HashMap、ConcurrentHashMap问题总结
一、为什么扩容是2的平方?
- 通过与元素的hash值进行与操作,能够快速定位到数组下标
相对于取模运算,直接进行与操作能提高计算效率。在CPU中,所有的加减乘除都是通过加法实现的,而与操作时CPU直接支持的。
- 扩容时简化计算数组下标的计算量
因为数组每次扩容都是原来的两倍,所以每一个元素在新数组中的位置要么是原来的index,要么index = index + oldCap,假设
二、HashMap的加载因子
- 加载因子:0.75
- 默认容量:16
- 扩容机制2的平方 容量*加载因子 > (size)
- map的自定义容量大小,系统内部会向上去2^n次方
- jdk1.7 链表插入顺序是链表头插入,扩容后的链表与之前是倒序,多线程时会出现链环。
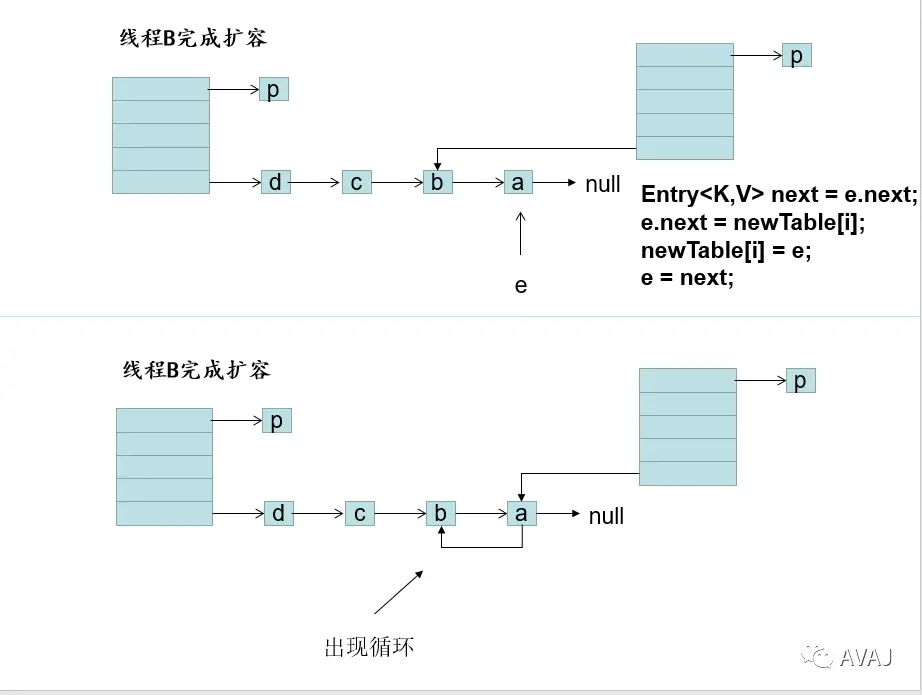
四、JDK1.7和1.8实现的区别
- 数据结构:1.7=数组+链表 1.8=数组+(链表/红黑树)
- 1.7是插入链表是表头插入(为什么这么设计:最近可能使用概率较大),多线程并发插入、读取会容易导致死循环(造成循环链)
- 1.8是链尾插入,先插入然后在扩容。
- 转红黑树的条件是,数组>=64,链表节点数>=8,当链表节点数<=6时(红黑树转列表),转红黑树是为了查询快,转回去为什么是6而不是7,是为了防止链表和红黑树频繁的切换。
五、ConcurrentHashMap实现原理
- jdk1.7版本
- initialCapacity:初始总容量,默认16
- loadFactor:加载因子,默认0.75
- concurrencyLevel:并发级别,默认16,如果需要修改通过new ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel)
- 扩容:指的Segement类内部的hash表扩容
- jdk1.8版本
- initialCapacity:初始总容量,默认16
- loadFactor:加载因子,默认0.75
- concurrencyLevel:没有,是根据Hash表的table里面的元素来作为锁的
- 扩容:ConcurrenHashMap在扩容过程中主要使用sizeCtl和transferIndex这两个属性来协调多线程之间的并发操作,并且在扩容过程中大部分数据依旧可以做到访问不阻塞。
- 桶上链表长度达到 8 个或者以上,并且数组长度为 64 以下时只会触发扩容而不会将链表转为红黑树。
- sizeCtl值表示的含义
- 控制标识符,用来控制table的初始化和扩容的操作,不同的值有不同的含义
- 当为负数时:-1代表正在初始化,-N代表有N-1个线程正在 进行扩容
- 当为0时:代表当时的table还没有被初始化
- 当为正数时:表示初始化或者下一次进行扩容的大小


