

- 论文题目:Asynchronous Methods for Deep Reinforcement Learning

所解决的问题?
在强化学习算法中agent所观测到的data是 non-stationary和strongly correlated的。通过设置memory的方式可以 reduces non-stationarity and decorrelates updates,但是会限制这些方法去使用off-policy的RL算法,并且会增加额外的运算。
作者主要是通过多个智能体并行地采样数据来decorrelates the agents’ data in to a more stationary process. 并且可以使用on-policy的策略。
背景
在此之前也有一些研究,比如The General Reinforcement Learning Architecture (Gorila),actor与环境互动采样(多台电脑),将数据放入replay memory中,learner从replay memory中获取数据,并计算DQN算法所定义的Loss梯度,但是这个梯度并不用于更新learner的参数,梯度被asynchronously sent to a central parameter server which updates a central copy of the model. The updated policy parameters are sent to the actor-learners at fixed intervals(learner的target拿central parameter server所更新的参数更新learner).
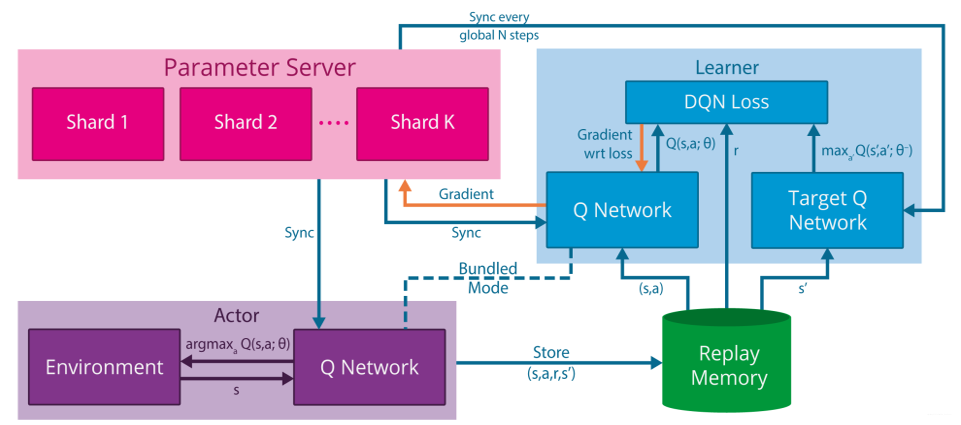
还有一些研究将Map Reduce framework引入用于加快矩阵运算,(并不是加快采样)。也还有一些工作是learner之间通过通讯共享一些参数信息。
所采用的方法?
作者所使用的方法与Gorila框架的方法类似,但是并没有用多台机器和参数服务器(parameter server),而是使用一个多线程的GPU在单台机器上运行,每一个线程上都有一个learner,它们采样的数据就更加丰富了,多个learner online更新最后汇总梯度,其实也是相当于切断了数据之间的关联性。因此作者没有使用replay memory而是对每个learner使用不同的exploration policy,因此这种方法也可以使用on-policy的强化学习算法,比如sarsa这种。将其用于Q-Learning算法的话,可以得到如下单线程learner伪代码:

对于actor-critic框架,单线程learner伪代码如下所示:

取得的效果?
所需的计算资源更小,使用一个multi-core CPU就可以进行训练。compares the learning speed of the DQN algorithm trained on an Nvidia K40 GPU with the asynchronous methods trained using 16 CPU cores on five Atari 2600 games.
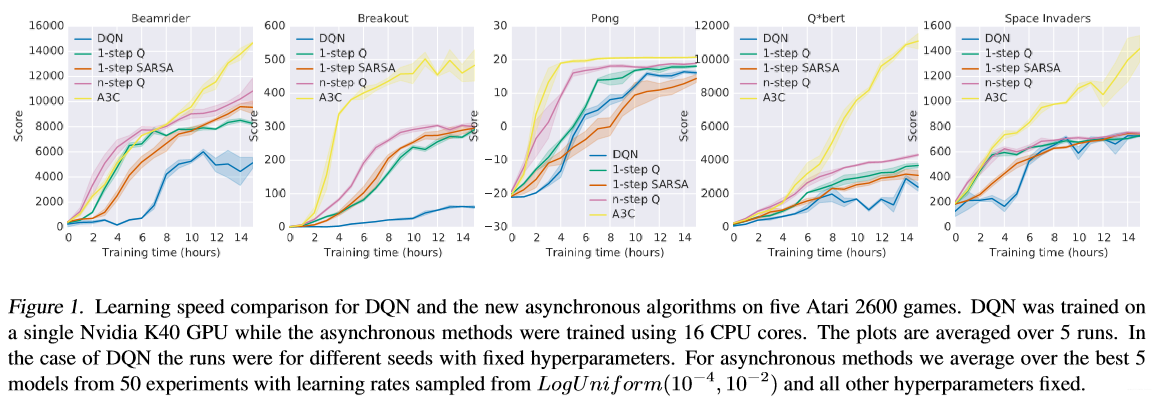
还有一些什么鲁棒性地分析可以参考原文,这里就不说了,在讨论部分作者强调了,并不是说experience replace不好,把其引入进来可能效果会改进采样效率,可能会使得效果更好。
所出版信息?作者信息?
这篇文章是ICML2016上面的一篇文章。第一作者Volodymyr Mnih是Toronto大学的机器学习博士,师从Geoffrey Hinton,同时也是谷歌DeepMind的研究员。硕士读的Alberta大学,师从Csaba Szepesvari。

