

前言
想要学好一个方向的编程语言,底层基础一定是个必不可少的前提。而在 Objective-C 这个篇章中,类与对象更是基础中的基础,它是能让我们串联起万物的基石。
因此,本篇文章就来好好探索一下 类的本质,类的结构,类的懒加载概念 以及 从编译时到运行时 到底做了什么事情,来彻底的了解一下它 。
源码准备
前导知识
什么是类
Objective-C 是一门面向对象的编程语言。每个对象都是其 类 的实例 , 被称为实例对象 . 每一个对象都有一个名为 isa 的指针,指向该对象的类。
而类本身也是一个对象。为什么这么说呢?
来看下源码
typedef struct objc_object *id;
typedef struct objc_class *Class;
struct objc_class : objc_object {
// Class ISA;
Class superclass;
cache_t cache; // formerly cache pointer and vtable
class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
/**/
}
struct objc_object {
private:
isa_t isa;
public:
// ISA() assumes this is NOT a tagged pointer object
Class ISA();
// getIsa() allows this to be a tagged pointer object
Class getIsa();
/*...*/
}
首先,对象是一个 id 类型 , 也就是一个指向 objc_object 结构体的指针。而我们看到 Class 是一个指向 objc_class 结构体指针,而 objc_class 继承于 objc_object , 因此,我们说 类也是一个对象 。
其实 对象是类的实例,而类是由元类对象的实例,实例方法存储在类中,同样,类方法则存储在元类中。同样我们可以得出结论:Objective-C 对象都是 C 语言结构体实现的。
总结:
在
Objective-C中,每个对象 ( 其根本是一个objc_object结构体指针 ) 都有一个名为isa的指针,指向该对象的类 ( 其根本是一个objc_class结构体 )。每一个类实际上也是一个对象 ( 因为
objc_class继承与objc_object),因此每一个类也可以接受消息,即调用类方法,而接受者就是类对象isa所指向的元类。
NSObject与NSProxy是两个基类,他们都遵循了<NSObject>协议,以此为其继承的子类提供了公共接口和能力。
类的结构
提示 :
OBJC2 中 以下 objc_class 已经被弃用 .
struct objc_class {
Class _Nonnull isa OBJC_ISA_AVAILABILITY;
#if !__OBJC2__
Class _Nullable super_class OBJC2_UNAVAILABLE;
const char * _Nonnull name OBJC2_UNAVAILABLE;
long version OBJC2_UNAVAILABLE;
long info OBJC2_UNAVAILABLE;
long instance_size OBJC2_UNAVAILABLE;
struct objc_ivar_list * _Nullable ivars OBJC2_UNAVAILABLE;
struct objc_method_list * _Nullable * _Nullable methodLists OBJC2_UNAVAILABLE;
struct objc_cache * _Nonnull cache OBJC2_UNAVAILABLE;
struct objc_protocol_list * _Nullable protocols OBJC2_UNAVAILABLE;
#endif
} OBJC2_UNAVAILABLE;
类的结构体源码如下 :
typedef struct objc_class *Class;
struct objc_class : objc_object {
// Class ISA;
Class superclass;
cache_t cache; // formerly cache pointer and vtable
class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
/**/
}
首先看到类的本质是一个结构体 , 这也是为什么我们都说 OC 对象的本质实际上是个结构体指针的原因 .
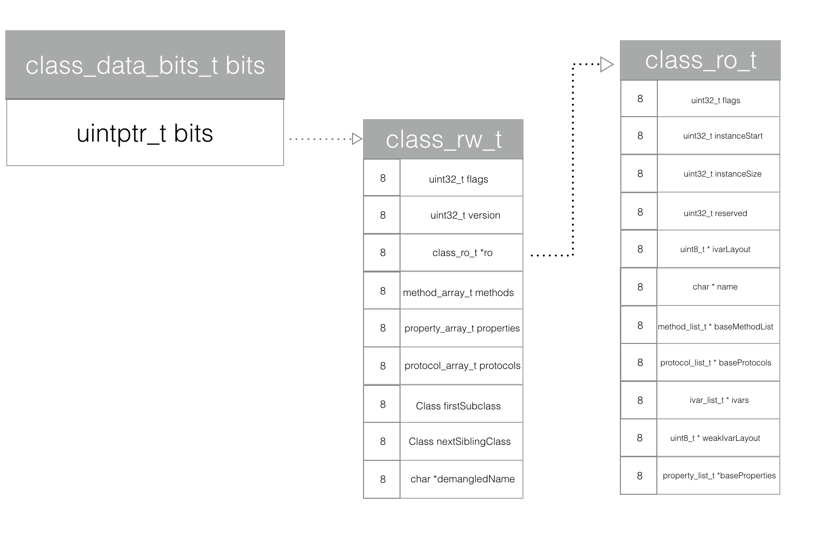
结构体内部结构如下 :
Class ISA:指向关联类 , 继承自objc_object. 参考 isa 的前世今生Class superclass:父类指针 , 同样参考上述文章中有详细指向探索 .cache_t cache, 方法缓存存储数据结构 .class_data_bits_t bits,bits中存储了属性,方法等类的源数据。
接下来我们就来一一探索一下 cache_t 与 class_data_bits_t .
1、class_data_bits_t - 类信息数据源
struct class_data_bits_t {
uintptr_t bits;
class_rw_t* data() {
return (class_rw_t *)(bits & FAST_DATA_MASK);
}
/*.其他一些方法省略..*/
}
typedef unsigned long uintptr_t;
// data pointer
#define FAST_DATA_MASK 0x00007ffffffffff8UL
点进去我们看到 , 其实这个 bits , 跟我们讲述 isa ( isa 的前世今生 ) 时开启了 isa 优化的情况下是大致相同的 .
也就是说 ,
bits使用了 8 个字节总共 64 个二进制位来存储更多内容 , 读取时通过mask进行位运算获取所存储指针数据 .
例如 :
class_rw_t* data() {
return (class_rw_t *)(bits & FAST_DATA_MASK);
}
通过 bits & FAST_DATA_MASK 获取其中固定二进制位下的数据 , 转化为 class_rw_t 类型的指针 . ( 其实 objc 源码中大多数 bits 字样的写法都是这种处理方法 , 也是一种优化措施 , 被称为 享元设计模式 ) .
1.1 class_rw_t
class_rw_t 数据结构如下 :
struct class_rw_t {
uint32_t flags;
uint32_t version;
const class_ro_t *ro;
method_array_t methods;
property_array_t properties;
protocol_array_t protocols;
Class firstSubclass;
Class nextSiblingClass;
char *demangledName;
#if SUPPORT_INDEXED_ISA
uint32_t index;
#endif
/*...*/
}
这个就是我们所熟悉的 方法列表 , 属性列表 , 协议列表等等数据信息了 .
其中方法列表需要注意的是 : (类对象存放对象方法,元类对象存放类方法)
还有一个值得提的就是 const class_ro_t *ro; . 其源码如下 :
1.2 class_ro_t
struct class_ro_t {
uint32_t flags;
uint32_t instanceStart;
uint32_t instanceSize;
#ifdef __LP64__
uint32_t reserved;
#endif
const uint8_t * ivarLayout;
const char * name;
method_list_t * baseMethodList;
protocol_list_t * baseProtocols;
const ivar_list_t * ivars;
const uint8_t * weakIvarLayout;
property_list_t *baseProperties;
}
可以看到 ro 中同样存储了 baseMethodList , baseProtocols , ivars 等数据 , 但是 ro 是被 const 修饰的 , 也就是不可变 .
其结构如下图 :
那么 rw 与 ro 是什么关系 , 为什么需要重复存储呢 ?
1.3 rw 与 ro 的关系
先说结论 .
其实如名称一样 ,
rw即read write,ro即read only.OC为了动态的特性 , 在编译器确定并保存了一份 类的结构数据在ro中 , 另外存储一份在运行时加载到rw中 , 供runtime动态修改使用 .
ro是不可变的 , 而rw中methods,properties以及protocols内存空间是可变的 . 这也是 已有类 为什么可以动态添加方法 , 确不能动态添加属性的原因 ( 添加属性会同样添加成员变量 , 也就是 ivar . 而 ivar 是存储在 ro 中的 ) .同样分类不能添加属性的原因也是如此 ( 关联属性是单独存储在
ObjectAssociationMap中的 , 跟类的原理并不一样 )
1.4 rw 与 ro 关系验证
首先在 从头梳理 dyld 加载流程 中我们提到过 , libobjc 的初始化是从 _objc_init 开始的 , 而这个函数中调用了 map_images , load_images , 以及 unmap_image 这三个函数 .
- 什么意思呢 ?
其实也就是 dyld 负责将应用由磁盘加载到运行内存中 , 而也是在此时注册的类及元类的数据和内存结构 . 也就是在 map_images 中 .
提示:
那我们来从源码看下 .
