


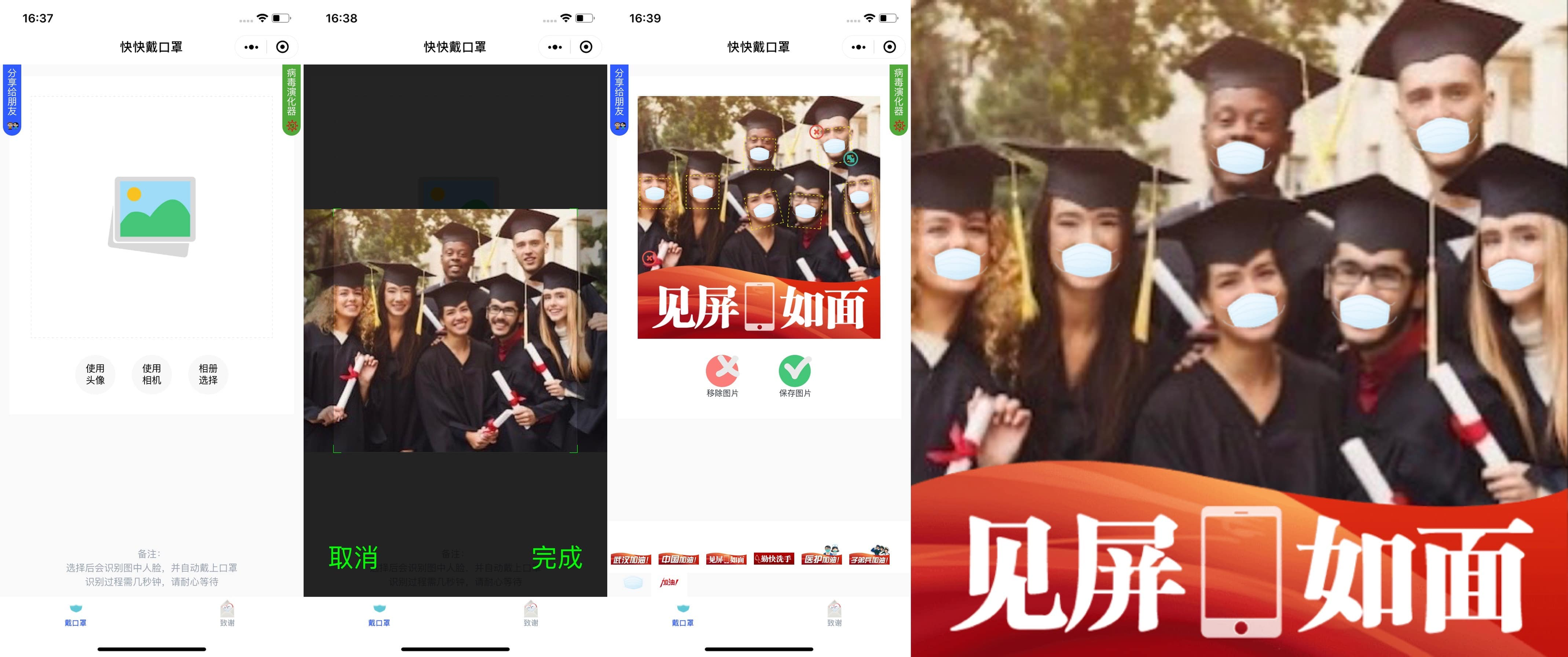
珍爱生命,从我做起,快点戴上口罩,给大家介绍我开源的 Taro + 腾讯云开发 小程序「快快戴口罩」它可以智能识别人脸,给集体照戴上口罩。(* ̄︶ ̄)
采用 Taro 跨端框架,采用腾讯云开发模式,采用基于腾讯云的五官分析的人脸识别,实现了自动为头像戴上口罩的功能。
源码地址:
我是 盛瀚钦,沪江 CCtalk 前端开发工程师,Taro 框架的 issue 维护志愿者,主要侧重于前端 UI 编写和团队文档建设。
主要功能
- 智能识别人脸,进行五官定位
- 支持多人识别
- 支持添加加油图片
扫码预览
微信搜一搜:快快戴口罩

小程序截图
Taro 云开发模式
Taro 是一套遵循 React 语法规范的 多端开发 解决方案。使用 Taro,我们可以只书写一套代码,再通过 Taro 的编译工具,将源代码分别编译出可以在不同端(微信/百度/支付宝/字节跳动/QQ/京东小程序、快应用、H5、React-Native 等)运行的代码。
本来呢,我的方案是小程序配合放在腾讯云个人服务器搭建的 nodejs + express实现的 API 服务。只不过呢,我个人配置的 API 请求不够理想,因为从小程序到腾讯云个人服务器再到腾讯云服务,中间路径比较长。
此时发现,Taro 已经集成了腾讯云云开发模式,从小程序+个人服务器切换到腾讯云开发模式,也就花了一个多小时的时间(历经了熟悉云开发、配置云开发环境等小细节)。
// taro/src/pages/wear-a-mask
Taro.cloud.callFunction({
name: 'analyze-face',
data: { fileID: '12345' }
}).then(res => console.log(res))
// cloud/functions/analyze-face 腾讯云人脸识别效果
return new Promise((resolve, reject) => {
// 通过client对象调用想要访问的接口,需要传入请求对象以及响应回调函数
client.AnalyzeFace(faceReq, function (error, response) {
// 请求异常返回,打印异常信息
if (error) {
const { code = '' } = error
resolve({
data: {},
time: new Date(),
status: -10086,
message: status.FACE_CODE[code] || '图片解析失败'
})
return
}
console.log('AnalyzeFace response :', response)
// 请求正常返回,打印response对象
resolve({
data: response,
time: new Date(),
status: 0,
message: ''
})
})
});
腾讯云五官识别
其实,启发我做这个小程序的是这两个文章,《「圣诞特辑」纯前端实现人脸识别自动佩戴圣诞帽》和《我要戴口罩 – 为微信、微博等社交网络头像戴口罩》。
因为新冠病毒疫情蔓延,而戴口罩就是一个必备的预防措施啦。那怎样才能创新呢,我在使用“我要戴口罩”小程序过程中发现,口罩的位置是手动移动的,我就想如何自动戴过去呢,正好先前看到的“自动识别戴圣诞帽”,那我来一个戴口罩就好了。
在“自动佩戴圣诞帽”中,使用的方案是纯前端的 face-api,想放到小程序中就会有如下几个小问题:
- face-api 的识别模型有 5M 大小还多,即使纯前端加载,也显得比较大。而小程序的 canvas 与 web 网页中的还是有差异的,没法直接用 face-api。
- face-api 放在 nodejs 上加载,还需要配合
tensorflow和canvas模拟。实际实现后发现,图片识别过程还是比较慢的(图片上传后、获取图片内容、识别五官位置、返回五官数据),容易让接口请求发生超时的情况。
在使用腾讯云的过程中,我就发现,腾讯云的人工智能大类目下居然有人脸识别功能,细致推究发现里面有“五官分析”,其返回的数据跟face-api返回的数据格式还是非常像的,“人脸识别”的每月免费额度 10000 次,当时就让我开心了一大把。
