

在iOS开发中如果我们想对一个对象进行安全的访问操作,为了避免多线程访问造成的错误,首先我们想到的是使用NSLock进行加锁操作.有这样一个类:
ThreadSafeQueue.m
@interface ThreadSafeQueue()
@property (nonatomic, assign) NSInteger sum;
@property (nonatomic, strong) NSLock *lock;
@end
@implementation ThreadSafeQueue
- (instancetype)init
{
self = [super init];
if (self) {
_lock = [[NSLock alloc] init];
}
return self;
}
- (void)add:(NSInteger)num {
[_lock lock];
_sum += num;
[_lock unlock];
}
这样可以避免多线程访问问题,另外我们也经常使用@synchronized关键字来简化这样的操作,例如:
- (void)add:(NSInteger)num {
@synchronized (self) {
_sum += num;
}
}
这样一来就省去我们自己创建锁的对象了, 而且使用了系统功能,更为高效可靠。那么问题来了, @synchronized方法具体是怎么实现的呢?
我们可以使用Clang工具将Objective-C代码编译成C++代码来看一下系统是如何实现的。
$ clang -rewrite-objc ThreadSafeQueue.m
执行完后在当前目录下会生成一个ThreadSafeQueue.cpp文件, 打开文件找到add函数的实现代码:
ThreadSafeQueue.cpp
static void _I_ThreadSafeQueue_push_(ThreadSafeQueue * self, SEL _cmd, id element)
{
{
id _rethrow = 0;
id _sync_obj = (id)element;
objc_sync_enter(_sync_obj);
try {
struct _SYNC_EXIT {
_SYNC_EXIT(id arg) : sync_exit(arg) {}
~_SYNC_EXIT() {
objc_sync_exit(sync_exit);
}
id sync_exit;
} _sync_exit(_sync_obj);
((void (*)(id, SEL, ObjectType))(void *)objc_msgSend)((id)(*(NSMutableArray **)((char *)self + OBJC_IVAR_$_ThreadSafeQueue$_elements)), sel_registerName("addObject:"), (id)element);
}
catch (id e) {
_rethrow = e;
}
{ struct _FIN {
_FIN(id reth) : rethrow(reth) {}
~_FIN() {
if (rethrow) objc_exception_throw(rethrow);
}
id rethrow;
} _fin_force_rethow(_rethrow);
}
}
}
从转换而来的C++代码来看, 可以看到编译器将@synchronized转换成使用Runtime代码objc_sync_enter和objc_sync_exit来实现加锁的。
我们可以在这里来查看内部实现. 下面我们深入runtime代码学习一下:
objc-sync.mm
// Begin synchronizing on 'obj'.
// Allocates recursive mutex associated with 'obj' if needed.
// Returns OBJC_SYNC_SUCCESS once lock is acquired.
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, ACQUIRE);
assert(data);
data->mutex.lock();
} else {
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
}
return result;
}
objc_sync_enter方法做了一件事情,就是根据参数进行加锁。那么它是如何进行加锁的呢? 我们继续往下看。
这里通过id2data(id object, enum usage why)方法来获取SyncData一个节点数据, 方法里根据obj参数来查找Cache对象,当然没有命中cache的时候会创建并存cache,接下来看具体查找缓存的过程。
objc-sync.mm
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);
SyncData* result = NULL;
#if SUPPORT_DIRECT_THREAD_KEYS
// Check per-thread single-entry fast cache for matching object
bool fastCacheOccupied = NO;
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
if (data) {
fastCacheOccupied = YES;
if (data->object == object) {
// Found a match in fast cache.
uintptr_t lockCount;
result = data;
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
if (result->threadCount <= 0 || lockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
switch(why) {
case ACQUIRE: {
lockCount++;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
break;
}
case RELEASE:
lockCount--;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
if (lockCount == 0) {
// remove from fast cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
#endif
// Check per-thread cache of already-owned locks for matching object
SyncCache *cache = fetch_cache(NO);
if (cache) {
unsigned int i;
for (i = 0; i < cache->used; i++) {
SyncCacheItem *item = &cache->list[i];
if (item->data->object != object) continue;
// Found a match.
result = item->data;
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) {
case ACQUIRE:
item->lockCount++;
break;
case RELEASE:
item->lockCount--;
if (item->lockCount == 0) {
// remove from per-thread cache
cache->list[i] = cache->list[--cache->used];
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
// Thread cache didn't find anything.
