

为什么需要 requestIdleCallback ?
在网页中,有许多耗时但是却又不能那么紧要的任务。它们和紧要的任务,比如对用户的输入作出及时响应的之类的任务,它们共享事件队列。如果两者发生冲突,用户体验会很糟糕。我们可以使用setTimout,对这些任务进行延迟处理。但是我们并不知道,setTimeout在执行回调时,是否是浏览器空闲的时候。
而requestIdleCallback就解决了这个痛点,requestIdleCallback会在帧结束时并且有空闲时间。或者用户不与网页交互时,执行回调。
requestIdleCallback API简介
- requestIdleCallback的第一个参数时callback
- 当callback被调用时,回接受一个参数 deadline,deadline是一个对象,对象上有两个属性
- timeRemaining,timeRemaining属性是一个函数,函数的返回值表示当前空闲时间还剩下多少时间
- didTimeout,didTimeout属性是一个布尔值,如果didTimeout是true,那么表示本次callback的执行是因为超时的原因
- 当callback被调用时,回接受一个参数 deadline,deadline是一个对象,对象上有两个属性
- requestIdleCallback的第二个参数是options
- options是一个对象,可以用来配置超时时间
requestIdleCallback((deadline) => {
// deadline.timeRemaining() 返回当前空闲时间的剩余时间
if (deadline.timeRemaining() > 0) {
task()
}
}, {
timeout: 500
})
空闲时间
requestIdleCallback 的callback会在浏览器的空闲时间运行,那么什么是空闲时间呢?
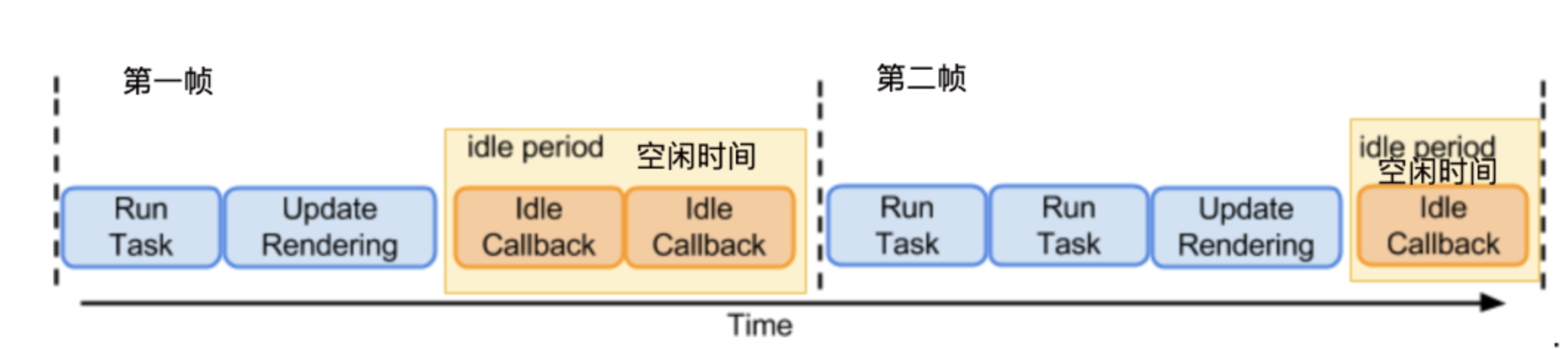
如上图。当我们在执行一段连续的动画的时候,第一帧已经渲染到屏幕上了,到第二帧开始渲染,这段时间内属于空闲时间。这种空闲时间会非常的短暂,如果我们的屏幕是60hz(1s内屏幕刷新60次)的。那么空闲时间会小于16ms(1000ms / 16)。
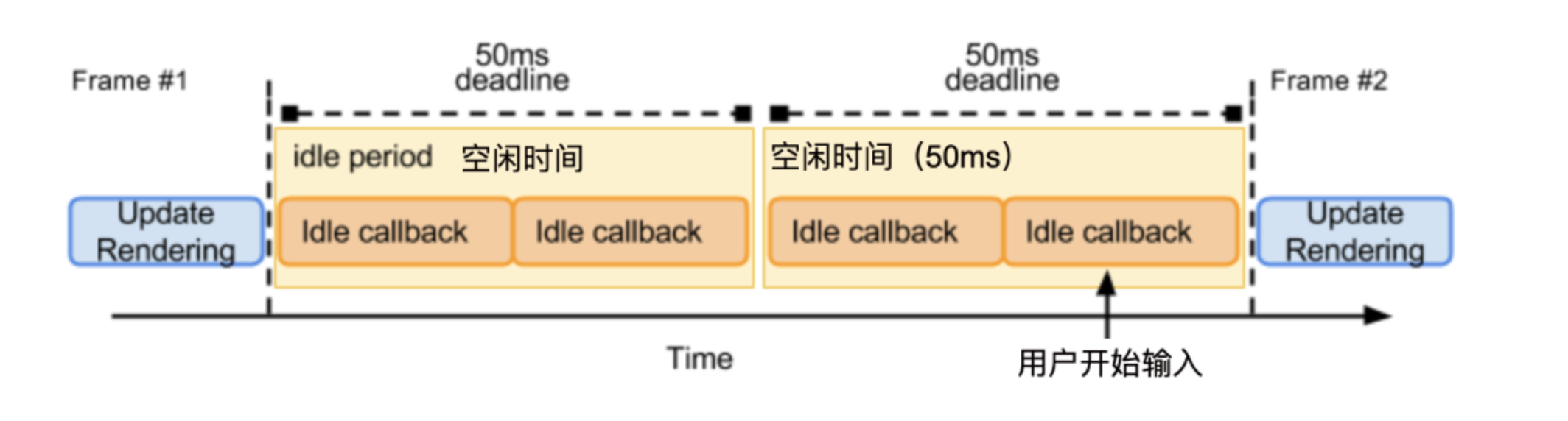
另外一种空闲时间,当用户属于空闲状态(没有与网页进行任何交互),并且没有屏幕中也没有动画执行。此时空闲时间是无限长的。但是为了避免不可预测的事(用户突然和网页进行交互),空闲时间最大应该被限制在50ms以内。
为什么最大是50ms?人类对100ms内的响应会认为是瞬时的。将空闲时间限制在50ms以内,是为了避免,空闲时间内执行任务,从而导致了对用户操作响应的阻塞,使用户感到明显的响应滞后。
在空闲期间,callback的执行顺序是以FIFO(先进先出)的顺序。但是如果在空闲时间内依次执行callback时,有一个callback的执行时间,已经将空闲时间用完了,剩下的callback将会在下一次的空闲时间执行。
const task1 = () => console.log('执行任务1')
const task2 = () => console.log('执行任务2')
const task3 = () => console.log('执行任务3')
// console
// 执行任务1
// 执行任务2
// 执行任务3
requestIdleCallback(task1)
requestIdleCallback(task2)
requestIdleCallback(task3)
如果当前的任务所需要的执行时间,超过了当前空闲时间周期内的剩余时间,我们也可以将任务带到下一个空闲时间周期内执行。在下一个空闲周期开始后,新添加的callback会被添加到callback列表的末尾。
const startTask = (deadline) {
// 如果 `task` 花费的时间是20ms
