


本文首发于 个人博客
GCD全称 Grand Central Dispatch,是Apple开发的一个多核编程解决办法。该方法在Mac OSX 10.6 雪豹 中首次推出,随后引入到IOS4.0中。GCD是一个替代NSThread,NSOperationQueue等技术的方案。
GCD初探
// 1.队列
dispatch_queue_t queue = dispatch_queue_create("Typeco", DISPATCH_QUEUE_CONCURRENT);
// 2.任务:无参数,无返回值
void(^block)(void) = ^{
NSLog(@"这是要执行的任务");
};
// 3.函数
dispatch_async(queue, block);
这里为了区分开任务和函数,我把block单独拆出来,这样对GCD的认识会更简单直观,总结一下就是:
GCD 就是将指定的任务(block)添加到指定的队列(queue),然后指定 dispatch 函数执行。任务的执行遵循队列的FIFO原则:先进先出。
队列

-
串行队列(Serial)
队列里的任务一个一个执行,一个任务执行完毕,才执行下一个任务。自定义串行队列如下:
dispatch_queue_t queue = dispatch_queue_create("Typeco", DISPATCH_QUEUE_SERIAL);其中第一个参数label是用来标识queue的字符串,第二个参数标识队列的类型,这里我们要创建串行队列:
DISPATCH_QUEUE_SERIAL。#define DISPATCH_QUEUE_SERIAL NULL
PS : 串行队列的第二个参数我们传NULL的效果是一样的。
-
并发队列(Concurrent)
允许多个任务并行(同时)执行,但是执行任务的顺序是随机,具体要看CPU的调度情况,这块后续会说到。
dispatch_queue_t queue = dispatch_queue_create("Typeco", DISPATCH_QUEUE_CONCURRENT);这里同上,不过第二个参数我们选择
DISPATCH_QUEUE_CONCURRENT -
系统队列
dispatch_get_main_queue()主队列是应用 程序启动时(main函数之前),系统自动创建的唯一一个串行队列,并且该队列与主线程绑定。dispatch_get_global_queue(0,0)全局并发队列,这里通常我们没有特别需求的情况下,默认都传0即可。全局并发队列只可获取而不能创建。
知道了队列的含义,我们就了解了任务加到队列中是如何执行的,接下来我们就要看函数是如何影响队列任务执行的。
函数
-
同步函数
dispatch_sync()- 必须等待当前语句执行完毕,才会执行下一条语句
- 不会开启线程,在当前线程执行block任务
- 其执行顺序依旧遵循当前队列的FIFO原则
-
异步函数
dispatch_async()- 不用等待当前语句执行完毕,就可以执行下一条语句
- 会开启线程执行block的任务
- 异步是多线程的代名词
-
线程和队列的关系
具体测试可前往 Demo 进行下载!
区别 串行 并发 主队列 同步 1.不会开启线程,在当前线程执行任务
2.任务一个接一个执行
3.会产生堵塞1.不会开启线程,在当前线程执行任务
2.任务一个接一个执行1.死锁卡住不执行 异步 1.开启一条新线程
2.任务一个接一个执行1.开启线程,在当前线程执行任务
2.任务异步执行,没有顺序,cpu调度有关1.不会开启新线程,依旧在主线程串行执行任务 由此可见,线程和队列并没有直接联系。
队列和函数的底层实现
首先可以去 GCD源码 进行下载查看。
队列的创建
我们大概分析一下队列是如何创建的,首先dispatch_queue_create的第一个参数是一个字符串为了标识queue,第二个参数代表的是串行还是并发,那么我们研究的重点就放在第二个参数上:
/*
初始方法,依次会调用下方核心代码
*/
dispatch_queue_create("sync_serial", DISPATCH_QUEUE_SERIAL);
/*
主要看下面的方法实现
此处dqa即是上面的 DISPATCH_QUEUE_SERIAL
*/
_dispatch_lane_create_with_target(const char *label, dispatch_queue_attr_t dqa,
dispatch_queue_t tq, bool legacy)
// 此处省略大量代码...
// 开辟内存 - 生成响应的对象 queue
dispatch_lane_t dq = _dispatch_object_alloc(vtable,
sizeof(struct dispatch_lane_s));
/*
构造方法,此处有关键点,如果是dqai_concurrent 那么队列宽度 DISPATCH_QUEUE_WIDTH_MAX 否则为 1
也就是说串行队列宽度为1,并发没有限制
*/
_dispatch_queue_init(dq, dqf, dqai.dqai_concurrent ?