1️⃣、 当
dyld加载到开始链接主程序的时候 , 递归调用recursiveInitialization函数 .2️⃣、 这个函数第一次执行 , 进行
libsystem的初始化 . 会走到doInitialization->doModInitFunctions->libSystemInitialized.3️⃣、
Libsystem的初始化 , 它会调用起libdispatch_init,libdispatch的init会调用_os_object_init, 这个函数里面调用了_objc_init.4️⃣、
_objc_init中注册并保存了map_images,load_images,unmap_image函数地址.5️⃣ : 注册完毕继续回到
recursiveInitialization递归下一次调用 , 例如libobjc, 当libobjc来到recursiveInitialization调用时 , 会触发libsystem调用到_objc_init里注册好的回调函数进行调用 . 就来到了libobjc, 调用map_images.
void map_images(unsigned count, const char * const paths[],
const struct mach_header * const mhdrs[])
{
mutex_locker_t lock(runtimeLock);
return map_images_nolock(count, paths, mhdrs);
}
void map_images_nolock(unsigned mhCount, const char * const mhPaths[],
const struct mach_header * const mhdrs[])
{
if (hCount > 0) {
_read_images(hList, hCount, totalClasses, unoptimizedTotalClasses);
}
}
↓↓
void _read_images(header_info **hList, uint32_t hCount, int totalClasses, int unoptimizedTotalClasses)
{
for (EACH_HEADER) {
classref_t *classlist = _getObjc2ClassList(hi, &count);
for (i = 0; i < count; i++) {
Class cls = (Class)classlist[i];
Class newCls = readClass(cls, headerIsBundle, headerIsPreoptimized);
}
}
}
Class readClass(Class cls, bool headerIsBundle, bool headerIsPreoptimized)
{
Class replacing = nil;
if (Class newCls = popFutureNamedClass(mangledName)) {
class_rw_t *rw = newCls->data();
const class_ro_t *old_ro = rw->ro;
memcpy(newCls, cls, sizeof(objc_class));
rw->ro = (class_ro_t *)newCls->data();
newCls->setData(rw);
freeIfMutable((char *)old_ro->name);
free((void *)old_ro);
addRemappedClass(cls, newCls);
replacing = cls;
cls = newCls;
}
}
结论 :
-
可以看到 , 在
dyld加载类过程中 , 将ro中数据拷贝到rw中 , 另外在realizeClassWithoutSwift中也有体现 , 这里就不贴出来了 . -
而在这之前 ,
ro的数据已经是处理完毕的 , 也就是说类的结构体在编译期ro的数据已经处理完毕 .
那么首先编译期 ro 数据确定我们如何验证 ?
答案是明显的 , clang + MachoView
1.5 编译期 ro 数据验证
1. clang 验证
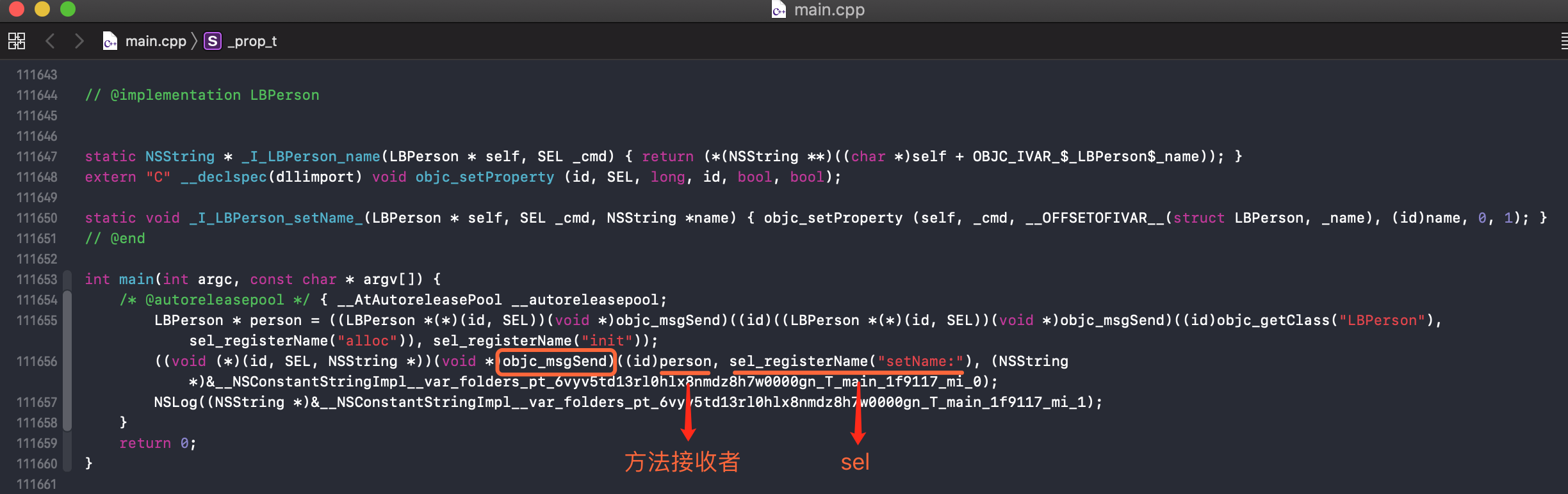
新建一个类 , clang readwrite 一下 , 打开 main.cpp . 查看到如下 :
static struct _class_ro_t _OBJC_METACLASS_RO_$_LBPerson __attribute__ ((used, section ("__DATA,__objc_const"))) = {
1, sizeof(struct _class_t), sizeof(struct _class_t),
(unsigned int)0,
0,
"LBPerson",
0,
0,
0,
0,
0,
};
static struct _class_ro_t _OBJC_CLASS_RO_$_LBPerson __attribute__ ((used, section ("__DATA,__objc_const"))) = {
0, __OFFSETOFIVAR__(struct LBPerson, name), sizeof(struct LBPerson_IMPL),
(unsigned int)0,
0,
"LBPerson",
(const struct _method_list_t *)&_OBJC_$_INSTANCE_METHODS_LBPerson,
0,
(const struct _ivar_list_t *)&_OBJC_$_INSTANCE_VARIABLES_LBPerson,
0,
(const struct _prop_list_t *)&_OBJC_$_PROP_LIST_LBPerson,
};
2. macho 查看验证
由上述 clang 中我们得到 , ro 是存储在 __DATA 段 _objc_const 节中 , 使用 MachOView 打开 macho 文件看到如下 :
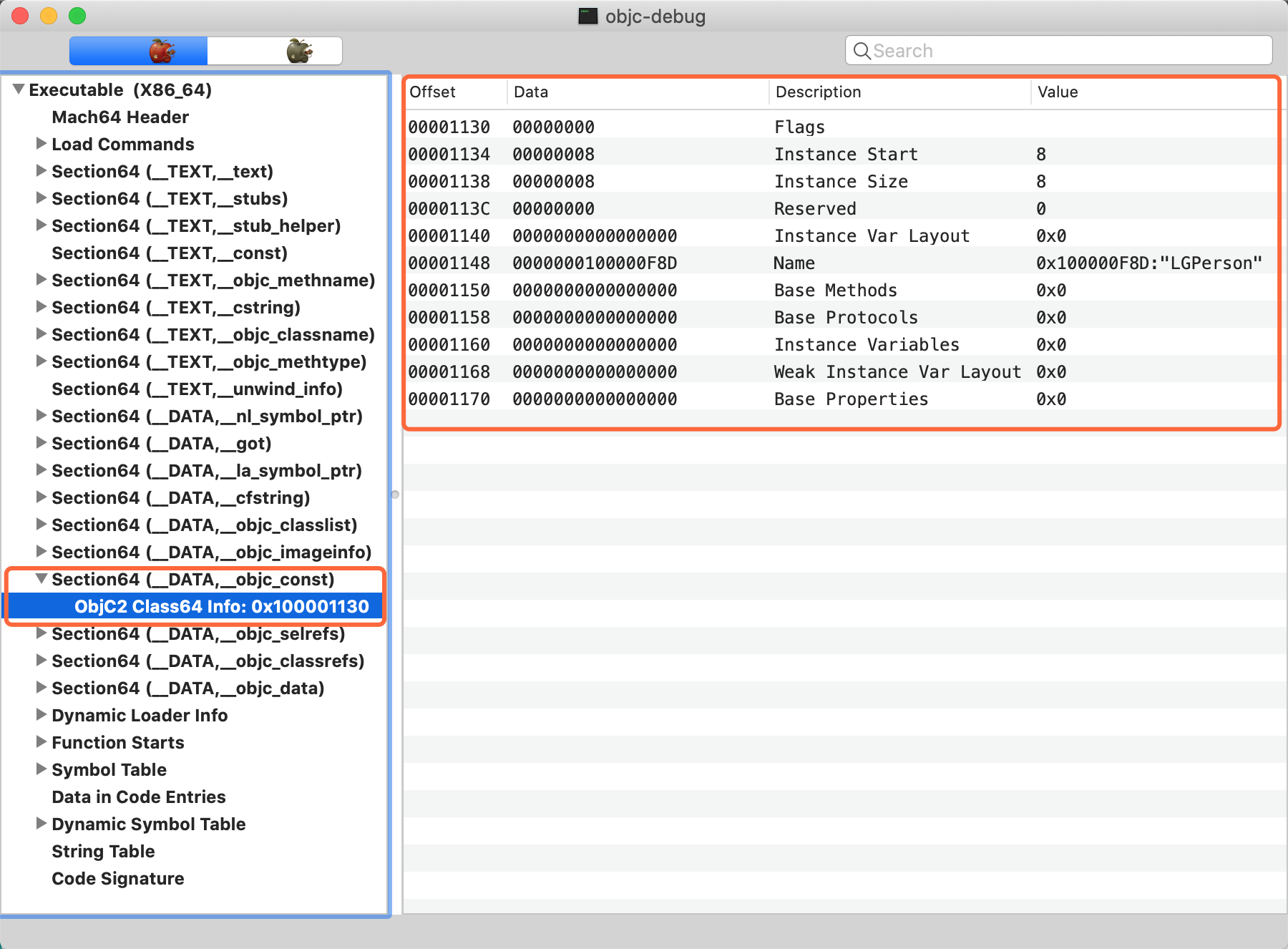
得到验证 , ro 中数据在编译期确定并存储完毕 , 运行时无法修改 .
那么接下来 , 我们就使用 lldb 来调试一下 , 来实际看下 类中数据的内存布局 .
1.6 内存布局调试探索
代码准备
@interface LBPerson : NSObject{
@public
NSString *ivarName;
}
@property (nonatomic, copy) NSString *propertyName;
+ (void)testClassMethod;
- (void)testInstanceMethod;
@end
@implementation LBPerson
+ (void)testClassMethod{
NSLog(@"%s",__func__);
}
- (void)testInstanceMethod{
NSLog(@"%s",__func__);
}
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
LBPerson * person = [[LBPerson alloc] init];
person->ivarName = @"ivar";
person.propertyName = @"property";
[person propertyName];
[person testInstanceMethod];
NSLog(@"123");
}
return 0;
}
添加断点到 NSLog 处 , 运行工程 .
lldb 输入指令 p/x LBPerson.class . 打印如下 :
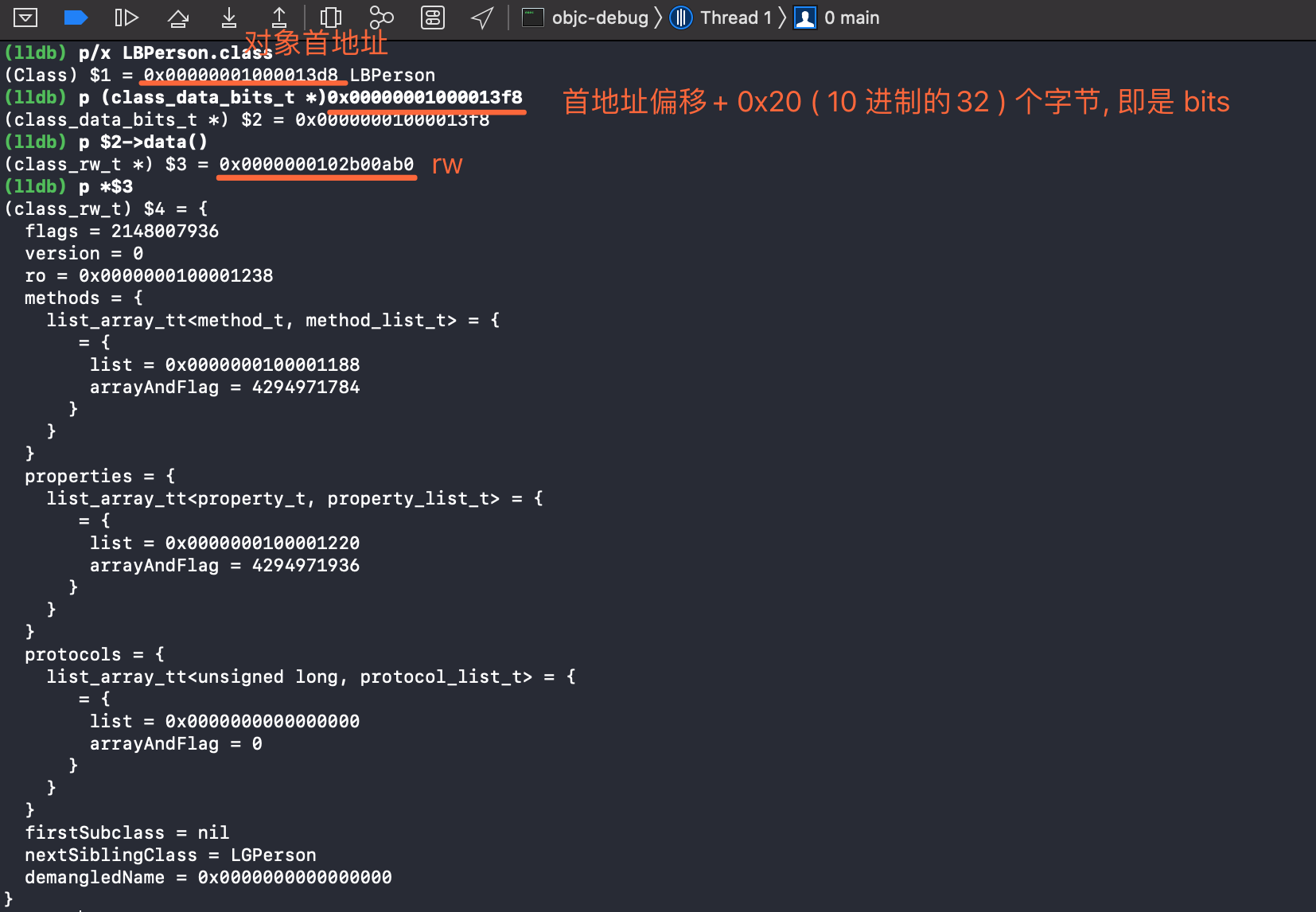
0x20 个字节就是 bits 呢 ?
- 因为类的结构体 ,
isa联合体8字节 ,superclass指针8字节 ,cache_t结构体16字节.
struct objc_class : objc_object {
// Class ISA; // 8
Class superclass; // 8
cache_t cache; // 16
class_data_bits_t bits;
}
struct cache_t {
struct bucket_t *_buckets; // 8
mask_t _mask; // 4
mask_t _occupied; // 4
}
另外注意 : 要在 objc 可编译源码进行上述 lldb 调试 , 否则无法强转 class_data_bits_t .
找到 rw 我们就分别来看下 成员变量 , 属性 , 方法的存储位置 .
成员变量
首先在 rw 中我们看到并没有 ivar . 因此来到 ro 中 .
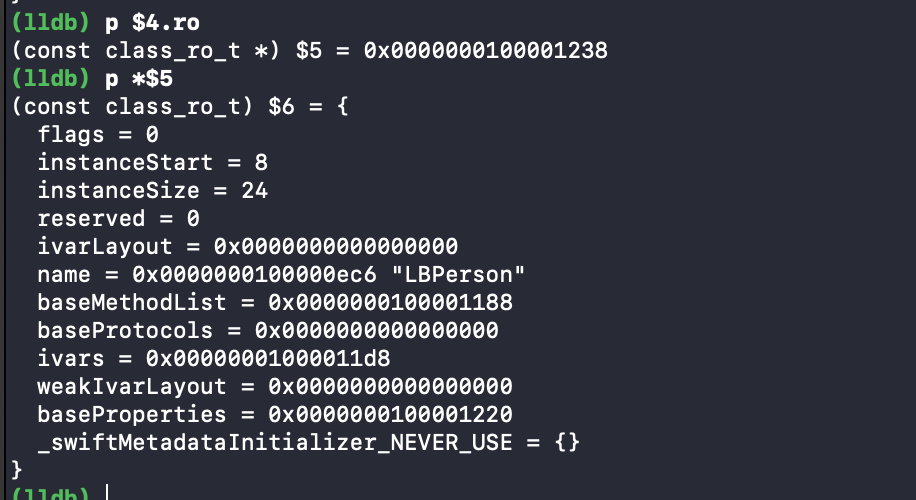
这里我们跟 rw 比较一下发现 , rw 与 ro 中 protocols , properties 与 methods 内存地址是一模一样的 . 说明了运行时 ro 读取到 rw 中的时候 , 这三个列表是浅拷贝 .
继续获取 ivar .
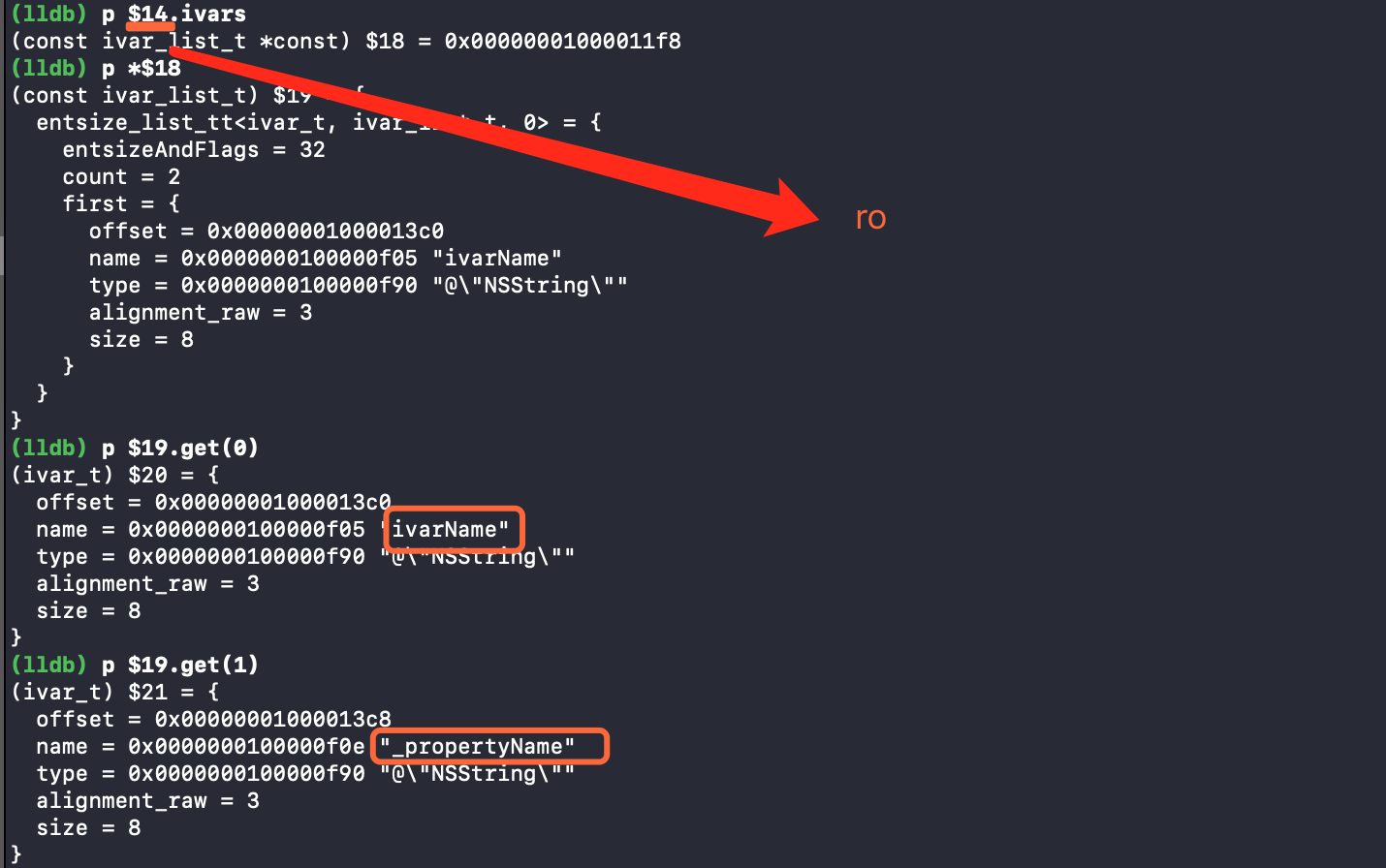
ivarName , 还有自动生成的 _propertyName . 定义属性时自动会生成 _ + 名称 的实例变量 .
