

感觉数据库有很多说烂了的问题,在实际应用中总还是容易出问题。正好就一个真实的踩坑场景来讨论一下这个话题。一次踩坑往往是我们理解一个问题的开始,这个想法是《踩坑攀登者》(pitfall climbers)系列文章的开始。
为了把握篇幅(在5000字以内)文章分成上下两篇,本文主要讲两种reading和innodb的各种锁的设计。
用户投诉表
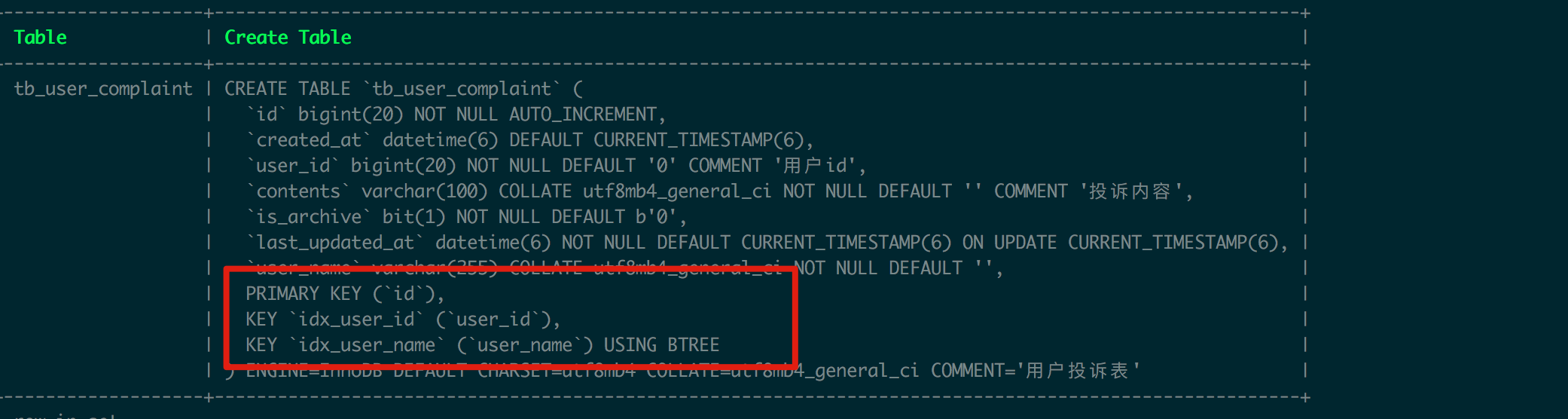
本文以这个table作为例子来进行讲解,注意例子中有1个聚集索引2个次级索引:
- clustered-index:id作为clustered index聚集索引,唯一;
- secondary-index:user_id和user_name都是次级索引,not unique;
踩坑问题
一个连接希望修改用户555的所有的数据并且不允许有其他的新数据产生。
