

网页其实就是一颗树;
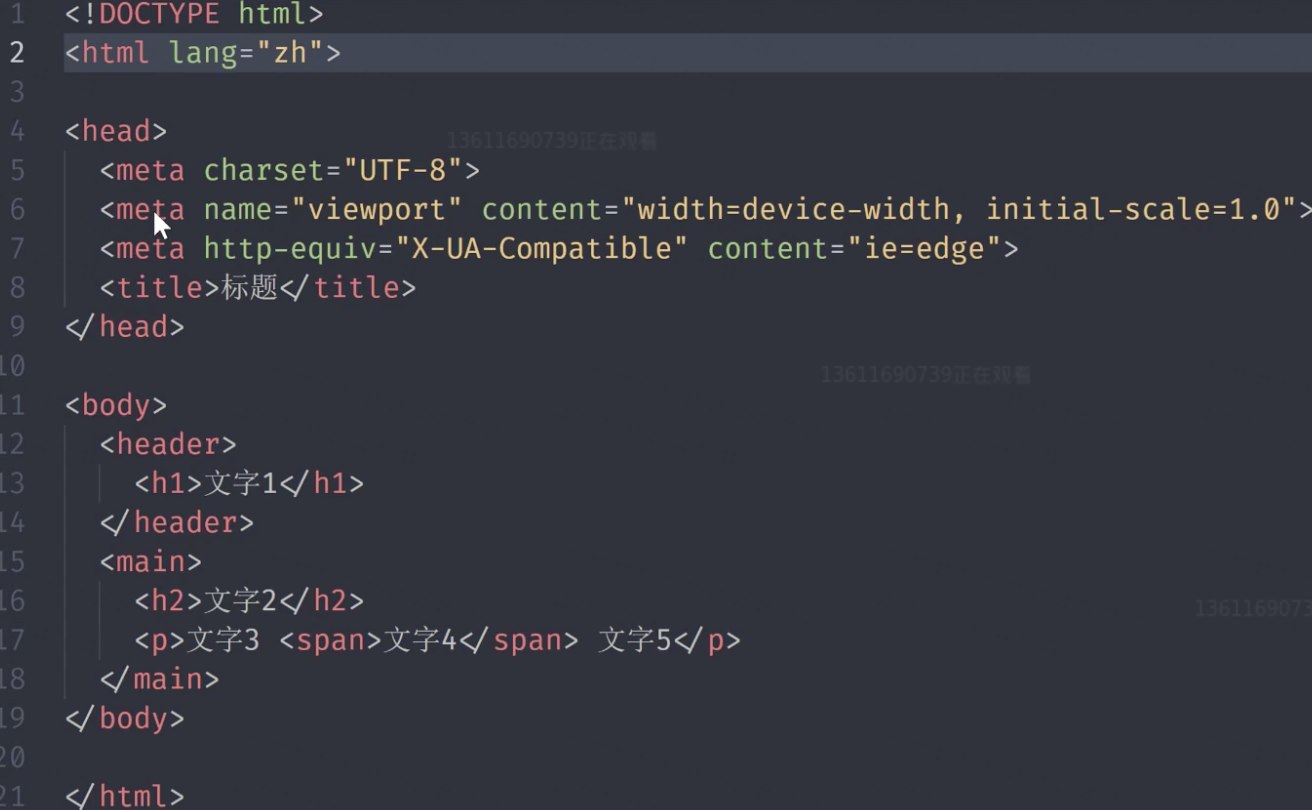
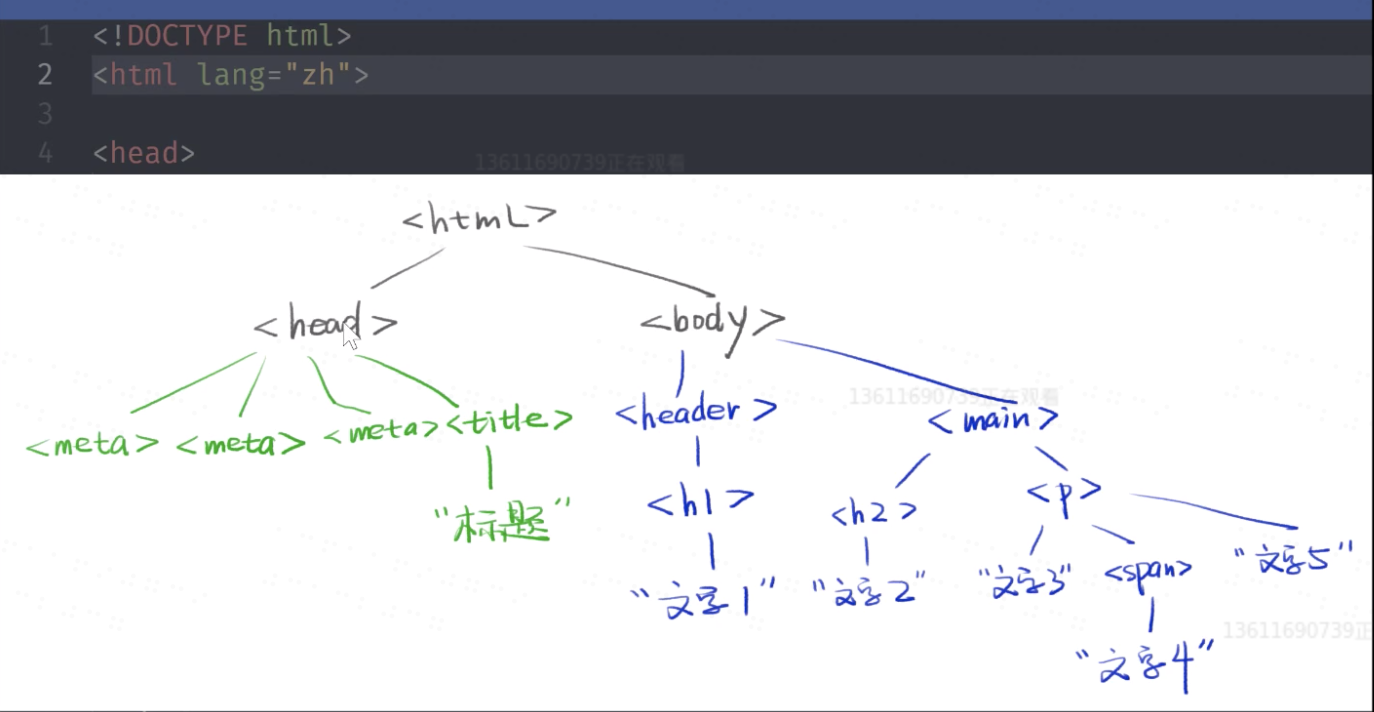
js是如何操作这颗DOM树呢
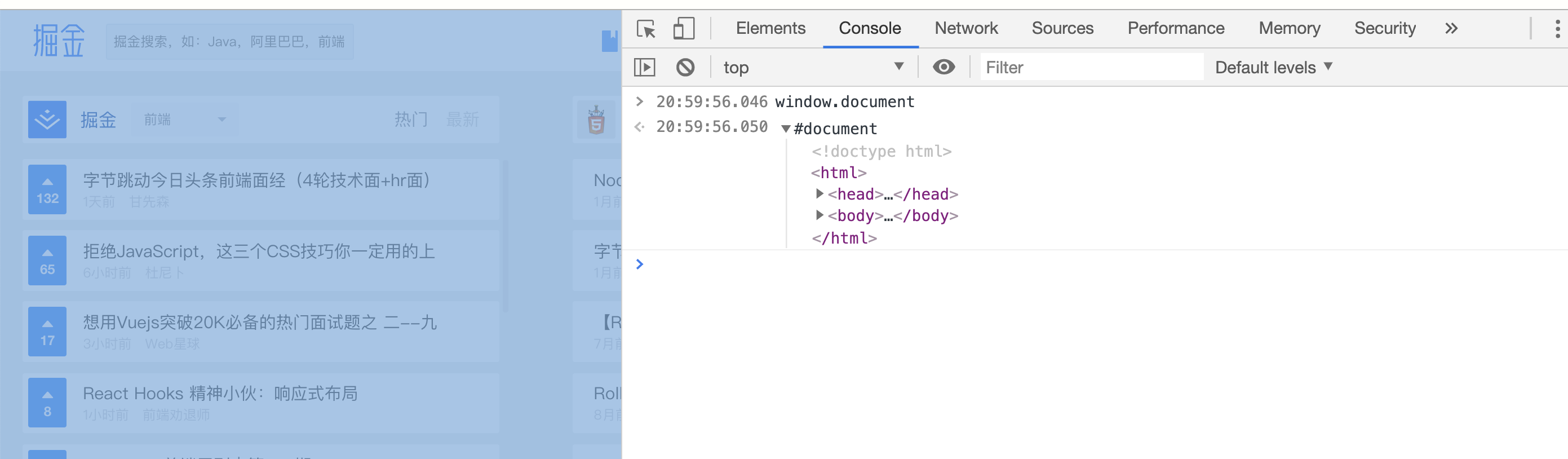
