

总述
Java中有数组可以存储数据,但是为了解决数组不能动态增长的问题,由此产生了各种的集合类来方便我们存储数据,以及类中的各种方法来对让我们对数据进行各种各样的操作。
总的来说,各种集合类分为Collection和Map两大接口。Collection的子接口又可分为List和Set,在List和Set下又有各种实现类;在Map下也有各种的实现类。具体的实现类以及类中的方法实现会在之后给出,下面我们先给出各种接口和类的继承关系图:
##?????(相关类的继承图
一、List
·ArrayList
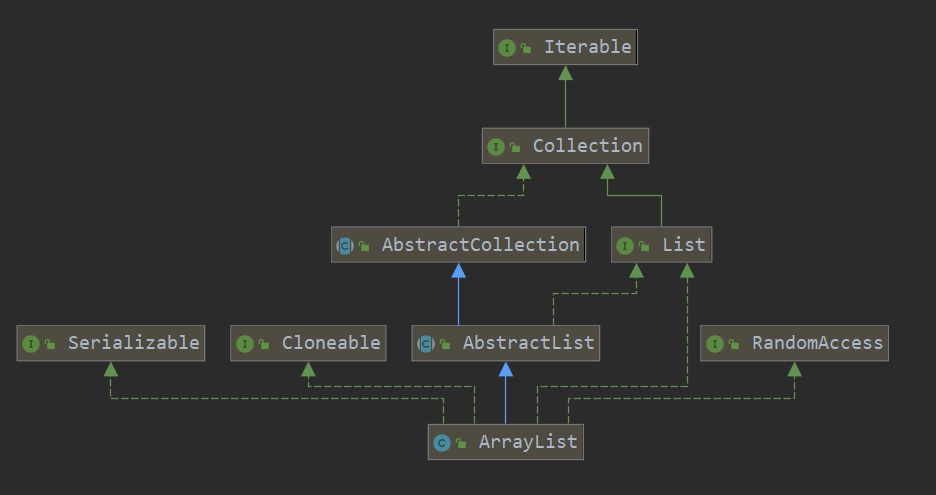
1> 相关类继承关系图
我们可以看到ArrayList继承了AbstractList类,AbstractList类继承了AbstractCollection抽象类并实现了List接口
1.1> AbstractColletion抽象类
由于AbstractColletion类也被其他集合类继承,所以我们先对这个抽象类进行查看,如下:

可以看到这个类实现了Collection接口,而Collection接口又继承了iterable接口(是为了方便实现对集合进行迭代)

属性
方法
1)public abstract Iterator<E> iterator();
返回是迭代器
2) public abstract int size();
用于返回集合的数据大小
3) public boolean isEmpty() {
return size() == 0;
}
用于判断集合是否为空
##?????相关方法
2> ArrayList具体实现以及增删改查
ArrayList是底层是由数组组成的,在ArrayList中有这个数组来存储数据
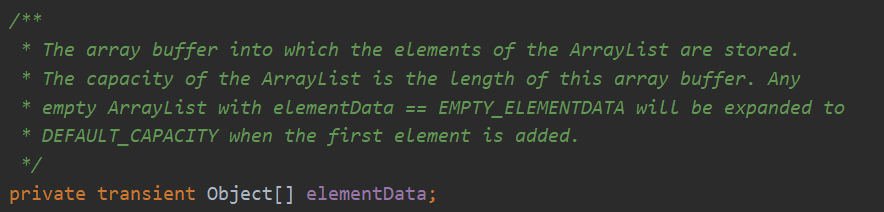


2.1>ArrayList添加元素
add(E e)

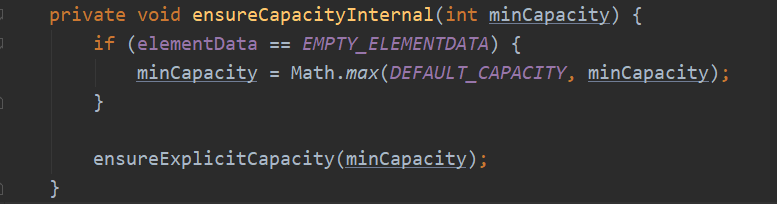
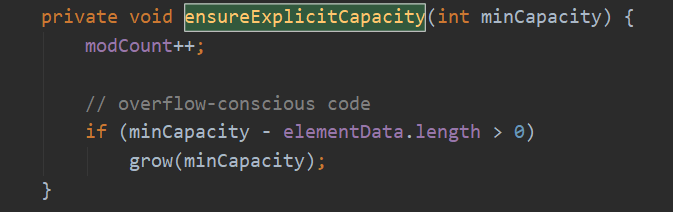
如果minCapacity大于elementData的长度,使用grow方法进行扩容
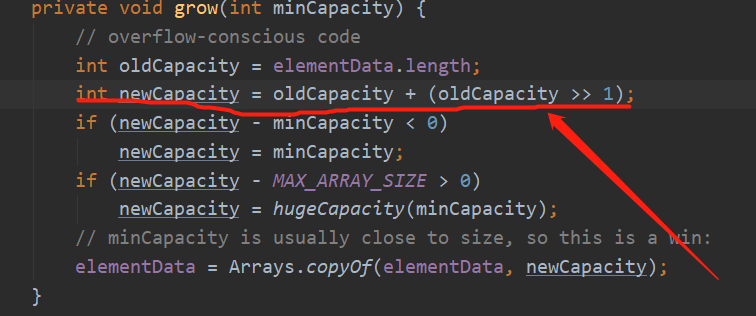
###???
2.2>ArrayList删除元素
remove(int index)