当然,使用过程中非常大的坑就是,我的实现过程是需要上传 1M 以上大小的图片,而“五官分析”签名方法需要TC3-HMAC-SHA256,官方提供 npm 版本tencentcloud-sdk-nodejs是不支持这个签名方法的,需要从官方 GitHub库的signature3分支上下载对应的代码。
裁剪图片
在“我要戴口罩”小程序中的另一个痛点就是如果上传一个长方形图片,会被强行变成正方形。我就想如何裁剪出正方形图片呢,此时在 npmjs 仓库中发现了taro-cropper这个强大的图片裁剪插件(也可以在 Taro 物料市场找到)。
口罩定位
从“五官分析”中得出人脸的五官数据后,如何基于此给人脸戴上口罩呢?“自动识别戴圣诞帽”是基于“三庭五眼”来计算出圣诞帽的位置,而口罩呢,其实更简单,获取嘴部的中点位置,再旋转缩放一下就行了。
- 获取嘴部信息,请先阅读《「圣诞特辑」纯前端实现人脸识别自动佩戴圣诞帽》,再看
taro/src/utils/face-utils.js中的getMouthInfo方法。 - 口罩定位呢,可以看下方代码~
let shapeList = info.map(item => {
let { faceWidth, angle, mouthMidPoint, ImageWidth } = item
let dpr = ImageWidth / CANVAS_SIZE * (375 / windowWidth)
const maskCenterX = mouthMidPoint.X / dpr
const maskCenterY = mouthMidPoint.Y / dpr
const scale = faceWidth / MASK_SIZE / dpr
const rotate = angle / Math.PI * 180
return {
maskSize: DEFAULT_MASK_SIZE,
maskCenterX,
maskCenterY,
scale,
rotate,
}
})
口罩定位
- 当 touchstart 时,保存此时的 touch 起始点,并以此时的底图和口罩位置作为旋转角度和缩放比例值计算的参考点
- 当 touchmove 时,根据起始点 和 临时的终止点 计算在 x/y 方向上的移动距离,计算参考点分别 加上这个距离,得到移动后的位置,通过移动前后的位置 计算移动前后位置的变动 计算旋转角和缩放比例
- 当 touchend 时,重置底图和口罩的位置及旋转角和缩放比例
Canvas 画图
- 首先绘制底图(根据屏幕大小、图片大小计算左上角和右下角坐标)
- 绘制口罩(计算最终口罩的大小及中心位置 旋转角度,移动画布原点到口罩的中心位置,旋转画布 并绘制口罩)
在微信小程序中,canvas 画图需要将网络图片变为本地图片的,如果绘制时再下载,存在下载时间挺长且容易下载失败的风险,还是使用本地图片更加靠谱一些。
在 Taro 项目,canvas 画图的drawImage(src, 0, 0, 300, 300)方法,如果 src 为require('../../images/xxx.png')的话,一定要记住修改以下配置,否则小程序就会报 http 500错误。
{
mini: {
imageUrlLoaderOption: {
limit: 0
}
}
参考项目
- 小程序:我要戴口罩,idealclover/Wear-A-Mask
- 自动圣诞帽:christmas-hat
- 自动识别人脸示例:bnk48-face-recognition
- 小程序:圣诞帽:jasscia/ChristmasHat
- face-api.js justadudewhohacks/face-api.js
- 腾讯云人脸识别: cloud.tencent.com/product/fac…
- Taro 版本图片裁剪:SunnyQjm/taro-cropper
- 病毒演化模拟器:qqqdu/zhonghuajia
欢迎关注凹凸实验室博客:aotu.io
或者关注凹凸实验室公众号(AOTULabs),不定时推送文章:

