

多线程程序、多进程程序是当前单机应用常用并行化的手段,线程是可以直接被CPU调度的执行单元,虽然多进程程序中每个进程也可以是多线程的,但是本文主要讨论的多进程程序默认是每个进程都有一个单独线程的情况。多线程程序和多进程程序,涉及到的线程间和进程间的通信、同步原语基本都是相同的,所以两者的开发在一定程度上有着高度的相似性,但同时差异化也十分的明显,所以高性能程序使用多线程还是多进程实现常常也是争论的焦点。
虽然自己之前开发的程序基本都是基于pthreads和C++ std::thread的多线程程序,但是多进程程序还是有它相应的用武之地的,比如大名鼎鼎的Nginx中master和worker机制就是采用多进程的方式实现的,所以这里也对多进程和多线程程序的区别联系整理一下,最后顺便看看Nginx中master和worker进程的管理和实现机制,在后续开发多进程程序的时候可以直接借鉴使用。
一、多线程和多进程程序
Linux中有一句耳熟能详的话——线程被认为是轻量级的进程,在现代操作系统的概念中,进程被认为是资源管理的最小单元,而线程被认为是程序执行的最小单元,所以多线程和多进程之间的差异基本体现在执行单元之间对资源耦合度的差异。虽然对于用户空间而言,最为广为使用的pthreads线程库提供了自己一套线程创建和管理、线程间同步接口,其实在Linux下面创线程和创建进程都是使用clone()系统调用实现的,只是在调用参数(flags)上不同,导致创建的执行单元具有不一样的资源共享情况,从而造就了线程和进程实质上的差异。
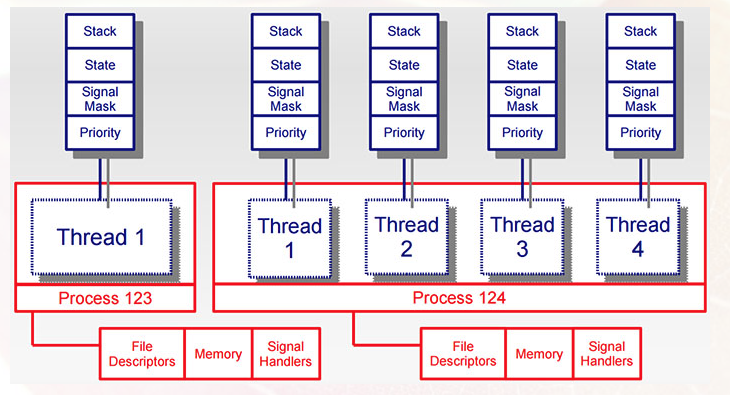
1.1 多线程的特点 multi-threaded
从上面的图中看出,同一个进程中的多个线程,跟执行状态相关的资源都是独立的,比如:运行栈、优先级、程序计数器、信号掩码等都是独立的,而打开的文件描述符(包含套接字)、地址空间(除了函数中的自动变量属于栈管理,还有新提出来的线程局部变量,其它基本都是共享的)都是共享的。这里还设计到信号处理句柄、信号掩码等,因为在多线程中信号的问题比较的复杂,后面单独列出来解释。
共享相同的地址空间、文件描述符给程序的开发带来了极大的便利,创建多线程的开销要小的多,而且在运行中任务切换损失也很小,很多的缓存都维持有效的,还有比如负责套接字listen的线程和工作线程之间可以方便的传递网络连接创建的套接字,生产线程和消费线程可以方便的用队列进行数据交换,程序设计也可以特化出日志记录、数据落盘等工作线程各司其职。但是天下没有免费的午餐,任何的便利都是需要付出代价的,多个执行单元可以访问资源意味着共享资源必须得到保护和同步,这是多线程程序设计不可回避的问题:
(1). 多个线程可以安全的访问只读的资源,但是哪怕只有一个修改者也是不安全的,额外说一句,我们说的保护是保护的资源,而不是行为;
(2). 传统很多库函数都不是线程安全的,这些函数当初设计的时候没有考虑到多线程的问题,所以使用了大量的全局变量和静态局部变量,这些函数是不可重入的。所以在你调用库函数、链接别人库的时候,一定要看看有没有”_r”后缀的版本;
(3). 还要就是之前不断被提到的内存模型,因为同个进程中的多个线程可能会并行的执行,这时候如果在线程之间有高速度的数据同步需求的时候,必须让资源的更新能够及时地被别的线程感知到;
(4). 多线程程序正因为线程之间共享的资源太多,所以如果一个线程出现严重的问题,其余的线程也会被杀死。遥想当年在TP-LINK的时候,所有的服务功能都以线程的形式被包裹在一个用户进程中,某个模块出现问题都可能导致上不了网需要重启,所以现在看来稳定运行的TP-LINK路由器不得不说是一个奇迹~
1.2 多进程的特点 multi-process
多进程程序之间保证了资源的高度隔离,只在创建出来的父子进程之间有少量的联系,进程组、回话等就不在此讨论了。
这个时候需要共享的资源必须显式共享,虽然操作系统优化机制可以让他们的只读数据(比如执行代码)物理上共享,进程间的资源共享或者通过关联到文件系统的某个路径或者文件,或者通过全局字符串名字方式,通过以某个进程首先创建资源,其他进程打开资源的方式共享。由于历史原因,Linux进程间通信通常包含SYS V和Posix两套接口,其种类和功能大同小异,但是个人的实际感受Posix的操作接口要更加的好用一些。