select * from tb_complaint_user where user_id = 555 for update; # 写锁
--- 修改用户555的所有数据
commit;
结果大失所望,另一个线程成功的insert了新的用户555的数据,但另一个线程的update 555的语句却被block住了。



解决方案
经验丰富的同学马上发现了问题来自隔离级别,查看了隔离级别发现级别REAT-COMMITED。(注意auto_commit都是false)于是尝试在测试环境把隔离级别改成REPEATABLE-READ,再次重试insert就被成功的block了。(大家注意不要在生产环境随便修改配置- -)
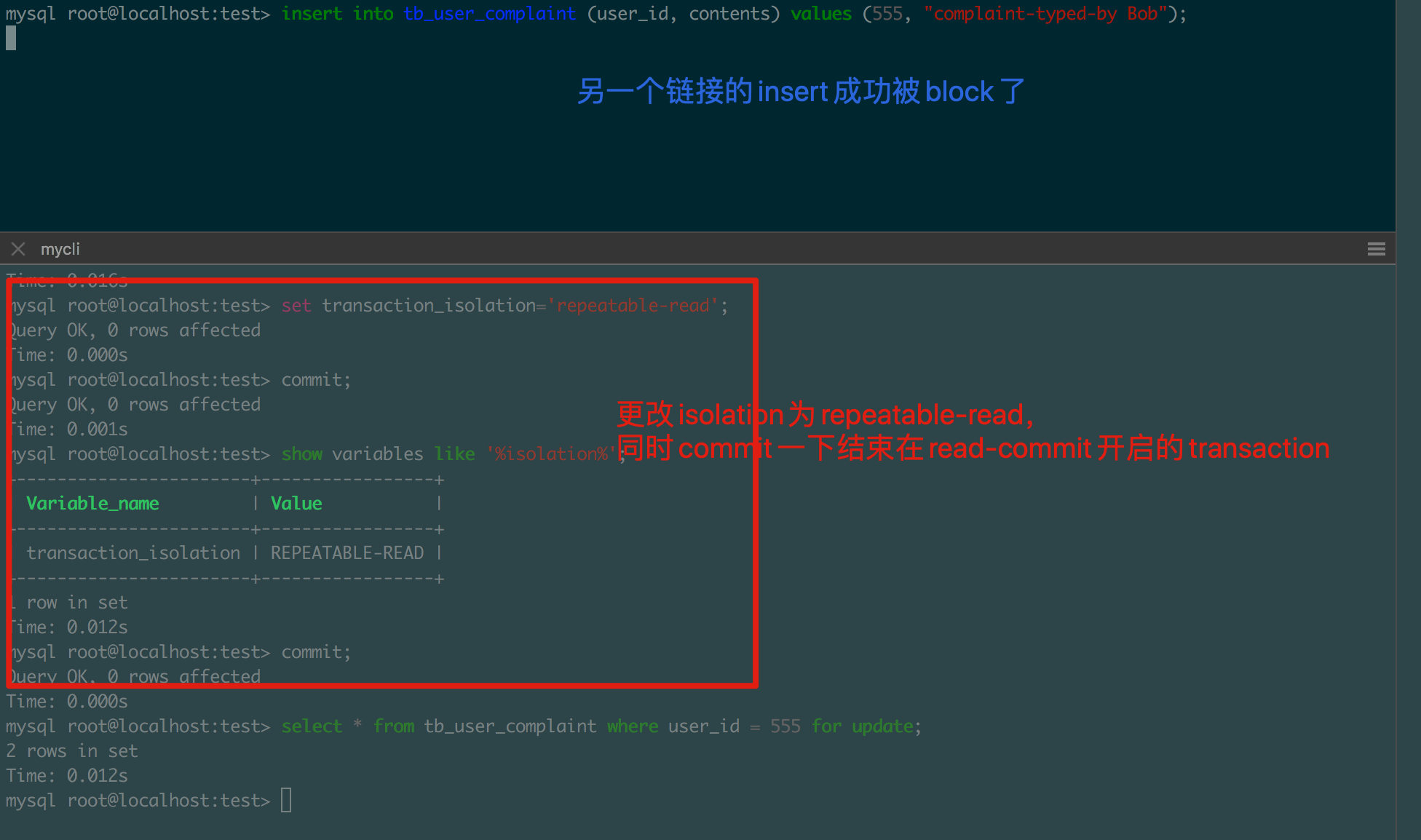
这里面整个过程到底发生了什么呢?
