

RN 热更新Node服务cpu占用从80% 优化到20% 记录
先看优化前后结果对比 优化前

优化后

先聊下背景,过年前半路接手团队的 RN的热更新的服务端开发,服务端采用的是 Express + Mysql,是拿 github 上一个开源服务改的 主要给React Native 项目提供热更,就是每次打开App,会发起一个请求,看当前App是否需要更新,目前已经用在 趣头条的 IOS端,集团萌推等一些项目上面,请求量还算比较大的,QPS 在 500 上下浮动,
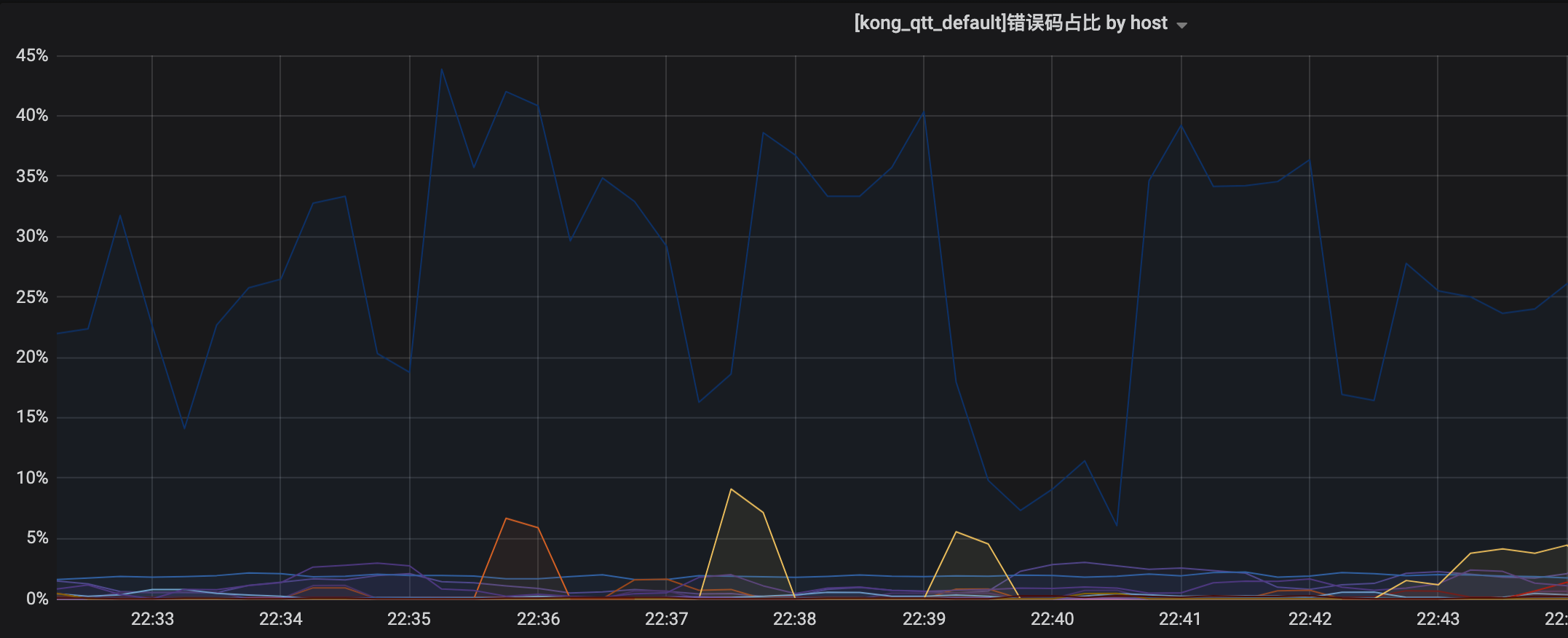
之前这个项目经常报警,网关Kong 上面的日志显示40%的504 状态码(网关连接超时,本质就是服务响应不过来),当时粗暴的处理了下,同事写了个脚本,cpu到到阀值就杀掉服务重启