// Walk in-use list looking for matching object
// Spinlock prevents multiple threads from creating multiple
// locks for the same new object.
// We could keep the nodes in some hash table if we find that there are
// more than 20 or so distinct locks active, but we don't do that now.
lockp->lock();
{
SyncData* p;
SyncData* firstUnused = NULL;
for (p = *listp; p != NULL; p = p->nextData) {
if ( p->object == object ) {
result = p;
// atomic because may collide with concurrent RELEASE
OSAtomicIncrement32Barrier(&result->threadCount);
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object
if ( (why == RELEASE) || (why == CHECK) )
goto done;
// an unused one was found, use it
if ( firstUnused != NULL ) {
result = firstUnused;
result->object = (objc_object *)object;
result->threadCount = 1;
goto done;
}
}
// malloc a new SyncData and add to list.
// XXX calling malloc with a global lock held is bad practice,
// might be worth releasing the lock, mallocing, and searching again.
// But since we never free these guys we won't be stuck in malloc very often.
result = (SyncData*)calloc(sizeof(SyncData), 1);
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t();
result->nextData = *listp;
*listp = result;
done:
lockp->unlock();
if (result) {
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) {
// Probably some thread is incorrectly exiting
// while the object is held by another thread.
return nil;
}
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
if (result->object != object) _objc_fatal("id2data is buggy");
#if SUPPORT_DIRECT_THREAD_KEYS
if (!fastCacheOccupied) {
// Save in fast thread cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);
} else
#endif
{
// Save in thread cache
if (!cache) cache = fetch_cache(YES);
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
}
objc-sync.mm
typedef struct SyncData {
struct SyncData* nextData;
DisguisedPtr<objc_object> object;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;
} SyncData;
typedef struct {
SyncData *data;
unsigned int lockCount; // number of times THIS THREAD locked this block
} SyncCacheItem;
typedef struct SyncCache {
unsigned int allocated;
unsigned int used;
SyncCacheItem list[0];
} SyncCache;
/*
Fast cache: two fixed pthread keys store a single SyncCacheItem.
This avoids malloc of the SyncCache for threads that only synchronize
a single object at a time.
SYNC_DATA_DIRECT_KEY == SyncCacheItem.data
SYNC_COUNT_DIRECT_KEY == SyncCacheItem.lockCount
*/
struct SyncList {
SyncData *data;
spinlock_t lock;
SyncList() : data(nil) { }
};
// Use multiple parallel lists to decrease contention among unrelated objects.
#define LOCK_FOR_OBJ(obj) sDataLists[obj].lock
#define LIST_FOR_OBJ(obj) sDataLists[obj].data
static StripedMap<SyncList> sDataLists;
先来看一下涉及到的数据结构
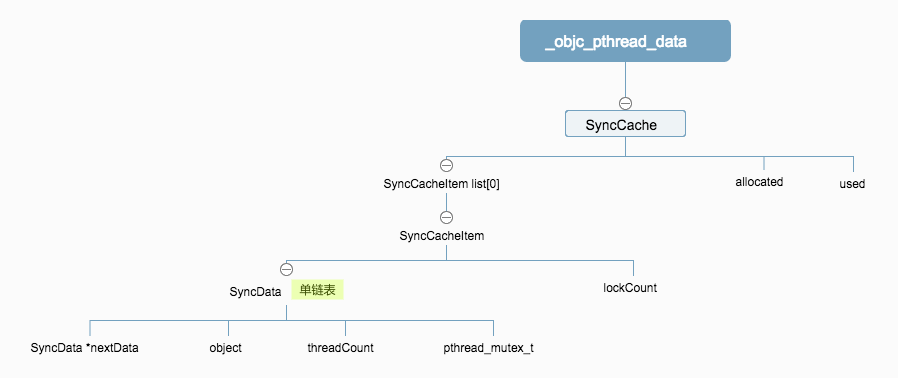
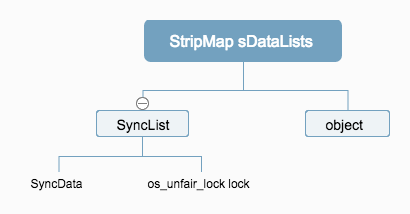
从代码中可以看出过程:
- 注意
static StripedMap<SyncList> sDataLists这个属性,里面存储了全局的针对每一个需要加锁的对象对应的锁数据结构,StripedMap会根据传入的对象的内存地址来映射对应的数据结构,这里会对内存地址进行移位运算后使用.这是个全局静态属性,保证了每个线程访问都有效.