背景知识
阅读锁需要先了解innodb是基于transaction和索引的:1)在innodb中仅select也在一个transaction里,不是只有update这种语句才会开启transaction;2)innodb是基于索引的设计,行数据存在于聚集索引(clustered-index)的叶子节点上(leaf-records);
另,如果没有明确指定,例子里的隔离级别都是read-committed,auto_commit = false;
两种reads
首先先看看reads的一种分类方法,innodb的官方文档根据reads是否需要请求数据库锁将其分为locking reads和none-locking reads。
none-locking reads是不加锁的查询,也就是我们最常用的select。在普通的select语句下,我们的transaction不会申请任何锁从而也不会被任何锁block。
select * from tb_xxxx [where xxxx] [group by xxx] [having xxx] [order by xxx]
那么locking reads就很好理解了,需要请求数据库锁的就是locking reads了,请求锁也就很可能需要等锁被block。下面几种reading语句都属于locking reads。
select xxx from tb_xxx for share;
select xxx from tb_xxx for update;
update xxx set xxx = xxx where xxx = xxx; //由于直接调用update/delete其实也会申请和for update一样的锁,
delete from xxx where xxx;
什么是锁

首先说说什么是锁,锁的设计其实非常多不仅仅是db会用到,redis、多线程开发中都会用到,而且业务开发的时候也常常用到锁的设计:比如参加双十一的商品不能再下架,这个时候淘宝系统就可以对这个商品加一个业务上的商品锁。
那么锁是什么呢,从实现角度看很可能只是一个行tag,标记了锁的类型、锁的对象、锁的拥有者等等。从含义理解锁是一种用来限制某种资源的某一能力被使用的机制,这个角度进而带给我们几个理解锁的角度:锁什么资源、锁限制了别人的什么能力、锁赋予了拥有者什么能力、多个锁是否共存。
innodb中锁的分类
(1) data与metaData
定义与设计
innodb对锁的第一种分类方式就是根据“锁出现的缘由”来分,对metaData比如table,procedure,db的定义而发生改动的锁叫metaData lock,由于对具体数据改动或者限制产生的锁称为datalock。比如DDL语句就需要锁住table定义从而申请的是table meta lock,而修改一个table中的一行申请的的锁就是datalock。
datalock往往是基于transaction的,结束占有锁的trx就会释放(rollback或者commit),当然和db的这个session直接结束了trx也会结束从而datalock释放。
metadata lock往往不是基于transaction而是基于session的,所以metadata的lock无法通过结束当前trx来结束,unlock需要显示调用、或者等申请锁的DDL执行完毕自动解锁、再或者直接close session- -。
LOCK TABLES table_name [READ | WRITE]
UNLOCK TABLES;
查看方式
查看innodb中正在使用的datalock和metalock都在performance_schema这个db中(mysql中schema和db属于等价概念),使用下面语句就可以查看当前正在使用中的locks了。当然直接查看innodb status也能看到锁的具体信息。
