

MR篇
首先,MR是否理解透彻,各个阶段的自定义配置是否清楚怎么个流程,例如
- 自定义key(MR中对key的设计很重要,虽然现在几乎不写MR了)
- 自定义排序比较器
- 自定义分区器
- 自定义combine(*)
- 自定义分组比较器
- 理解MR过程中的排序。理解其设计目的。
- Map输入输出源码
- Reduce输入输出源码
- Map端join,cache的设置。
- 编程题:找共同好友问题。
- MR和Spark的比较(*)
Spark基础
scala里的迭代器很牛逼,比如iterator.map返回的还是迭代器
- spark迭代器pipeline思想(嵌套迭代器,在MR中也有体现)。以及其中的模板方法iterator是父类RDD中的方法,里面调用子类的compute。
- flatMap是怎么进行扁平化的?
- HadoopRDD是怎么得到数据的。
- 通过文件创建的HadoopRDD他的分区数是怎么创建的(追源码)
- combineByKey原理
- cogroup原理,以及join是怎么实现的。
- union是shuffle操作吗?
- sortByKey会产生job吗?大数据排序问题。
- rdd的宽窄依赖是什么?
- mapvalues比map多了一点优化。
preservesPartitioning - 行转列,列转行
//行转列了
val group = source.groupByKey
// 列转行,这么写是为了清楚flatMap接受的函数返回值是一个迭代器。
group.flatMap(x => x._2.iterator.map((_, x._1)))
// 另一个算子
group.flatMapValues(_.iterator)
- groupByKey源码注释中写到了
This operation may be very expensive.
统计算子
统计计算
val source = sc.parallelize(List(
(104005, 20),
(104005, 23),
(104005, 25),
(204005, 25),
(404005, 25),
(404005, 30)
))
- 求max:
source.reduceByKey((a, b) => Math.max(a, b)).foreach(println) - 求min:
source.reduceByKey((a, b) => Math.min(a, b)).foreach(println) - 求count:
source.mapValues(_ => 1).reduceByKey(_+_).foreach(println) - 求sum:
source.reduceByKey(_+_).foreach(println) - 求avg(*)
combineByKey,很多时候有些特殊的逻辑需要它来处理
// 这种做法不可取,复杂度高,产生了两笔shuffle
val count = source.mapValues(_ => 1).reduceByKey(_ + _)
val sum = source.reduceByKey(_ + _)
sum.join(count).mapValues(x => x._1 / x._2).foreach(println)
// 通过使用底层算子combineByKey来拿到sum和count,只通过一次shuffle
source.combineByKey(
x => (x, 1), // 第一笔数据怎么处理
(x: (Int, Int), y) => (x._1 + y, x._2 + 1), // 第二笔和第一笔怎么reduce
(x: (Int, Int), y: (Int, Int)) => (x._1 + y._1, x._2 + y._2) // 两波combine怎么reduce
).mapValues(x => x._1 / x._2).foreach(println)
// combineByKey 来算 count 纯碎练api
source.combineByKey(
_ => 1,
(o: Int, _: Int) => o + 1,
(x: Int, y: Int) => x + y
).foreach(println)
分区相关操作
对一个分区进行操作
有这么一个需求,每一条数据需要查一下DB做丰富。
如果使用是map算子,那么每笔数据操作时都需要DB连接打开和关闭
这就需要mapPartitionsWithIndex
val source = sc.parallelize(seq = 1 to 50, 5)
source
.mapPartitionsWithIndex((x, y) => {
println(s"$x---打开数据库连接")
val iterator = new Iterator[Int] {
override def hasNext: Boolean = {
if (y.hasNext) {
return true
}
else println("关闭数据库连接")
false
}
override def next(): Int = {
val ret = y.next
println(s"select ..$ret.")
ret
}
}
iterator
})
.foreach(println)
调整分区的数量底层算子coalesce,可以有shuffle也可以没有shuffle。
val source = sc.parallelize(seq = 1 to 50, 5)
// 从4040页面看是产生了shuffle的,此行为是把分区数从5增加到6
source.mapPartitionsWithIndex((e,i)=>i.map((e,_)))
.repartition(6)
.mapPartitionsWithIndex((e,i)=>i.map((e,_)))
.foreach(println)
来看源码注释
Return a new RDD that has exactly numPartitions partitions.
Can increase or decrease the level of parallelism in this RDD.
Internally, this uses a shuffle to redistribute data.
If you are decreasing the number of partitions in this RDD,
consider using coalesce, which can avoid performing a shuffle.
