

Redis将数据存储在内存中,宕机或重启都会使内存数据全部丢失, Redis的持久化机制用来保证数据不会因为故障而丢失。Redis提供两种持久化方式,一种为内存快照方式,生成rdb文件,rdb是某一时间点内存数据的全量备份,文件内容是存储结构非常紧凑的二进制序列化形式;另一种是AOF日志备份方式,日志保存的是基于数据的连续增量备份,日志文件内容是服务端执行的每一条指令的记录文本。两种方式各有优略,下面的章节会详细介绍两种持久化机制的实现原理和使用技巧。
1.内存快照
Redis进行快照数据持久化时,为了不阻塞线上业务,要能够响应客户端请求。快照持久化的工作是将一个时间点内存数据序列化后同步到磁盘rdb文件。备份数据如何在内存中瞬间凝固,不再改变?文件IO操做怎样才能不拖累服务端对客户端的正常响应?这一切都要从Copy On Write说起。
1.1 快照原理——Copy On Write
Copy On Write简写为COW,又叫写时复制,是操作系统为优化使用子进程采取的一种策略。
类Unix系统创建进程的主要方式是调用glibc的函数fork,熟悉Linux的人都知道:Linux操作系统的进程都是通过init进程(pid=1)或者其子进程fork(vfork)出来的。
fork()会产生一个与父进程完全相同的子进程,有两次返回:将子进程的pid返回给父进程,0返回给子进程。如果小于0,说明创建进程失败!下面是一个C语言的例子:
#include <unistd.h>
#include <stdio.h>
int main() {
pid_t pid;
int count = 0;
pid = fork();
if (pid < 0)
printf("error in fork!");
else if (pid == 0) {
printf("child process, process id is %d/n", getpid());
count++;
} else {
printf("parent process, process id is %d/n", getpid());
count++;
}
printf("count total: %d/n", count);
return 0;
}
输出结果为:
parent process, process id is 23049
count total: 1
child process, process id is 23050
count total: 1
当前进程调用fork(),会创建一个跟当前进程完全相同的子进程(除了pid),所以子进程同样是会执行fork()之后的代码。父子进程的count变量都是1,说明父子进程使用了各自独有的栈区(count变量存放在栈区)。
我们先来看一下CPU执行程序的流程。
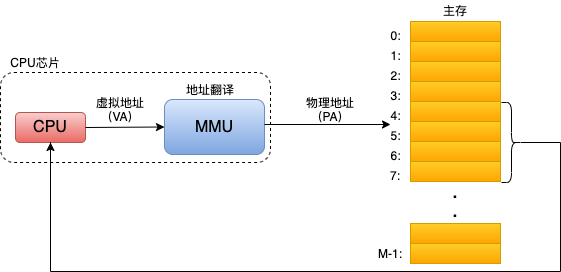
CPU在加载执行程序时,首先按照虚拟地址来寻址,然后通过MMU(内存管理单元)将虚拟地址转换为物理地址。因为只有程序的一部分加入到内存中(按页加载),所以会出现所寻找的地址不在内存中的情况(CPU产生缺页异常),如果在内存不足的情况下,就会通过页面调度算法来将内存中的页面置换出来,然后将在外存中的页面加入到内存中,使程序继续正常运行。
Linux操作系统的每一个进程,都会分配有虚拟地址和物理地址,虚拟地址和物理地址通过MMU保持映射关系。一个进程是一个主体,它有灵魂有身体,灵魂就是其虚拟地址空间(有相应的数据结构表示),包括:正文段、数据段、堆、栈这四个部分;相应的,内核会为这四个部分分配各自的物理块(进程的身体)即:正文段块、数据段块、堆块、栈块。
我们再来看一下fork进程时写时复制的过程:
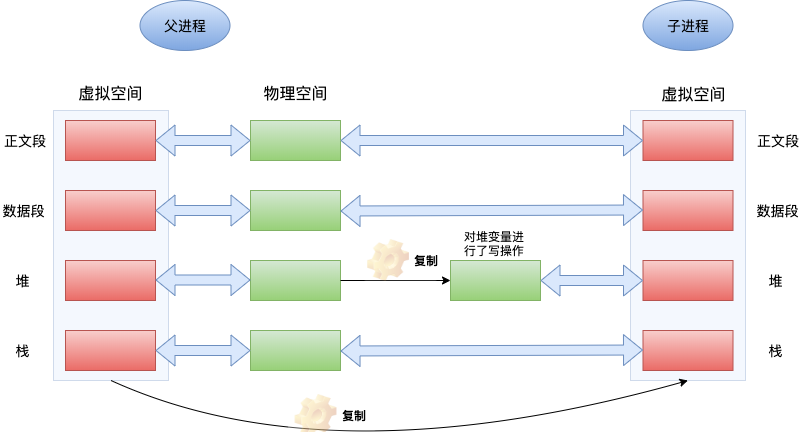
在fork产生子进程时,操作系统只为新生成的子进程创建虚拟空间结构,它们复制于父进程的虚拟空间结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,这就是写时复制。
1.2 快照执行流程
Redis在持久化时会调用glibc的函数fork产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求。
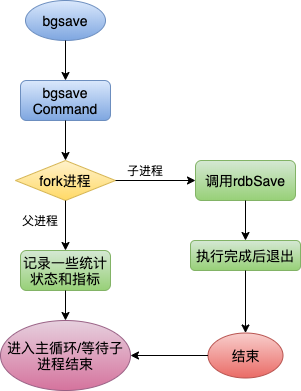
