

作者:星空下的文仔(才云)
校对:bot( 才云)
当前,K8s 已成为容器编排领域的胜利者,越来越多企业正在尝试将业务迁移到 K8s 集群之上,通过 K8s 实现应用的快速部署、优雅升级、监控管理及减少资源占用。作为容器应用编排的核心组件、应用调度的基石,调度器却一直饱受诟病……
随着 Kubernetes 需求场景的复杂化,越来越多特性被加入到调度器中,使得调度器变得更加庞大,更加复杂,也更加难以维护,实现自定义调度器的用户也很难跟上上游的新功能和错误修复。
当前,K8s 通过 Webhook(Scheduler Extender) 的方式提供功能扩展,但依旧有如下限制:
- 扩展点数量的限制:仅支持 “Predicate”、“Priority”、“Bind” 三个扩展点。即可以在这三个阶段进行扩展,但扩展的功能只能在默认的功能之后被调用。例如当增加了新的 “Predicate” 功能后,开发者只能在默认所有预选函数执行完成之后才能调用它,不能够在这之前进行调用;
- 效率低下:调度器通过 JSON 的数据格式与扩展通信,比调用原生函数要慢得多;
- 调度器也无法通知 Extender Pod 已经取消调度;
- Extender 是单独的进程,无法使用默认调度器的缓存,需要自建一个和默认调度器一样的缓存。
以上限制阻碍了开发者构建高性能和通用调度程序功能。
为了解决上述问题,我希望能有一种扩展机制,它应该足够快以允许将现有功能转换为插件,例如预选和优先级功能。这样的插件将被编译到调度程序二进制文件中。另外,自定义调度程序的开发者可以使用(未修改的)调度程序代码和他们自己的插件来编译自定义调度程序。
由此,Scheduler Framework 应运而生。Scheduler Framework 为默认调度器定义了新的扩展点和 API,并通过插件的方式提供。插件可以被编译进调度器中,并提供配置的方式,启用、禁用和排序插件。
什么是 Scheduler Framework
Scheduler Framework 将 Pod 的调度过程分为两步:调度和绑定。
调度是为 Pod 选择一个合适的节点,而绑定则是将调度结果提交给集群。调度是顺序执行的,绑定并发执行。无论是在调度还是绑定过程中,如果发生错误或者判断 Pod 不可调度,那么 Pod 就会被重新放回调度队列,等待重新调度。
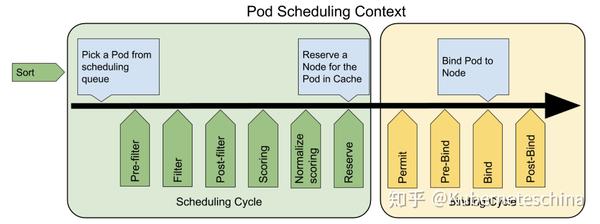
在上图中,可以看到 Scheduler Framework 提供了多个扩展点,“Filter” 即 “Predicate”,“Scoring” 即 “Priority”。
一个 Plugin 可以实现多个扩展点。即在一个 Plugin 中既可以实现 Filter,又可以实现 Scoring,也可以再实现 Pre-Bind,看具体需求和场景,避免了一个需求实现多个 Plugin 的情况。
下面简单介绍下每个扩展点:
- Sort(QueueSort):用于给调度队列排序,但只有一个是生效的,即如果注册了多个,只有一个是可用的。默认是优先级的队列;