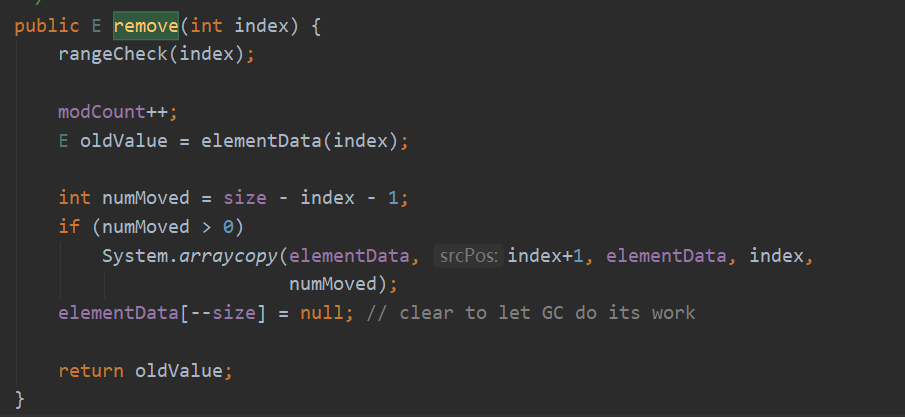
先检查该数字是否在允许范围内,再将要返回的删除的值存入oldValue,numMoved是计算要删除位置的元素后还有几个元素,用于后面的操作
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
这是jdk的一个本地方法,用于将一个数组从指定位置复制到目标数组的指定位置,也就等同于删除相应的元素了 。其中numMoved就是要复制的个数,也就是被删除元素后面的元素个数。
remove(Object o)
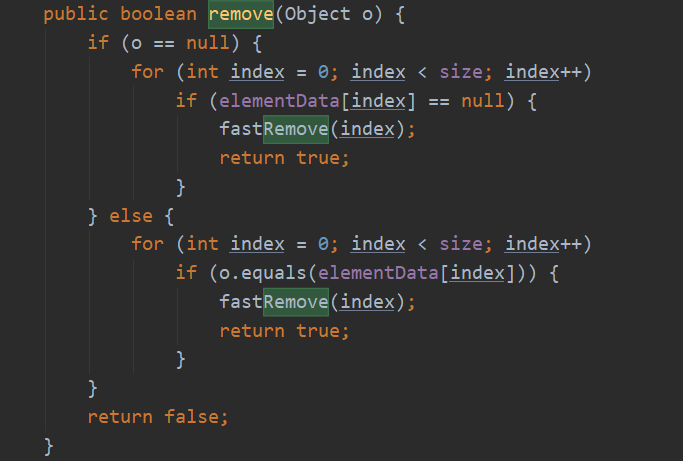
2.3>ArrayList查询元素
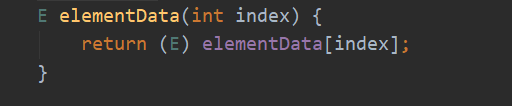
get(int index)
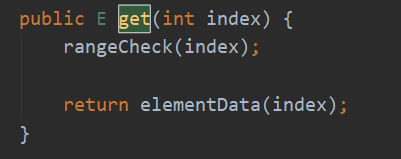
2.4>ArrayList更改元素
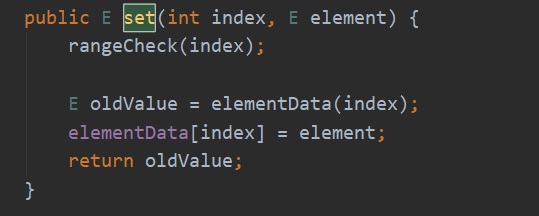
set(int index, E element)
·LinkedList
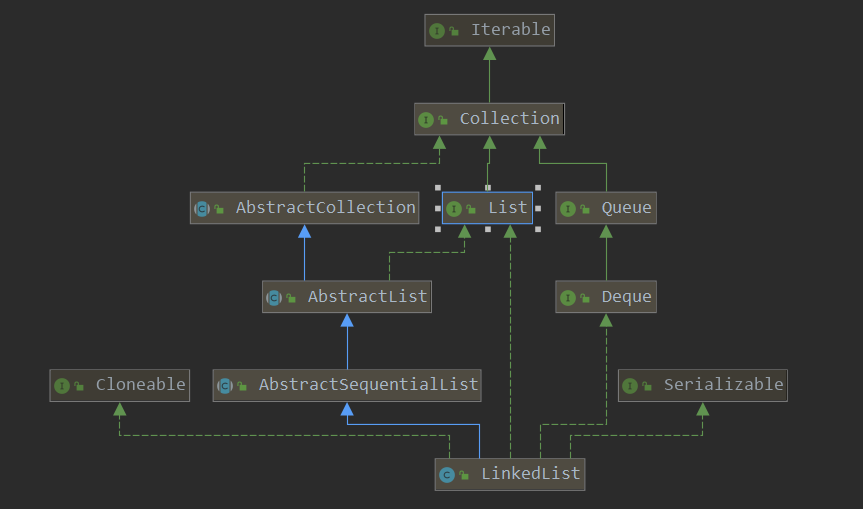
1> 相关类继承关系图
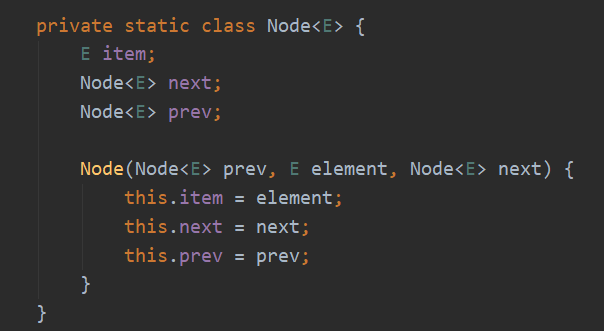
LinkedList底层是由链表实现的,我们可以找到结点的具体结构用成员内部类实现如下



我在总览了LinkedlList后将该类的内容后,把它大致分为四个部分:
· 内部类
这个内部类在
ListItr内部类是实现ListIterator的迭代器具体实现,可以理解为是另外一个list的实现
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned = null;//当前这个结点
private Node<E> next;//下一个结点
private int nextIndex;//下一个结点的下标
private int expectedModCount = modCount;
//必须实现该有参构造
ListItr(int index) {
next = (index == size) ? null : node(index);//如果是最后一个元素,则下一个元素就为Null,否则就是下一个结点
nextIndex = index;//给出的下标数
}
//用于判断是否有下一个元素
public boolean hasNext() {
return nextIndex < size;
}
//使该迭代器指向下一个元素,并返回下一个元素
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
//判断是否是第一个元素,为previous方法做准备
public boolean hasPrevious() {
return nextIndex > 0;
}
////使该迭代器指向下一个元素,并返回下一个元素
public E previous() {
checkForComodification();//检查是否存在版本问题
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
//获取下一个元素的下标
public int nextIndex() {
return nextIndex;
}
//获取上一个元素的下标
public int previousIndex() {
return nextIndex - 1;
}
//--------------------------
//这部分是对迭代器的操作的方法(CRUD),由于和LinkedList中方法类似,在下面会介绍
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
//----------------------------------
//用于保证线程安全的
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
其中还对ListItr内部类做了一层包装,这个也就是我们平时使用的迭代器的直接使用的类,主要提取出来了, next(),remove(),hasNext(),来方便遍历list集合
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
· 转型
这个部分主要是LinkedList转型为ArrayList所用,但是有两个方法,先来看简单的一个
public Object[] toArray() {
Object[] result = new Object[size];
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}
它是直接新创建了一个数组然后for循环遍历Linked链表,依次赋值.
另外一个toArray方法是带有一个数组参数 总的来说,构造了一个对应类型的,长度和ArrayList的size一致的空数组,虽然方法本身还是以 Object数组的形式返回结果,不过由于构造数组使用的ComponentType跟需要转型的ComponentType一致,猜测是为了不会产生转型异常,总的其他操作过程还是和上个方法一致的。
public <T> T[] toArray(T[] a) {
if (a.length < size)//这个size是Linkedlist的元素个数
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size);
int i = 0;
Object[] result = a;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
if (a.length > size)
a[size] = null;
return a;
}
· 异常处理
这部分是为了捕获异常而需要做的判断方法为了解耦而提取出来了。
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
· 增删改查
在后部分会详细介绍,需要提出的应该是(猜测)为了满足栈的数据结构的条件,源码中特地写了许多删改方法,例如,
public boolean offerFirst(E e)
public void push(E e)
public boolean removeFirstOccurrence(Object o)
···等等等等
2> LinkeList具体实现以及增删改查
2.1>LinkedList增加元素
通过linkedasts具体实现
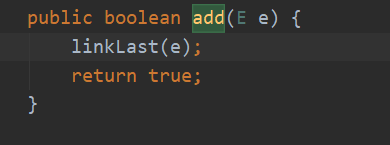
在linkedasts方法中,首先让l和last"指向"同一个对象,然后判断是否l为null(即判断这个链表是否为空),如果是就让新结点赋值给first,否则是l的next为新结点。
2.2>LinkedList删除元素
· 方法一 由unLIinked具体实现
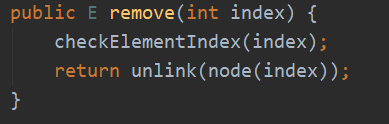
