客信息是-->:5> 体温偏高-->Raytek(raytek_2,37.4,bush,15826411231,北京西站-北广场3号停车场)
体温正常的旅客信息是-->:1> Raytek(raytek_2,36.4,leon,1582641127,北京西站-北广场3号停车场)
体温正常的旅客信息是-->:3> Raytek(raytek_3,36.8,alice,1582641129,北京西站-南广场-公交站)
体温正常的旅客信息是-->:8> Raytek(raytek_9,36.3,tom,1582641124,北京西站-公交车站)
2.9 用户自定义函数
2.9.1 说明
实现方式:
方式1: 使用自定义函数子类
a)参数固化在特定的业务方法中
b)参数动态传入
方式2: 使用匿名函数
案例: 使用用户自定义函数的方式,筛选当天所有经过红外测温仪编号为raytek_2的旅客信息
2.9.2 实现方式1 参数固化在特定的业务方法中
源码
package com.jd.unbounded.sample_self
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
/**
* Description: 用户自定义函数演示,筛选当天所有经过红外测温仪编号为raytek_2的旅客信息
* @author lijun
* @create 2020-03-26
*/
object SelfDefineFunctionTest {
def main(args: Array[String]): Unit = {
//步骤
//1. 执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.readTextFile("/Users/lijun/Downloads/flink_input/raytek")
.map(perInfo => {
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).filter(new MyFilter)
.print("使用自定义函数子类,实现的效果-->")
//3. 启动
env.execute(this.getClass.getSimpleName)
}
//自定义过滤函数的子类
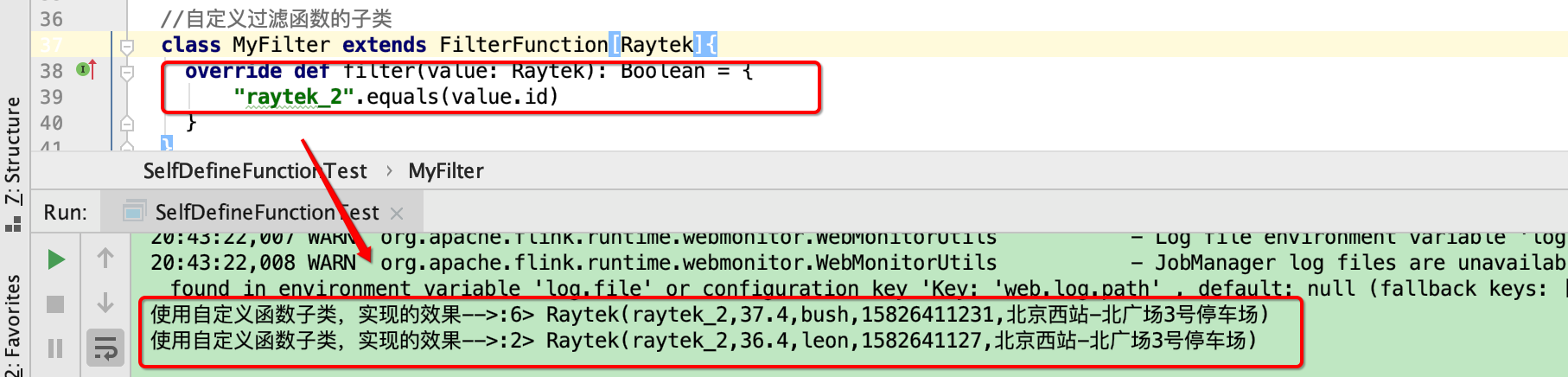
class MyFilter extends FilterFunction[Raytek]{
override def filter(value: Raytek): Boolean = {
"raytek_2".equals(value.id)
}
}
}
效果
2.9.3 实现方式1 参数动态传入
源码
package com.jd.unbounded.sample_self
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* Description: 用户自定义函数演示,筛选当天所有经过红外测温仪编号为raytek_2的旅客信息
*
* @author lijun
* @create 2020-03-26
*/
object SelfDefineFunctionTest2 {
def main(args: Array[String]): Unit = {
//1.拦截非法参数
if(args == null || args.length !=2){
println(
"""
请传入参数!--id <红外测温仪的id>
""".stripMargin)