属性
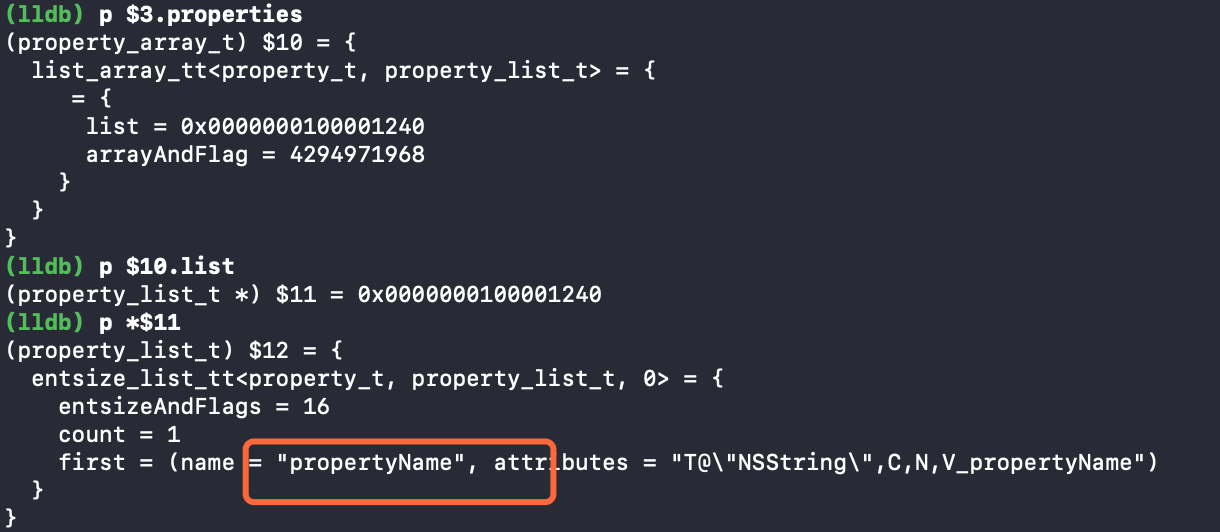
方法
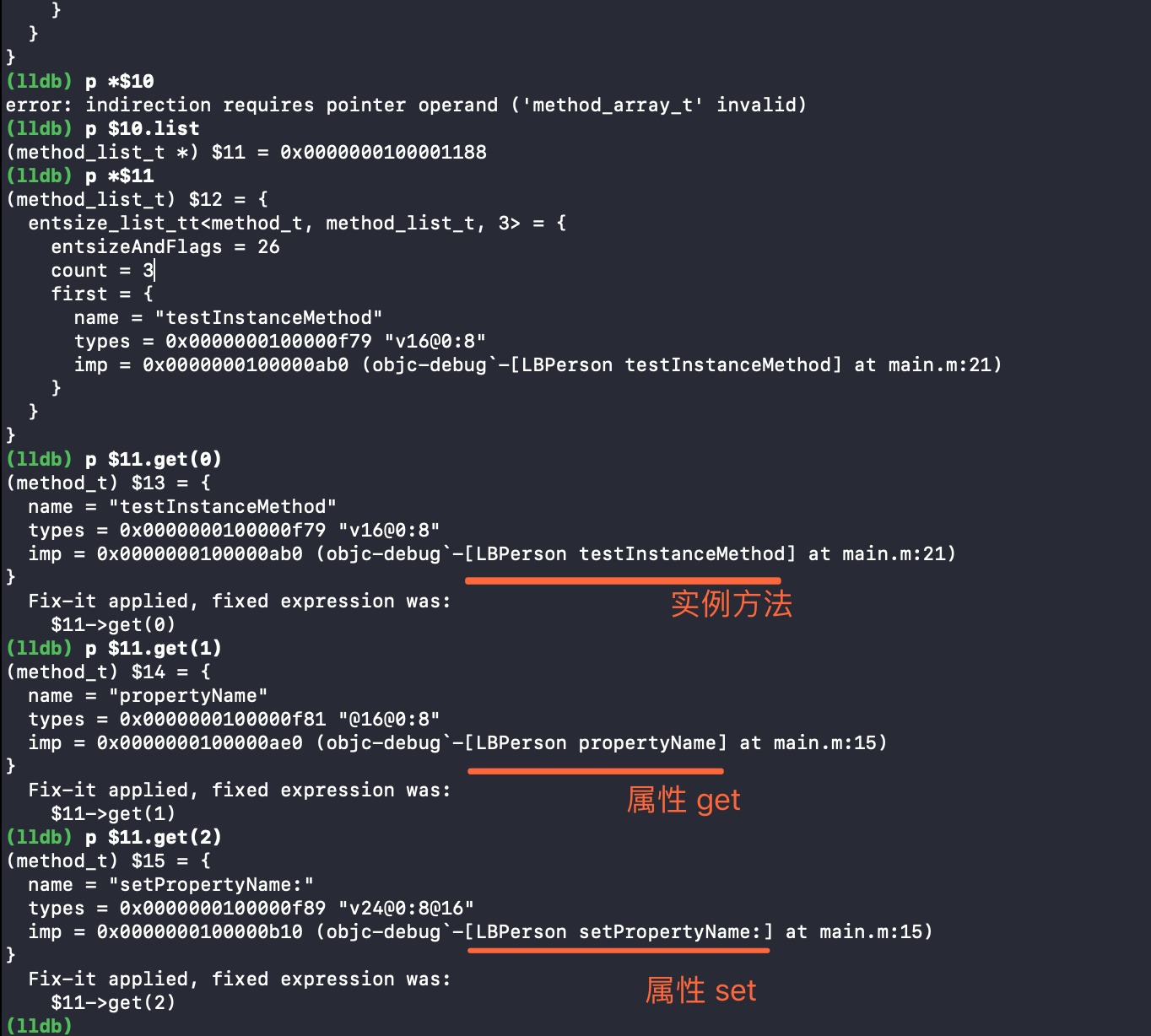
- 可以看到实例变量并没有生成
getter与setter, 这也是属性跟成员变量的区别 . - 结合实例变量中的结果可以得出 : 属性 = 成员变量 +
getter与setter - 另外类方法也并没有在类的方法列表中 , 其实是在元类里 , 感兴趣的同学可以继续去测试一下 .
以上就是类中主要存储数据的内容了 . 探索完 bits . 下面我们来看看 cache_t , 顺便了解了解方法缓存的原理 .
2、cache_t - 方法缓存数据源
cache_t 作为存储方法缓存的数据结构 , 我们就来探索一下方法缓存的原理 .
struct cache_t {
struct bucket_t *_buckets; // 缓存数组,即哈希桶
mask_t _mask; // 缓存数组的容量临界值,实际上是为了 capacity 服务
mask_t _occupied; // 缓存数组中已缓存方法数量
/* ... */
}
#if __LP64__
typedef uint32_t mask_t; // x86_64 & arm64 asm are less efficient with 16-bits
#else
typedef uint16_t mask_t;
#endif
struct bucket_t {
private:
#if __arm64__
uintptr_t _imp;
SEL _sel;
#else
SEL _sel;
uintptr_t _imp;
#endif
}
从源码得知 , cache_t 在 64 位下占用 16 个字节 , 而 imp 与 sel 就是存储在 bucket_t 结构中的.
接下来 , 我们就使用 lldb 来实际探索一下 方法缓存的原理 .
3、方法缓存原理探索
3.1 代码准备
@interface LBObj : NSObject
- (void)testFunc1;
- (void)testFunc2;
- (void)testFunc3;
@end
@implementation LBObj
- (void)testFunc1{
NSLog(@"%s",__FUNCTION__);
}
- (void)testFunc2{
NSLog(@"%s",__FUNCTION__);
}
- (void)testFunc3{
NSLog(@"%s",__FUNCTION__);
}
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
LBObj * obj = [[LBObj alloc] init];
[obj testFunc1];
[obj testFunc2];
[obj testFunc3];
}
return 0;
}
3.2 开始探索
提示 : 在 objc 源码中跑项目 , 否则 lldb 强转会提示找不到 cache_t .
在对象创建前加上断点 , 先来看下缓存桶中数据 .
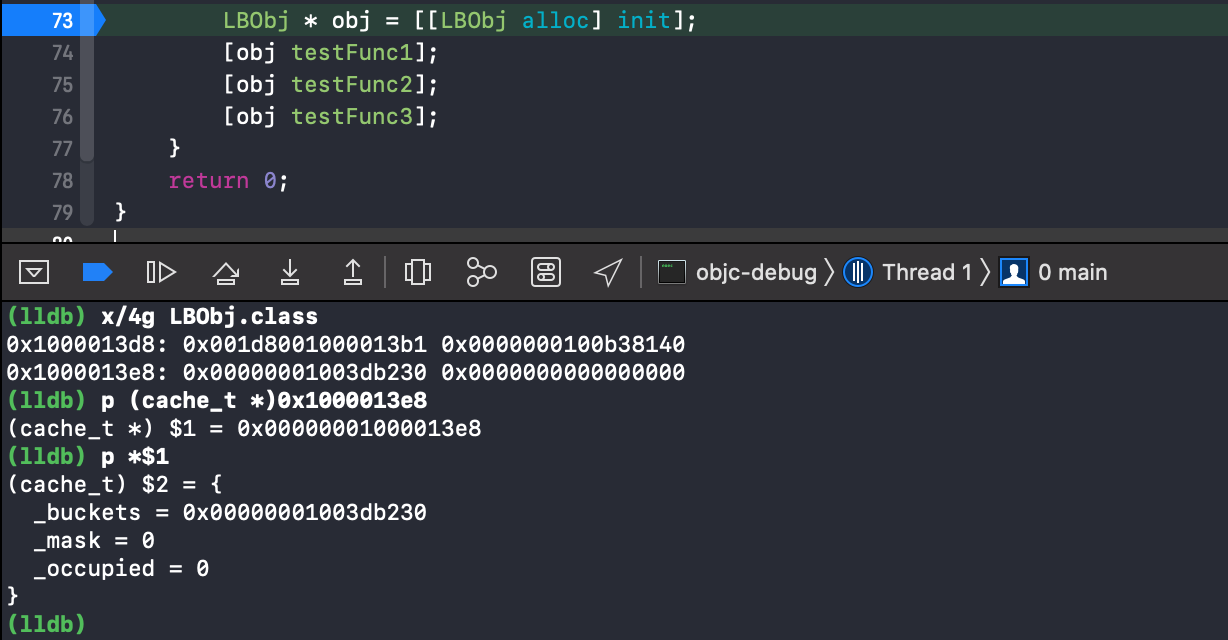
过掉创建对象断点 , 来到调用方法处 , 再次查看 .