select * from performance_schema.metadata_locks;
select * from performance_schema.data_locks;
show engine innodb status;

(2) X与S的
这一部分讲的互斥锁(X=exclusive)和共享锁(S=shared)更多的是讲互斥和共享的设计,而不是具体的一种数据库锁,这种共享和互斥关系针对具体的资源无论一个行记录(record)还是表(table)都适用。
S锁正如其名shared可以被多个trx(T1,T2,T3都可以获得),获取S锁代表该资源(record/table)正在被很”认真“的读,限制的是在这个读的过程中不能发生修改删除(dml)操作。如果java的GC回收认为无法回收的对象是被root节点锁住了,那么这种锁就是一种shared锁,多个roots可以共享限制了回收能力。
X锁exclusive也就是排它互斥的意思,同一时刻只能被一个trx来获得,下一个trx申请锁往往会被block直至锁被释放,获得X锁认为该资源正在被一个trx修改从而不能被S锁加锁读也不能被其他线程加X锁写。java中的sync和lock都是一种排他锁,限制了对象代码的执行权限。
(3)行锁: record, gap, next-key
根据行锁锁定的范围,row lock这一个笼统的概念可以再细粒分为record lock,insert-lock, gap lock,next-key lock。next-key其实是record和gap的组合,所以重点在于理解recard,insert和gap lock。
(3.1) record lock
设计
record lock应该具叫index record lock才更准确。这种锁的目标就是命中sql条件的一个个index records, 这里的index最重要的是执行计划使用到的key,此外也会在pk上加记录锁。所以一个命中记录很可能会加多个记录锁
另一个常常误解的知识点事index record的粒度是“一个个”。什么叫一个呢,如果使用的key不是unique key,这一行的定位应该是(key=xxx,pk=xxx)(也就是次级索引叶子节点里的内容:key+pk)。这里不能笼统的理解为对(key=xxx)加了锁因为key=xxx是一个多行代表的是从xxx到xxx+1的这个范围。
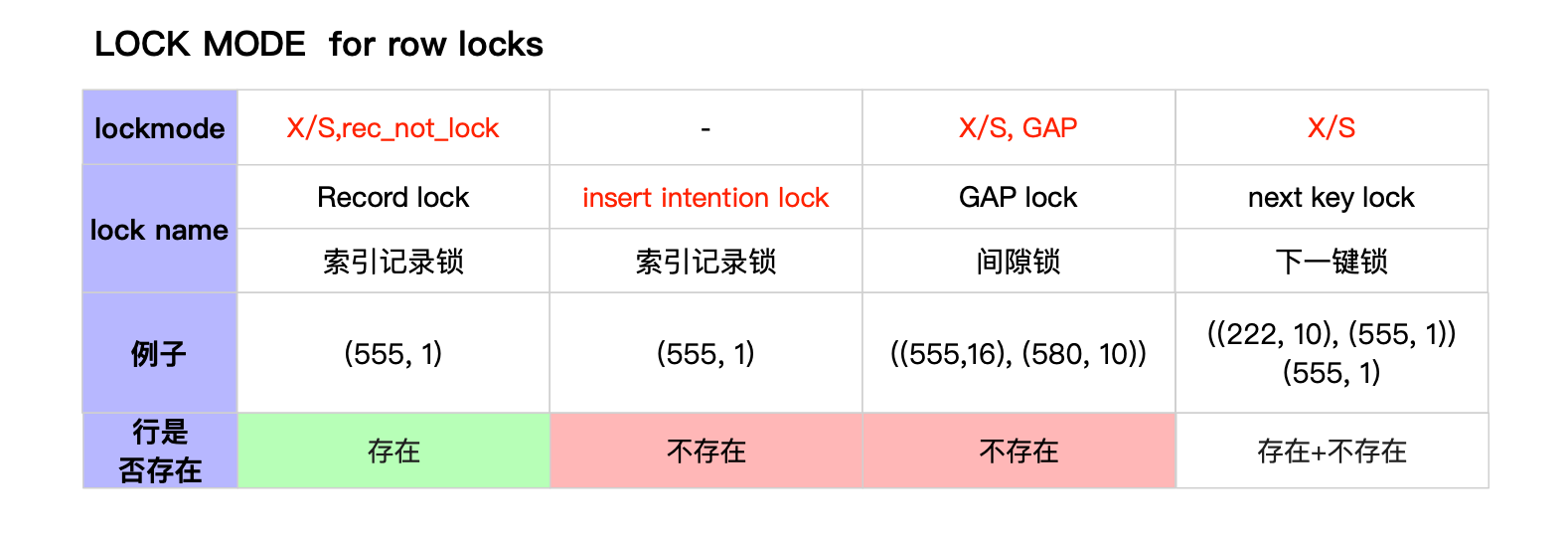
记录锁在innodb系统中的标识LockMode注意不是X,S而是(X/S,LOCK_REC_NOT_GAP),也就是lock is record not gap的意思。
案例分析
下面我们看看例子理解一下上面的设定,现在我们user_complaint表上有2行数据:

我们通过userid和名字来select,explain sql发现执行计划使用userid作为索引。查看data_locks表里的recordMode和indexName,发现如同上文所说的innodb在pk和userid上使用了recordLock。查看lockData这一列的数据发现user_id这个次级索引上的record(userId=555, id=1)和pk这个unique的聚集索引上的记录是(id=1)。
explain select * from tb_user_complaint where user_id = 555 and user_name = "macavity" for update;
select * from tb_user_complaint where user_id = 555 and user_name = "macavity" for update;
