

前言
前几天看到一个文章,感触很深
作者从0实现了大文件的切片上传,断点续传,秒传,暂停等功能,深入浅出的把这个面试题进行了全面的剖析
彩虹屁不多吹,我决定蹭蹭热点,录录视频,把作者完整写代码的过程加进去,并且接着这篇文章写,所以请看完上面的文章后再食用,我做了一些扩展如下
- 计算
hash耗时的问题,不仅可以通过web-workder,还可以参考React的FFiber架构,通过requestIdleCallback来利用浏览器的空闲时间计算,也不会卡死主线程 - 文件
hash的计算,是为了判断文件是否存在,进而实现秒传的功能,所以我们可以参考布隆过滤器的理念, 牺牲一点点的识别率来换取时间,比如我们可以抽样算hash - 文中通过
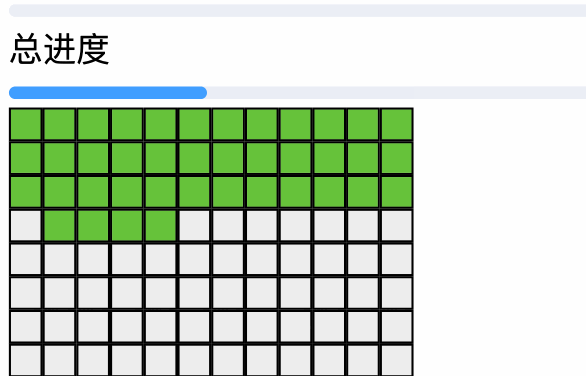
web-workder让hash计算不卡顿主线程,但是大文件由于切片过多,过多的HTTP链接过去,也会把浏览器打挂 (我试了4个G的,直接卡死了), 我们可以通过控制异步请求的并发数来解决,我记得这也是头条的一个面试题 - 每个切片的上传进度不需要用表格来显示,我们换成方块进度条更直管一些(如图)
- 并发上传中,报错如何重试,比如每个切片我们允许重试两次,三次再终止
- 由于文件大小不一,我们每个切片的大小设置成固定的也有点略显笨拙,我们可以参考
TCP协议的慢启动策略, 设置一个初始大小,根据上传任务完成的时候,来动态调整下一个切片的大小, 确保文件切片的大小和当前网速匹配 - 小的体验优化,比如上传的时候
- 文件碎片清理
已经存在的秒传的切片就是绿的,正在上传的是蓝色的,并发量是4,废话不多说,我们一起代码开花
时间切片计算文件hash
其实就是time-slice概念,React中Fiber架构的核心理念,利用浏览器的空闲时间,计算大的diff过程,中途又任何的高优先级任务,比如动画和输入,都会中断diff任务, 虽然整个计算量没有减小,但是大大提高了用户的交互体验
这可能是最通俗的 React Fiber(时间分片) 打开方式
requestIdleCallback
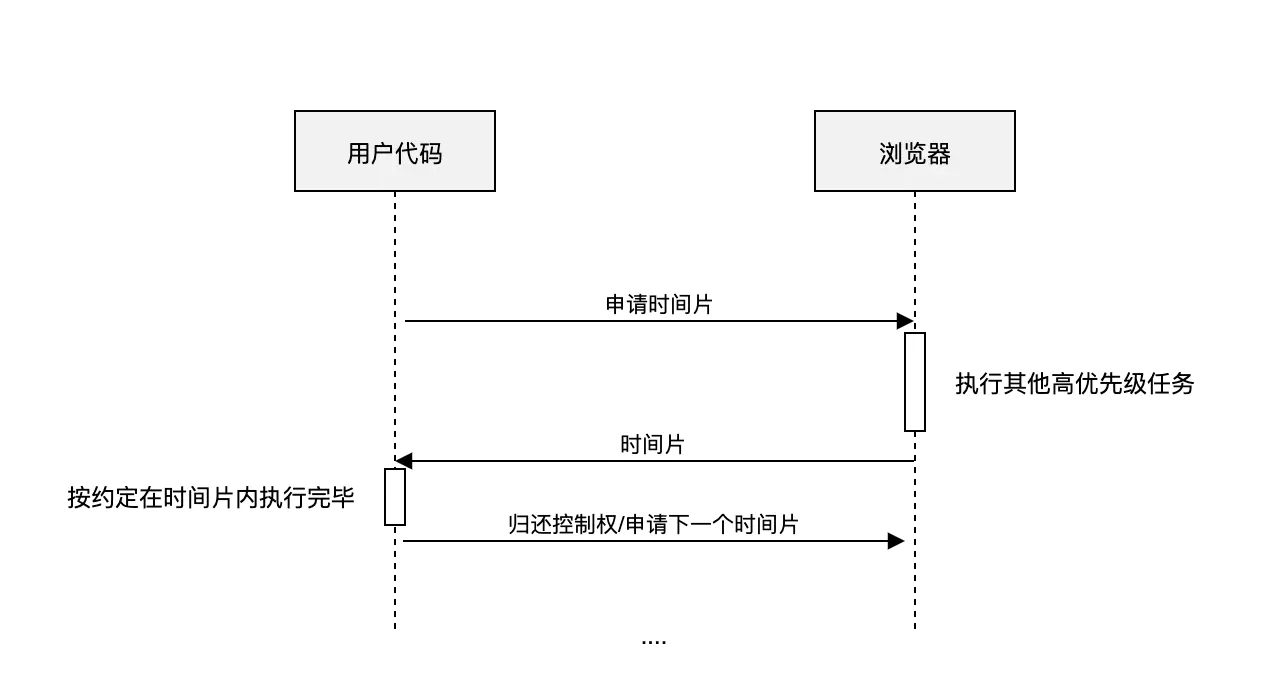
window.requestIdleCallback()方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作
requestIdelCallback执行的方法,会传递一个deadline参数,能够知道当前帧的剩余时间,用法如下
requestIdelCallback(myNonEssentialWork);
function myNonEssentialWork (deadline) {
// deadline.timeRemaining()可以获取到当前帧剩余时间
// 当前帧还有时间 并且任务队列不为空
while (deadline.timeRemaining() > 0 && tasks.length > 0) {
doWorkIfNeeded();
}
if (tasks.length > 0){
requestIdleCallback(myNonEssentialWork);
}
}
deadline的结构如下
interface Dealine {
didTimeout: boolean // 表示任务执行是否超过约定时间
timeRemaining(): DOMHighResTimeStamp // 任务可供执行的剩余时间
}

该图中的两个帧,在每一帧内部,TASK和redering只花费了一部分时间,并没有占据整个帧,那么这个时候,如图中idle period的部分就是空闲时间,而每一帧中的空闲时间,根据该帧中处理事情的多少,复杂度等,消耗不等,所以空闲时间也不等。
