

分区(Heap Region,HR)
分区类型
- 自由分区(Free Heap Region,FHR)
- 新生代分区(Young Heap Region,YHR)
- Eden
- Survivor
- 大对象分区(Humongous Heap Region,HHR)
- 大对象头分区
- 大对象连续分区
- 老年代分区(Old Heap Region,OHR)
分区大小设置(1M ~ 32M,且为2的幂)
HR的大小直接影响分配和垃圾回收的效率。
大,HR可以放更多对象,分配效率高,回收花费时间过长
小,分配效率低,易回收
HR大小分配方式
- 配置参数 G1HeapRegionSize,默认值为0
- 当 G1HeapRegionSize 为0,则开启启发式推断
启发式推断
- 依据 堆空间的最大值和最小值以及HR个数进行推断
- 设置Initial HeapSize(默认为0)等价于设置Xms
- 设置MaxHeapSize(默认为96M)等价于设置Xmx
- 计算大小的方式在HeapRegion.cpp中的setup_heap_region_size()
- 由于分区大小需要落在1M~32M之间,按照默认的分区个数(2048个)来计算,最大内存为 64G,最小内存为2G
- 例如设置xms = 32G,xmx=128G,则xms算出的HR大小为 16M,xmx算出的分区大小为 64M > 32M,所以设置为32M,两者取最大值,所以HR大小为32M。所以分区个数动态范围变化为1024个到4096个之间。
- 由于分区大小需要落在1M~32M之间,按照默认的分区个数(2048个)来计算,最大内存为 64G,最小内存为2G
大对象
- 算出HR大小后,就可以根据HR大小来判断大对象,即只要 >= 1/2 heap_region_size 的都为大对象
新生代大小分配
- 直接设置 MaxNewSize (新生代最大值),NewSize(新生代最小值)
- 如果设置了Xmn参数,等价于设置了 MaxNewSize = NewSize = Xmn
- 如果既设置了最大值或最小值,又设置了NewRatio,则NewRatio不生效
- 如果没设置最大值或最小值,但是设置了NewRatio,则 MaxNewSize = NewSize = 堆空间/(NewRatio+1)
- 如果没设置最大值或最小值,或只设置了其中一个,那么G1将根据参数G1MaxNewSizePercent(默认为60)和G1NewSizePercent(默认为5)占整个堆空间的比例来计算最大最小值。
- 如果MaxNewSize == NewSize,则说明新生代不会动态变化,在后续堆新生代垃圾回收的时候可能不能满足期望停顿的时间。
新生代的变化如何实现
- G1有个线程专门抽样处理预测新生代列表的长度应该多大,并动态调整
- 使用分区列表。
- 扩展时
- 如果有空闲的分区列表,则可以直接把空闲分区加入到新生代分区列表中。
- 如果没有的话,分配新的分区然后把它加入新生代分区列表中。
- 扩展时
分配新的分区时,如何扩展,一次拓展多少内存
- 参数 -XX:GCTimeRatio 表示GC与应用的耗费时间比,G1默认是9
- 当GC时间/应用时间超过(GCTimeRatio+1)% 时,就可以动态扩展;按照默认值,这个比例为10%
- 扩展的比例由G1ExpandByPercentOfAvailable(默认为20)控制;即每次从未提交的内存中申请20%
- 一次拓展的内存不能小于1M,最多是目前已分配的一倍。
G1停顿预测模型
G1是个响应时间优先的GC算法
- 参数MaxGCPauseMills控制(默认值200ms),该值为期望值。G1会尽可能靠近这个期望值,但是也有可能完不成。
- G1根据这个模型来分析,这次需要回收多少个分区,可以满足这个期望值。 例如过去N次回收时间和回收分区数量之间的关系。
- G1利用衰减平均算法,给越近的数据以更高的权重,来计算数据的平均值。
卡表和位图
- 卡表(CardTable):在CMS中用来记录内存对象应用关系。
- 位图(bitmap)
- 设有HR1和HR2,HR1中有对象A,HR2中有对象B,且A.obj = B,这时候两个HR就有引用关系了。这时候,我们在HR1中,如何能引用到HR2呢?这时候位图就登场了。
- 设置位图的方法,记录两个内存分区之间的引用关系。假设在32位的机器上(一个字为32位),需要32KB的空间来描述一个分区。那么我们就在A中添加一个额外的指针,这个指针指向B的位图。从这个指针指向的位图就能找到被A引用的HR2对应的内存块。这时候我们只需要判断位图里对应的位是否有1,有的话则认为发生了引用。
- 设有HR1和HR2,HR1中有对象A,HR2中有对象B,且A.obj = B,这时候两个HR就有引用关系了。这时候,我们在HR1中,如何能引用到HR2呢?这时候位图就登场了。
对象头
- java代码首先被编译为字节码,在JVM执行的时候,才能确定执行函数的地址,通过把java对象映射/封装成一个C++对象。比如加一个对象头,里面指向一个对象,而这个对象存储了java代码的地址。