过年来,添加了新的需求,然后我就发到线上了,三天2头的报警,还经常是大晚上,,给我气的要死,无法忍受了,决定好好整整,优化一把,下面是我整个流程的一个记录

这次不是这台服务器,而是 Redis 报警了!,手忙脚乱的,回滚项目,看日志
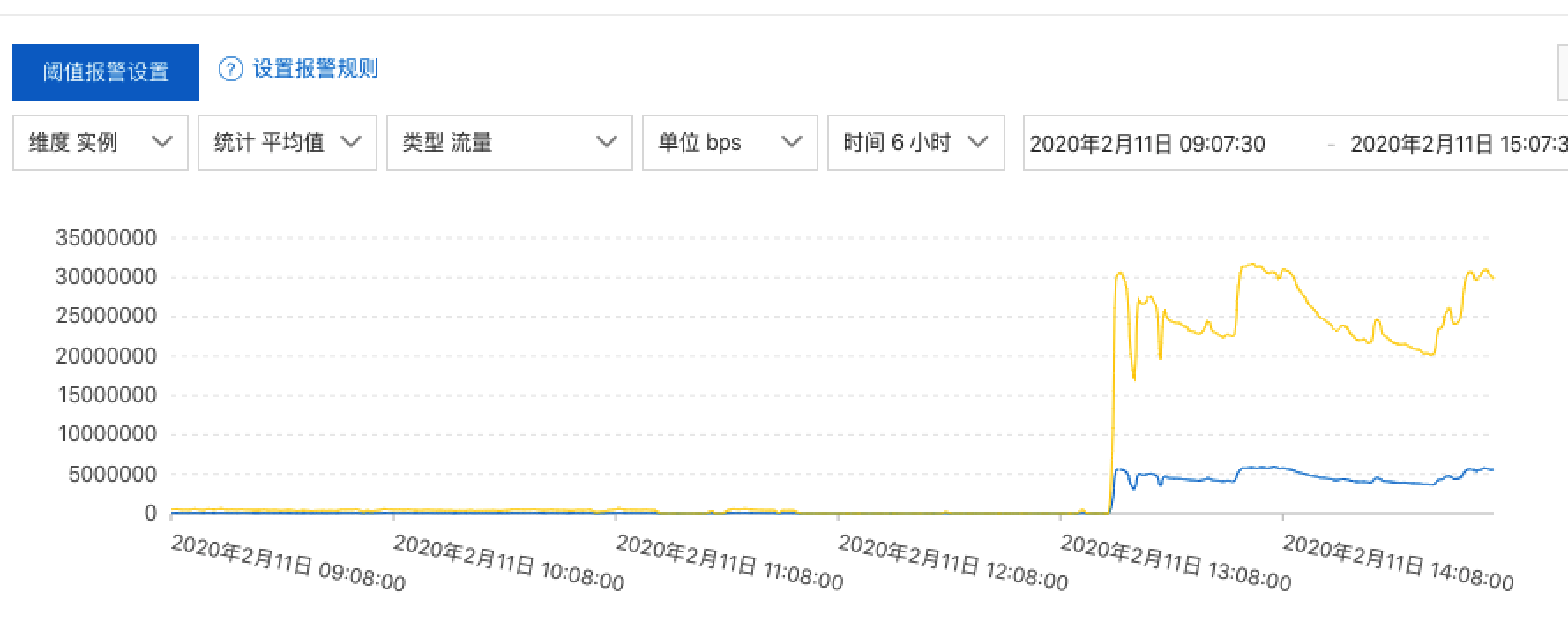
从图上可以看到 用上 Redis 后,Redis 连接数飙升,快要到最大值了,Redis还丢弃了很多连接,头大头大了,以为上了 Redis 就是银弹,没想到新问题又来了,运维说要不加机器,要不 Redis 改成长连接,加机器是不可能的,思考一会,猜测是自己代码里是不是有些地方 redis 连接是不是没有关,检查代码,发现下面一段代码
return redisClient
.getAsync(redisCacheKey)
.then(data => {
if (data) {
try {
log.info("get data from cache");
var obj = JSON.parse(data);
// redisClient.quit() // 少了这行代码
return obj;
} catch (e) {
// redisClient.quit() 少了这行代码
log.error(`JSON.parse error:${data}`)
}
}
}).then(....一堆代码)
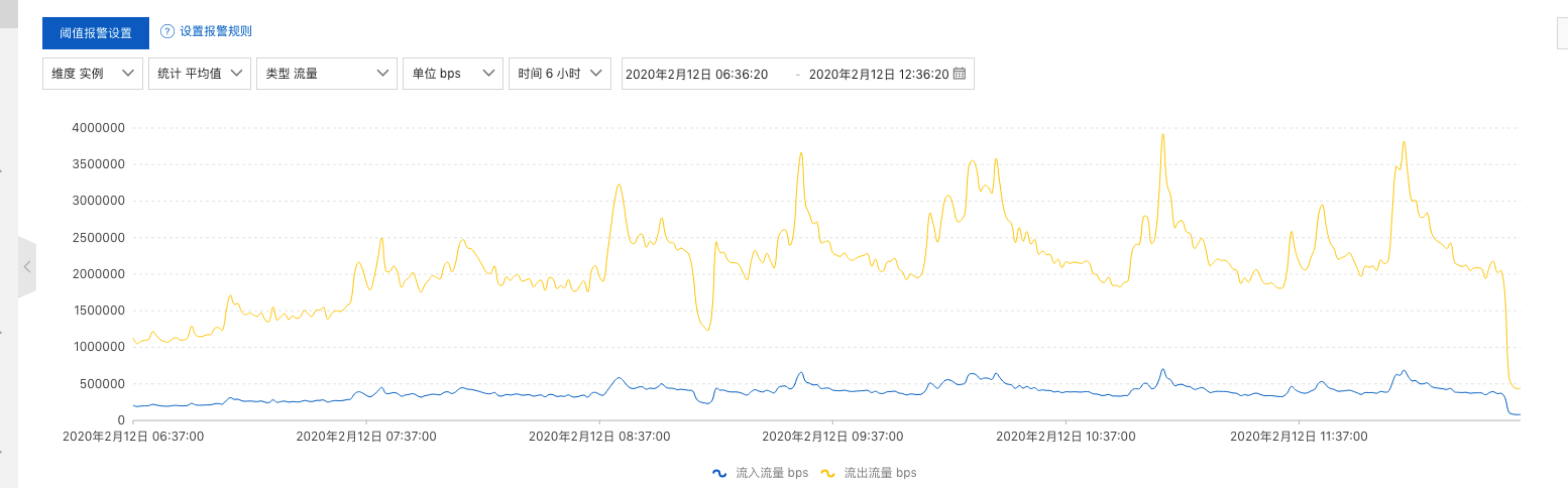
真想抽自己耳光,赶紧在 加上上面注释的2行代码,发布上线,Reids 曲线降下来了,一些,没有之前那么多了,但连接数还是不少
稍微平复下心情,盯着日志看,分析分析,思考下来,这个服务,app打开就会请求一次,虽然用 Redis 做了缓存,但有的版本实际是没有热更的需求的,但是都得经过去redis 查询下缓存,看有没有数据,而且这样的请求还非常多,就相当于 我要看今天有没有课,得走进教学楼,到教室里面,看看有没有人,然后确定有没有课,太浪费时间了,要是在教学楼前面有个告示,就知道今天上不上课,不就好了么,对应的,我在请求进来,在路由那做一层拦截不就好了,于是我就做了个内存缓存,创建了 size 最大为 200 的 map,请求进来,先看看 map 里面有没有,没有就直接返回,不耽搁时间,也不占用 cpu,在新发布版本的时候,clear 掉这个map 就好
