

背景
在 2 月10 号下午大概 1 点半左右,收到用户方反馈,发现日志 kafka 集群 A 主题 的 34 分区选举不了 leader,导致某些消息发送到该分区时,会报如下 no leader 的错误信息:
In the middle of a leadership election, there is currently no leader for this partition and hence it is unavailable for writes.
接下来运维在 kafka-manager 查不到 broker0 节点了处于假死状态,但是进程依然还在,重启了好久没见反应,然后通过 kill -9 命令杀死节点进程后,接着重启失败了,导致了如下问题:
由于 A 主题 34 分区的 leader 副本在 broker0,另外一个副本由于速度跟不上 leader,已被踢出 ISR,0.11 版本的 kafka 的 unclean.leader.election.enable 参数默认为 false,表示分区不可在 ISR 以外的副本选举 leader,导致了 A 主题发送消息持续报 34 分区 leader 不存在的错误,且该分区还未消费的消息不能继续消费了。
Kafka 日志分析
查看了 KafkaServer.log 日志,发现 Kafka 重启过程中,产生了大量如下日志:
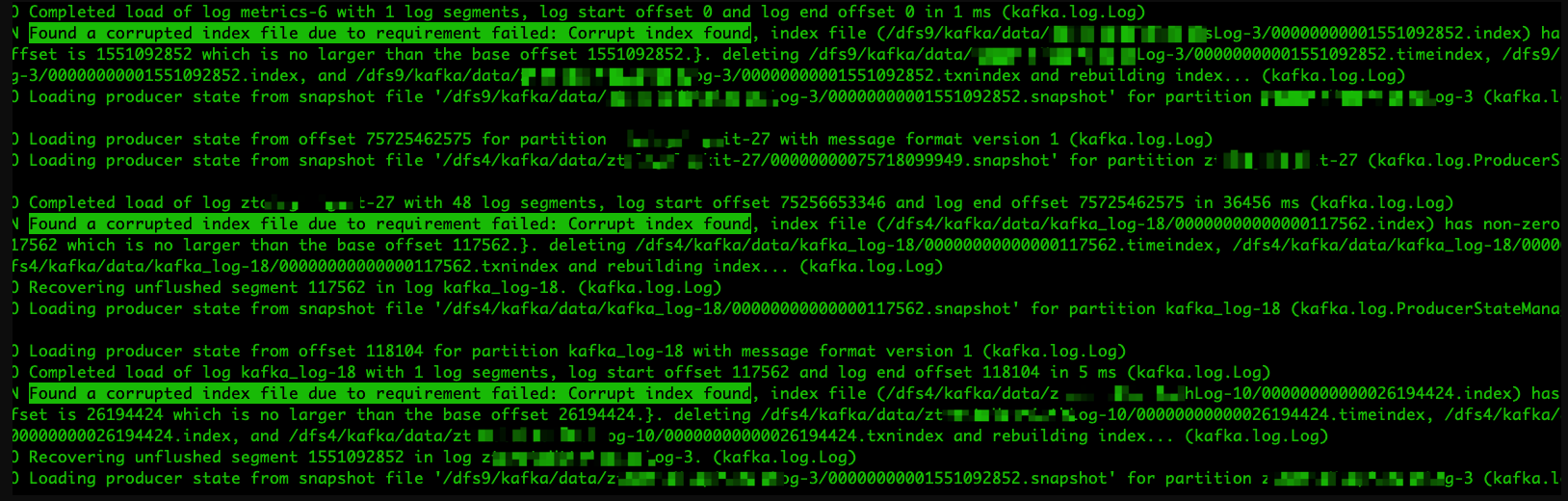
发现大量主题索引文件损坏并且重建索引文件的警告信息,定位到源码处:
kafka.log.OffsetIndex#sanityCheck
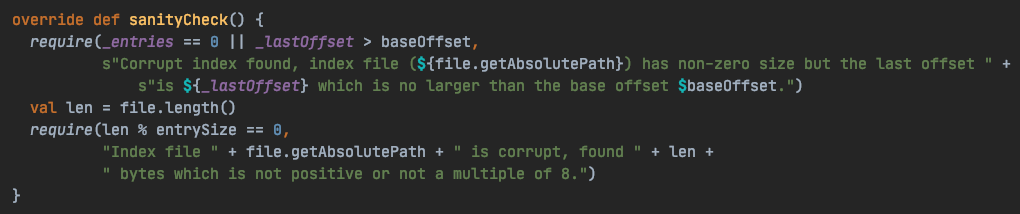
按我自己的理解描述下:
Kafka 在启动的时候,会检查 kafka 是否为 cleanshutdown,判断依据为 ${log.dirs} 目录中是否存在 .kafka_cleanshutDown 的文件,如果非正常退出就没有这个文件,接着就需要 recover log 处理,在处理中会调用 sanityCheck() 方法用于检验每个 log sement 的 index 文件,确保索引文件的完整性:
- entries:由于 kafka 的索引文件是一个稀疏索引,并不会将每条消息的位置都保存到 .index 文件中,因此引入了 entry 模式,即每一批消息只记录一个位置,因此索引文件的 entries = mmap.position / entrySize;