如果想要减少rdd的分区数,使用coalesce可以避免产生shuffle
这个在调优的时候很有用,我还没有实际经验所以先记录一下。
TopN问题
原始数据如下,求出每个月温度最高的两天。
val source = sc.parallelize(List(
// 日期 温度
"2019-06-01 32",
"2019-06-02 36",
"2019-06-03 33",
"2019-05-01 32",
"2019-05-02 34",
"2019-05-03 34",
"2019-04-02 29",
"2019-04-02 24",
"2019-04-22 31",
"2019-04-22 30"
))
val t4 = source.map(line => {
val strings = line.split(' ')
val strings1 = strings(0).split('-')
(strings1(0).toInt, strings1(1).toInt, strings1(2).toInt, strings(1).toInt)
})
这个综合练习各种算子的应用,以及观察4040web页面,观察作业的复杂度。 需要解决的问题如下:
- 如何进行数据的去重(数据中存在日期相同的数据,这时候需要将相同日期的温度最大的取出来)
- 取出同一个年月中最大温度的两天
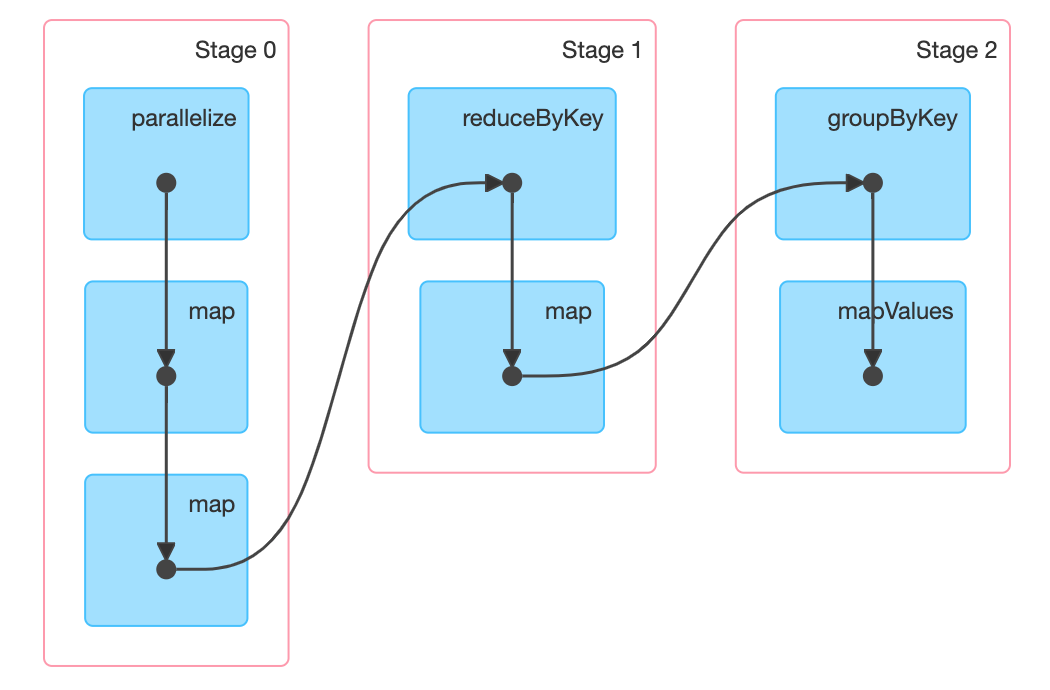
planA
// 年月日为key,这样能够去重数据。这步处理之后一个月最多也就只有31条数据了。
t4.map(x => ((x._1, x._2, x._3), x._4))
.reduceByKey(Math.max)
// 改为年月为key
.map(x => ((x._1._1, x._1._2), (x._1._3, x._2)))
// 通过groupByKey拿到相同年月的所有数据,这里不会产生oom。一个月最多31笔
.groupByKey()
// 相同年月的数据 按温度倒序 取出前两条
.mapValues(_.toList.sortWith((x, y) => x._2 > y._2).take(2))
.foreach(println)
产生两次shuffle
planB
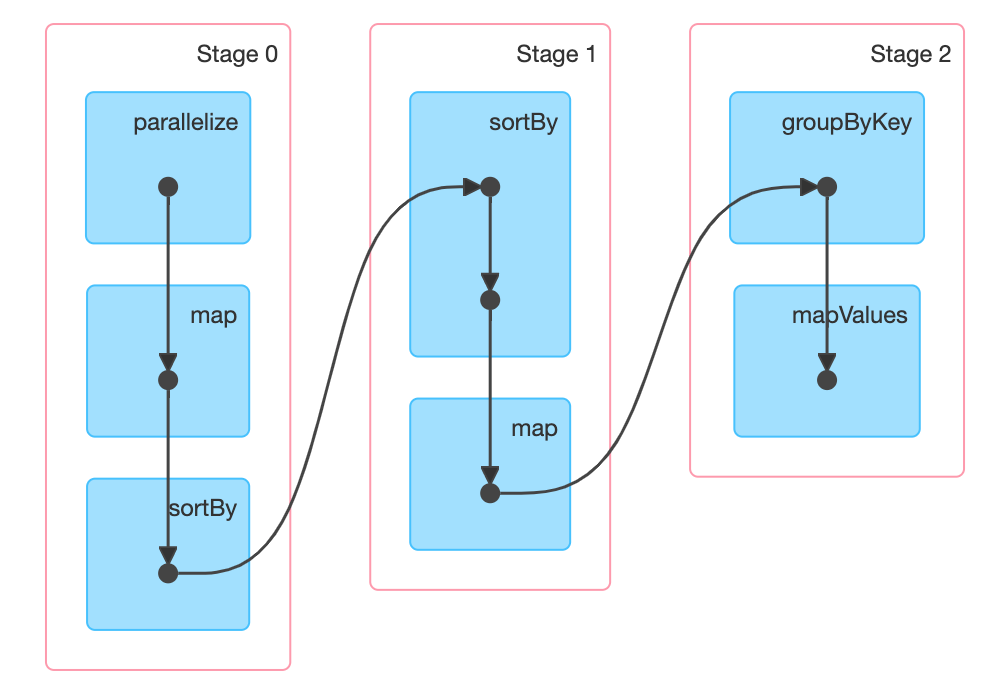
首先使用sortBy对年月温度进行倒序,再把年月转换为key,进行group。此时数据整体是温度降序,相同年月,拿出第一条,然后只要拿出日期和第一条不同的即为第二条。我感觉这种算法不如上面那种,io比上面多很多。
t4.sortBy(x => (x._1, x._2, x._4), ascending = false)
.map(x => ((x._1, x._2), (x._3, x._4)))
.groupByKey()
.mapValues(x => {
val iterator = x.iterator
val result = new Array[(Int, Int)](2)
var tuple = (0, 0)
