

1. 转码
使用getDict工具转码mdx为HTML或者xml, 编码格式为utf-8
转换好之后
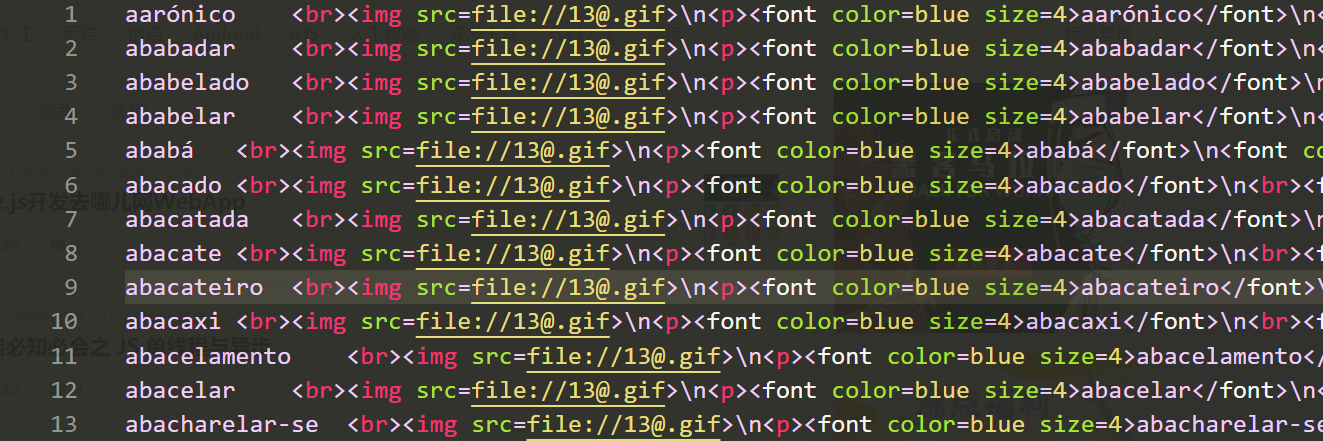
2. 正则表达式匹配移除标签
/([!a-zA-Z-_ ’'‘ÆÐƎƏƐƔIJŊŒẞÞǷȜæðǝəɛɣijŋœĸſßþƿȝĄƁÇĐƊĘĦĮƘŁØƠŞȘŢȚŦŲƯY̨Ƴąɓçđɗęħįƙłøơşșţțŧųưy̨ƴÁÀÂÄǍĂĀÃÅǺĄÆǼǢƁĆĊĈČÇĎḌĐƊÐÉÈĖÊËĚĔĒĘẸƎƏƐĠĜǦĞĢƔáàâäǎăāãåǻąæǽǣɓćċĉčçďḍđɗðéèėêëěĕēęẹǝəɛġĝǧğģɣĤḤĦIÍÌİÎÏǏĬĪĨĮỊIJĴĶƘĹĻŁĽĿʼNŃN̈ŇÑŅŊÓÒÔÖǑŎŌÕŐỌØǾƠŒĥḥħıíìiîïǐĭīĩįịijĵķƙĸĺļłľŀʼnńn̈ňñņŋóòôöǒŏōõőọøǿơœŔŘŖŚŜŠŞȘṢẞŤŢṬŦÞÚÙÛÜǓŬŪŨŰŮŲỤƯẂẀŴẄǷÝỲŶŸȲỸƳŹŻŽẒŕřŗſśŝšşșṣßťţṭŧþúùûüǔŭūũűůųụưẃẁŵẅƿýỳŷÿȳỹƴźżžẓ]+)</font>/
const express = require('express');
const fs = require('fs');
let path = require('path');
fs.readFile('./dic_dhz.txt', 'utf-8', (err, data) => {
if (err) {
console.log(err);
} else {
// 将MDX 词典分条处理
let arr = data.split('\r\n');
arr.forEach((ele, index) => {
arr[index] = ele + "_end"
})
// 每一条转换为固定的数据结构
let dic_fixed_structure = {};
console.log('********分割线********');
arr.forEach((ele, index, self) => {
let item = {};
//获取单词名称
let wordName = ele.match(/<font color=blue size=4>([!a-zA-Z\-_ ’‘ÆÐƎƏƐƔIJŊŒẞÞǷȜæðǝəɛɣijŋœĸſßþƿȝĄƁÇĐƊĘĦĮƘŁØƠŞȘŢȚŦŲƯY̨Ƴąɓçđɗęħįƙłøơşșţțŧųưy̨ƴÁÀÂÄǍĂĀÃÅǺĄÆǼǢƁĆĊĈČÇĎḌĐƊÐÉÈĖÊËĚĔĒĘẸƎƏƐĠĜǦĞĢƔáàâäǎăāãåǻąæǽǣɓćċĉčçďḍđɗðéèėêëěĕēęẹǝəɛġĝǧğģɣĤḤĦIÍÌİÎÏǏĬĪĨĮỊIJĴĶƘĹĻŁĽĿʼNŃN̈ŇÑŅŊÓÒÔÖǑŎŌÕŐỌØǾƠŒĥḥħıíìiîïǐĭīĩįịijĵķƙĸĺļłľŀʼnńn̈ňñņŋóòôöǒŏōõőọøǿơœŔŘŖŚŜŠŞȘṢẞŤŢṬŦÞÚÙÛÜǓŬŪŨŰŮŲỤƯẂẀŴẄǷÝỲŶŸȲỸƳŹŻŽẒŕřŗſśŝšşșṣßťţṭŧþúùûüǔŭūũűůųụưẃẁŵẅƿýỳŷÿȳỹƴźżžẓ]+)<\/font>/);
// 截取字符串, 分类处理
let types = ele.split(`<font color=red>`);
// 如果单词存在的情况下
if (wordName) {
// 如果是动词
if (ele.indexOf('v.t.') !== -1 || ele.indexOf('v.r.') !== -1) {
item.word = wordName[0].match(/>([\d\D]+)</)[1];
let attrName = item.word.trim()
dic_fixed_structure[attrName] = {};
/***
* @该单词是主动词
* */
if (ele.indexOf('v.t.') !== -1) {
// 单词赋值
item.word = wordName[0].match(/>([\d\D]+)</)[1];
item.index = index;
var itemStr = ''
// 获取v.t.
for (let i = 0; i < types.length; i++) {
if (types[i].indexOf('v.t.') !== -1) {
itemStr = types[i];
}
}
// 获取意思数组
var meaningsArr = itemStr.split(`<font color=darkblue>`);
// console.log(meaningsArr);
var newArr = [];
meaningsArr.forEach((ele, index) => {
var str = ele.replace(/<[\d\D]+?>/g, '').replace('\\n_end', '').replace('v.t.', '').split("\\n").join('');
// console.log(str);
if (str !== '') {
newArr.push(str)
}
});
if (newArr.length === 1) {
newArr[0] = "(1)" + newArr[0]
}
dic_fixed_structure[attrName].vt = newArr;
}
/**
* @该单词是反身动词
* */
if (ele.indexOf('v.r.') !== -1) {
// 单词赋值
item.word = wordName[0].match(/>([\d\D]+)</)[1];
item.index = index;
var itemStr = '';
// 获取v.r.
for (let i = 0; i < types.length; i++) {
if (types[i].indexOf('v.r.') !== -1) {
itemStr = types[i];
}
}
// 获取意思数组
var meaningsArr = itemStr.split(`<font color=darkblue>`);
var newArr = [];
meaningsArr.forEach((ele, index) => {
var str = ele.replace(/<[\d\D]+?>/g, '').replace('\\n_end', '').replace('v.r.', '').split("\\n").join('');
if (str !== '') {
newArr.push(str)
}
});
if (newArr.length === 1) {
newArr[0] = "(1)" + newArr[0]
}
dic_fixed_structure[attrName].vr = newArr;
}
}
}
});
console.log(dic_fixed_structure);
fs.writeFile('./dic/dic' + new Date().getTime() + '.json', JSON.stringify(dic_fixed_structure), (err, data) => {
if (err) console.log(err)
})
}
})
生成JSON文件,用于后续写入word。