参考链接
- The General Reinforcement Learning Architecture (Gorila) of (
Nairetal.,2015) performs asynchronous training of reinforcement learning agents in a distributed setting. The gradients are asynchronously sent to a central parameter server which updates a central copy of the model. The updated policy parameters are sent to the actor-learners at fixed intervals.
- 参考文献:Nair, Arun, Srinivasan, Praveen, Blackwell, Sam, Alcicek, Cagdas, Fearon, Rory, Maria, Alessandro De, Panneershelvam, Vedavyas, Suleyman, Mustafa, Beattie, Charles, Petersen, Stig, Legg, Shane, Mnih, Volodymyr, Kavukcuoglu, Koray, and Silver, David. Massively parallel methods for deep reinforcement learning. In ICML Deep Learning Workshop. 2015.
- We also note that a similar way of parallelizing DQN was proposed by (
Chavez et al., 2015).
- 参考文献:Chavez, Kevin, Ong, Hao Yi, and Hong, Augustus. Distributed deep q-learning. Technical report, Stanford University, June 2015.
- In earlier work, (
Li & Schuurmans, 2011) applied the Map Reduce framework to parallelizing batch reinforcement learning methods with linear function approximation. Parallelism was used to speed up large matrix operations but not to parallelize the collection of experience or stabilize learning.
- 参考文献:Li, Yuxi and Schuurmans, Dale. Mapreduce for parallel reinforcement learning. In Recent Advances in Reinforcement Learning - 9th European Workshop, EWRL 2011, Athens, Greece, September 9-11, 2011, Revised Selected Papers, pp. 309–320, 2011.
- (
Grounds & Kudenko, 2008) proposed a parallel version of the Sarsa algorithm that uses multiple separate actor-learners to accelerate training. Each actor learner learns separately and periodically sends updates to weights that have changed significantly to the other learners using peer-to-peer communication.
- 参考文献:Grounds, Matthew and Kudenko, Daniel. Parallel reinforcement learning with linear function approximation. In Proceedings of the 5th, 6th and 7th European Conference on Adaptive and Learning Agents and Multi-agent Systems: Adaptation and Multi-agent Learning, pp. 60– 74. Springer-Verlag, 2008.
扩展阅读
基于value estimation的critic方法。广泛应用于各种领域,但有一些缺点使它的应用受到局限。如 :
- 难以应用到随机型策略(
stochastic policy)和连续的动作空间。 value function的微小变化会引起策略变化巨大,从而使训练无法收敛。尤其是引入函数近似(function approximation,FA)后,虽然算法泛化能力提高了,但也引入了bias,从而使得训练的收敛性更加难以保证。
而基于actor方法通过将策略参数化,从而直接学习策略。这样做的好处是与前者相比拥有更好的收敛性,以及适用于高维连续动作空间及stochastic policy。但缺点包括梯度估计variance比较高,且容易收敛到非最优解。另外因为每次梯度的估计不依赖以往的估计,意味着无法充分利用老的信息。
但对于AC算法来说其架构可以追溯到三、四十年前。 最早由Witten在1977年提出了类似AC算法的方法,然后Barto, Sutton和Anderson等大牛在1983年左右引入了actor-critic架构。但由于AC算法的研究难度和一些历史偶然因素,之后学界开始将研究重点转向value-based方法。之后的一段时间里value-based方法和policy-based方法都有了蓬勃的发展。前者比较典型的有TD系的方法。经典的Sarsa, Q-learning等都属于此列;后者比如经典的REINFORCE算法。之后AC算法结合了两者的发展红利,其理论和实践再次有了长足的发展。直到深度学习(Deep learning, DL)时代,AC方法结合了DNN作为FA,产生了化学反应,出现了DDPG,A3C这样一批先进算法,以及其它基于它们的一些改进和变体。可以看到,这是一个先分后合的圆满故事。
我的微信公众号名称:深度学习与先进智能决策 微信公众号ID:MultiAgent1024 公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!