可通过window.document可以得到根节点,而这个根节点又包含了很多的其他节点,所以可以获取到整个网页的所有元素
首先说明一下,DOM很难用,所以在工作中我们基本上不会直接使用DOM,之前是使用jquery,到现在我们使用vue或者react;
获取元素
通过window.id方式
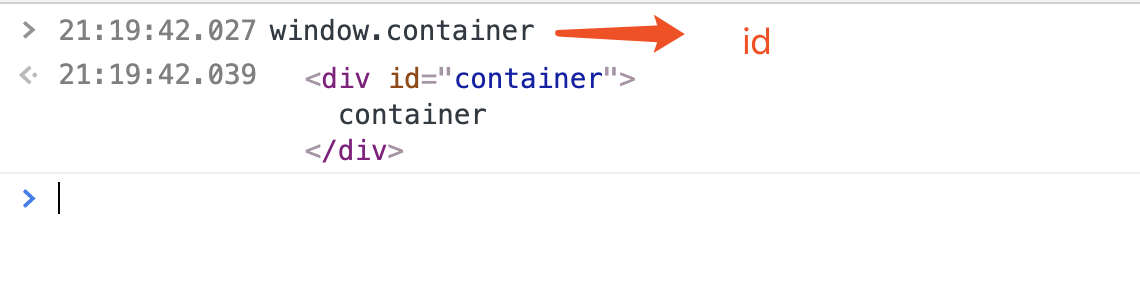
,如果id的名字是全局属性名字字,这种方式是不可以的,但是可以使用window.getElementById("")