-
首先若支持
SUPPORT_DIRECT_THREAD_KEYS,这种情况下只会用到SyncData这个数据,不停的更新它就可以了.- 先会去查找缓存的
SyncData,如果找到cache,则根据why参数来更新缓存数据的lockCount字段,表示有多少个线程等待这个锁 - 否则继续执行, 查找线程缓存
- 最后使用
SyncData的pthread_mutex_t进行加锁,pthread_mutex_t的初始化方法定义, 这里使用了嵌套锁
这个选项的意思是将SyncData快速缓存在内存中,为什么说是快缓存呢? 我认为因为它只用了一个
SyncData对象来做缓存,通过lockCount字段刷新缓存, 相比较下面的单链表缓存方式要快,单链表要有查表的开销. 它的存储方式类似NSUserdefault的用法,使用固定的Key去取cache。当然,这里使用了Linux内核的cache**address_space**,在这里有代码,也可以看参考资料 - 先会去查找缓存的
-
若未找到快速线程缓存,接下来继续在根据
Thread存储的缓存对象SyncCache进行更新,SyncCache是存储在_objc_pthread_data这个线程缓存数据结构中的。在SyncCache中的list属性保存了SyncData数据,list属性中的每一个对象代表一个需要被保护的对象,就如上面代码中的@synchronized (self)的self对象,每个线程都有一个SyncCache,但是同一个对象只有一份对象,保存在某一个线程的SyncCache中, 这个机制是由全局的sDataLists来保证的.若没有找到缓存,则继续 -
开始创建