select * from performance_schema.data_locks;
rollback;

如果把select中的userid条件删掉会发现recordlock加载了pk和userName这两个index上,因为这个时候执行计划使用的key就是userName了; 如果把select的条件改成id=1那么执行计划用的index就是pk也就只会有pk这一个index lock。
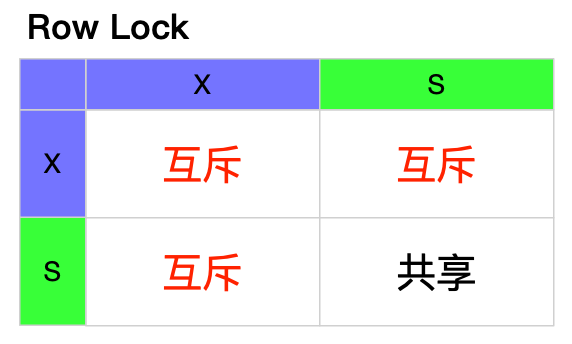
X/S record locks
当record与X和S的机制结合在一起时,就是我们最常说的行同享排它锁。可以得到了以下互斥图。注意,这个互斥图中的X与S是指同一行的行锁,不要理解成其他行更不要表的x与s和行的x与s混淆在这张图里。
(3.2) insert intention lock 行插入意向锁
DML中insert操作和update、delete不太相同,udpate和delete是对已经有的数据(index records)进行操作,而insert操作(update更改index的操作其实是另一种update+insert)是在间隙中新增index records。所以insert操作涉及到的锁不再是record lock而是insert intention lock。
由于insert的行还未存在(命中unique key duplicate error的除外),insert锁是无法被record锁排斥的。这也就是案例中的问题。为了防止insert锁,innodb设计了一种转么针对不存在锁
(3.3) gap lock
设计
gaplock,顾名思义它不再锁定一个个的index record,而是锁定一个records之间的空隙。间隙锁的lockmode为(X/S,Gap)。这里一定注意间隙锁表示的是空隙,并不表示构成间隙的边界(前提是边界上自己没有加行锁),所以gap lock不会与表示实体行的record lock互斥而会对同样限制间隙的insert lock互斥。
innodb只有在isolation>=repeatble-read(简称RR)的隔离级别才会采用间隙锁,所以我们这里需要把修改隔离级别。 隔离级别和锁的关系会在下一篇详细介绍,本篇的目的是理解锁。
案例
我们再次执行下面sql。
set @@session.transaction_isolation='repeatable-read';
commit;
select * from tb_user_complaint where user_id = 555 for update;
当隔离级别变成RR之后我们再次执行加锁语句,发现多了一行gaplock。gaplock标记着gap的结束点在(userId=580,id=36)的位置,也就是(555,16)之后的第一个record。这个时候(555, 16)到(580, 36)这个区间都无法再insert任何数据。
+------+----------------------------+---------+------------------------+------------+----------------------------+-----------+
| id | created_at | user_id | contents | is_archive | last_updated_at | user_name |
+------+----------------------------+---------+------------------------+------------+----------------------------+-----------+