- lastOffset:最后一块 entry 的位移,即 lastOffset = lastEntry.offset;
- baseOffset:指的是索引文件的基偏移量,即索引文件名称的那个数字。
索引文件与日志文件对应关系图如下:

判断索引文件是否损坏的依据是:
_entries == 0 || _lastOffset > baseOffset = false // 损坏
_entries == 0 || _lastOffset > baseOffset = true // 正常
这个判断逻辑我的理解是:
entries 索引块等于零时,意味着索引没有内容,此时可以认为索引文件是没有损坏的;当 entries 索引块不等于 0,就需要判断索引文件最后偏移量是否大于索引文件的基偏移量,如果不大于,则说明索引文件被损坏了,需要用重新构建。
那为什么会出现这种情况呢?
我在相关 issue 中似乎找到了一些答案:

issues.apache.org/jira/browse…
issues.apache.org/jira/browse…
总的来说,非正常退出在旧版本似乎会可能发生这个问题?
有意思的来了,导致开机不了并不是这个问题导致的,因为这个问题已经在后续版本修复了,从日志可看出,它会将损坏的日志文件删除并重建,我们接下来继续看导致重启不了的错误信息:
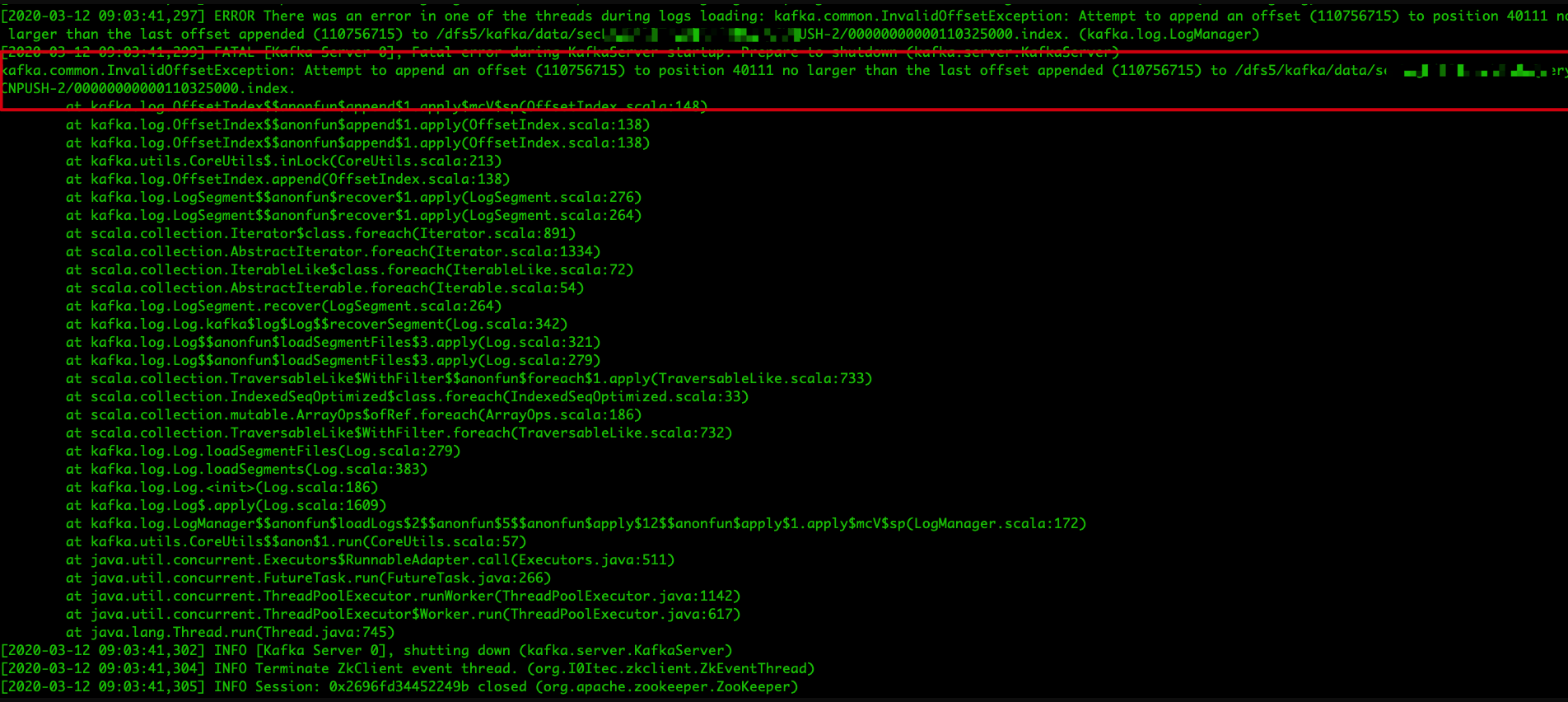
问题就出在这里,在删除并重建索引过程中,就可能出现如上问题,在 issues.apache.org 网站上有很多关于这个 bug 的描述,我这里贴两个出来:
issues.apache.org/jira/browse…
issues.apache.org/jira/browse…
这些 bug 很隐晦,而且非常难复现,既然后续版本不存在该问题,当务之急还是升级 Kafka 版本,后续等我熟悉 scala 后,再继续研究下源码,细节一定是会在源码中呈现。
解决思路分析
针对背景两个问题,矛盾点都是因为 broker0 重启失败导致的,那么我们要么把 broker0 启动成功,才能恢复 A 主题 34 分区。
由于日志和索引文件的原因一直启动不起来,我们只需要将损坏的日志和索引文件删除并重启即可。