SyncData对象, 在创建之前,使用SyncList里面的spinlock_t锁去加锁,即使用了os_unfair_lock互斥锁加锁(这里老版本runtime使用的是OSSpinLock自旋锁),防止多线程同时访问为一个对象创建多个cache数据. -
将创建的
SyncData对象存快速线程缓存和线程缓存中.供下次使用来更新里面的数据. -
当外部
objc_sync_enter方法获取到SyncData数据后, 直接使用了pthread_mutex_t的嵌套锁来加锁,进行多线程访问的保护操作 -
当外部操作完后,调用了
objc_sync_exit方法解锁,内部实现也很简单, 和加锁步骤一样,先找到这个对象对应的SyncData数据,然后将嵌套锁解锁,更新数据(更新这个数据被线程使用的个数和加锁次数)
请注意
static StripedMap<SyncList> sDataLists;这个全局变量, 这里面就存放了针对线程进行加锁的数据的指针。
通过查看源码,能大体了解了加锁过程和如何使用了缓存的机制来提高性能,下面简述一下整体流程
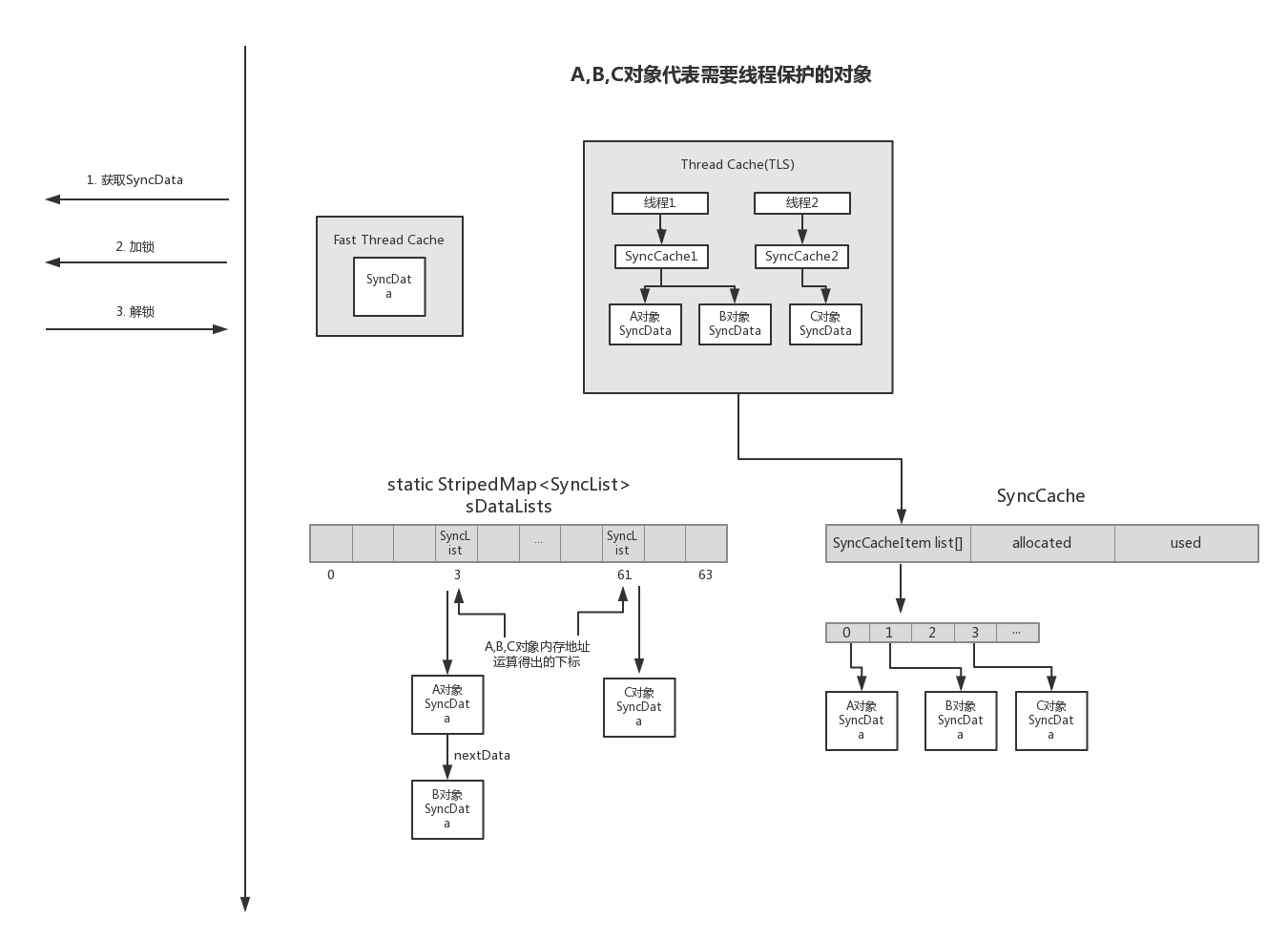
- 为A对象添加
@synchronized方法 - 调用
objc_sync_enter方法 - 若使用快速线程缓存,则都在快速线程缓存中存取
- 若未使用快速线程缓存,则使用线程内部缓存,每个线程都有一个
SyncCache缓存对象,存储被保护对象,但是同一个对象只能在某一个线程内部缓存中存储, 由全局的sDataLists数组存储这个所有被保护对象对应的SyncData数据内存地址,来找到它进行更新,更新的前后会使用os_unfair_lock互斥锁加锁 - 找到缓存对象后返回
SyncData - 使用
SyncData的pthread_mutex_t嵌套锁加锁 - 对A对象操作完之后调用
objc_sync_exit加锁操作
