

扫描下方二维码或者微信搜索公众号
菜鸟飞呀飞,即可关注微信公众号,阅读更多Spring源码分析和Java并发编程文章。

前言
前两篇文章中分析了 netty 中解码器相关的源码,解码过程是发生在读数据这一步的,那么读到数据,经过解码器解码后,最终就会交由我们自定义的业务处理中执行,当我们的业务逻辑处理完成后,就需要给客户端响应消息,这就涉及到服务端如何通过 channel 将响应消息写出去的流程了,同时还会涉及到消息的编码过程,因为在 TCP 协议中,数据最终是通过字节流传输的,而我们通常在业务代码中是返回一个对象,因此需要进行编码。接下来本文将会重点分析这两个的过程的源码实现。
Demo 代码
为了方便描述,这里模拟一个简单的场景:netty 服务端在读到客户端发来的消息后,netty 服务端就通过我们自定义的 ChannelHandler 来进行业务处理,并返回一个 Data 对象,Data 类是我们自定义的一个类,然后我们将 Data 对象通过我们自定义的一个编码器 DataEncoder 进行编码,最后将消息发送出去。
netty 服务端启动的 demo 代码
public static void main(String[] args) throws InterruptedException {
NioEventLoopGroup bossGroup = new NioEventLoopGroup(1);
NioEventLoopGroup workerGroup = new NioEventLoopGroup(8);
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class)
.group(bossGroup,workerGroup)
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// 向客户端channel中添加两个channelHandler
pipeline.addLast(new DataEncoder());
pipeline.addLast(new BusinessHandler());
}
});
serverBootstrap.bind(8080).sync();
}
可以看到,分别向客户端的 channel 的 pipeline 中添加了两个 ChannelHandler:DataEncoder 是自定义的一个编码器,负责进行编码,BusinessHandler 是负责进行业务处理的。因此创建出来的客户端 channel 的 pipeline 的结构如下,这个结构很重要,后面的源码分析全是基于这个结构来分析的。
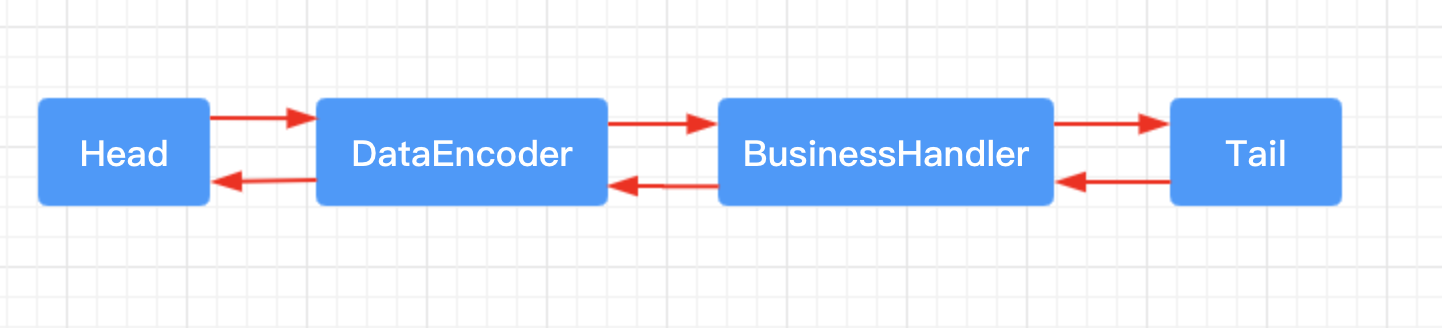
DataEncoder 编码器的源码
/**
* 实际上就是一个基于换行符的编码器
*/
public class DataEncoder extends MessageToByteEncoder<Data> {
private static final String LINE = "\r\n";
@Override
protected void encode(ChannelHandlerContext ctx, Data msg, ByteBuf out) throws Exception {
if(msg instanceof Data){
out.writeBytes(msg.getMsg().getBytes());
out.writeLong(msg.getServerTime());
out.writeBytes(LINE.getBytes());
}
}
}
为了简化分析,BusinessHandler 的代码比较简单,它就是直接向客户端返回一个 Data 对象
public class BusinessHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 读到客户端发来的消息后,服务端直接返回一个data对象
Data data = new Data("Hello World",System.currentTimeMillis());
ctx.channel().writeAndFlush(data);
}
}
Data 类就是一个简单的 Bean,包含两个属性:msg,serverTime
public class Data {
private String msg;
private Long serverTime;
public Data(String msg, Long serverTime) {
this.msg = msg;
this.serverTime = serverTime;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
public Long getServerTime() {
return serverTime;
}
public void setServerTime(Long serverTime) {
this.serverTime = serverTime;
}
}
源码分析
当服务端读到客户端发送过来的消息后,就会通过客户端 channel(即:NioSocketCahnnel)的 pipeline 进行传播执行 channelRead() 方法,也就是会执行到我们自定义的 BusinessHaandler 中的 channelRead()方法。此时我们直接创建了一个 Data 对象,然后通过客户端 channel 的 writeAndFlush() 方法,将 Data 对象写出去,发送给客户端。所以接下来详细分析下 writeAndFlush()方法的工作原理。
ctx.channel()获取到的是客户端 channel,调用客户端 channel 的 writeAndFlush()时,最终会执行客户端 channel 的 pipeline 的 writeAndFlush()方法。