但如果出现 34 分区的日志索引文件也损坏的情况下,就会丢失该分区下未消费的数据,原因如下:
此时 34 分区的 leader 还处在 broker0 中,由于 broker0 挂掉了且 34 分区 isr 只有 leader,导致 34 分区不可用,在这种情况下,假设你将 broker0 中 leader 的数据清空,重启后 Kafka 依然会将 broker0 上的副本作为 leader,那么就需要以 leader 的偏移量为准,而这时 leader 的数据清空了,只能将 follower 的数据强行截断为 0,且不大于 leader 的偏移量。
这似乎不太合理,这时候是不是可以提供一个操作的可能:
在分区不可用时,用户可以手动设置分区内任意一个副本作为 leader?
后面我会单独一篇文章对这个问题进行分析。
后续集群的优化
- 制定一个升级方案,将集群升级到 2.2 版本;
- 每个节点的服务器将 systemd 的默认超时值为 600 秒,因为我发现运维在故障当天关闭 33 节点时长时间没反应,才会使用 kill -9 命令强制关闭。但据我了解关闭一个 Kafka 服务器时,Kafka 需要做很多相关工作,这个过程可能会存在相当一段时间,而 systemd 的默认超时值为 90 秒即可让进程停止,那相当于非正常退出了。
- 将 broker 参数 unclean.leader.election.enable 设置为 true(确保分区可从非 ISR 中选举 leader);
- 将 broker 参数 default.replication.factor 设置为 3(提高高可用,但会增大集群的存储压力,可后续讨论);
- 将 broker 参数 min.insync.replicas 设置为 2(这么做可确保 ISR 同时有两个,但是这么做会造成性能损失,是否有必要?因为我们已经将 unclean.leader.election.enable 设置为 true 了);
- 发送端发送 acks=1(确保发送时有一个副本是同步成功的,但这个是否有必要,因为可能会造成性能损失)。
作者简介
张乘辉,目前就职于中通科技信息中心技术平台部,主要负责中通消息平台与全链路压测项目的研发,热爱分享技术,微信公众号「后端进阶」作者,技术博客(objcoding.com/)博主,Seata Contributor,GitHub ID:objcoding。