const NOTFOUND_MAP = new Map();
const NOTIN_WHITELIST_MAP = new Map();
function clearNotFoundMap() {
NOTFOUND_MAP.clear();
}
function setNotFoundMap(key) {
if (NOTFOUND_MAP.size > 200) {
NOTFOUND_MAP.delete(NOTFOUND_MAP.keys().next().value);
}
NOTFOUND_MAP.set(key, true);
}
function getNotFoundMap(key) {
return NOTFOUND_MAP.get(key);
}
module.exports = {
clearNotFoundMap,
getNotFoundMap,
setNotFoundMap,
clearNotWhiteListdMap
};
改完上线,然后先看了 下 Redis 曲线
再看下 cpu 占用

效果也挺好,从 平均 80% 降到 20%,效果也非常明显,从这以后,到目前位置也没有报警大半夜来骚扰了,睡个安稳觉
基本上就完成了本次优化思路,总结下来就是不要急,遇到问题先回滚代码,仔细分析日志,业务流程,一定是能找到问题点
插一句,最开始 运维给我讲 Kong 报的 4xx|5xx 问题非常多,当时没有看监控曲线,我以为报是 都是500,就想到是代码问题,然后检查代码里面做全局的错误 捕获,但是日志显示没有 500 错误,但是 node 是异步的,异步的错误, expres 这种框架如果自己不处理,是捕获不到的,接下来我会写一篇,Node.js 里面怎么样 友好的设计一个全局的异常处理,就像 Java那样,在最外层捕获异常,漂亮的很
如果你喜欢也可以关注我的 公众号 「chromedev」