可以通过在Redis客户端输入bgsave命令来触发快照保存操作,Redis调用bgsaveCommand函数,该函数fork一个子进程,子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。这时将父子进程比喻成一个连体婴儿非常恰当,这是Linux操作系统的机制,为了节约内存资源,尽可能的将内存资源共享起来。在进程分离的一瞬间,内存的增长几乎没有明显的变化。子进程因为没有数据的变化,它能感知到的内存数据在进程产生的一瞬间就凝固了,再也不会改变。父进程可以继续处理客户端请求,当子进程推出后,父进程调用相关函数处理子进程的善后工作。
2.AOF持久化
AOF日志存储的Redis服务器的顺序指令序列,只记录对内存进行修改的指令记录。有了AOF文件,就可以通过一个空的Redis实例顺序执行所有的指令来恢复Redis当前实例的内存数据结构的状态,这个过程叫做重放。
2.1 AOF日志文件写入
AOF日志以文件的形式存在,写文件通过操作系统提供的write函数执行,但是write之后的数据只是写到了内核的一个缓冲区中,然后内核还需要异步的调用fsync函数异步的将数据刷回磁盘。fsync函数是一个阻塞并且缓慢的操作,如果机器突然宕机,AOF日志内容可能还没来的及完全刷到磁盘,这时候就会丢失数据。Redis通过appendfsync配置控制执行fsync的频次,具体有如下三种模式:
- no: 永远不调用fsync,让操作系统决定何时同步磁盘,这样做很不安全,但是Redis的性能最高。
- always: 每执行一次写入操作就执行一次fsync,虽然数据安全性高,会导致执行非常缓慢。
- everysec: 每隔1s执行一次fsync,这个1s的周期是可以配置的,这是数据安全性和性能之间的折中方案,在保证高性能的同时,尽量使数据少丢失。推荐在生产环境中使用。
2.2 AOF执行流程
Redis收到客户端的指令以后,首先进行参数校验、逻辑处理,如果没有问题,会判断是否开启AOF,如果开启,则会将每条命令执行完毕后同步写入aof_buf中,aof_buf是个全局的SDS类型的缓冲区。
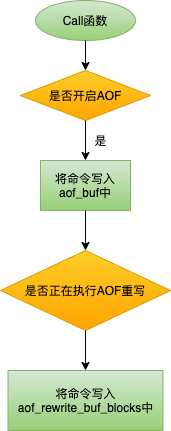
每一条命令的执行都会调用call函数,注意:Redis服务端是先执行指令再将命令写入aof_buf。
2.3 日志瘦身——AOF重写
Redis服务端在长期运行过程中,AOF日志会越来越长,如果实例宕机或者重启,重放整个AOF日志会非常耗时,导致Redis长时间无法对外提供服务,所以需要对AOF日志进行瘦身,即:AOF重写。
我们考虑一下AOF和RDB文件的加载过程:RDB只需要把相应的数据加载都内存并生成相应的数据结构就可以了,有些结构如intset、ziplist,保存的时候直接按照字符串保存,加载速度非常快。但是AOF日志文件的加载需要创建一个伪客户端,顺序执行一遍命令,根据Redis作者做的测试,RDB在10~20秒能加载1GB的文件,AOF的速度是RDB的一半(如果做了AOF重写会加快)
通过Redis客户端bgrewriteaof指令对AOF日志进行瘦身过程如下:
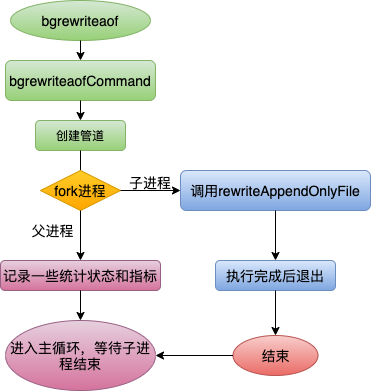
Redis服务端调用bgrewriteaofCommand命令创建管道,创建管道对作用是AOF重写过程中批量接收服务端累积的命令;创建完管道以后,fork进程,子进程调用rewriteAppendOnlyFile执行AOF重写操作;父进程记录一些统计指标后继续进入主循环处理客户端请求,待子进程结束以后,处理一些善后工作。瘦身工作就是子进程对所有数据库中的键各自生成一条相应的执行命令,最后将重写开始后父进程继续执行的命令进行回放,生成一个新的AOF文件。
例如执行了下面的命令:
127.0.0.1:6379> lpush list guo zhao ran
(integer) 3
127.0.0.1:6379> lpop list
"ran"
127.0.0.1:6379> lpop list
"zhao"
127.0.0.1:6379> lpush list zhao
(integer) 2
AOF文件会保存对list操作的4条命令,但是list现在内存中的元素是这样的:
127.0.0.1:6379> lrange list 0 -1
1) "zhao"
2) "guo"
AOF重写以后就日志文件内容直接就变为了lpush list zhao guo。日志瘦身既可以减小文件大小,又可以提高加载速度。
3.混合持久化
RDB和AOF实现持久化的方式各有优缺点,我们来简单总结一下:
RDB保存的是一个时间的快照,如果发生故障,丢失的是最后一次RDB执行时间点到故障发生的时间间隔之内产生的数据。如果Redis数据量很大,QPS很高,执行一次RDB需要的时间会相应增加,发生故障时丢失的数据也会增多。