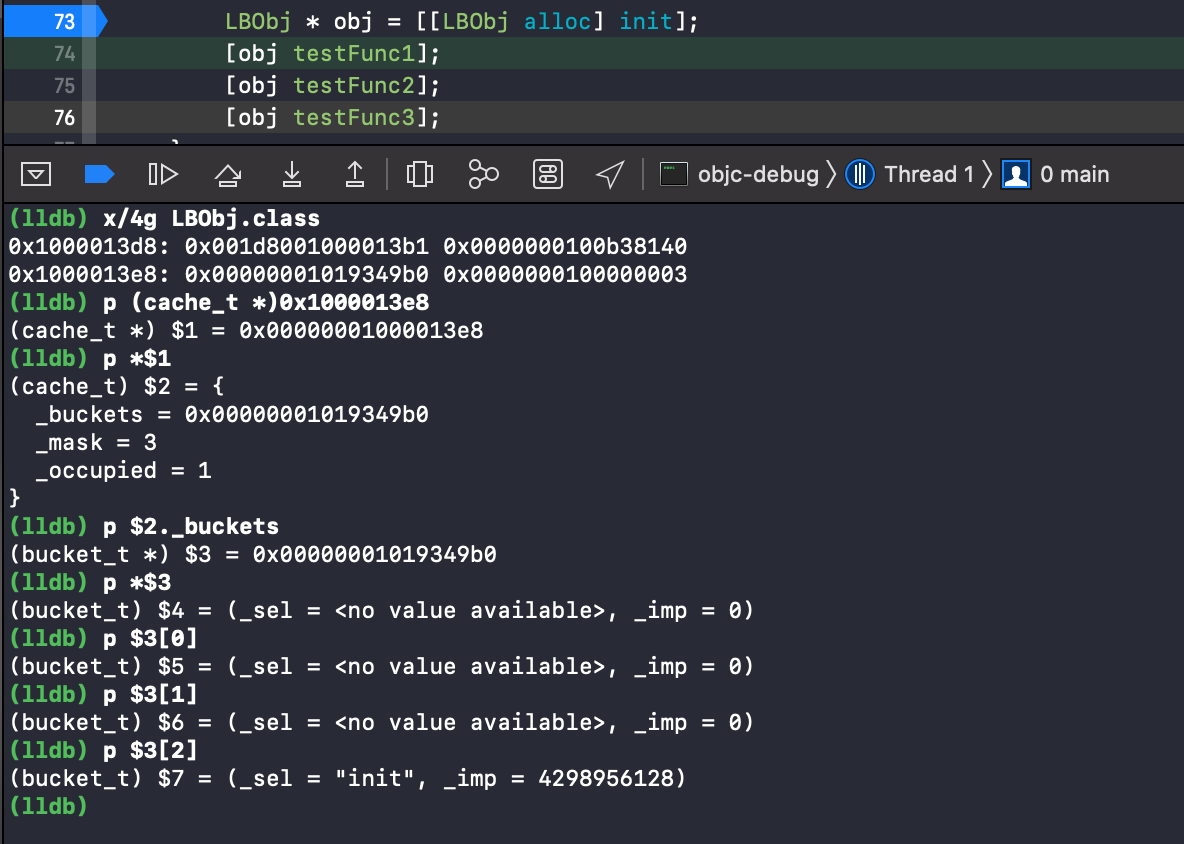
- 看到这里 , 首先
init的sel以及imp都已经缓存到了桶中 , 已占用_occupied变为 1 ,_mask变为 3 .
另外我们有两个疑问 .
1️⃣ : alloc 方法为什么没有缓存 ?
2️⃣ : 为什么 init 方法不在 _buckets 第一个位置 ?
答 :
alloc为什么在类的cache_t中没有缓存呢 ? 答案很明显 , 类方法以及类方法的缓存都是存储在元类中的 . 有兴趣的同学可以去验证一下 .为什么不是按顺序存储呢 , 这个涉及到哈希表的结构设计 , 本篇文章不多做讲述了 . 熟悉的同学应该清楚 , 另外还有
key值编码 , 哈希表扩容 , 以及哈希冲突的处理 , 是一个比较经典的题目 , iOS 中使用的也比较多 .
过掉断点执行 testFunc1 . 继续查看 .
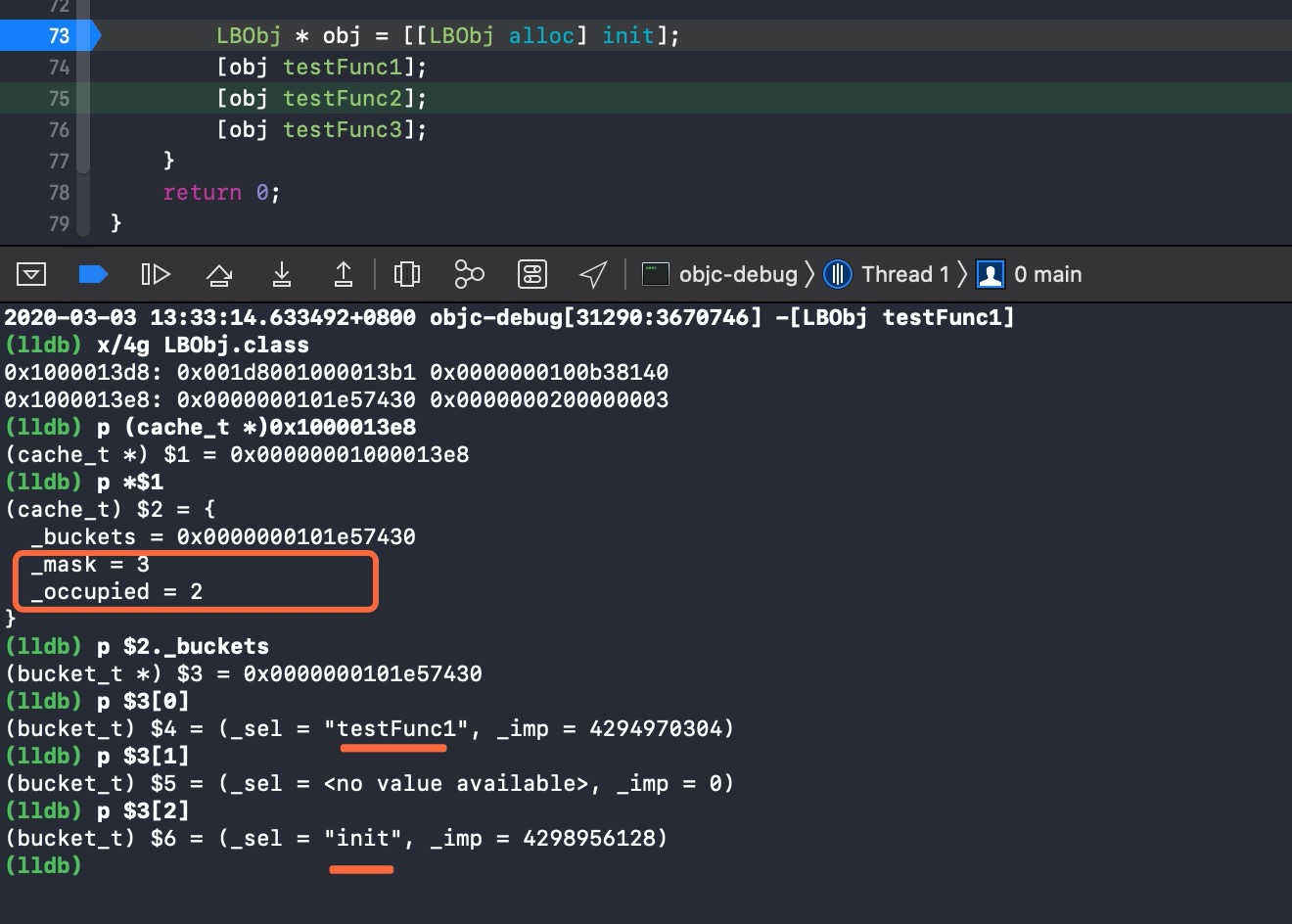
init以及testFunc1的sel以及imp都已经缓存到了桶中 , 已占用_occupied变为 2 ,_mask为 3 .
过掉断点执行 testFunc2 . 继续查看 .