// 超过了当前空闲时间的剩余毫秒数,我们等到下一次空闲时间执行task
if (deadline.timeRemaining() <= 20) {
// 将任务带到下一个空闲时间周期内
// 添加到下一个空闲时间周期callback列表的末尾
requestIdleCallback(startTask)
} else {
// 执行任务
task()
}
}
当我们网页处于不可见的状态时(比如切换到其他的tag),我们空闲时间将会每10s, 触发一次空闲期。
timeout
如果指定了timeout,但是浏览器没有在timeout指定的时间内,执行callback。在下次空闲时间时,callback会强制执行。并且callback的参数,deadline.didTimeout等于true, deadline.timeRemaining()返回0。
requestIdleCallback((deadline) => {
// true
console.log(deadline.didTimeout)
}, {
timeout: 1000
})
// 这个操作大概花费5000ms
for (let i = 0; i < 3000; i++) {
document.body.innerHTML = document.body.innerHTML + `<p>${i}</p>`
}
requestIdleCallback实践:在requestIdleCallback中打点
使用requestIdleCallback延迟数据的上报,可以避免一些渲染阻塞。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<input type="text" id="text" />
</body>
<script>
const datas = []
const text = document.getElementById('text')
let isReporting = false
function sleep (ms = 100) {
let sleepSwitch = true
let s = Date.now()
while (sleepSwitch) {
if (Date.now() - s > ms) {
sleepSwitch = false
}
}
}
function handleClick () {
datas.push({
date: Date.now()
})
// 监听用户响应的函数,需要花费150ms
sleep(150)
handleDataReport()
}
// ========================= 使用requestIdleCallback ==============================
function handleDataReport () {
if (isReporting) {
return
}
isReporting = true
requestIdleCallback(report)
}
function report (deadline) {
isReporting = false
while (deadline.timeRemaining() > 0 && datas.length > 0) {
get(datas.pop())
}
if (datas.length) {
handleDataReport()
}
}
// ========================= 使用requestIdleCallback结束 ==============================
function get(data) {
// 数据上报的函数,需要话费20ms
sleep(20)
console.log(`~~~ 数据上报 ~~~: ${data.date}`)
}
text.oninput = handleClick
</script>
</html>