- Pre-filter:在预选前,对 Pod 信息的检查,比如 Pod 是否包含某些 annotations or labels,或者其他信息;
- Filter:如果对于默认调度器提供的预选算法不满意,则可以禁用默认调度器的预选算法,在这个 point 实现对节点的预选。Framework 按照插件注册的顺序执行依次执行,如果某个插件将一个节点标记为不可调度,则不会再执行其他插件;
- Post-filter:在预选后被调用,通常用来记录日志和监控信息。也可以当做 “Pre-scoring” 插件的扩展点;
- Scoring:为预选阶段的节点打分,根据配置中插件的权重等信息;
- Normalize scoring:在调度器为节点计算最终排名前修改节点排名。配合 Scoring 插件使用,为了平衡插件中的打分情况
- Reserve:为给定的 Pod 预留节点上的资源,目的是为了防止资源竞争,并且是在绑定前做的;
- Permit:类似对 Pod 进行“准入”(预绑定)检查或者延迟绑定;
- Approve:所有的 permit 插件都允许才能够被绑定
- Deny:如果有一个 permit 插件不允许 Pod 绑定,Pod 将被放回调度队列,重新调度,并触发 unreserve 插件调用
- Wait:延迟绑定,超时则变成 deny 模式,Pod 被重新调度,并触发 unreserve 插件调用
- Pre-bind:在 Pod 绑定前被执行;
- Bind:在 Pre-bind 执行完之后才被调用,注册的插件可以选择是否处理给定的 Pod,如果选择处理,则剩余的插件将被跳过;
- Post-bind:在绑定之后被调用,可用于清理相关联的资源;
- Unreserve:如果给定的 Pod 在 Reserve 阶段做了资源预留,但绑定失败了,那么这个扩展点将被调用,用于恢复保留的资源等。
插件的生命周期
初始化
初始化有两步:注册和配置。
注册即向默认调度器中注册,配置是通过配置文件的方式决定哪些插件需要初始化。如果插件实现了多个扩展点,也只被初始化一次。
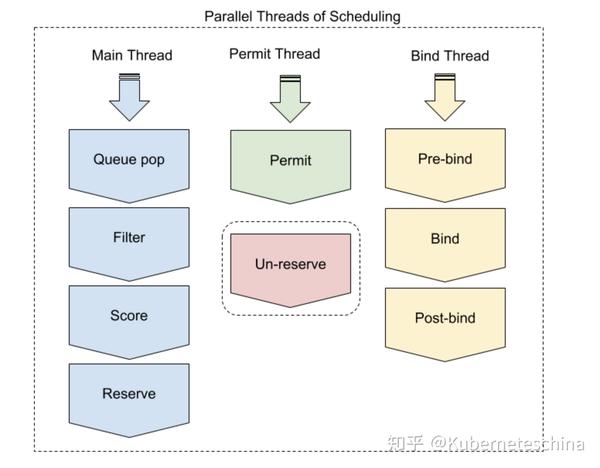
并发
插件应该考虑两种类型的并发。在计算多个节点时,可以并发地多次调用插件,并且可以从不同的调度上下文中并发地调用插件。
在调度器的主线程中,一次只处理一个调度周期。在下一个调度周期开始之前,所有包含 “reserve” 在内的扩展点都将完成。在 “reserve” 阶段之后,绑定周期将异步执行。这意味着可以从两个不同的调度上下文中并发地调用插件,前提是至少有一个调用是在 “reserve” 之后调用扩展点。有状态插件应该小心处理这些情况。
最后,根据 Pod 被拒绝的方式,可以从 Permit 线程或 Bind 线程调用 Unreserve 插件。
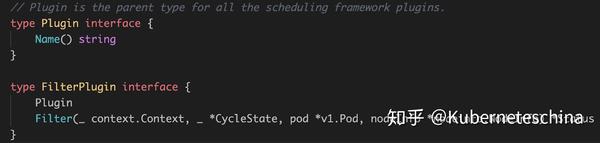
如何实现一个插件
实现一个插件必须实现 Plugin 接口以及想要实现的扩展点的接口,例如,如果你想让插件实现一个预选功能,需要如下:
插件注册
那实现完成的插件如何向默认调度器中注册呢?