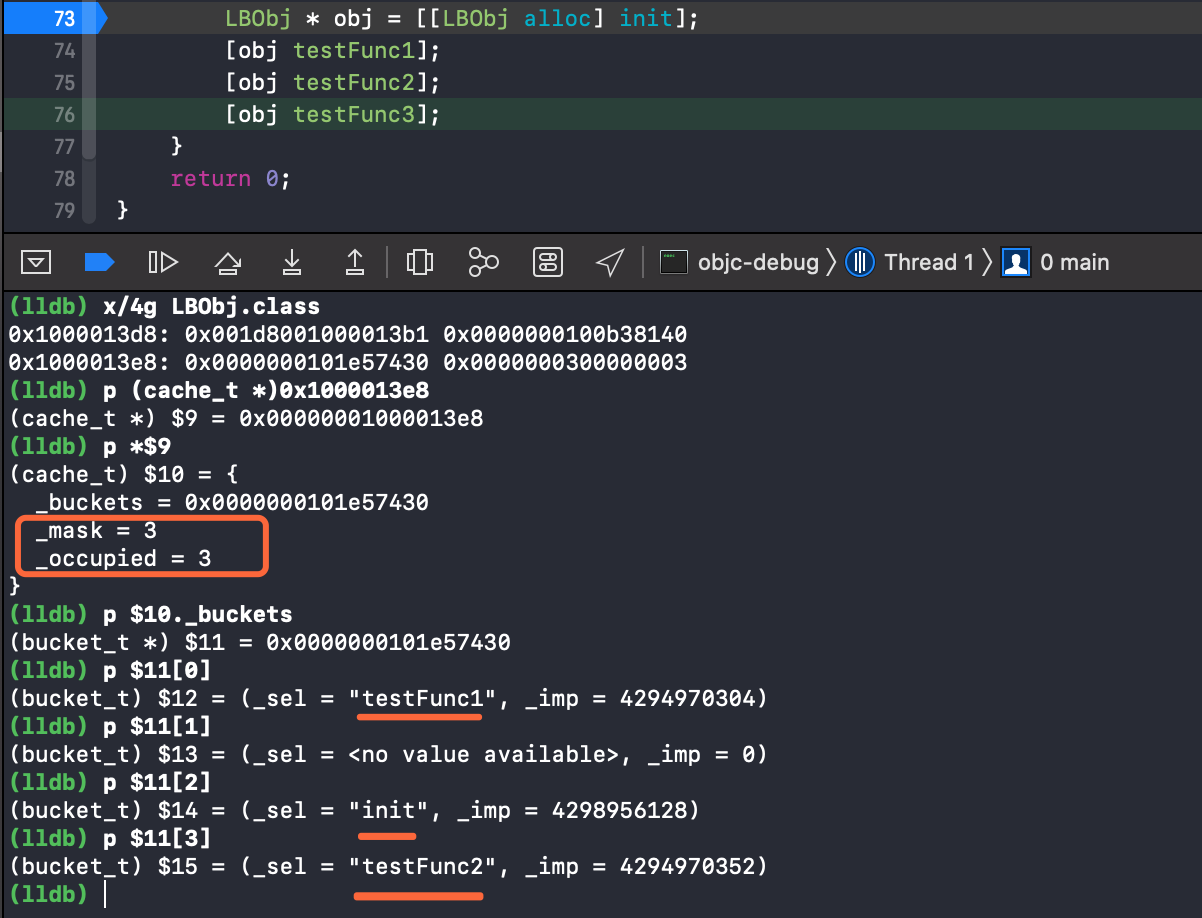
init、testFunc1、testFunc2的sel以及imp都已经缓存到了桶中 , 已占用_occupied变为 3 ,_mask为 3 .
过掉断点执行 testFunc3 . 继续查看 .
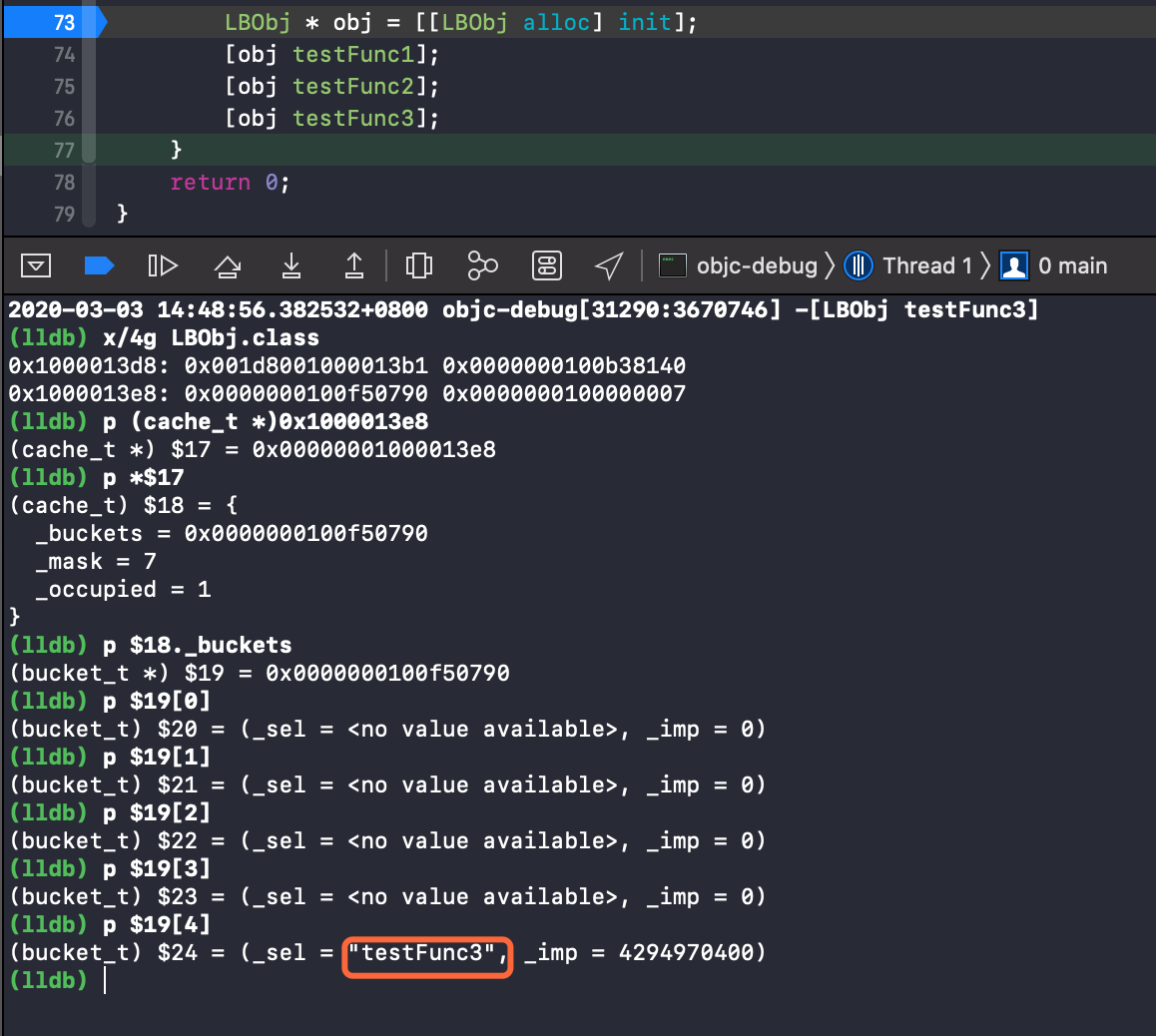
这里就比较有意思了 , 之前存储的方法缓存已被清理 , testFunc3 的 sel 以及 imp 缓存到了桶中 . 已占用 _occupied 变为 1 , _mask 为 7 , 为什么会这样呢 ? 下面我们会详细探索 .
3.3 关于缓存容量
实际上缓存容量并不取
_mask属性 , 而是调用cache_t结构体中的mask_t capacity();方法 .
mask_t cache_t::capacity()
{
return mask() ? mask()+1 : 0;
}
mask_t cache_t::mask()
{
return _mask;
}
当没有调用过方法 ,
_mask为 0 , 容量capacity也为 0 , 当_mask有值时 , 实际容量为_mask + 1.
当我们对 cache_t 的内存结构有了深入了解之后 , 就可以来看下 OC 调用方法时 , 到底是如何查找缓存的 . 当缓存到达临界值时 , 又是如何扩容 , 或者说缓存的淘汰策略又是什么样的呢 ?
在 探索OC方法的本质 与 OC方法查找与消息转发 这两篇文章中我们详细探索了方法的本质和方法查找的完整流程 .
其中第一部分就是 objc_MsgSend 的汇编查找缓存部分 .
3.4 汇编查找缓存
以 arm64 为例 ( 不同架构下对应着不同的汇编指令集 ) .
ENTRY _objc_msgSend
UNWIND _objc_msgSend, NoFrame
cmp p0, #0 // nil check and tagged pointer check
#if SUPPORT_TAGGED_POINTERS
b.le LNilOrTagged // (MSB tagged pointer looks negative)
#else
b.eq LReturnZero
#endif
ldr p13, [x0] // p13 = isa
GetClassFromIsa_p16 p13 // p16 = class
LGetIsaDone:
CacheLookup NORMAL // calls imp or objc_msgSend_uncached
#if SUPPORT_TAGGED_POINTERS
LNilOrTagged:
b.eq LReturnZero // nil check
// tagged
adrp x10, _objc_debug_taggedpointer_classes@PAGE
add x10, x10, _objc_debug_taggedpointer_classes@PAGEOFF
ubfx x11, x0, #60, #4
ldr x16, [x10, x11, LSL #3]
adrp x10, _OBJC_CLASS_$___NSUnrecognizedTaggedPointer@PAGE
add x10, x10, _OBJC_CLASS_$___NSUnrecognizedTaggedPointer@PAGEOFF
cmp x10, x16
b.ne LGetIsaDone
// ext tagged
adrp x10, _objc_debug_taggedpointer_ext_classes@PAGE
add x10, x10, _objc_debug_taggedpointer_ext_classes@PAGEOFF
ubfx x11, x0, #52, #8
ldr x16, [x10, x11, LSL #3]
b LGetIsaDone
// SUPPORT_TAGGED_POINTERS
#endif
LReturnZero:
// x0 is already zero
mov x1, #0
movi d0, #0
movi d1, #0
movi d2, #0
movi d3, #0
ret
END_ENTRY _objc_msgSend
在有了对
isa的详细了解以后 , 看这些汇编指令还是比较清楚的 . 不太清楚isa的同学可以去查阅查阅 isa 的前世今生 .对于汇编指令不太熟悉的同学可以借助
Hopper与IDA, 他们上面是有汇编语言还原高级伪代码的功能 , 帮助查看 .