sys.exit(-1)
}
//2.获取参数值
val tool = ParameterTool.fromArgs(args)
val id = tool.get("id")
//步骤
//1. 执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.readTextFile("/Users/lijun/Downloads/flink_input/raytek")
.map(perInfo => {
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).filter(new MyFilter(id))
.print("使用自定义函数子类之动态传参方式,实现的效果-->")
//3. 启动
env.execute(this.getClass.getSimpleName)
}
//自定义过滤函数的子类
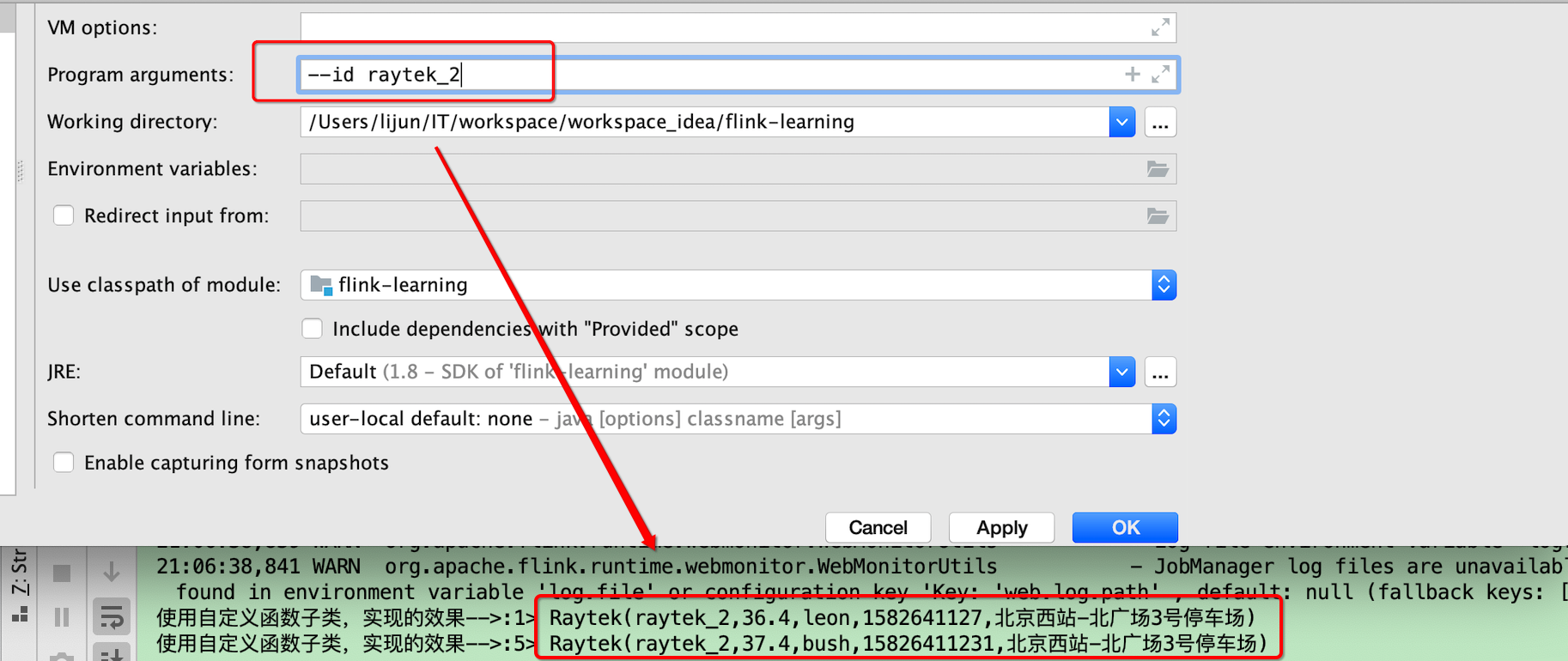
class MyFilter(id:String) extends FilterFunction[Raytek]{
override def filter(value: Raytek): Boolean = {
id.equals(value.id)
}
}
}
效果
2.9.4 实现方式2 使用匿名函数 动态传参方式
源码
package com.jd.unbounded.sample_self
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* Description: 用户自定义函数演示,筛选当天所有经过红外测温仪编号为raytek_2的旅客信息
*
* @author lijun
* @create 2020-03-26
*/
object SelfDefineFunctionTest3 {
def main(args: Array[String]): Unit = {
//1.拦截非法参数
if(args == null || args.length !=2){
println(
"""
请传入参数!--id <红外测温仪的id>
""".stripMargin)
sys.exit(-1)
}
//2.获取参数值
val tool = ParameterTool.fromArgs(args)
val id = tool.get("id")
//步骤
//1. 执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.readTextFile("/Users/lijun/Downloads/flink_input/raytek")
.map(perInfo => {
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).filter(new FilterFunction[Raytek]{
override def filter(value: Raytek): Boolean = {
id.equals(value.id)
}
})
.print("使用自定义【匿名】函数之动态传参方式,实现的效果-->")
//3. 启动
env.execute(this.getClass.getSimpleName)
}
}
2.10 用户自定义富函数(本质:升级版的自定义transformation)
2.10.1 说明
案例: 一批旅客正在通过各个关口设置的红外测温仪,将体温异常的旅客信息单独提取出来,存入到kafka消息队列中,体温正常的旅客不予干预