而对于每一个deadline.timeRemaining()的返回值,就是如图中,Idle Callback到所在帧结尾的时间(ms级)
时间切片计算
我们接着之前文章的代码,改造一下calculateHash
async calculateHashIdle(chunks) {
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
let count = 0;
// 根据文件内容追加计算
const appendToSpark = async file => {
return new Promise(resolve => {
const reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.onload = e => {
spark.append(e.target.result);
resolve();
};
});
};
const workLoop = async deadline => {
// 有任务,并且当前帧还没结束
while (count < chunks.length && deadline.timeRemaining() > 1) {
await appendToSpark(chunks[count].file);
count++;
// 没有了 计算完毕
if (count < chunks.length) {
// 计算中
this.hashProgress = Number(
((100 * count) / chunks.length).toFixed(2)
);
// console.log(this.hashProgress)
} else {
// 计算完毕
this.hashProgress = 100;
resolve(spark.end());
}
}
window.requestIdleCallback(workLoop);
};
window.requestIdleCallback(workLoop);
});
},
计算过程中,页面放个输入框,输入无压力,时间切片的威力
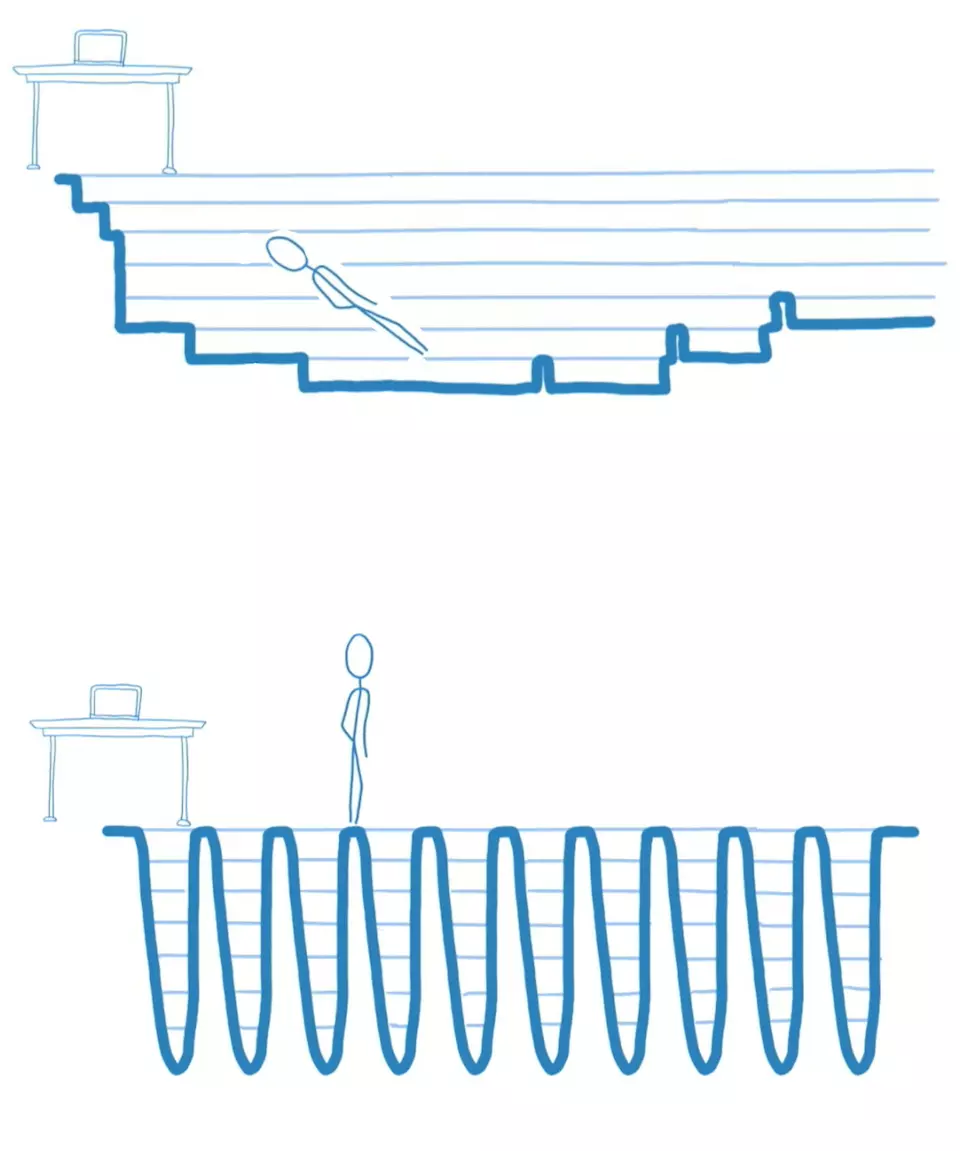
React15和Fiber架构的对比,可以看出下图任务量没边,但是变得零散了,不混卡顿主线程
抽样hash
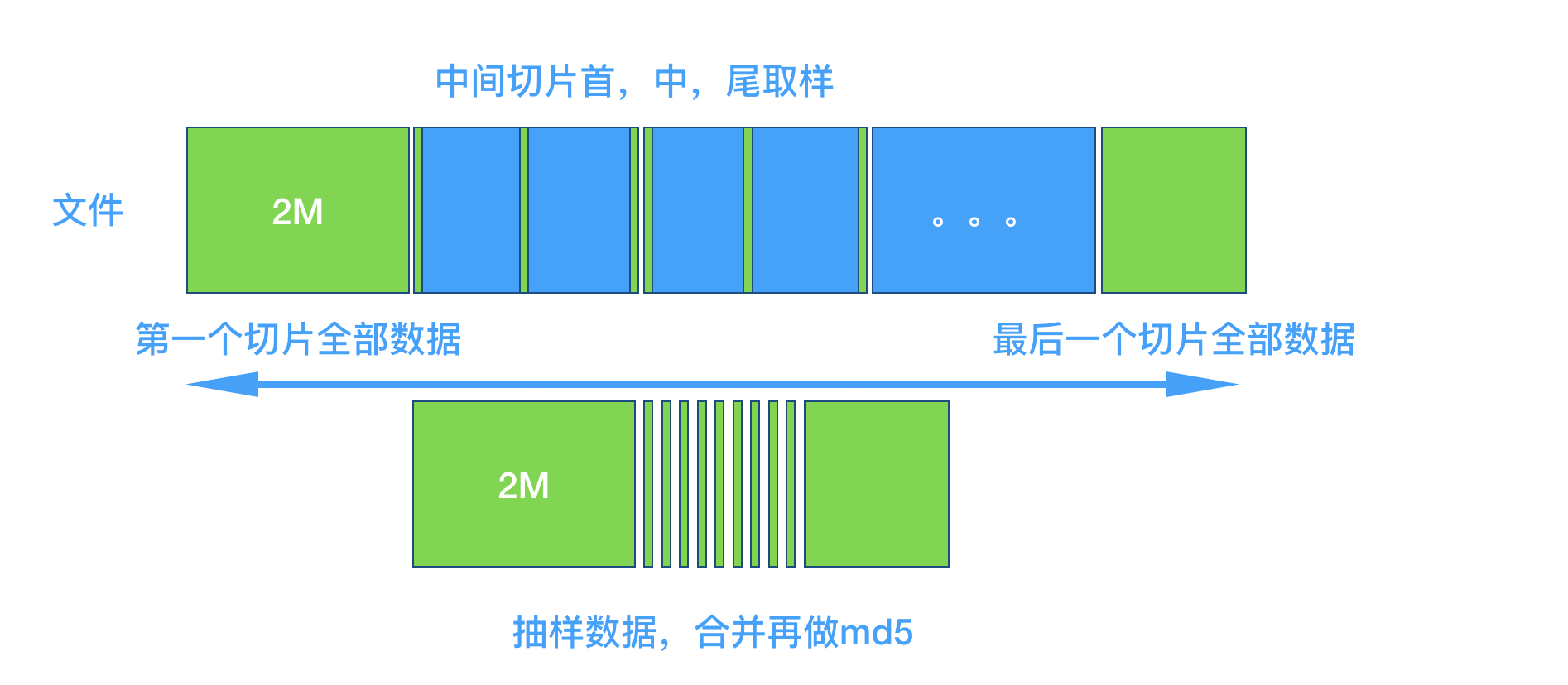
计算文件md5值的作用,无非就是为了判定文件是否存在,我们可以考虑设计一个抽样的hash,牺牲一些命中率的同时,提升效率,设计思路如下
- 文件切成2M的切片
- 第一个和最后一个切片全部内容,其他切片的取 首中尾三个地方各2个字节
- 合并后的内容,计算
md5,称之为影分身Hash - 这个
hash的结果,就是文件存在,有小概率误判,但是如果不存在,是100%准的的 ,和布隆过滤器的思路有些相似, 可以考虑两个hash配合使用 - 我在自己电脑上试了下1.5G的文件,全量大概要20秒,抽样大概1秒还是很不错的, 可以先用来判断文件是不是不存在
- 我真是个小机灵
抽样md5: 1028.006103515625ms
全量md5: 21745.13916015625ms
async calculateHashSample() {
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
const reader = new FileReader();
const file = this.container.file;
// 文件大小
const size = this.container.file.size;
let offset = 2 * 1024 * 1024;