| 1 | 2020-02-12 15:12:11.922491 | 555 | complaint-test-1 | ^@ | 2020-02-12 20:12:44.989804 | macavity |
| 2 | 2020-02-12 15:12:19.214543 | 222 | complaint-test-1 | ^@ | 2020-02-12 15:12:19.214543 | macavity |
| 10 | 2020-02-12 15:26:50.164283 | 111 | complaint-test-1 | ^@ | 2020-02-12 15:26:50.164283 | macavity |
| 16 | 2020-02-12 15:42:58.989849 | 555 | complaint-typed-by Bob | ^@ | 2020-02-12 15:42:58.989849 | macavity |
| 36 | 2020-02-12 18:03:55.962341 | 580 | complaint-test-1 | ^@ | 2020-02-12 18:03:55.962341 | macavity |
| 1012 | 2020-02-12 20:52:51.732739 | 600 | complaint-test-1 | ^@ | 2020-02-12 20:52:51.732739 | kiki |
+------+----------------------------+---------+------------------------+------------+----------------------------+-----------+

这里需要注意的是(X,Gap)代表间隙锁并不代表记录锁,也就是(580,36)这行数据并没有被行锁锁定。select for update这行还是可以获得这行的记录锁也就是(X, REC_NOT_GAP)锁。
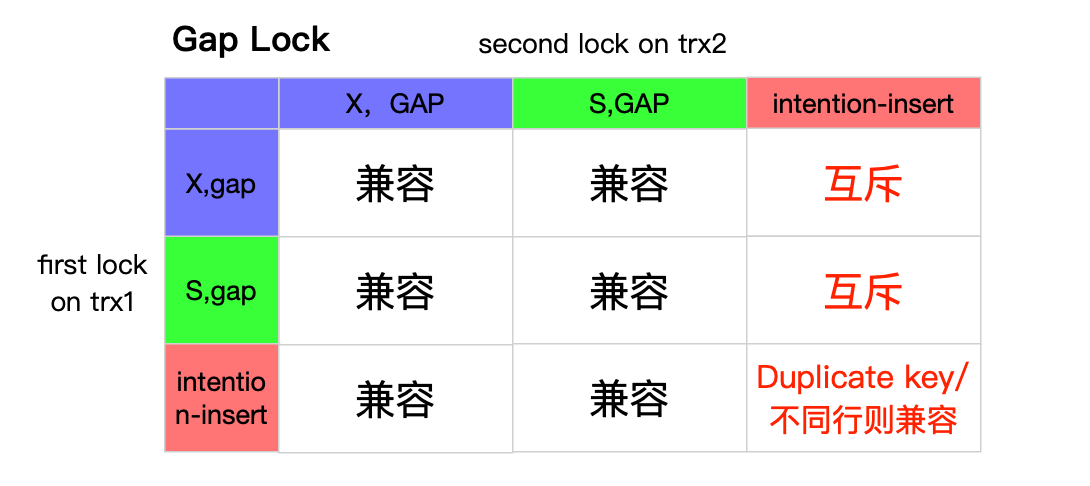
gap与insert lock的互斥与同享
下面我们看一下间隙锁和insert lock的同享互斥关系:
- Gap之间相互compatible,不同的trx可以拥有相重叠区间的间隙锁;(gap锁里的x和s更多的是标识是什么语句导致的间隙锁)
- 先加gap锁可以阻碍区间内的inserts;
- 先insert尚未commit:也不会导致gap锁block,但是由于insert行已经存在其会影响gap锁的区间。
(3.4) next-key lock
在上文间隙锁的案例里,当我们改变隔离级别,gap lock中除了红色的X,GAP之外的变更,其实绿色的部分也随着隔离级别发生了变更。之前这两行的记录是X,REC_NOT_GAP,在这里变成了X。
X/S是下一键锁的lockmode,表示一个record-lock R和一个gap-lock (R-1, R)。这个命名实在是太容易引起迷惑了。, 举个例子来说,被标记X的(555,1)其实代表了两个锁:
- (555,1)X,rec_not_gap
- ((222, 2),(555,1)) X, gap 也就是555和之前一个record之间的间隙写锁
(3.5) row lock总结
在讲table锁之前总结一下讲过的行锁,请参考下图:
select * from tb_user_complaints where user_id = 555 for update;
(4) 表锁:IX与IS,X与S
相对行锁,表锁就没有那么常常遇到了。
(4.1) 表意向锁