- JVM设计了一个对象结构来描述java对象,结构分为 对象头(Header),实例数据(Instance Data),对齐填充(Padding)
- 虚指针: 虚指针指向一个虚表,虚表里存的是虚函数地址。
对象头分为两部分:标记信息,元数据信息
- jvm中的java对象都是继承于oopDesc
class oopDesc {
friend class VMStructs;
friend class JVMCIVMStructs;
private:
// 对象头
volatile markOop _mark;
// 元数据
union _metadata {
// 对应的Klass对象
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
- 标记信息就位于 markOop,java对象头的位格式如下
32 bits:
--------
hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
size:32 ------------------------------------------>| (CMS free block)
PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
64 bits:
--------
unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
size:64 ----------------------------------------------------->| (CMS free block)
unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
- age:分代年龄
- biased_lock:是否偏向锁(1是0非)
- lock:锁状态标志位
- 当lock为
11时,指针配合对象晋升时候发生的复制:- 当新生代晋升为老年代时
- 先分配空间
- 再把原有对象的所有数据都复制过去
- 最后修改对象引用指针
- lock设置为marked,即
11,表示对象已经被标记复制了,ptr指向新的地址。 - 当遍历其他引用对象时,如果发现被引用对象已经完成标记,则不用再复制对象,直接完成对象引用的更新即可。
- 当lock为
- promoted:当对象从新生代晋升到老年代的时候,如果晋升失败,需要重新恢复对象头。如果晋升成功,则promo_bits没有意义。实际上只需要在以下三种情况时才需要保存对象头:
- 使用了偏向锁,并且偏向锁被设置了。
- 对象被上锁了
- 对象设置了hashcode
- 原数据信息
- 指向Klass对象,Klass对象是元数据对象。
- GC在根结点发现了一个值(例如0x12345678),那么JVM如何判断这个是个立即数还是地址呢。实际上垃圾回收器无法判断。
- JVM会将这个值看成一个地址,转换成OOP对象,再看看这个OOP是否含有Klass指针,如果有的话,认为这个值是个指针,否则则认为是个数。
- 如果这个数正好和一个OOP地址相同,JVM同时维护了一个全局的OopMap,标记栈里的数是立即数还是个值。
- 每个InstanceKlass都维护了这个map(OopMapBlock)用于标记是OOP还是立即数。
内存分配和管理
JVM如何管理内存的
- JVM通过操作系统的**系统调用(System Call)**申请,典型的就是mmap。
- 内存只能以**页(Page Size)**的方式来映射,如果映射非Page Size整数倍的,就先进行内存对齐,再以Page Size的倍数进行映射。
- 告知操作系统,需要为其**保留(reserve)**一段连续的虚拟内存,进程其他分配内存的操作不得使用这段内存。
- **提交(commit)**虚拟地址,映射到真实的物理地址内存中,这块内存就可以正常使用。
JVM常见的对象类型
- ResourceObj:线程有个资源空间(Resource Area),里面存放的就是ResourceObj,用于对JVM提供其他功能的支持。
- StackObj:栈对象。
- ValueObj:值对象。在堆对象需要嵌套时使用
- AllStatic:静态对象,全局对象,只有一个。JVM中的静态对象的初始化,都是显式调用静态初始化函数。
- MetaspaceObj:元对象。例如InstanceKlass
- CHeapObj:堆空间的对象,由new/delete/free/malloc管理。
线程
JVM线程结构类
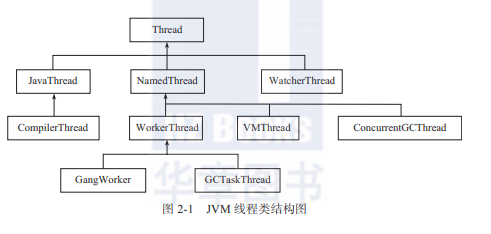
- JavaThread:执行java代码的线程
- java代码的启动会通过JNI_CreateJavaVM创建一个JavaThread运行
- java的一般线程通过调用 Thread 中的**start()**方法,start()方法再通过JNI调用创建JavaThread对象。
- CompilerThread:执行JIT的线程
- WatcherThread:执行周期性任务,例如JVM内存抽样等
- NameThread:JVM内部线程
- VMThread:JVM执行GC的同步线程,主要用于处理垃圾回收。
- 如果是多线程回收,则启动多个线程。
- 如果是单线程回收,则使用VMThread
- ConcurrentGCThread:并发执行GC任务的线程
- WorkerThread:工作线程,在G1中使用了FlexibleWorkGang,这个线程是并行执行的,可以认为是一个线程池
JVM线程状态

栈帧(frame)
-
栈帧是虚拟机栈的组成元素,
-
栈帧所包含的元素:
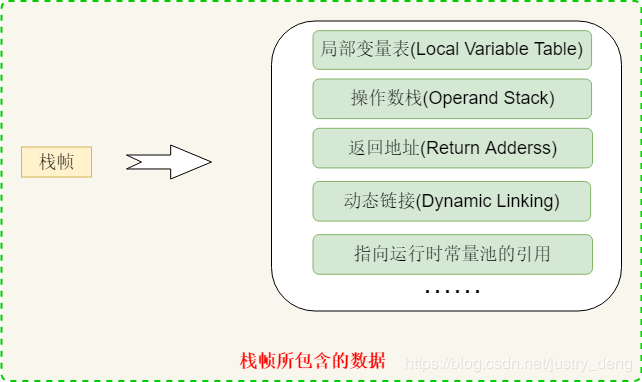
-
在GC第一步就是遍历根,栈帧就是根元素之一,通过StactFrameStream遍历根元素。
句柄(handle)
jvm通过线程的资源区(handleArea)来管理所有的句柄。如果函数还在调用,那么句柄有效,句柄关联的对象也是活跃对象。 句柄的作用主要是用于管理本地代码对堆上资源的调用。
如何管理句柄的生命周期
- JVM引入HandleMark,通常HandleMark分配在栈上,在创建HandleMark的时候标记HandleArea有效
- 在HandleMark析构的时候,从HandleArea中删除这个对象的引用。
- 所有的句柄都形成了一个链表,那么访问这个句柄链表就可以获得本地代码执行中对堆对象的引用。
G1参数介绍和注意事项
- G1HeapRegionSize:指定堆分区大小。分区大小可以指定,也可以不指定;不指定时,由内存管理器启发式推断分区大小。
- xms/xmx:指定堆空间的最小值/最大值。一定要正确设置xms/xmx,否则将使用默认配置,将影响分区大小推断。
- 在以前的内存管理器中(非G1),为了防止新生代因为内存不断地重新分配导致性能变低,通常设置Xmn或者NewRatio。但是G1中不要设置MaxNewSize、NewSize、Xmn和NewRatio。原因有两个,第一G1对内存的管理不是连续的,所以即使重新分配一个堆分区代价也不高,第二也是最重要的,G1的目标满足垃圾收集停顿,这需要G1根据停顿时间动态调整收集的分区,如果设置了固定的分区数,即G1不能调整新生代的大小,那么G1可能不能满足停顿时间的要求。具体情况本书后续还会继续讨论。
- GCTimeRatio指的是GC与应用程序之间的时间占比,默认值为9,表示GC与应用程序时间占比为10%。增大该值将减少GC占用的时间,带来的后果就是动态扩展内存更容易发生;在很多情况下10%已经很大,例如可以将该值设置为19,则表示GC时间不超过5%。
- 根据业务请求变化的情况,设置合适的扩展G1ExpandByPercentOfAvailable速率,保持效率。
- JVM在对新生代内存分配管理时,还有一个参数就是保留内存G1ReservePercent(默认值是10),即在初始化,或者内存扩展/收缩的时候会计算更新有多少个分区是保留的,在新生代分区初始化的时候,在空闲列表中保留一定比例的分区不使用,那么在对象晋升的时候就可以使用了,所以能有效地减小晋升失败的概率。这个值最大不超过50,即最多保留50%的空间,但是保留过多会导致新生代可用空间少,过少可能会增加新生代晋升失败,那将会导致更为复杂的串行回收。
- G1NewSizePercent是一个实验参数,需要使用 -XX:+UnlockExperimentalVMOptions 才能改变选项。有实验表明G1在回收Eden分区的时候,大概每GB需要100ms,所以可以根据停顿时间,相应地调整。这个值在内存比较大的时候需要减少,例如32G可以设置-XX:G1NewSizePercent = 3,这样Eden至少保留大约1GB的空间,从而保证收集效率。
- MaxGCPauseMillis指期望停顿时间,可根据系统配置和业务动态调整。因为G1在垃圾收集的时候一定会收集新生代,所以需要配合新生代大小的设置来确定,如果该值太小,连新生代都不能收集完成,则没有任何意义,每次除了新生代之外只能多收集一个额外老生代分区。
- 参数GCPauseIntervalMillisGC指GC间隔时间,默认值为0,GC启发式推断为MaxGCPauseMillis + 1,设置该值必须要大于MaxGCPauseMillis。
- 参数G1ConfidencePercent指GC预测置信度,该值越小说明基于过去历史数据的预测越准确,例如设置为0则表示收集的分区基本和过去的衰减均值相关,无波动,所以可以根据过去的衰减均值直接预测下一次预测的时间。反之该值越大,说明波动越大,越不准确,需要加上衰减方差来补偿。
- JVM中提供了一个对象对齐的值ObjectAlignmentInBytes,默认值为8,需要明白该值对内存使用的影响,这个影响不仅仅是在JVM对对象的分配上面,正如上面看到的它也会影响对象在分配时的标记情况。注意这个值最少要和操作系统支持的位数一致才能提高对象分配的效率。所以32位系统最少是4,64位最少是8。一般不用修改该值。