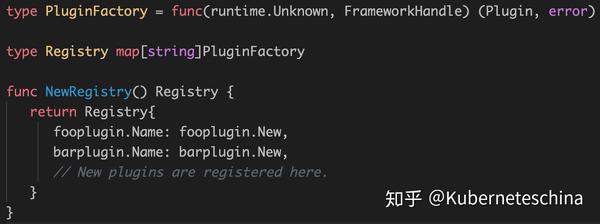
以上是默认调度器中,预选和优选函数插件化后的注册方式,自定义实现的插件的注册和此类似:

插件配置
调度器提供了以 KubeSchedulerConfiguration为对象的方式,对调度器进行自定义配置。开发者在该对象中可以启用或禁用插件,以及配置插件的参数。
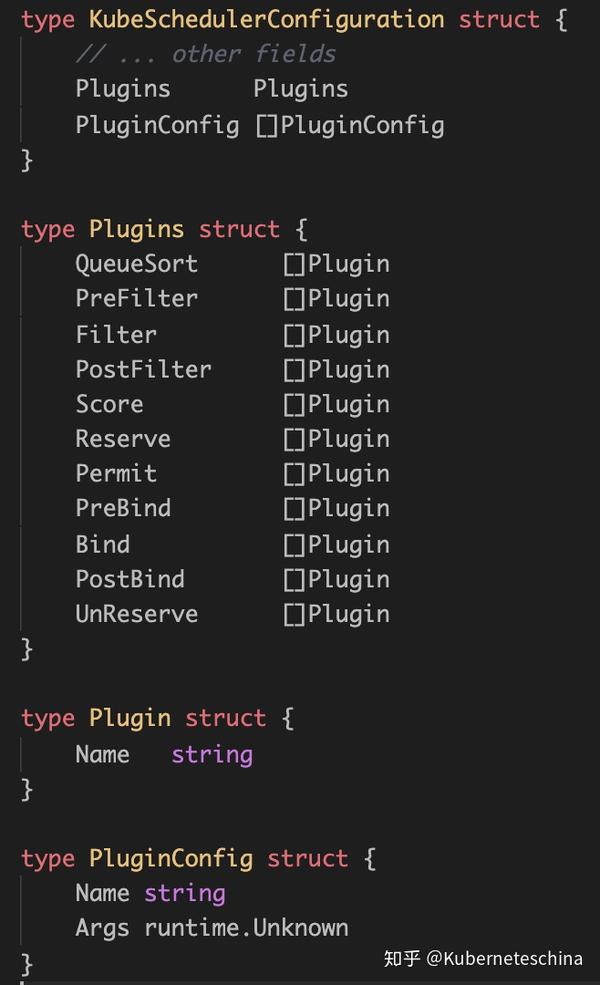
例如:
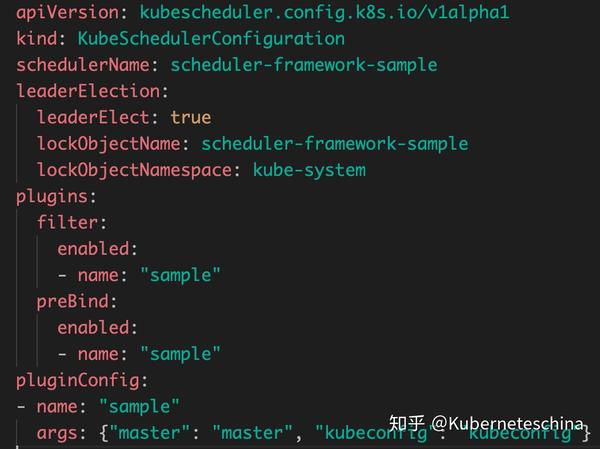
我在 GitHub 中写了个简单的插件实现,并且能够打包成镜像运行在 Kubernetes 集群中,详细可参考:Scheduler-Framework-Sample(github.com/angao/sched…)。
结语
日前,Kubernetes v1.17 正式发布,Scheduler Framework 内置的预选和优选函数已经全部插件化,但调度器的配置还是以 Policy 的方式为主。
升级后的 Scheduler Framework 将无法在低版本集群中使用,原因是它依赖 v1 版本的 CSINode 资源,而低版本的 Kubernetes 集群中没有此版本的资源。
参考文献
