

LinkedHashMap 数据结构
这篇文章需要先了解 HashMap 的相关知识,详情可以参考这篇文章
由于 LinkedHashMap 是通过集成 HashMap 实现的,所以它本身会用到 HashMap 的数据结构,即:数组+链表(或红黑树, java8),这里主要分析 LinkedHashMap的数据结构,可以查看下图:
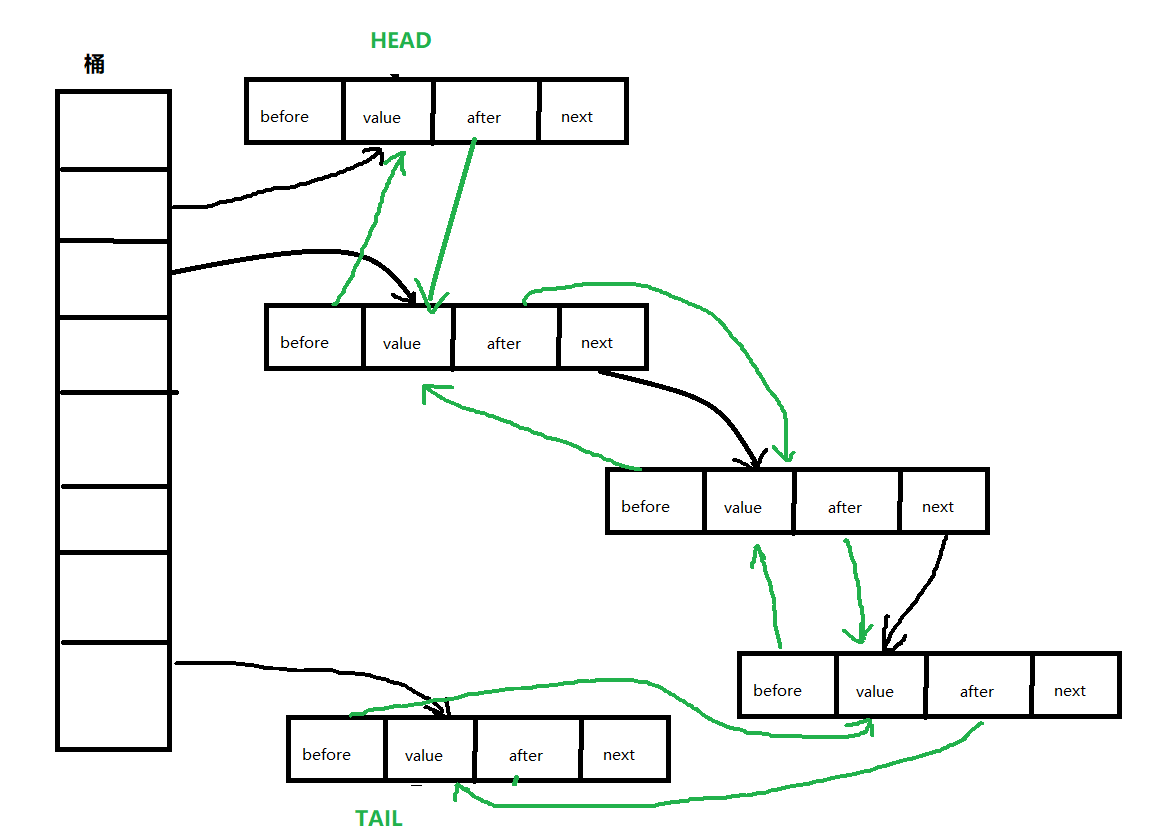
其中黑色部分是 HashMap 的数据结构(数组+单向链表),绿色箭头链接起来的是一个双向链表,是 LinkedHashMap 所维护的数据结构。
其实我们可以看到,它主要是在 HashMap 的 Node 的基础上,添加了额外两个变量(指针),before 和 after ,供双向链表使用,根据构造函数的 accessOrder 参数以不同的顺序(访问顺序或者插入顺序)来连接 HashMap 中各个节点。
这样通过增加很小的内存空间(before 和 after 两个指针),重复利用节点就可以实现有序性,当我们迭代 LinkedHashMap 中的元素就可以从链表的 HEAD 开始顺序读取元素,达到一种有序的遍历。
源码分析
这里我们主要挑选几个比较重要的方法来讲述 LinkedHashMap 是怎样维护链表的顺序的:get(Object)、afterNodeInsertion(Node)、afterNodeRemoval(Node) 和 afterNodeAccess(Node)。
讲这些方法前,我们需要先了解 LinkedHashMap.Entry 类,这个是存储节点数据的关键:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
也就是上图中的:

从这个类可以看到,LinkedHashMap.Entry<K,V> 是继承自 HashMap.Node<K,V> 的,并且比 HashMap.Node<K,V> 多了两个变量 before 和 after 用来指向节点的上一个节点和下一个节点。
通过覆写 HashMap.newNode() 方法来创建 LinkedHashMap.Entry<K,V> 节点:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 创建成功后添加到双向链表的末尾
linkNodeLast(p);
return p;
}
- get(Object) 方法和 afterNodeAccess(Node) 方法。
public V get(Object key) {
Node<K,V> e;
// 通过 HashMap 的 getNode() 方法获得 key 对应的节点
if ((e = getNode(hash(key), key)) == null)
return null;
// 如果是根据访问顺序来排序,则将节点添加至末尾
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
// afterNodeAccess具体实现
// 主要是维护双向链表的指针,删除对应节点,并将其添加至链表末尾
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
只有当构造 LinkedHashMap 的时候 accessOrder 为 true 时,才会根据访问顺序将元素放置双向链表最末尾。
- afterNodeInsertion(Node) 方法
这个方法是 HashMap.putVal() 中的一个钩子(hook),在添加了新的元素之后判断是否需要删除最早(插入的顺序,或者访问的顺序)的元素。这个方法会在后面的 LRU算法 中讲到。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 判断是否需要删除节点
// 其中 removeEldestEntry
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
- afterNodeRemoval(Node) 方法
这是 HashMap.removeNode() 中的一个钩子(hook)方法。
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
这里主要做的是也就是在双向链表中删除指定节点。
Tips: 可能小伙伴会有疑问,当链表转换成树的时候怎么办?即 HashMap 中当链表长度大于等于8时转换成红黑树。
其实我们看 HashMap 中树节点的类 TreeNode<K,V> 就可以知道,其实它是继承 LinkedHashMap.Entry<K,V> 的:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
...
}
这样我们也可以把 TreeNode<K,V> 树节点也当作一个双向链表节点使用。
为什么使用双向链表
因为这样我们可以很方便的删除元素和添加元素,时间复杂度基本是 O(1)。
我们可以利用 HashMap 在 O(1) 的时间找到节点(getNode 方法),然后通过这个节点的前后指针很容易的删除节点,而不需要像单向链表那样通过遍历链表来找这个节点的前一个节点,然后再删除。
LRU算法实现
LRU(Least Recently Used,最近最少使用的)算法主要应用于内存缓存中,在使用的内存达到限制的内存时需要淘汰最近最少使用的元素。这里利用 LinkedHashMap 很方便地实现这个算法。
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
// 当元素容量超过限制容量将返回 true
// 然后 afterNodeInsertion 方法中会删除双向链表的 head 节点
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
}