let chunks = [file.slice(0, offset)];
// 前面100K
let cur = offset;
while (cur < size) {
// 最后一块全部加进来
if (cur + offset >= size) {
chunks.push(file.slice(cur, cur + offset));
} else {
// 中间的 前中后去两个字节
const mid = cur + offset / 2;
const end = cur + offset;
chunks.push(file.slice(cur, cur + 2));
chunks.push(file.slice(mid, mid + 2));
chunks.push(file.slice(end - 2, end));
}
// 前取两个字节
cur += offset;
}
// 拼接
reader.readAsArrayBuffer(new Blob(chunks));
reader.onload = e => {
spark.append(e.target.result);
resolve(spark.end());
};
});
}
网络请求并发控制
大文件hash计算后,一次发几百个http请求,计算哈希没卡,结果TCP建立的过程就把浏览器弄死了,而且我记得本身异步请求并发数的控制,本身就是头条的一个面试题

思路其实也不难,就是我们把异步请求放在一个队列里,比如并发数是3,就先同时发起3个请求,然后有请求结束了,再发起下一个请求即可, 思路清楚,代码也就呼之欲出了
我们通过并发数max来管理并发数,发起一个请求max--,结束一个请求max++即可
+async sendRequest(forms, max=4) {
+ return new Promise(resolve => {
+ const len = forms.length;
+ let idx = 0;
+ let counter = 0;
+ const start = async ()=> {
+ // 有请求,有通道
+ while (idx < len && max > 0) {
+ max--; // 占用通道
+ console.log(idx, "start");
+ const form = forms[idx].form;
+ const index = forms[idx].index;
+ idx++
+ request({
+ url: '/upload',
+ data: form,
+ onProgress: this.createProgresshandler(this.chunks[index]),
+ requestList: this.requestList
+ }).then(() => {
+ max++; // 释放通道
+ counter++;
+ if (counter === len) {
+ resolve();
+ } else {
+ start();
+ }
+ });
+ }
+ }
+ start();
+ });
+}
async uploadChunks(uploadedList = []) {
// 这里一起上传,碰见大文件就是灾难
// 没被hash计算打到,被一次性的tcp链接把浏览器稿挂了
// 异步并发控制策略,我记得这个也是头条一个面试题
// 比如并发量控制成4
const list = this.chunks
.filter(chunk => uploadedList.indexOf(chunk.hash) == -1)
.map(({ chunk, hash, index }, i) => {