而如果不使用 requestIdleCallback , 直接进行数据上报,会直接卡死主线程,影响到浏览器的渲染。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<input type="text" id="text" />
</body>
<script>
const datas = []
const text = document.getElementById('text')
let isReporting = false
function sleep (ms = 100) {
let sleepSwitch = true
let s = Date.now()
while (sleepSwitch) {
if (Date.now() - s > ms) {
sleepSwitch = false
}
}
}
function handleClick () {
datas.push({
date: Date.now()
})
// 监听用户响应的函数,需要花费150ms
sleep(150)
handleDataReport()
}
// ========================= 不使用requestIdleCallback ==============================
function handleDataReport () {
if (isReporting) {
return
}
isReporting = true
report()
}
function report (deadline) {
isReporting = false
while (datas.length > 0) {
get(datas.pop())
}
if (datas.length) {
handleDataReport()
}
}
// ========================= 不使用requestIdleCallback结束 ==============================
function get(data) {
// 数据上报的函数,需要话费20ms
sleep(20)
console.log(`~~~ 数据上报 ~~~: ${data.date}`)
}
text.oninput = handleClick
</script>
</html>
原因分析:
如果使用了requestIdleCallback:
监听事件处理 --> 页面渲染 --> 数据上报(空闲时) --> 监听事件处理 --> 页面渲染 --> 数据上报(空闲时)
如果不使用requestIdleCallback:
监听事件处理 --> 数据上报(被添加到主线程中) --> 监听事件处理 --> 数据上报(被添加到主线程中) --> 监听事件处理 --> 数据上报(被添加到主线程中) --> 页面渲染
常见Q&A
Q1: requestIdleCallback 会在每一次帧结束时执行吗?
A1: 只会在帧末尾有空闲时间时会执行,不应该期望每一次帧结束都会执行requestIdleCallback。
😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂
Q2: 什么操作不适合放到 requestIdleCallback 的callback中。
A2: 更新DOM,以及Promise的回调(会使帧超时),什么意思?请看下面的代码。requestIdleCallback中代码,应该是一些可以预测执行时间的小段代码。
// console
// 空闲时间1
// 等待了1000ms
// 空闲时间2
// Promise 会在空闲时间1接受后立即执行,即使没有空闲时间了也是如此。拖延了进入下一帧的时间
requestIdleCallback(() => {
console.log('空闲时间1')
Promise.resolve().then(() => {
sleep(1000)
console.log('等待了1000ms')
})
})
requestIdleCallback(() => {
console.log('空闲时间2')
})