在unLIinked方法中,先进行判断是否是头结点和尾节点,进行特殊操作,否则如果是中间的结点,就直接实现双向链表的删除就可以了
· 方法二
public void remove() {
checkForComodification();//用于检查判断Mod的版本,保证数据安全
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
2.3>LinkedList查找元素
linkedlist之所以是用双向链表实现,而不是单向的,很大程度上也是为了加快查找效率
public E get(int index) {
checkElementIndex(index);//检查是否超越链表个数
return node(index).item;//交给Node(index)
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
2.3>LinkedList更改元素
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
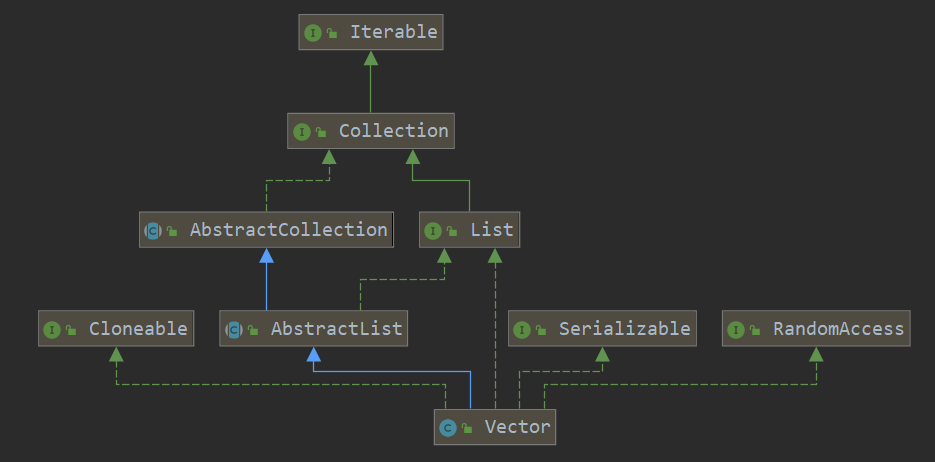
·Vector
1> 相关类继承关系图

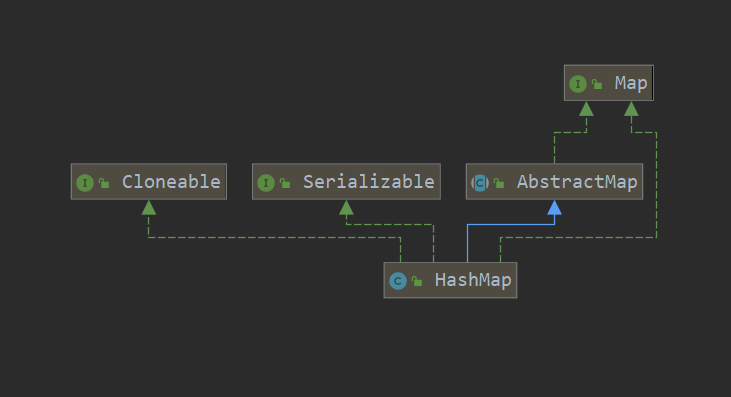
Map
·HashMap
1> 相关类继承关系图
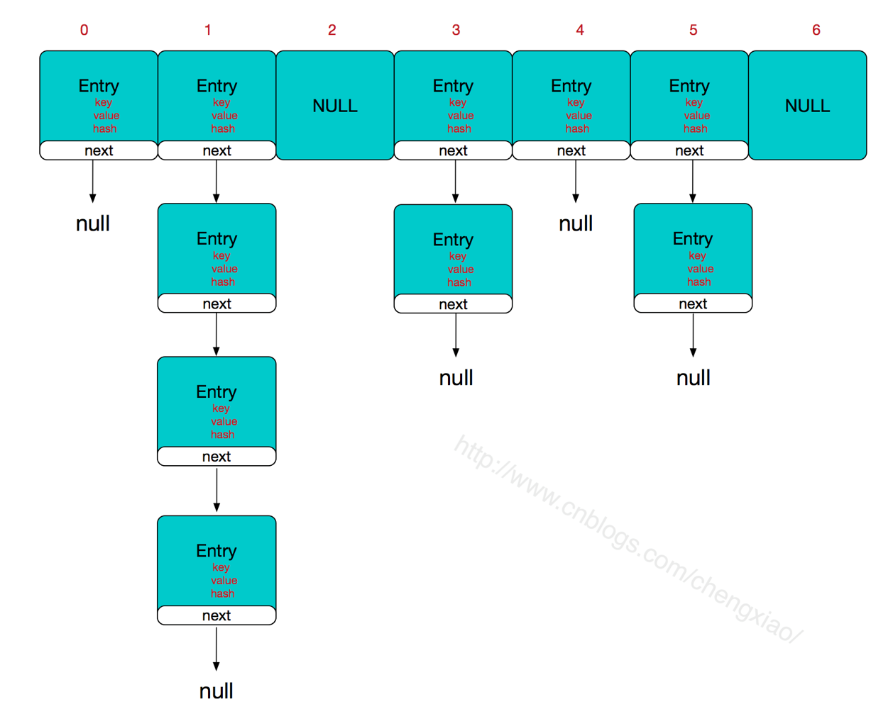
基本的属性和内部类
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;//默认最大容量大小
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量的最大值
static final float DEFAULT_LOAD_FACTOR = 0.75f;//加载因子,被使用的地址数/总共的地址数
transient int size;//当前的被使用容量大小
int threshold;//阈值,如果size大小超过阈值需要resize
final float loadFactor;//当前的加载因子
transient int modCount;//修改的版本
transient int hashSeed = 0;//???