const form = new FormData();
form.append("chunk", chunk);
form.append("hash", hash);
form.append("filename", this.container.file.name);
form.append("fileHash", this.container.hash);
return { form, index };
})
- .map(({ form, index }) =>
- request({
- url: "/upload",
- data: form,
- onProgress: this.createProgresshandler(this.chunks[index]),
- requestList: this.requestList
- })
- );
- // 直接全量并发
- await Promise.all(list);
// 控制并发
+ const ret = await this.sendRequest(list,4)
if (uploadedList.length + list.length === this.chunks.length) {
// 上传和已经存在之和 等于全部的再合并
await this.mergeRequest();
}
},
话说字节跳动另外一个面试题我也做出来的,不知道能不能通过他们的一面
慢启动策略实现
TCP拥塞控制的问题 其实就是根据当前网络情况,动态调整切片的大小
chunk中带上size值,不过进度条数量不确定了,修改createFileChunk, 请求加上时间统计)- 比如我们理想是30秒传递一个
- 初始大小定为1M,如果上传花了10秒,那下一个区块大小变成3M
- 如果上传花了60秒,那下一个区块大小变成500KB 以此类推
- 并发+慢启动的逻辑有些复杂,我自己还没绕明白,囧所以先一次只传一个切片,来演示这个逻辑,新建一个
handleUpload1函数
async handleUpload1(){
// @todo数据缩放的比率 可以更平缓
// @todo 并发+慢启动
// 慢启动上传逻辑
const file = this.container.file
if (!file) return;
this.status = Status.uploading;
const fileSize = file.size
let offset = 1024*1024
let cur = 0
let count =0
this.container.hash = await this.calculateHashSample();
while(cur<fileSize){
// 切割offfset大小
const chunk = file.slice(cur, cur+offset)
cur+=offset
const chunkName = this.container.hash + "-" + count;
const form = new FormData();
form.append("chunk", chunk);
form.append("hash", chunkName);
form.append("filename", file.name);
form.append("fileHash", this.container.hash);
form.append("size", chunk.size);
let start = new Date().getTime()
await request({ url: '/upload',data: form })
const now = new Date().getTime()