Linux进程间通信通常用到的方法有:匿名管道、命名管道、信号、消息队列、共享内存、信号量和套接字,其中匿名管道只用于有亲属关系的父子进程之间的一种单功通信方式,在fork()创建进程之前创建匿名管道。其中个人用的最多的是命名管道、共享内存和信号量:命名管道由于返回的文件描述符,可以十分方便的融合到现有的select/poll/epoll框架下面去;信号量主要用于模拟进程间互斥的行为;共享内存用于进程间大规模的数据共享。陈硕的一句名言就是“在多进程之间共享内存无异于掩耳盗铃”,其实多进程间通过共享内存的方式共享数据弊端和限制确实很多:首先共享内存中不能共享指针,而指向共享内存段本身的指针也最好用便宜的方式退化指针;如果共享内存的数据经常会被修改,那更是个灾难。当然简单只读数据是可以的,比如Nginx的缓存也使用了共享内存。
多进程程序的好处,就是消除了进程之间的耦合度后,操作系统的保护机制可以让多个进程更加的独立可靠,而且分成多个进程之后管理进程比管理线程方便灵活的多;同时,多进程程序可以实现进程的特异化管理,比如在Nginx设计中master process是特权进程,可以读取配置文件、修改数重要数据等关键操作,而worker process是普通权限进程,只负责业务方面的处理,符合系统管理中的最小化权限原则;再有就是多进程程序可以进行业务的热更新平滑升级,下面的Nginx算是将这一功能使用的淋漓尽致啊。
但是多进程的程序也有个问题,就是很多共享的资源、同步的手段都是命名全局的,很有可能进程意外退出后这些资源都得不到回收,补救的办法只能是重启操作系统,汗~
1.3 多线程程序和信号
感觉信号一直是Linux平台下开发比较头疼的问题,尤其对于多线程情况下的程序,信号的处理将更加的复杂。
1.3.1 单线程程序中信号的处理方式
Linux中的信号的处理方式可以是SIG_IGN、SIG_DFL以及自己通过sigaction设置自定义处理函数,进程创建的时候信号都有默认的处理方式,而用户可以后续选择忽略、默认处理方式、自定义处理这些信号(SIGKILL、SIGSTOP两个信号只能默认处理方式,不能被忽略或者重定义处理),当进程接收到信号的时候就会转向信号处理历程去执行。
信号可以在某些情况下被系统发送(比如触发段错误),或者被别的进程使用kill发送,或者进程自己调用kill、raise系统调用触发信号。进程可以通过signal mask去block某些信号,默认情况下是没有信号被block的,此时如果被block的信号发送过来了,将会被设置为pending的,然后一旦该进程unblock了该信号,pending的信号将会立即被传递。
1.3.2 pthreads库多线程环境对信号处理的方式
pthreads库多线程中信号处理的方式,和信号的种类、各个线程对信号的mask状态共同决定的。
Linux中多线程环境下信号的种类可以分为同步(Synchronously)信号和异步(Asynchronously)信号:同步信号是针对某个线程的,比如某个线程执行过程中除以零(SIGFPE)、访问非法地址(SIGSEGV)、使用了broken的管道(SIGPIPE),这些信号都根某个特定的线程特定的执行上下文有关,还有就是同个进程中线程之间通过pthread_kill显式发送信号的情况;异步信号主要是其他进程向该进程通过kill向这个进程(而非其中的线程)发送信号,并不跟某个特定的线程相关联的情况。
pthreads库中多线程之间共享sigaction结构但是不共享sig_mask结构,这意味所有的线程共享相同的信号处理方式,而不论信号处理方式是谁设置的。进程在最初fork()后创建的第一个线程继承了其signal mask,而通过pthread_create创建的其他线程也继承了这个信号mask,后续可以通过pthread_sigmask接口控制本线程对某些信号的block或者unblock。
有了上面的知识,信号在多线程下的行为就可以被确定了:
(1). 所有的线程共享相同的sigaction,所以所有进程对某个信号的处理方式是完全相同的;
(2). 同步信号是针对某个特定线程的,该线程是否接收处理这个信号看其signal mask设置情况;
(3). 异步信号是针对这个进程的,当这种信号到达的时候,进程会从没有block这个信号的线程集合中随机选出一个出来处理这个信号,如果所有的线程都block该信号,那么这个信号将被pending起来,直到有线程unblock这个信号,就将其发送给那个线程处理;