这个是用于存储数据的数据结构的,可以底层也是由数组组成的,至于Entry的内部类的结构,可以看到是由单向链表实现的,所以它的数据结构是如图:
static final Entry<?,?>[] EMPTY_TABLE = {};
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
....
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
...
}
基本构造方法有四种:
总的参数有负载因子(默认为0.75f)和初始化大小(默认为16),所以默认被使用到的大小为12.
public HashMap(int initialCapacity, float loadFactor) {
//initialCapacity和loadFactor的大小必须满足的范围
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//这个NaN是float值的被0除的时候的数
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;//赋值给相应的属性
threshold = initialCapacity;//这是阈值
init();
}
这个方法是采用已有的Map来构造新的Hashmap.
public HashMap(Map<? extends K, ? extends V> m) {
//Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,DEFAULT_INITIAL_CAPACITY)是选出来传进来的map和默认的初始化的大小的较大值,作为容量大小
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);//创建新的table表
putAllForCreate(m);//将给出的map依次赋值到
}
其中采用inflateTable方法来初始化容量大小,并构造相应的Entry类型的数组,而initHashSeedAsNeeded方法是用来推迟hash值的计算,直到我们需要用到的时候再去计算。
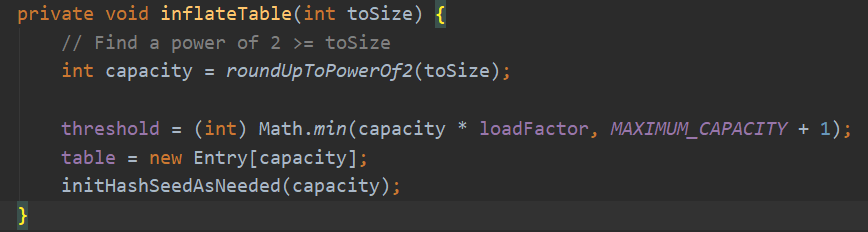
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
2> HashMap具体实现以及增删改查
2.1>HashMap增加元素
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);//如果table是空的那么就初始化table
}
if (key == null)
return putForNullKey(value);//
int hash = hash(key);//计算要新加入的节点的hash值
int i = indexFor(hash, table.length);//为了更加避免哈希冲撞,再计算一遍更详细的哈希值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果没有再哈希,就直接添加到相应的哈希值的那个哈希地址。然后返回旧值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);//如果再哈希了,就转入addEntry方法
return null;
}
addEntry(hash, key, value, i);再哈希过的方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//由于size比阈值大了,就需要resize扩大哈希表
hash = (null != key) ? hash(key) : 0;//如果key值为空值就存放在表的0号位置
bucketIndex = indexFor(hash, table.length);//再计算一遍哈希值
}
createEntry(hash, key, value, bucketIndex);//是将再哈希过的值存入相应的地址位置
}
着重看一下resize方法,他是默认resizet哈希表长变为原长的两倍
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {//如果表长已经是默认最长的数了,那就不再扩容
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));//迁移数据到新表中
//重新置值
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
2.1>HashMap删除元素
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}//这是用于存放
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