const time = ((now -start)/1000).toFixed(4)
let rate = time/30
// 速率有最大2和最小0.5
if(rate<0.5) rate=0.5
if(rate>2) rate=2
// 新的切片大小等比变化
console.log(`切片${count}大小是${this.format(offset)},耗时${time}秒,是30秒的${rate}倍,修正大小为${this.format(offset/rate)}`)
// 动态调整offset
offset = parseInt(offset/rate)
// if(time)
count++
}
}
调整下slow 3G网速 看下效果
切片0大小是1024.00KB,耗时13.2770秒,是30秒的0.5倍,修正大小为2.00MB
切片1大小是2.00MB,耗时25.4130秒,是30秒的0.8471倍,修正大小为2.36MB
切片2大小是2.36MB,耗时14.1260秒,是30秒的0.5倍,修正大小为4.72MB
搞定
进度条优化
这就属于小优化了,方便我们查看存在的文件区块和并发数,灵感来自于硬盘扫描
<div class="cube-container" :style="{width:cubeWidth+'px'}">
<div class="cube"
v-for="chunk in chunks"
:key="chunk.hash">
<div
:class="{
'uploading':chunk.progress>0&&chunk.progress<100,
'success':chunk.progress==100
}"
:style="{height:chunk.progress+'%'}"
>
<i v-if="chunk.progress>0&&chunk.progress<100" class="el-icon-loading" style="color:#F56C6C;"></i>
</div>
</div>
</div>
.cube-container
width 100px
overflow hidden
.cube
width 14px
height 14px
line-height 12px;
border 1px solid black
background #eee
float left
>.success
background #67C23A
>.uploading
background #409EFF
// 方块进度条尽可能的正方形 切片的数量平方根向上取整 控制进度条的宽度
cubeWidth(){
return Math.ceil(Math.sqrt(this.chunks.length))*16
},
效果还可以 再看一遍🐶
并发重试+报错
- 请求出错.catch 把任务重新放在队列中
- 出错后progress设置为-1 进度条显示红色
- 数组存储每个文件hash请求的重试次数,做累加 比如
[1,0,2],就是第0个文件切片报错1次,第2个报错2次 - 超过3的直接
reject
首先后端模拟报错
if(Math.random()<0.5){
// 概率报错
console.log('概率报错了')
res.statusCode=500
res.end()
return
}
async sendRequest(urls, max=4) {
- return new Promise(resolve => {
+ return new Promise((resolve,reject) => {
const len = urls.length;
let idx = 0;
let counter = 0;
+ const retryArr = []