3. json写入word
下载officegen生成器
const officegen = require('officegen')
const fs = require('fs')
// Create an empty Word object:
let docx = officegen('docx')
// 完成监听:
docx.on('finalize', function (written) {
console.log('Finish to create a Microsoft Word document.')
})
// 错误监听:
docx.on('error', function (err) {
console.log(err)
})
// 创建段落
var data = fs.readFileSync('./dic/dic1569026153874.json', 'utf-8');
var num = 0;
var frequent1720 = fs.readFileSync('./1700frequentWord.json', 'utf-8');
let genWord = (data) => {
let pObj = docx.createP();
// A-Z排序的全部单词
var keys = Object.keys(data);
// 1720排序的全部单词
// var keys = JSON.parse(frequent1720);
console.log(keys)
// console.log(keys);
for (var i = 0; i < keys.length; i++) {
var word = keys[i];
if (data[word]) {
num = num + 1;
pObj.addText(word + "\r\n", { font_size: 16, color: '0022aa', link: 'https://dicionario.priberam.org/' + word });
}
// if (data[word] && data[word].vt) {
// let arr = data[word].vt;
// pObj.addText('[v.t.] : ', { font_size: 10, bold: true, color: '881100', })
// for (var j = 0; j < arr.length; j++) {
// pObj.addText(arr[j] + "\r\n", { font_size: 10, color: '000000' })
// }
// }
// if (data[word] && data[word].vr) {
// let arr = data[word].vr;
// pObj.addText('[v.r.] : ', { font_size: 10, bold: true, color: '881100' })
// for (var x = 0; x < arr.length; x++) {
// pObj.addText(arr[x] + "\r\n", { font_size: 10, color: '000000' })
// }
// }
// if (data[word]) {
// pObj.addLineBreak()
// }
}
}
genWord(JSON.parse(data));
// Let's generate the Word document into a file:
let out = fs.createWriteStream('exampleWord.docx')
out.on('error', function (err) {
console.log(err)
});
// Async call to generate the output file:
docx.generate(out);
console.log(num)
// pObj.options.align = 'right'
// pObj = docx.createP()
// pObj.addLineBreak()
// docx.putPageBreak()
// docx.putPageBreak()
// pObj = docx.createP()
// pObj.addImage('some-image.png');

MDX生成word词典大功告成,耶✌!
