

背景
由于业务需求,需要通过MQ同步商品全量数据,为了防止同步的全量数据有问题导致线上事故,保留原来全量数据,新建索引用来保存本次同步索引数据,计划通过别名来实现索引的切换。
写入索引的过程中发现日志平台大量报错:
{"error":{"root_cause":[{"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"}],"type":"
cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"},"status":403}
Caused by: org.elasticsearch.ElasticsearchStatusException: Elasticsearch exception [type=cluster_block_exception, reason=blocked by: [FORBIDDEN/
12/index read-only / allow delete (api)];]
吓尿,先暂停MQ消息的消费。百度(谷歌)了一下这个问题,发现大概原因是ES存储空间不够,索引被强制设置为只读,不能写入。这时候我决定打开kibana,查看一下节点机器的运行情况。顺利走入了一个排查问题的误区。
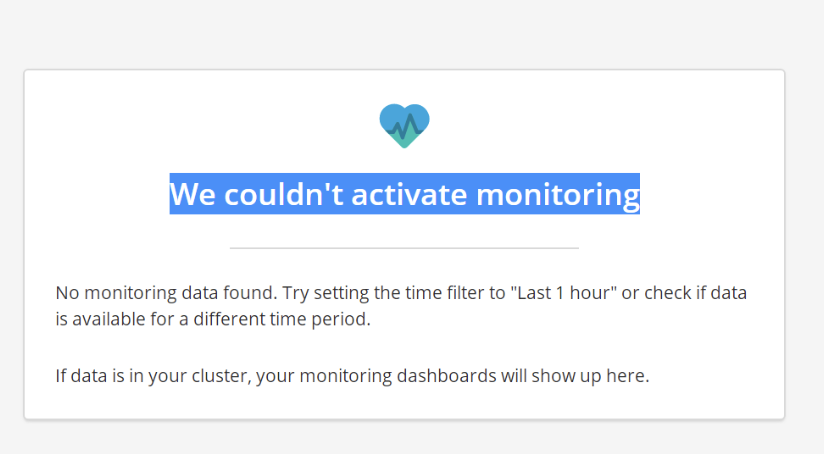
Kibana监控页面无法打开
顺利打开kibana页面,点一下左侧的monitoring菜单,发现监控提示:We couldn't activate monitoring。
看到有人说重新选举一个主节点可以解决这个问题
我重启了主节点,根据es的主节点选举,主节点重启的过程中,设置为node.master的节点有可能成为新的主节点,就这样通过重启完成了主节点的切换,发现问题依然没有解决。
接下来我又重启了kibana,发现问题依然没有解决。
最后,通过以下命令查看监控日志的生成情况:
GET /.monitoring-es-6-*/_search
{
"size": 0,
"query": {
"term": {
"type": "cluster_stats"
}
},
"aggs": {
"group_by_day": {
"date_histogram": {
"field": "timestamp",
"interval": "hour"
}
}
}
}
发现kibana的监控日志确实没有生成新的了。顿时明白,又回到了最初的问题,es索引只读不可写入状态。
es 索引 read-only
删除了之前以防万一留的索引数据,2分索引大概数据量为20g。执行以下命令
PUT _settings
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}
让es恢复到可写入状态。问题解决!
复盘
当Elasticsearch所在磁盘占用大于等于95%时,Elasticsearch会把所有相关索引自动置为只读。(官网文档)
节点上存在的3个主要索引数据大约30g,节点的磁盘大小40g,在加上一些小的索引数据,很容易就超过了阈值95%。
通过lsblk,查看节点磁盘情况,该节点磁盘被分为两个区,vda1大小为40g,vbd1大小为200g。
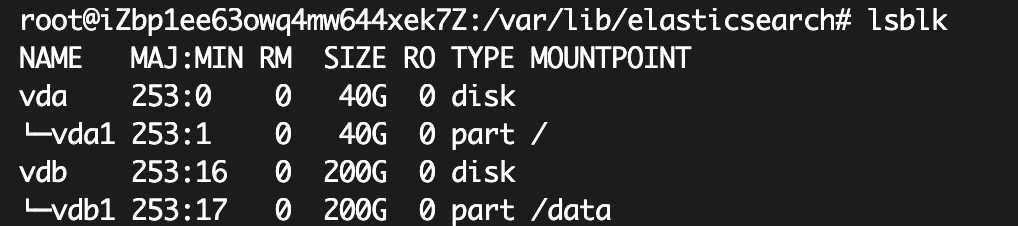
es默认的索引存储位置为home.data,通过命名df看到索引数据被存在了40g的vda1分区。

最终解决方案
修改es的配置文件elasticsearch.yml,为es 的索引和log指定新的存储分区。
path.data=
path.log=
并迁移数据文件,重启es。