const start = async ()=> {
// 有请求,有通道
- while (idx < len && max > 0) {
+ while (counter < len && max > 0) {
max--; // 占用通道
console.log(idx, "start");
- const form = urls[idx].form;
- const index = urls[idx].index;
- idx++
+ // 任务不能仅仅累加获取,而是要根据状态
+ // wait和error的可以发出请求 方便重试
+ const i = urls.findIndex(v=>v.status==Status.wait || v.status==Status.error )// 等待或者error
+ urls[i].status = Status.uploading
+ const form = urls[i].form;
+ const index = urls[i].index;
+ if(typeof retryArr[index]=='number'){
+ console.log(index,'开始重试')
+ }
request({
url: '/upload',
data: form,
onProgress: this.createProgresshandler(this.chunks[index]),
requestList: this.requestList
}).then(() => {
+ urls[i].status = Status.done
max++; // 释放通道
counter++;
+ urls[counter].done=true
if (counter === len) {
resolve();
} else {
start();
}
- });
+ }).catch(()=>{
+ urls[i].status = Status.error
+ if(typeof retryArr[index]!=='number'){
+ retryArr[index] = 0
+ }
+ // 次数累加
+ retryArr[index]++
+ // 一个请求报错3次的
+ if(retryArr[index]>=2){
+ return reject()
+ }
+ console.log(index, retryArr[index],'次报错')
+ // 3次报错以内的 重启
+ this.chunks[index].progress = -1 // 报错的进度条
+ max++; // 释放当前占用的通道,但是counter不累加
+
+ start()
+ })
}
}
start();
}
如图所示,报错后会区块变红,但是会重试
文件碎片清理
如果很多人传了一半就离开了,这些切片存在就没意义了,可以考虑定期清理,当然 ,我们可以使用node-schedule来管理定时任务
比如我们每天扫一次target,如果文件的修改时间是一个月以前了,就直接删除把
// 为了方便测试,我改成每5秒扫一次, 过期1钟的删除做演示
const fse = require('fs-extra')
const path = require('path')
const schedule = require('node-schedule')
// 空目录删除
function remove(file,stats){
const now = new Date().getTime()
const offset = now - stats.ctimeMs
if(offset>1000*60){
// 大于60秒的碎片
console.log(file,'过期了,浪费空间的玩意,删除')