document.getElementsByTagName("tagName")[0] 获取div标签的伪数组
document.getElementsByClassName("className")[0] 获取某一类名的伪数组
请注意,window.getElementById("")、document.getElementsByTagName("tagName")、document.getElementsByClassName("className")如果你不需要兼容IE,就不需要使用这三个方法,因为名字又长又不好用,接下来介绍两个好用的api
document.querySelector('') 参数和css选择器的用法一样


document.querySelectorAll('') 参数和css选择器的用法一样,可以获取符合条件的多个元素,返回伪数组;

获取整个文档,window.document

获取html: document.documentElement

获取head元素:document.head

获取body元素:document.body

获取当前窗口: window

获取页面的所有元素: document.all


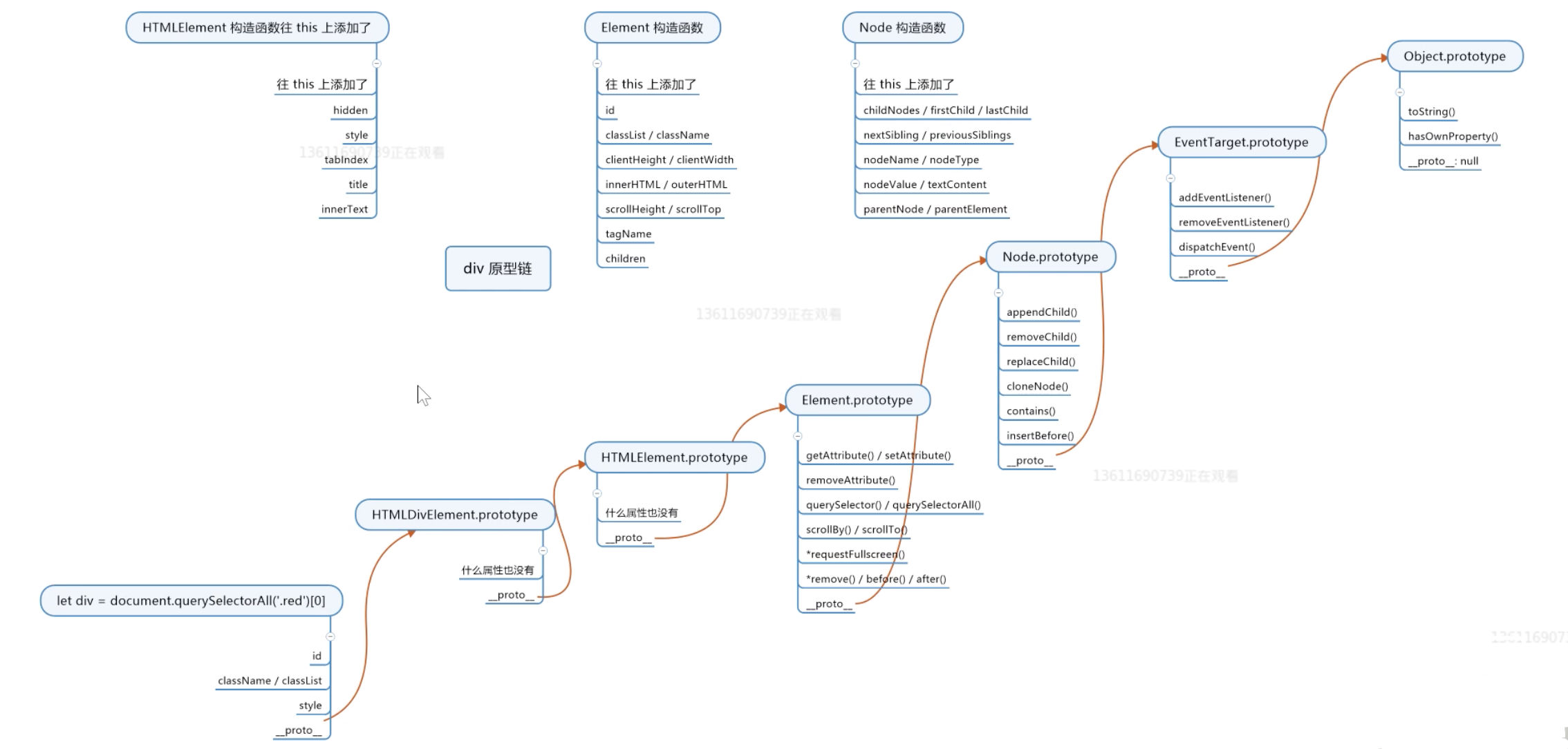
元素的原型链
我们通过js获取的元素也是对象,是对象就有原型,接下来我们看下元素的原型链
let a = document.querySelector('#parent');
console.dir(a)






- 浏览器分为渲染引擎和js引擎
- js引擎不能操作页面,只能操作js
- 渲染引擎不能操作js,只能操作页面
- 当浏览器发现js里面添加了元素,或者修改了元素,就会通知渲染引擎做相应修改