在整个 _objc_msgSend 汇编部分 , 其实就是查找缓存的流程 , 也就是我们所说的快速查找流程 ( 缓存 ) . 这个流程具体步骤如下 :
1️⃣、对象空值判断
ENTRY _objc_msgSend
UNWIND _objc_msgSend, NoFrame
cmp p0, #0
#if SUPPORT_TAGGED_POINTERS
LNilOrTagged:
b.eq LReturnZero // nil check
方法调用者即是我们 OC 隐藏参数的第一个 , 在 arm 汇编中 , 方法的第一个参数以及返回值会存储在 x0 寄存器中 .
因此 , 此处就是对 x0 寄存器中的消息接收者是否为空的判断 , 为空就直接返回了 , 这也是为什么向空对象发送消息 , 不会崩溃也不会调用的原因 .
2️⃣、根据消息调用者获取isa
#if SUPPORT_TAGGED_POINTERS
b.le LNilOrTagged // (MSB tagged pointer looks negative)
#else
b.eq LReturnZero
#endif
ldr p13, [x0] // p13 = isa
GetClassFromIsa_p16 p13 // p16 = class
由于对象的根本是 objc_object , 因此每个对象都有一个 isa 指针 , 而通过对象获取 isa 的时候 , 由于 isa 优化 ( 是否为 nonpointer_isa 以及是否是 taggedPoint ) 需要不同处理 .
如果这部分不太熟悉的同学请阅读 isa 的前世今生 , 里面有非常详细的讲述 .
汇编代码具体获取 isa 如下 :
.macro GetClassFromIsa_p16 /* src */
#if SUPPORT_INDEXED_ISA
// Indexed isa
mov p16, $0 // optimistically set dst = src
tbz p16, #ISA_INDEX_IS_NPI_BIT, 1f // done if not non-pointer isa
// isa in p16 is indexed
adrp x10, _objc_indexed_classes@PAGE
add x10, x10, _objc_indexed_classes@PAGEOFF
ubfx p16, p16, #ISA_INDEX_SHIFT, #ISA_INDEX_BITS // extract index
ldr p16, [x10, p16, UXTP #PTRSHIFT] // load class from array
1:
#elif __LP64__
// 64-bit packed isa
and p16, $0, #ISA_MASK
#else
// 32-bit raw isa
mov p16, $0
#endif
.endmacro
这里就获取到了 isa , 放在了 p16 寄存器中 .
其实跟 objc 源码中 getIsa 中的基本差不多 , 只不过一个是用汇编 , 一个是用 c 来实现的 .
inline Class objc_object::getIsa()
{
if (!isTaggedPointer()) return ISA();
uintptr_t ptr = (uintptr_t)this;
if (isExtTaggedPointer()) {
uintptr_t slot =
(ptr >> _OBJC_TAG_EXT_SLOT_SHIFT) & _OBJC_TAG_EXT_SLOT_MASK;
return objc_tag_ext_classes[slot];
} else {
uintptr_t slot =
(ptr >> _OBJC_TAG_SLOT_SHIFT) & _OBJC_TAG_SLOT_MASK;
return objc_tag_classes[slot];
}
}
3️⃣、遍历缓存哈希桶并查找缓存中的方法实现
汇编源码 : CacheLookup
.macro CacheLookup
// p1 = SEL, p16 = isa
ldp p10, p11, [x16, #CACHE] // p10 = buckets, p11 = occupied|mask
#if !__LP64__
and w11, w11, 0xffff // p11 = mask
#endif
and w12, w1, w11 // x12 = _cmd & mask
add p12, p10, p12, LSL #(1+PTRSHIFT)
// p12 = buckets + ((_cmd & mask) << (1+PTRSHIFT))
ldp p17, p9, [x12] // {imp, sel} = *bucket
1: cmp p9, p1 // if (bucket->sel != _cmd)
b.ne 2f // scan more
CacheHit $0 // call or return imp
2: // not hit: p12 = not-hit bucket
CheckMiss $0 // miss if bucket->sel == 0
cmp p12, p10 // wrap if bucket == buckets
b.eq 3f
ldp p17, p9, [x12, #-BUCKET_SIZE]! // {imp, sel} = *--bucket
b 1b // loop
3: // wrap: p12 = first bucket, w11 = mask
add p12, p12, w11, UXTW #(1+PTRSHIFT)
// p12 = buckets + (mask << 1+PTRSHIFT)
ldp p17, p9, [x12] // {imp, sel} = *bucket
1: cmp p9, p1 // if (bucket->sel != _cmd)
b.ne 2f // scan more
CacheHit $0 // call or return imp
2: // not hit: p12 = not-hit bucket
CheckMiss $0 // miss if bucket->sel == 0
cmp p12, p10 // wrap if bucket == buckets
b.eq 3f
ldp p17, p9, [x12, #-BUCKET_SIZE]! // {imp, sel} = *--bucket
b 1b // loop
3: // double wrap
JumpMiss $0
.endmacro
CacheLookup 有三种情况 , NORMAL , GETIMP , LOOKUP . 我们这里先走的是 NORMAL 情况 .
根据我们前面提到 类的结构 , 8 个字节 isa + 8 个字节 superClass , 然后就是 cache_t 了 .
ldp p10, p11, [x16, #CACHE] // p10 = buckets, p11 = occupied|mask
and w12, w1, w11 // x12 = _cmd & mask
add p12, p10, p12, LSL
-
3.1 、 这里就是偏移 16 字节 , 获取到
cache_t中的buckets和occupied放到p10,p11中 . 然后将方法名强转成cache_key_t与mask进行与运算 ( and 指令即是 & )-
这里稍微描述一下 , 首先我们已经知道
mask的值是缓存中桶的数量减 1,一个类初始缓存中的桶的数量是 4 ,每次桶数量扩容时都乘 2 。 -
也就是说
mask的值的二进制的所有bit位数全都是 1,那么方法名转成cache_key_t和mask进行与操作时也就是取其中低mask位数来命中哈希桶中的元素。 -
因此这个哈希算法所得到的
index索引值一定是小于缓存中桶的数量而不会出现越界的情况。 -
方法查找时是这个流程 , 那么存的时候 也一定是这样 . 下文我们会继续讲述 .
-
-
3.2 、 当通过哈希算法得到对应的索引值后 , 循环遍历比较所要查找的 方法名与桶中所存储方法名 , 每次查找索引值
index--.- 找到则
CacheHit $0, 直接call or return imp - 没有找到
key则if $0 == NORMAL cbz p9, __objc_msgSend_uncached. - 找到符合的
key, 但是没有对应imp, 哈希冲突 ,index--继续查找 .
- 找到则
4️⃣、 缓存没有查找到 调用 : __objc_msgSend_uncached .
STATIC_ENTRY __objc_msgSend_uncached
UNWIND __objc_msgSend_uncached, FrameWithNoSaves
MethodTableLookup
TailCallFunctionPointer x17
END_ENTRY __objc_msgSend_uncached
MethodTableLookup 源码如下 :
.macro MethodTableLookup
SignLR
stp fp, lr, [sp, #-16]!
mov fp, sp
/*省略*/
// receiver and selector already in x0 and x1
mov x2, x16
bl __class_lookupMethodAndLoadCache3
.endmacro
class_lookupMethodAndLoadCache3 就来到了 C 函数的流程 , 也就是我们所说的 类和父类消息查找以及转发流程 .
对这部分感兴趣的同学可以阅读 探索OC方法的本质 与 OC方法查找与消息转发
这两篇文章中我们详细探索了方法的本质和方法查找的完整流程 .
3.5 存储缓存
在知道了方法调用时 , 如何查找缓存 , 我们来看下当没有找到缓存 ( 也就是结束汇编查找来到了 C 函数的部分 ) 时, 对方法如何进行存储到缓存的 . 达到临界值时又是如何扩容以及存储的 .
在 OC方法查找与消息转发 中我们说过 , 查找完自己的类以及父类的方法列表后 .
- 如果找到
imp, 会调用到log_and_fill_cache. - 如果没找到
imp, 首先会有一次动态方法解析的机会 , 最后会来到 获取到resolveInstanceMethod中返回的imp并且进行cache_fill.
源码如下 : ( 截取片段 )
/**查找本类 */
{
Method meth = getMethodNoSuper_nolock(cls, sel);
if (meth) {
log_and_fill_cache(cls, meth->imp, sel, inst, cls);
imp = meth->imp;
goto done;
}
}
/**遍历查找父类 */
unsigned attempts = unreasonableClassCount();
for (Class curClass = cls->superclass;
curClass != nil;
curClass = curClass->superclass)
{
if (imp) {
if (imp != (IMP)_objc_msgForward_impcache) {
// Found the method in a superclass. Cache it in this class.
log_and_fill_cache(cls, imp, sel, inst, curClass);
goto done;
}
}
/* 动态方法解析后 */
imp = (IMP)_objc_msgForward_impcache;
cache_fill(cls, sel, imp, inst);
log_and_fill_cache 内部也是调用的 cache_fill , cache_fill 内部调用 cache_fill_nolock , 因此我们直接来到这个方法实现 .
static void cache_fill_nolock(Class cls, SEL sel, IMP imp, id receiver)
{
cacheUpdateLock.assertLocked();
if (!cls->isInitialized()) return;
// 再查一次 , 确保没有其他线程刚好已经将该方法存储了
if (cache_getImp(cls, sel)) return;
// 取到 cls 类/元类的 cache_t
cache_t *cache = getCache(cls);
// 新的占用数 为旧的 + 1
mask_t newOccupied = cache->occupied() + 1;
mask_t capacity = cache->capacity();
if (cache->isConstantEmptyCache()) {
// 检查是否是类第一次缓存 occupied == 0 && buckets() == emptyBuckets
// cache_t 默认 为 read-only , 替换掉 .
cache->reallocate(capacity, capacity ?: INIT_CACHE_SIZE);
}
else if (newOccupied <= capacity / 4 * 3) {
// 加上本次后新的占用数如果不超过总容量的 四分之三 不作处理
}
else {
// 加上本次后新的占用数超过总容量的四分之三 , 进行扩容
cache->expand();
}
// 通过本sel查找缓存 , 找到则占用数无须增加,直接更新该 sel 对应的 imp
//没找到则占用数 + 1 , 并把 sel 与 imp 设置到这个 bucket 中
bucket_t *bucket = cache->find(sel, receiver);
if (bucket->sel() == 0) cache->incrementOccupied();
bucket->set<Atomic>(sel, imp);
}
缓存方法的填充在上述源码注释我们已经解释的非常清楚了 .