DISPATCH_QUEUE_WIDTH_MAX : 1, DISPATCH_QUEUE_ROLE_INNER |
(dqai.dqai_inactive ? DISPATCH_QUEUE_INACTIVE : 0));
// 标签
dq->dq_label = label;
// 优先级
dq->dq_priority = _dispatch_priority_make((dispatch_qos_t)dqai.dqai_qos,
dqai.dqai_relpri);
/*
此处对queue进行保留,api里有描述如果非ARC 我们创建完之后要调用 dispatch_release
*/
_dispatch_retain(tq);
return dq;
以上只是大概分析一下 dispatch_queue_create 是如何创建队列以及队列是如何区分串行和并发的,相关细节还请下载源码进行阅读。
信号量
研究信号量无非就是关注其三个方法:
dispatch_semaphore_create
dispatch_semaphore_t
dispatch_semaphore_create(long value)
{
dispatch_semaphore_t dsema;
// If the internal value is negative, then the absolute of the value is
// equal to the number of waiting threads. Therefore it is bogus to
// initialize the semaphore with a negative value.
if (value < 0) {
return DISPATCH_BAD_INPUT;
}
dsema = _dispatch_object_alloc(DISPATCH_VTABLE(semaphore),
sizeof(struct dispatch_semaphore_s));
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
dsema->do_targetq = _dispatch_get_default_queue(false);
dsema->dsema_value = value;
_dispatch_sema4_init(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
dsema->dsema_orig = value;
return dsema;
}
其实就是一个初始化dispatch_semaphore_t并赋值的过程,其赋值主要在**dema_value**上,记住这个字段,可能我们在后面的分析中要用到.
dispatch_semaphore_signal
long
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
long value = os_atomic_inc2o(dsema, dsema_value, release);
if (likely(value > 0)) {
return 0;
}
if (unlikely(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_semaphore_signal()");
}
return _dispatch_semaphore_signal_slow(dsema);
}
os_atomic_inc2o---->os_atomic_add2o(p, f, 1, m)---->os_atomic_add(&(p)->f, (v), m)---->_os_atomic_c11_op((p), (v), m, add, +)----> 得出结果deem_value+1,也就是说上述os_atomic_inc2o返回的结果是在之前value的基础上进行+1,如果>0立即返回0
dispatch_semaphore_wait
long
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
// value++
long value = os_atomic_dec2o(dsema, dsema_value, acquire);
if (likely(value >= 0)) {
return 0;
}
return _dispatch_semaphore_wait_slow(dsema, timeout);
}
os_atomic_dec2o的原理跟上面那个os_atomic_inc2o差不多,只不过这次运算符是 - 号,所以总结一下就是,对信号量进行减1操作,如果大于等于0返回0
那么纵观这两个方法给我们看到的仅仅是对一个数字(信号量)进行加减的操作,那么它在底层是如何影响我们的线程的呢?
do {
_dispatch_trace_runtime_event(worker_unpark, dq, 0);
_dispatch_root_queue_drain(dq, pri, DISPATCH_INVOKE_REDIRECTING_DRAIN);
_dispatch_reset_priority_and_voucher(pp, NULL);
_dispatch_trace_runtime_event(worker_park, NULL, 0);
} while (dispatch_semaphore_wait(&pqc->dpq_thread_mediator,
dispatch_time(0, timeout)) == 0);
在queue.c文件中,找到了上述代码,其实就是一个do..while 循环,只要wait返回0就一直让queue处于一个推迟执行(park)的状态,结合我们上述wait方法的理解可以得出,只要信号量为>=0 当前队列继续FIFO,否则一直等待直到wait返回0,当执行signal方法之后信号量会执行+1操作,这个时候就会打破上述循环。
综上我们通常这么使用信号量:
- (void)demo {
dispatch_semaphore_t sema = dispatch_semaphore_create(1);
dispatch_semaphore_wait(sema, DISPATCH_TIME_FOREVER);
dispatch_async(dispatch_get_global_queue(0, 0), ^{
// 耗时操作,异步操作
sleep(5);
dispatch_semaphore_signal(sema);
});
}
初始化1的信号量,代表了单线程一次只能有一个线程访问,比如当前我们线程1已经执行了wait方法,这个时候信号量为0,当另外一个线程2来访问这个异步耗时操作时候就会处于上述的do...while 循环等待中,直到线程1执行signal 对信号量执行+1操作,这个时候才会打破这个循环让线程2能访问该操作。
这个是为了解决防止多线程同时访问同一个资源造成的安全问题,我们还可以使用信号量达到barrier (栅栏)的作用:
- (void)demo {
dispatch_semaphore_t sema = dispatch_semaphore_create(0);
dispatch_async(dispatch_get_global_queue(0, 0), ^{
// 执行方法1
NSLog(@"执行方法1");
sleep(5);
dispatch_semaphore_signal(sema);
});
dispatch_semaphore_wait(sema, DISPATCH_TIME_FOREVER);
dispatch_async(dispatch_get_global_queue(0, 0), ^{
//执行方法2
NSLog(@"执行方法2");
});
}
此处唯一的区别的就是初始化的时候赋值为0,默认wait等待,直到异步线程signal,才能越过wait执行后续的任务,达到一个栅栏的效果。
调度组
以下都是基于libdispatch源码分析的结果: 源码参考,源码部分内容比较多,详细代码请下载查看,这里尽量少粘贴代码,力求用流程图来展示大概过程:
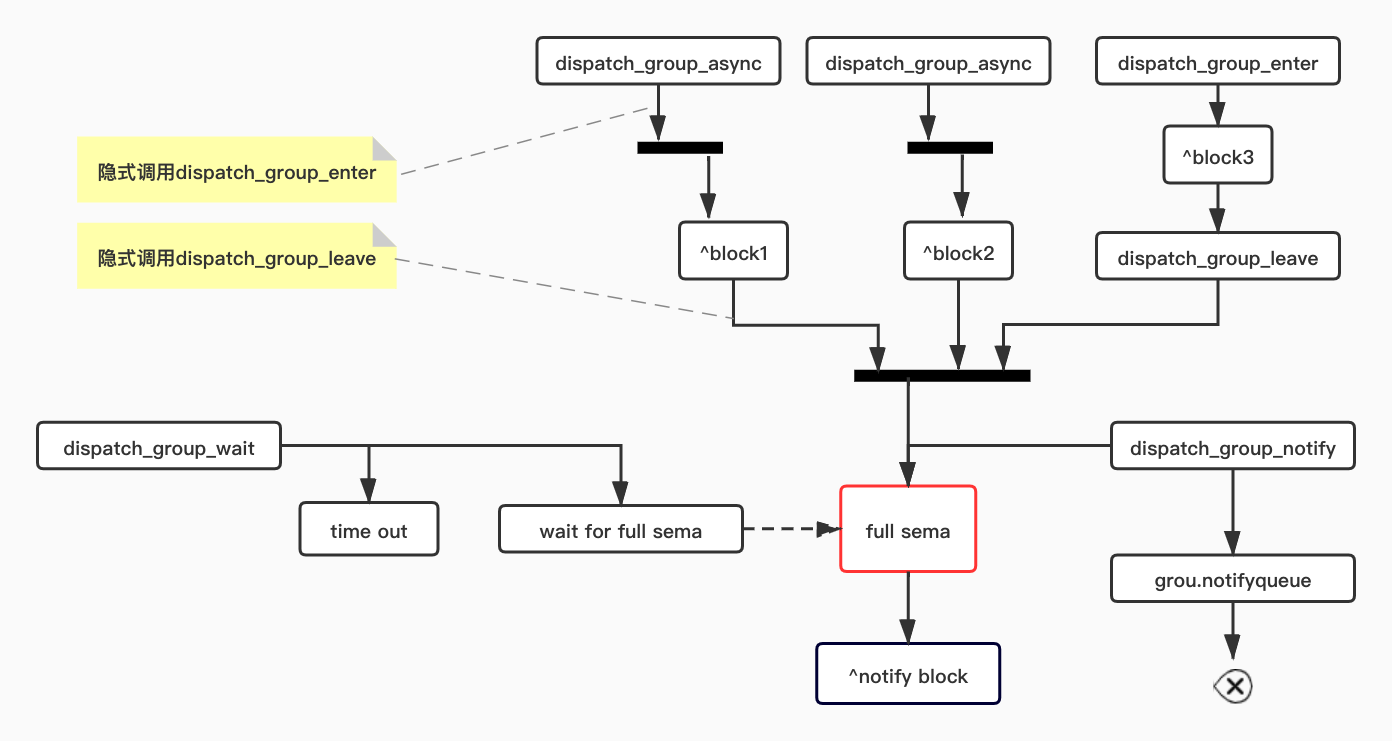
dispatch_group 相关代码都在dispatch_semaphore.c模块中,可见dispatch_group是一个基于信号量的同步机制,核心功能主要是下面几个函数:
- dispatch_group_enter
- dispatch_group_leave
- dispatch_group_wait
- dispatch_group_async
- dispatch_group_notify
图中共有4组控制流:
- 上方有两条并行的async,异步执行并且内部会隐式调用enter和leave方法
- 右上角是普通的enter和leave
- 左下角是wait控制,使用了阻塞等待方式,一致等到信号符合
- 右下角的notify有两个分支,一致是判断信号符合直接唤醒wait进行处理notify的block,如果条件不满足,则见notify的block放入group对应的queue中等到将来满足信号量的时候来触发执行。
最好就是谁来唤醒notify,所有的async和普通的方式都会走enter和leave,所以信号的判断就是enter和leave的配对,正如api所述,enter和leave要成对出现,如果使用async则不用担心,因为其内部帮你成对的实现了:
void
dispatch_group_async(dispatch_group_t group, dispatch_queue_t queue, dispatch_block_t block)
{
dispatch_retain(group);
dispatch_group_enter(group);
dispatch_async(queue, ^{
block();
dispatch_group_leave(group);
dispatch_release(group);
});
}
所以每条控制流执行leave的时候都要检查信号量是否满足,如果满足则执行notify,否则等待,既然关键是leave方法的执行触发notify,所以就可以重点看看leave的实现:
void
dispatch_group_leave(dispatch_group_t dg)
{
// The value is incremented on a 64bits wide atomic so that the carry for
// the -1 -> 0 transition increments the generation atomically.
uint64_t new_state, old_state = os_atomic_add_orig2o(dg, dg_state,
DISPATCH_GROUP_VALUE_INTERVAL, release);
uint32_t old_value = (uint32_t)(old_state & DISPATCH_GROUP_VALUE_MASK);
if (unlikely(old_value == DISPATCH_GROUP_VALUE_1)) {
old_state += DISPATCH_GROUP_VALUE_INTERVAL;
do {
new_state = old_state;
if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {
new_state &= ~DISPATCH_GROUP_HAS_WAITERS;
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
} else {
// If the group was entered again since the atomic_add above,
// we can't clear the waiters bit anymore as we don't know for
// which generation the waiters are for
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
}
if (old_state == new_state) break;
} while (unlikely(!os_atomic_cmpxchgv2o(dg, dg_state,
old_state, new_state, &old_state, relaxed)));
return _dispatch_group_wake(dg, old_state, true);
}
if (unlikely(old_value == 0)) {
DISPATCH_CLIENT_CRASH((uintptr_t)old_value,
"Unbalanced call to dispatch_group_leave()");
}
}
其中有一个do...while循环,每次对状态进行比对,直到状态符合调用wake方法唤醒group。
调度组使用
-
(异步请求1 + 异步请求2) ==> 异步请求3,请求3依赖请求1和请求2的返回
dispatch_group_t group = dispatch_group_create();
dispatch_group_async(group, dispatch_get_global_queue(0, 0), ^{
NSLog(@"异步请求1");
});
dispatch_group_async(group, dispatch_get_global_queue(0, 0), ^{
sleep(3);
NSLog(@"异步请求2");
});
dispatch_group_notify(group, dispatch_get_global_queue(0, 0), ^{
NSLog(@"1和2执行完了异步请求3");
});
dispatch_group_async(group, dispatch_get_global_queue(0, 0), ^{
NSLog(@"异步请求4");
});GCD_Demo[19428:6087378] 异步请求1
GCD_Demo[19428:6087375] 异步请求4
GCD_Demo[19428:6087377] 异步请求2
GCD_Demo[19428:6087377] 1和2执行完了异步请求3
这里我故意在notify后面多加了个4,发现notify这个是不分前后顺序的。
-
enter + leave
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_group_enter(group);
dispatch_async(queue, ^{
NSLog(@"异步请求1");
dispatch_group_leave(group);
});
dispatch_group_enter(group);
dispatch_async(queue, ^{
sleep(3);
NSLog(@"异步请求2");
dispatch_group_leave(group);
});
dispatch_group_notify(group, dispatch_get_global_queue(0, 0), ^{
NSLog(@"1和2执行完了异步请求3");
});达到的效果是一样的,只不过这里没有用到group_async 是一样能达到相应目的。
至此GCD分析告一段落,欢迎点评交流。