在row record上加锁时,table schema可能会被直接修改掉,或者被drop掉。为了防止这种table级别的操作,innodb设计了意向锁(intention lock)来帮助快速确认一个table内部是不是有transaction正在进行锁操作或者其他的DML操作。总结一下 意向锁是一种表级锁,lockType是table,lockMode为IX/IS;但意向锁用意是表内有行操作所以要对表的操作做出限制,所以意向锁更多的是一种datalock并不算是真正的metalock。 对行的S锁操作触发的意向锁为IS锁,对行的写行为(update,insert相关)触发的意向锁为IX锁。
由于IX和IS并不会导致table本身被锁定所以IX和IS都是一种共享锁。在metaLock的角度,IX是shared write锁,IS是shared read锁。
当我们执行select * from tb_user_complaint where user_id = 555 for share;时会发现datalocks和metadata_locks表中会出现意向锁的记录:


(4.2) 表的读写锁
表的另一种锁就是和行锁对应的X锁与S锁,table级别的x锁与s锁和row级别的x锁和s锁相当类似,只是它锁的对象是table相关的元数据,从而这种锁是一种真正的metalock。 当我们进行DDL时,比如rename,alter或者drop首先要获得metalock的写锁。如果要显示的获得和释放table X/S lock需要执行下面语句。
LOCK TABLES table_name [READ | WRITE]
UNLOCK TABLES;
(4.3) 表锁的同享互斥关系
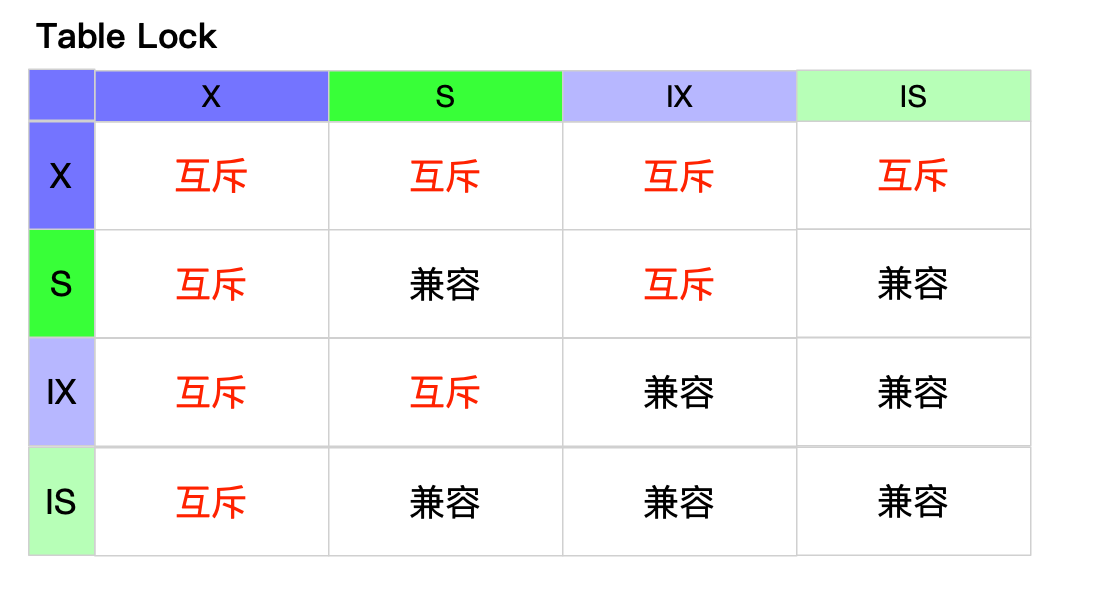
关于table对象上的表也可以通过一个表格来表示互斥共享关系:
- X锁一定与所有锁互斥,包括自己
这个很好理解,因为X锁往往代表要对lock object做修改,那么lock object本身的其他修改就要排队,object内部数据的锁定也要排队。所以X锁与所有意向锁(代表table内部数据)也都互斥。
- S锁与X,IX互斥,与S,IS兼容
S与S类的锁(S,IS)兼容这个很好理解,大家都是锁定读不发生写事件,互不干扰;S锁与X锁互斥也很好理解,这个机制和row的x与s互斥一样。但是笔者之前一直不能理解S锁为什么要与IX锁互斥呢,锁定table的meta data不能变动和改动table内部data的IX锁有什么关系呢?其实如果跳出meta这个局限把S锁理解成对table一个整体加的锁就很好理解了,S锁锁住了整个table,table的一切都只能读不能写无论是meta还是data- -!
- I锁和I锁之间兼容
由于I锁代表的是行数据的锁情况,所以I锁之间不会发生互斥问题。就算是因为I锁对应的是同一行,互斥问题也由行锁来处理,毕竟I锁是表级所已经不再负责具体的行信息了。
- IX与表的XS都互斥,与IXIS兼容
意向锁的兼容刚刚讲了,IX与XS互斥如果理解了XS就很好理解了,X和S都冻结了整个表的更改当然不能容忍标识行更改的IX存在了。
- IS只与X互斥
IS与S不互斥因为都是读互不影响,IS与IXIS不互斥因为都是标识的data,IS与X互斥由于X往往代表要对schema发生变更而schema变更往往会导致一行发生变更与S锁的目的相违背所以不能共存。
下集预告
下一篇主要讲一下几个问题:4种隔离级别,不一致性的几种情况(脏读幻读和不可重复读),在不同隔离级别下none-locking reading是如何做到consistent的,在不同的隔离级别下locking reads又是怎么加锁解决不一致问题的。
希望大家觉得有所帮助的不吝点赞哦,大家的支持是我继续整理案例的动力!