if (iterator.hasNext) {
tuple = iterator.next()
result(0) = tuple
}
var flag = true
while (iterator.hasNext && flag) {
val tuple1 = iterator.next()
if (tuple1._1 != tuple._1) {
result(1) = tuple1
flag = false
}
}
result.toList
})
.foreach(println)
两次shuffle
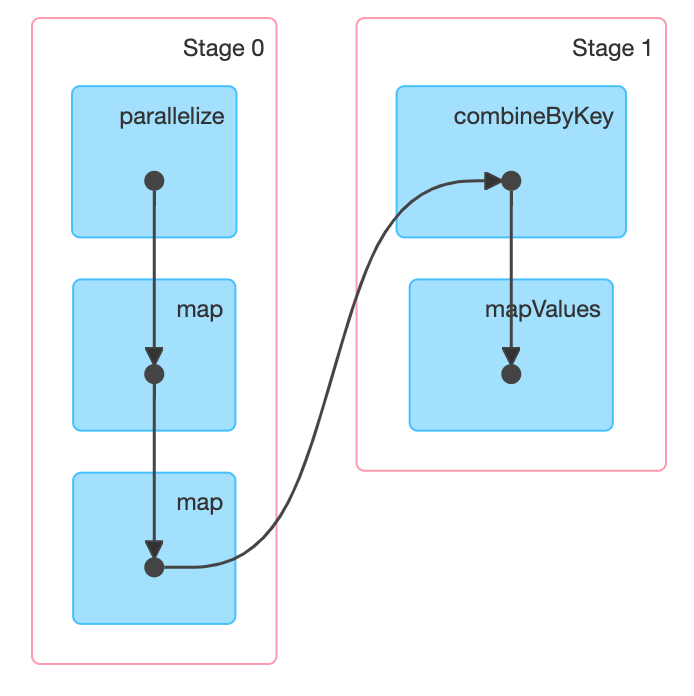
终极
combineByKey是底层算子,只要逻辑写的对。
t4.map(x => ((x._1, x._2), (x._3, x._4)))
.combineByKey(
x => {
Array(x, (0, 0), (0, 0))
},
(arr: Array[(Int, Int)], x: (Int, Int)) => {
if (arr(0)._1 == x._1 && arr(0)._1 < x._1) {
arr(0) = x
} else if (arr(1)._1 == x._1 && arr(1)._1 < x._1) {
arr(1) = x
} else if (arr(0)._1 != x._1 && arr(1)._1 != x._1) {
arr(2) = x
}
// 这中排序直接对原始数据进行修改
util.Sorting.quickSort(arr)(new Ordering[(Int, Int)] {
override def compare(x: (Int, Int), y: (Int, Int)): Int = Integer.compare(y._2, x._2)
})
arr
},
(arr1: Array[(Int, Int)], arr2: Array[(Int, Int)]) => {
arr1.union(arr2).sortWith((x, y) => x._2 > y._2).take(2)
}
)
.mapValues(_.toList)
.foreach(println)
复杂度仅一次shuffle
集群相关
历史服务器
spark.eventLog.enabled true
#计算层把日志写到哪里,历史服务器没起也不影响写日志
spark.eventLog.dir hdfs://mycluster/spark_log
#历史服务器进程去哪里取日志
spark.history.fs.logDirectory hdfs://mycluster/spark_log
#历史服务器的启动
在sbin目录下 sbin/start-history-server.sh
yarn
- 上传spark jar包去hdfs。这样不会每次提交任务都上传200多MB的jar,配置
spark.yarn.jars官方文档有写 - 观察进程,
ExecutorLaunchApplication这两个是什么意思 - spark example 求π,逻辑得知道怎么回事。