AOF保存的是一条条的命令,理论上可以做到发生故障时只丢失一条命令。但是由于操作系统中执行写文件操作代价很大,Redis提供了配置参数,可以对完全性和性能取折中,设置不同的配置策略。但是重放AOF日志相对于使用RDB来说还是慢很多。
Redis4.0为了解决这个问题,带来了一个新的持久化选项——混合持久化。混合持久化是指进行AOF重写时子进程将当前时间点的数据快照保存为RDB文件格式,而后将父进程累积命令保存为AOF格式,最终生成的格式如下图所示:
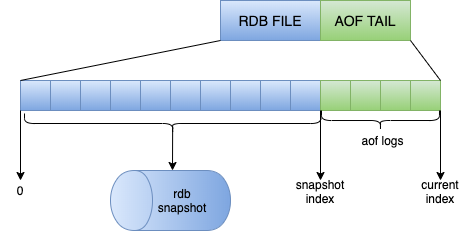
将RDB文件内容和增量AOF日志文件存在一起,这里的AOF日志不再是全量日志,通常这部分AOF日志很小。于是在Redis重启的时候,可以先加载rdb内容,然后再重放增量AOF日志,就可以完全替代之前的AOF全量文件重放,重启效率会得到大幅度提升。
4. Redis持久化相关配置
下面总结一下Redis4.0版持久化相关的配置及其含义。
| 配置项 | 可选值 | 默认值 | 作用 |
|---|---|---|---|
| save | save <seconds> <changes> | save 900 1 save 300 10 save 60 10000 |
save "":禁用快照备份,默认关闭 save 900 1:在900秒内有1个key被改动,自动保存到dump.rdb文件中 save 300 10:在300秒内有10个key被改动,自动保存到dump.rdb文件中 save 60 10000:在60秒内有10000个key被改动,自动保存到dump.rdb文件中 以上3中条件任意一种被满足就会触发保存 |
| stop-writes-on-bgsave-error | yes/no | yes | 开启该参数后,如果开启了RDB快照(即配置了save指令),并且最近一次快照执行失败,则Redis将停止接收写相关的请求 |
| rdbcompression | yes/no | yes | 执行rdb的时候是否将string类型的数据压缩 |
| rdbchecksum | yes/no | yes | 是否开启rdb文件内容的校验 |
| dbfilename | 文件名称 | dump.rdb | rdb文件名称 |
| dir | 文件路径 | ./ | RDB和AOF文件存放路径 |
| appendonly | yes/no | no | 是否开启AOF功能 |
| appendfilename | 文件名称 | appendonly.aof | AOF文件名称 |
| appendfsync | always/everysec/no | everysec | fsync执行频次,上边有说到 |
| no-appendfsync-on-rewrite | yes/no | no | 开启该参数后,如果后台正在执行一次rdb快照或者aof重写,则主进程不再进行fsync操作,即使将appendsync配置成always或者everysec |
| auto-aof-rewrite-percentage | 百分比 | 100 | 和auto-aof-rewrite-min-size配和使用,下面会讲解 |
| auto-aof-rewrite-min-size | 文件大小 | 64M | 当AOF文件大于64M时,并且AOF文件当前大小比基准大小增长了100%时会触发一次AOF重写。 |
| aof-load-truncated | yes/no | yes | AOF以追加日志的方式生成,当服务端发生故障时会有命令不完整的情况。开启该参数后,在这种情况下,AOF会截断尾部不完整的命令继续加载,并且在日志中给出提示。 |
| aof-use-rdb-preamble | yes/no | yes | 是否开启混合持久化 |
| aof-rewrite-incremental-fsync | yes/no | yes | 开启该参数后,AOF重写时每产生32MB数据执行一次fsync |
5.总结
Redis是内存数据库,机器故障或重启之后,内存数据全部丢失,所以需要持久化来保证数据安全。Redis提供了快照RDB和AOF日志同步两种方式进行数据持久化,快照RDB实现原理是Copy On Write,优点是机器加载速度快,缺点是执行缓慢,QPS高的情况下会丢失大量数据;AOF则是将命令一条条的有序存放到日志文件中,优点是尽可能少的丢失数据,缺点是日志文件重放缓慢,日志文件会很大,可以通过重写AOF日志来实现,另外提供了这种的配置方案异步执行fsync操作。生产环境中推荐使用混合持久化,这种方式综合了RDB和AOF两种方式的优点。文章最后总结了一下Redis持久化配置项。本文是笔者学习Redis持久化的总结,希望能对读者有所帮助。