实现的步骤:
1.启动kafka分布式集群,新建一个名为temperature_exception的主题
2.编写自定义的富函数,如MyRichFlatMapFunction
a) close ->进行资源的释放
b) open -> 进行初始化的操作
c) flatMap -> 进行业务处理,将当前的旅客信息根据指定的业务进行处理
i) 体温正常的,直接送往主DataStream进行后续的处理
ii) 体温异常,将该旅客的信息存入到kafka消息队列特定的主题分区中
2.10.2 启动kafka分布式集群,新建一个名为temperature_exception的主题
[robin@node01 ~]$ kafka-topics.sh --create --topic temperature_exception --partitions 3 --replication-factor 3 --zookeeper node01:2181
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "temperature_exception".
2.10.3 编写自定义的富函数, 如MyRichFlatMapFunction
/**
* @param topic 主题名
* @param properties 该参数值中封装了与kafka分布式集群建立连接的一系列参数
*/
class MyRichFlatMapFunction(topic:String,properties:Properties) extends RichFlatMapFunction[Raytek,Raytek]{
//准备全局变量producer, 给后续的方法flatMap来使用
private var producer:KafkaProducer[String,String] = _
/**
* 进行初始化的工作,分析当前的DataStream时也只会执行一次
* @param parameters
*/
override def open(parameters: Configuration): Unit = {
producer = new KafkaProducer[String,String](properties)
}
/**
* 该方法会执行n次,从DataStream中每次流过来一条信息,就会触发执行一次
* @param value 封装了DataStream中实时产生的一条旅客信息
* @param out 将处理后的数据收集到新的DataStream中
*/
override def flatMap(value: Raytek, out: Collector[Raytek]): Unit = {
val normal = value.temperature >= 36.3 && value.temperature <= 37.2
if(normal){
//体温正常,直接送往主DataStream
out.collect(value)
}else{
//体温异常,将该旅客信息存入到kafka中
val msg:ProducerRecord[String,String] = new ProducerRecord(topic,value.toString)
producer.send(msg)
}
}
/**
* 进行资源释放
* 该方法只会执行一次
*/
override def close(): Unit = {
if(producer != null){
producer.close()