我们来看下是如何扩容的 , 以了解我们上述探索中 , 调用完 testFunc3 后 _occupied 变为 1 , _mask 为 7 的原因 .
void cache_t::expand()
{
cacheUpdateLock.assertLocked();
uint32_t oldCapacity = capacity();
uint32_t newCapacity = oldCapacity ? oldCapacity*2 : INIT_CACHE_SIZE;
if ((uint32_t)(mask_t)newCapacity != newCapacity) {
newCapacity = oldCapacity;
}
reallocate(oldCapacity, newCapacity);
}
enum {
INIT_CACHE_SIZE_LOG2 = 2,
INIT_CACHE_SIZE = (1 << INIT_CACHE_SIZE_LOG2)
};
可以看到 新容量有以下几个条件 :
- 当第一次开辟 ( mask 为 0 时 capacity 也为 0 ) , 容量为
INIT_CACHE_SIZE, 也就是1 << 2, 就是 4 . - 当
oldCapacity不为 0 , 则开辟老的容量的两倍 . - 当新容量超过
4字节 , 新开辟容量重新置为老容量 .
容量处理完之后 , reallocate , 重置哈希桶 , 这也是我们上面调用完为什么 testFunc3 之前存储的缓存没了的原因 .
3.6 疑问
🔐 1 、为什么每次扩容都要重置哈希桶 ?
🔑答 :
1️⃣ : 由于哈希表的特性 -- 地址映射 , 当每次总表扩容时 , 所有元素的映射都会失效 , 因为总容量变了 , 下标哈希结果也会改变 .
2️⃣ : 如果需要之前所有所缓存的方法都重新存储 , 消耗与花费有点过于大了 .
3️⃣ : 因此满足最新的方法会缓存的前提下 , 老的方法如果每次扩容需要重新存储 , 对于设计缓存本身的意义 ( 为了提升查找方法的效率 ) 就冲突了 .
🔐 2 、为什么缓存是在占用了 四分之三 就进行扩容呢 ? iOS 中很多处淘汰策略都采用了 3/4 处理措施 .
🔑答 :
1️⃣ : 扩容并不一定会成功 , 这样就算不成功还是能保证有空间存储 , 如果用完再扩容 , 扩容失败那么本次方法缓存就会存储失败了 , 基于最常见的
LRU( 最近最少访问原则 ) 来看 , 显然最新的方法不应该存储失败 .2️⃣ : 综合 空间 和 时间 的利用率以及 哈希冲突问题来看 , 3/4 显然是最佳处理策略 .
3️⃣ : 当为系统总是会将空桶的数量保证有
1/4的空闲的情况下 ,循环遍历查找缓存时一定会出现命中缓存或者会出现key == NULL的情况而退出循环 , 以此来避免死循环的情况发生 。
3.7 多线程下缓存的读写安全
本部分知识文章参考
3.7.1 多线程读取缓存
首先 , 读取缓存并不会进行写入操作 , 因此多个线程都是读取缓存的情况下 , 是不会有资源多线程安全问题的 , 因此 为了效率考量 , 在 _objc_msgSend 汇编读取缓存部分为了效率没有加锁的处理 .
3.7.2 多线程写缓存
在上述 expand 扩容 , 以及 cache_fill_nolock 中第一步都有一个
cacheUpdateLock.assertLocked();
/***********************************************************************
* Lock management
**********************************************************************/
mutex_t runtimeLock;
mutex_t selLock;
mutex_t cacheUpdateLock;
recursive_mutex_t loadMethodLock;
系统使用了一个全局的互斥锁 , 在填充缓存时 我们说到了写入前会 再查一次 , 确保没有其他线程刚好已经将该方法存储了 , 因此多线程写入缓存安全问题得以确保 .
3.7.3 多线程读写缓存
首先我们来思考一下 , 多线程读写缓存会发生什么问题 .
- 🔐 1、删 : 当其中一条线程写入缓存达到临界值触发扩容时 , 会丢弃掉老的方法 , 只保留本地调用的方法 . 那么其他线程读取时可能就会出现问题 .
- 🔐 2、改 : 当其中一条线程修改了
bucket中sel对应的imp, 其他线程读取同样会出现问题 . - 🔐 3、改 : 当一个线程扩容了
buckets,mask变大 , 而其他线程读取到了旧的buckets和新的mask, 就会出现越界情况 .
那么带着上述问题我们来探索下 libobjc 是如何保证线程安全的同时最大化不影响性能的需求的 .
问题 1 :
答 : 🔑 为了保证扩容清零不对其他线程读取有影响 为了解决这个问题系统将所有会访问到 Class 对象中的 cache 数据的 6 个 API 函数的开始地址和结束地址保存到了两个全局的数组中:
extern "C" uintptr_t objc_entryPoints[];
extern "C" uintptr_t objc_exitPoints[];
当某个写线程对
Class对象cache中的哈希桶进行扩充时,会先将已经分配的老的需要销毁的哈希桶内存块地址,保存到一个全局的垃圾回收数组变量garbage_refs中.然后再遍历当前进程中的所有线程,并查看线程状态中的当前 PC 寄存器中的值是否在
objc_entryPoints和objc_exitPoints这个范围内。也就是说查看是否有线程正在执行
objc_entryPoints列表中的函数 .
- 如果没有则表明此时没有任何函数会访问
Class对象中的cache数据,这时候就可以放心的将全局垃圾回收数组变量garbage_refs中的所有待销毁的哈希桶内存块执行真正的销毁操作;- 而如果有任何一个线程正在执行
objc_entryPoints列表中的函数则不做处理,而等待下次再检查并在适当的时候进行销毁。这样也就保证了读线程在访问
Class对象中的cache中的buckets时不会产生内存访问异常。
问题 2 / 3 :
答 : 🔑在上述 _objc_msgSend 汇编查找缓存部分 , 我们看到
ldp x10, x11, [x16, #CACHE] // x10 = buckets, x11 = occupied|mask
-
在整个查找缓存方法中 , 将
buckets与mask( occupied 就是 mask + 1 , mask 为 0 时 occupied 也为 0 , 无须读取 ) 读取到了x10与x11寄存器中 , 后续处理都是使用的这两个寄存器里的值 . -
而汇编指令由于本身就是最小执行单位 . ( 原子(atom)指化学反应不可再分的基本微粒,原子在化学反应中不可分割 ) , 因此绝大多数情况下 , 汇编指令可以保证原子性 .
- 为什么说绝大多数情况下 , 系统仍然可以中止正在执行的命令,这时候普通汇编指令仍然是可能被意外修改。在汇编语言层面上,提供了
lock指令前缀来保护指令执行过程层中的数据安全 . - 加了
lock修饰的单条编译指令以及这些特殊的安全指令才算是真正的原子操作 - 例 :
lock addl $0x1 %r8d
- 为什么说绝大多数情况下 , 系统仍然可以中止正在执行的命令,这时候普通汇编指令仍然是可能被意外修改。在汇编语言层面上,提供了
-
所以 只要保证读取
_buckets与_mask到x10 , x11寄存器 这条指令读取到的是互相匹配的(即要么同时是扩容前的数据,要么同时是扩容后的数据),那么即使在这个过程中该bucket被删掉了 , 也不会影响本次调用 , 因为寄存器中已经存储了 。
那么如何保证 这条指令读取到的 _buckets 与 _mask 是匹配的 , 不会被编译器优化所影响呢 ?
编译内存屏障
首先我们知道 _mask 在每次扩容永远是新值有可能会大于旧值 .
//设置更新缓存的哈希桶内存和mask值。
void cache_t::setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask)
{
// objc_msgSend uses mask and buckets with no locks.
// It is safe for objc_msgSend to see new buckets but old mask.
// (It will get a cache miss but not overrun the buckets' bounds).
// It is unsafe for objc_msgSend to see old buckets and new mask.
// Therefore we write new buckets, wait a lot, then write new mask.
// objc_msgSend reads mask first, then buckets.
// ensure other threads see buckets contents before buckets pointer
mega_barrier();
buckets = newBuckets;
// ensure other threads see new buckets before new mask
mega_barrier();
mask = newMask;
occupied = 0;
}
上述代码中注释已经写的很清楚了 , 利用编译内存屏障仅仅是保证 _buckets 的赋值会优先于 _mask 的赋值,也就是说,指令
ldp x10, x11, [x16, #CACHE]
执行后,要么是旧的 _mask 和 旧的 buckets, 要么是新的 buckets 和旧的 mask , 都不会出现越界的情况 , 综上这些手段来保证了多线程读写缓存的安全 .
至此 , 方法的缓存查找以及缓存的读取我们已经探索完毕了 .
4、 方法缓存原理总结
- 1️⃣ : OC 方法可以进行缓存 , 类方法 和 实例方法 分别存储在 元类 和 类 的结构体的
cache_t的buckets哈希桶中 . 消息发送时会先查找缓存 , 找到则不会继续方法查找和转发的流程 . - 2️⃣ :
cache_t使用capacity(mask = 0 ? mask + 1 : 0)来记录当前最大容量 . - 3️⃣ :
cache_t使用occupied来记录当前已经使用容量 . - 4️⃣ : 当使用容量到达总容量的
3/4时 , 哈希桶会进行扩容 , 扩容容量为当前容量的两倍 ( 当使用超过 4 字节不扩容 ) . 扩容时会清空历史缓存 , 只保留最新sel和imp. - 5️⃣ : 缓存的读取是线程安全的 .
关于类的基础知识 , 所涉及的知识点我们基本上都讲述完毕了 , 接下来会继续带来 iOS 相关底层知识文章 , 敬请关注 .