fse.unlinkSync(file)
}
}
async function scan(dir,callback){
const files = fse.readdirSync(dir)
files.forEach(filename=>{
const fileDir = path.resolve(dir,filename)
const stats = fse.statSync(fileDir)
if(stats.isDirectory()){
return scan(fileDir,remove)
}
if(callback){
callback(fileDir,stats)
}
})
}
// * * * * * *
// ┬ ┬ ┬ ┬ ┬ ┬
// │ │ │ │ │ │
// │ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
// │ │ │ │ └───── month (1 - 12)
// │ │ │ └────────── day of month (1 - 31)
// │ │ └─────────────── hour (0 - 23)
// │ └──────────────────── minute (0 - 59)
// └───────────────────────── second (0 - 59, OPTIONAL)
let start = function(UPLOAD_DIR){
// 每5秒
schedule.scheduleJob("*/5 * * * * *",function(){
console.log('开始扫描')
scan(UPLOAD_DIR)
})
}
exports.start = start
开始扫描
/upload/target/625c.../625c...-0 过期了,删除
/upload/target/625c.../625c...-1 过期了,删除
/upload/target/625c.../625c...-10 过期了,删除
/upload/target/625c.../625c...-11 过期了,删除
/upload/target/625c.../625c...-12 过期了,删除
后续扩展和思考
留几个思考题,下次写文章再实现 方便继续蹭热度
- requestIdleCallback兼容性,如何自己实现一个
- react也是自己写的调度逻辑,以后有机会写个文章介绍
- React自己实现的requestIdleCallback
- 并发+慢启动配合
- 抽样hash+全量哈希+时间切片配合
- 大文件切片下载
- 一样的切片逻辑,通过axios.head请求获取content-Length
- 使用http的Range这个header就可以切片下载了,其他逻辑和上传差不多
- 小的体验优化
- 比如离开页面的提醒 等等小tips
- 慢启动的变化应该更平滑,比如使用三角函数,把变化率平滑的限制在0.5~1.5之间
- websocket推送进度
思考和总结
- 任何看似简单的需求,量级提升后,都变得很复杂,人生也是这样
- 文件上传简单,大文件就复杂,单机简单,分布式难
- 就连一个简单的leftPad函数(左边补齐字符),考虑到性能,二分法性能都秒杀数组join ,引起大讨论
- 论left-pad函数的实现
- 任何一个知识点 都值得深挖
- 产品经理下次再说啥需求简单,就kan他
- 我准备结合上一篇,录一个大文件上传的手摸手剖析视频 敬请期待

代码
前半段抄袭了@yeyan1996的代码,后面代码主要为了讲明思路,实现的比较粗糙,求轻喷
github.com/shengxinjin…
欢迎关注

参考资料
有些图也是我直接从下面连接中copy的