二、master管理多个worker进程
在Nginx的配置文件中有个条目worker_processes,其用于指定master进程可以产生几个worker进程,默认情况下是CPU执行单元的数目。在Linux下实验发现,当kill掉worker进程的时候,master进程会自动再次启动worker进程,但是当kill掉master进程的时候,worker进程仍然活着并向外提供服务,这种方式或许是对于常驻服务最好的处理语义:master进程存在的时候会保证设定数目的工作进程存在,而master进程挂掉的时候worker进程仍然继续服务,不会存在单点故障导致服务立即停止的情况。
其基本原理也很简单,这源于在Linux平台下,当子进程退出的时候,内核会向父进程发送SIGCHLD信号,父进程可以捕获这个信号,并通过wait系统调用搜集子进程退出的相关信息,此后子进程的资源会被相应的释放掉。因此,父进程可以通过接收信号的方式异步得到子进程退出的消息,并且适当安排创建工作者进程。
当然,这仅仅是一个小trick,探究一下,发现Nginx的设计中,尤其是多进程服务端程序的开发维护中,大有学问可以借鉴!同时还有一个跟Nginx关系十分密切,估计也是使用相同master-worker方式构建的多进程的构架的,那就是php-fpm。之所以说关系密切,就是因为Apache本身支持php的解析,而Nginx只能通过外挂的方式,而挂件最常见的恰巧就是php-fpm了,通过ps查看,其也像是master-worker的结构,不过没看代码尚且不敢断定。
2.1 跟踪环境的配置
不知道啥时候,自己都快成了代码控了,GitHub上面一些感兴趣的项目代码都会clone下来并不断pull跟踪,nginx就是其中之一啊。调试环境设置很简单,只是有些点需要额外注意一下
root@srv:~/nginx# apt-get install libpcre3-dev zlib1g-dev root@srv:~/nginx# auto/configure --with-debug root@srv:~/nginx# make 上面configure的时候一定要添加–with-debug参数,这个时候可以让可执行程序支持生成debug的log信息,同时如果是MacOS的系统的话,还需要事先用homebrew安装gcc,然后添加–with-cc=/usr/local/bin/gcc-5指定使用gcc编译器(后面有时间说是要折腾一下Clang的,而苹果xcode默认就是用的这货),不过MacOS底层用的是kqueue而不是epoll,你应该知道我要说什么;make编译之后会在objs目录下面生成nginx可执行程序
root@srv:~/nginx# mkdir logs root@srv:~/nginx# objs/nginx -p . 通过-p参数,可以避免使用默认系统路径的权限问题,以及对现有环境的干扰。此时进程全部转到后台执行了,更要命的是IDE的调试环境此处被断开失连了,所以需要在nginx.c中将系统初始化过程的ngx_daemon()注释起来,就可以正常断点跟踪了。
到此,Nginx的调试跟踪环境设置完成,设置conf/nginx.conf中log级别error_log logs/error.log debug;然后通过tail -f logs/error.log所有运行调试日志尽收眼底。
2.2 多进程服务端程序设计
通过官网Nginx文档大致了解了一下他的构架,看的真是让人拍案叫绝大快人心,请待我慢慢道来。
2.2.1 多进程下的套接字
传统上Nginx在启动开始的时候就bind一个地址进行listen,后续在fork()创建worker process的时候,这些进程是共享这个侦听套接字的,这个在linux fork()的手册中明确地被表示出了
The child inherits copies of the parent’s set of open file descriptors. Each file descriptor in the child refers to the same open file description (see open(2)) as the corresponding file descriptor in the parent. The child inherits copies of the parent’s set of open message queue descriptors, open directory streams.
所以master process创建出来的所有worker process都是可以accept()客户端请求的,当多个进程对同一个socket调用accept()接收连接的时候,他们都会把自己放到这个套接字的等待队列上面去,然后一旦有客户发起连接请求,这个队列上面等待的进程就会被唤醒,这个过程在之前分析epoll的时候就介绍过了,但是在较早的epoll版本中,上面的唤醒过程会产生惊群(Thundering Herd)的问题:即使只有一个连接请求到来,也会唤醒在这个共享侦听套接字上所有等待的进程,而所有进程争抢这个连接只有一个能获得连接,其他所有进程都无功而返,所以新版的epoll添加了EPOLLEXCLUSIVE这么一个新的flag,通过在EPOLL_CTL_ADD的时候使用,保证在事件就绪的时候不会产生惊群的问题。
Nginx对于共享accept套接字惊群问题的处理,有三个方法:
(1). accept_mutex = on
当这个选项打开的时候,worker process在其任务循环的时候,会首先通过ngx_trylock_accept_mutex去获得一个进程间的ngx_accept_mutex互斥锁,而该锁通常是使用文件锁来实现的。在持有这个锁的时候,首先收集底层就绪的事件,同时执行accept的所有回调,然后释放该锁,处理一般的非accept事件。
(2). accept_mutex = off
这个设置在较新版本的Nginx已经是默认关闭的,主要考虑到的是:一来通过EPOLLEXCLUSIVE、下面的SO_REUSEPORT等新技术可以避免accept的时候惊群的问题;另一方面Nginx采用基于事件的处理方式,worker process只有很少的几个,而不像Apache的技术Prefork很多的子进程,所以即使发生惊群对系统造成的影响也极为有限。
(3). reuseport
在Linux内核3.9的时候,内核Socket支持了SO_REUSEPORT选项,而Nginx在1.9版本中引入了这个选项,这样每个worker process都可以同时侦听同一个IP:Port地址,内核会发现哪些listener可用,从而自动将连接请求分配给给定的worker process,消除了Nginx传统上通过用户态采用accept_mutex互斥锁而带来的性能损耗问题。
上面三种方式的性能对比在官方也给出了 测试结果 。
2.2.2 基于事件的异步模型
异步模型是新一代http服务器Nginx和老牌Apache最大的不同之处:
Apache采用的是Prefork技术,服务启动之后预先启动一定数目的子进程,当服务器压力增大的时候不断增加子进程的数目,而当服务器空闲后自动关闭一些子进程,虽然这种弹性常驻子进程比One Child per Client的模型要进步很多,但是经过这么久的多进程、协程开发技术的熏陶可知,子进程的增加只在一定范围内可以增加服务能力,同时子进程在进程切换、内存等方面会对服务器带来很大的压力,如果当连接客户达到C10K的时候其占用的资源是不可估量的。
Nginx采用的是基于事件驱动的模型来解决C10K问题,所以通常Nginx只需要启动很少(通常CPU执行单元个数)的worker process就可以同时服务大量连接,以至于越来越多的http服务器迁移到Nginx平台上面。其工作流程主要是:
当master process通过fork()创建出几个worker process的时候,worker process进程主执行函数为ngx_worker_process_cycle(),这里面除了检查各种状态标识(比如接受到父进程发送的信号后,设置ngx_terminate、ngx_quit、ngx_reopen等标识)作出特定行为外,其正事主要是通过ngx_process_events_and_timers处理事件:
此时如果accept_mutex==on,而当ngx_trylock_accept_mutex抢锁失败则直接返回,否则就会设置NGX_POST_EVENTS这个标识,表示事件的回调延后执行。因为我们要把持锁的临界区降低,所以在持锁的过程中,通过ngx_process_events(实质乃是ngx_epoll_module_ctx.actions)检查底层侦听套接字就绪的事件,根据epoll特性可以快速的收集就绪事件并添加到ngx_posted_accept_events和ngx_posted_events队列上去,执行ngx_posted_accept_events队列回调后释放锁,最后执行一般的事件回调操作。
如果accept_mutex==off,那么在ngx_process_events的过程中,事件的回调将会在搜集就绪事件的过程中同步执行。
2.3 Nginx配置文件和二进制程序平滑升级 Nginx中多进程之间将信号运用的活灵活现(Windows平台下没用借用信号的方式,而是用其特有的Event事件进行的通信),使得Nginx可以在不间断服务的情况下进行配置文件,甚至是二进制文件的平滑升级操作,信号的含义可以参见ngx_config.h,信号处理参见ngx_process.c:ngx_signal_handler,在信号处理文件中其实也只是设置一些状态变量,然后在进程的时间循环中去执行相应的操作,比如向worker process发送特定信号、启动worker process等。
2.3.1 Nginx配置文件平滑升级
通过nginx –s reload或者直接kill -SIGHUP向Nginx master process发送信号,当master process接受到SIGHUP信号的时候:
a. 检查配置文件,然后打开新的listen socket和日志文件,如果失败则让old nginx继续执行,否则
b. 创建新的worker process,同时向old worker process发送信息,让他们graceful关闭,old worker process会关闭侦听套接字,服务已经连接的客户,当所有连接客户服务完了之后退出
2.3.2 Nginx二进制程序平滑升级
将新的二进制文件拷贝覆盖原二进制执行文件,然后向master process发送SIGUSR2信号,当master process接收到该信号的时候:
a. 将pid文件重新命名为nginx.pid.oldbin
b. 执行新的可执行文件,按照常规的路径会产生new master process和new worker process,此时新老进程全部并存,并且全部正常工作——接受客户端连接请求和服务客户端
c. 向old master process发送SIGWINCH,其将会把自己所有的old master workers关闭,注意此时old master process的侦听套接字仍然工作的,必要时候还是会自动产生自己的worker process。调试新版本升级是否正常:如果正常就向old master process发送SIGQUIT,加上之前SIGWINCH工作所有的old process清理完毕;如果不正常,向old master process发送SIGHUP产生worker process,同时向new master process发送SIGTERM信号立即清理所有的new worker process,然后使用SIGKILL杀死new master process
本文完!
参考 GitHub Nginx
THREADS VS. PROCESSES FOR PROGRAM PARALLELIZATION
On Threads, Processes and Co-Processes
POSIX thread (pthread) libraries
Extending Traditional Signals
Pthreads Programming Chapter 5 - Pthreads and UNIX Threads and Signals
Windows服务端程序向Linux平台移植事项
深刻理解Linux进程间通信(IPC) Inside NGINX: How We Designed for Performance & Scale
The Architecture of Open Source Applications – NGINX
Controlling nginx
Socket Sharding in NGINX Release 1.9.1
Issues In Concurrent Server Design on Linux Systems - Part I
查看原文: taozj.org/2016/11/浅谈多…