}
}
}
2.10.4 准备producer.properties资源文件
############################# Producer Basics #############################
# list of brokers used for bootstrapping knowledge about the rest of the cluster
# format: host1:port1,host2:port2 ...
bootstrap.servers=node01:9092
# specify the compression codec for all data generated: none, gzip, snappy, lz4
compression.type=none
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
2.10.5 最终源码
package com.jd.unbounded.sample_self.b_rich
import java.util.Properties
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.util.Collector
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.flink.api.scala._
/**
* @param topic 主题名
* @param properties 该参数值中封装了与kafka分布式集群建立连接的一系列参数
*/
class MyRichFlatMapFunction(topic:String,properties:Properties) extends RichFlatMapFunction[Raytek,Raytek]{
//准备全局变量producer, 给后续的方法flatMap来使用
private var producer:KafkaProducer[String,String] = _
/**
* 进行初始化的工作,分析当前的DataStream时也只会执行一次
* @param parameters
*/
override def open(parameters: Configuration): Unit = {
producer = new KafkaProducer[String,String](properties)
}
/**
* 该方法会执行n次,从DataStream中每次流过来一条信息,就会触发执行一次
* @param value 封装了DataStream中实时产生的一条旅客信息
* @param out 将处理后的数据收集到新的DataStream中
*/
override def flatMap(value: Raytek, out: Collector[Raytek]): Unit = {
val normal = value.temperature >= 36.3 && value.temperature <= 37.2
if(normal){
//体温正常,直接送往主DataStream
out.collect(value)
}else{
//体温异常,将该旅客信息存入到kafka中
val msg:ProducerRecord[String,String] = new ProducerRecord(topic,value.toString)
producer.send(msg)
}
}
/**
* 进行资源释放
* 该方法只会执行一次
*/
override def close(): Unit = {
if(producer != null){
producer.close()
}
}
}
object SelfDefineRichFunctionTest {
def main(args: Array[String]): Unit = {
val topic:String = "temperature_exception"
val properties = new Properties()
properties.load(this.getClass.getClassLoader.getResourceAsStream("producer.properties"))
//步骤
//1. 执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.readTextFile("/Users/lijun/Downloads/flink_input/raytek")
.map(perInfo => {
val arr = perInfo.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).flatMap(new MyRichFlatMapFunction(topic,properties))
.print("经由富函数处理,体温正常的旅客信息是-->")
//3. 启动
env.execute(this.getClass.getSimpleName)
}
}
2.10.6 效果演示
体温正常的旅客信息处理情形

体温异常的旅客信息处理情形

3、物理分区
物理分区 (Physical partitioning) 是 Flink 提供的底层的 API,允许用户采用内置的分区规则或者自定义的分区规则来对数据进行分区,从而避免数据在某些分区上过于倾斜,常用的分区规则如下:
3.1 Random partitioning [DataStream → DataStream]
随机分区 (Random partitioning) 用于随机的将数据分布到所有下游分区中,通过 shuffle 方法来进行实现:
dataStream.shuffle();
3.2 Rebalancing [DataStream → DataStream]
Rebalancing 采用轮询的方式将数据进行分区,其适合于存在数据倾斜的场景下,通过 rebalance 方法进行实现:
dataStream.rebalance();
3.3 Rescaling [DataStream → DataStream]
当采用 Rebalancing 进行分区平衡时,其实现的是全局性的负载均衡,数据会通过网络传输到其他节点上并完成分区数据的均衡。 而 Rescaling 则是低配版本的 rebalance,它不需要额外的网络开销,它只会对上下游的算子之间进行重新均衡,通过 rescale 方法进行实现:
dataStream.rescale();
3.4 Broadcasting [DataStream → DataStream]
将数据分发到所有分区上。通常用于小数据集与大数据集进行关联的情况下,此时可以将小数据集广播到所有分区上,避免频繁的跨分区关联,通过 broadcast 方法进行实现:
dataStream.broadcast();
4、任务链和资源组
任务链和资源组 ( Task chaining and resource groups ) 也是 Flink 提供的底层 API,用于控制任务链和资源分配。默认情况下,如果操作允许 (例如相邻的两次 map 操作) ,则 Flink 会尝试将它们在同一个线程内进行,从而可以获取更好的性能。但是 Flink 也允许用户自己来控制这些行为,这就是任务链和资源组 API:
4.1 startNewChain
startNewChain 用于基于当前 operation 开启一个新的任务链。如下所示,基于第一个 map 开启一个新的任务链,此时前一个 map 和 后一个 map 将处于同一个新的任务链中,但它们与 filter 操作则分别处于不同的任务链中:
someStream.filter(...).map(...).startNewChain().map(...);
4.2 disableChaining
disableChaining 操作用于禁止将其他操作与当前操作放置于同一个任务链中,示例如下:
someStream.map(...).disableChaining();
4.3 slotSharingGroup
slot 是任务管理器 (TaskManager) 所拥有资源的固定子集,每个操作 (operation) 的子任务 (sub task) 都需要获取 slot 来执行计算,但每个操作所需要资源的大小都是不相同的,为了更好地利用资源,Flink 允许不同操作的子任务被部署到同一 slot 中。slotSharingGroup 用于设置操作的 slot 共享组 (slot sharing group) ,Flink 会将具有相同 slot 共享组的操作放到同一个 slot 中 。示例如下:
someStream.filter(...).slotSharingGroup("slotSharingGroupName");
