

春天来了!加油!
要想了解什么是伪共享,先说说缓存行。
什么是缓存行
内存读取的最小单位,cpu到内存中取数据时是基于缓存行来取的,而缓存行的大小都是2的倍数,对于64位机器来说,缓存行一般是64kb的倍数,而对于32位则是32kb的倍数,所以一般缓存行的单位是以64kb来计算的。
什么是伪共享
由于cpu取数据是基于缓存行,那么如果有两个变量x和y在同一个缓存行内,但是两个线程分别使用到了x和y,那么两个线程在并发进行读写时就必须通过内存交换来保证这个缓存行的可见性,尤其是现在是多cpu的架构,这就导致了如果这两个线程在不同的cpu上面,甚至在不同的插槽上面性能会更差。
如何避免伪共享
首先需要知道jvm的对象内存模型:当我们创建一个对象时,首先会给每个对象创建一个对象头一般是8个字节,其中前4个字节是Mark Word,后4个字节是Class Word。对于数组来说还有4个字节用来表示数组长度。

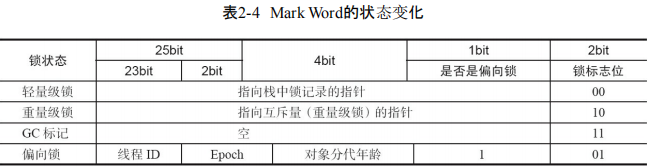
Mark Word
主要是hashcode,gc年龄 和锁信息(无锁,偏向锁,轻量锁,重量锁),这部分会在加锁后被替换成对象引用

Class Word
对象存放对象类型指针,用于找到对象在方法区对应的类型
这里面涉及压缩指针和指针类型等,还没有深入了解过,所以略过【尴尬!】
因此为了避免出现上述问题,我们可以使用填充对齐的方式来保证某个热点对象会被隔离在不同的缓存行中。
详细可以看jdk 1.8 中的@Contended 注解
