

- 论文题目:Playing Atari with Deep Reinforcement Learning

所解决的问题?
解决从高维传感器获取数据而端到端实现控制的难题(以前很多都是使用手工提取的特征)。所使用的例子:直接用图像数据学会控制Atari游戏,并且达到了人类水平。
背景
在这之前已经有很多研究工作是直接从高维数据直接获取输出结果的例子。如视觉和语音方面(文末参考文献中有具体文献)。作者将这种处理技术直接用于强化学习中。而由于强化学习学习方式的特殊性(奖励延迟稀疏、状态之间高度相关,强化学习其所学习的数据会发生改变,并不会满足一个固定的分布)。因此将神经网络直接用于强化学习还是会有一定的难度的。
所采用的方法?
文章基于1992年文献1Q-Learning算法的强化学习框架,结合卷积神经网络强大的图像处理能力从而提出了一个最基本的端到端的高维像素控制策略。
上述框架是能处理像素这种高维数据的问题,但是强化学习本身的这种数据之间的这种相关性和数据分布的不平稳性依然没有得到解决。作者依据1993年文献2采用经验回放机制来解决这个问题。这种经验回放机制,期望强化学习,学习的分布能够从最开始随机的数据中的慢慢过渡到现在的效果比较好的这种情况中来。
为了提高强化学习的泛化能力,采用函数近似的方法来评估动作-值函数。。其核心算法和网络的描述原文如下所示:

这里需要看懂这个Target Network,以及公式3所有符号以及下标的含义。这个模型的算法是Model-free和off-policy的。
其算法伪代码如下所示:

相比于标准的Q-Learning算法,DQN算法改进如下:
- 采用经验回放,样本的使用效率提高;
- 随机从经验池中采样,减少数据之间的相关性,会减少更新过程中的方差问题;
- 使用经验回放数据会不容易发散。其原文解释如下:

取得的效果?
作者在2013年文献3所提供的环境Arcade Learning Environment (ALE)中的Atari游戏中实验。同一个网络参数和框架在三个游戏中打败了人类专家。
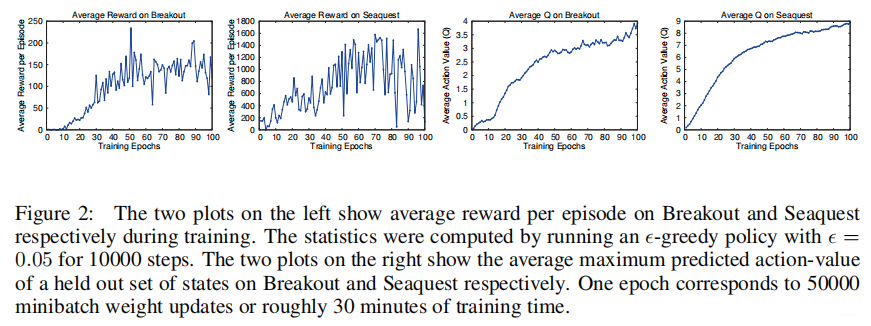
最左边这两幅图描述的是平均奖励,看起来是没有收敛;但是右边两幅图预测的最大Q值要平稳很多。也算是给神经网络收敛性做了一个实验证明吧。最终取得的效果以及对后世的影响都是非常巨大的。其性能可与人类选手媲美。
所出版信息?作者信息?
这篇文章是arXiv上面的一篇文章。第一作者Volodymyr Mnih是Toronto大学的机器学习博士,师从Geoffrey Hinton,同时也是谷歌DeepMind的研究员。硕士读的Alberta大学,师从Csaba Szepesvari。

参考链接
- Q-Learning算法:Christopher JCH Watkins and Peter Dayan. Q-learning. Machine learning, 8(3-4):279–292, 1992.
- experience replay mechanism:Long-Ji Lin. Reinforcement learning for robots using neural networks. Technical report, DTIC Document, 1993.
- Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
视觉方面:
- Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
- Volodymyr Mnih. Machine Learning for Aerial Image Labeling. PhD thesis, University of Toronto, 2013.
- Pierre Sermanet, Koray Kavukcuoglu, Soumith Chintala, and Yann LeCun. Pedestrian detection with unsupervised multi-stage feature learning. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR 2013). IEEE, 2013.
语音方面:
-
George E. Dahl, Dong Yu, Li Deng, and Alex Acero. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. Audio, Speech, and Language Processing, IEEE Transactions on, 20(1):30 –42, January 2012.
-
Alex Graves, Abdel-rahman Mohamed, and Geoffrey E. Hinton. Speech recognition with deep recurrent neural networks. In Proc. ICASSP, 2013.
我的微信公众号名称:深度学习与先进智能决策 微信公众号ID:MultiAgent1024 公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!