public ChannelFuture writeAndFlush(Object msg) {
return pipeline.writeAndFlush(msg);
}
看到调用 pipeline 的方法,首先想到的是这个方法的调用,会沿着 pipeline 这个管道执行所有 channelHandler 的方法。进入到 pipeline 的 writeAndFlush(msg)方法的源码中,果然,它是从 tail 节点开始向前传播执行。
@Override
public final ChannelFuture writeAndFlush(Object msg) {
// 从尾结点开始向前传播
return tail.writeAndFlush(msg);
}
最终会调用 tail 节点的 write() 方法。在调用 write()方法时,传入的第二个参数 flush 为 true,表示的是需要执行 flush()方法(注意:此时传入的是 true,记住这一点很重要,因为后面还会有一个地方也会调用 write()方法,但是传入的是 false)。
private void write(Object msg, boolean flush, ChannelPromise promise) {
// 省略部分代码...
// 找到下一个Outbound类型的handler
final AbstractChannelHandlerContext next = findContextOutbound(flush ?
(MASK_WRITE | MASK_FLUSH) : MASK_WRITE);
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
// 同步执行
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
// 异步执行,实际上就是将当前的写操作封装成一个task,然后提交到线程池
final AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
if (!safeExecute(executor, task, promise, m)) {
task.cancel();
}
}
}
write()方法的逻辑可以分为三步,第一步:找到 pipeline 中下一个 OutBound 类型的 channelHandler,对于我们 demo 中的示例,就是 DataEncoder。
第二步:根据当前的线程是否是 NioEventLoop 线程来判断是同步执行还是异步执行 writeAndFlush,由于当前线程是 NioEventLoop,所以最终是同步执行。
第三步:根据传入的 flush 标识来判断是否需要执行 flush 方法,如果传入的是 true,表示需要执行 flush,前面已经提到了,此时传入的 flush 为 true,因此最后会调用 next.invokeWriteAndFlush(m, promise) 这一行代码。
在 invokeWriteAndFlush()中会先调用 invokeWrite0(),也就是触发执行 write()方法,然后调用 invokeFlush0(),也就是触发执行 flush()方法。今天先分析 write()方法相关的源码,flush 相关的源码下一篇文章分析。
invokeWrite0()会触发执行 channelHandler 的 write()方法,此时传播到的 handler 是我们自定义的 DataEncoder(因为 tail 节点的前一个 OutBound 类型的节点就是 DataEncoder,注意:BusinessHandler 是 InBound 类型),由于 DataEncoder 没有重写 write()方法,所以调用的是父类 MessageToByteEncoder 的 write()方法。在 write()方法中,会调用到子类的 encode()方法,对数据进行编码。其源码如下。
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
// 判断要写出的数据对象msg,是否需要当前的MessageToByteEncoder来处理
// 如何判断呢?就根据类中传入的泛型类型和msg的实际类型相比较
// 如果类型匹配成功,那就使用MessageToByteEncoder来处理,即会进行编码:encode()
// 如果匹配不成功,则直接使用write()方法
if (acceptOutboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
// 创建一个ByteBuf
buf = allocateBuffer(ctx, cast, preferDirect);
try {
// 调用编码器的编码方法(在编码后,会将编码出来的字节数据存放到buf)
encode(ctx, cast, buf);
} finally {
// 将cast对象的资源释放,因为前面一步已经将对象进行编码了,后面不再需要用到该对象了
ReferenceCountUtil.release(cast);
}
// 如果编码成功,buf中就会有数据,如果有数据,那么就就可以调用write()方法了
// 会调用父类AbstractChannelHandlerContext的write()方法
if (buf.isReadable()) {
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable e) {
throw new EncoderException(e);
} finally {
// 出现异常后,释放资源
if (buf != null) {
buf.release();
}
}
}
write()方法的源码比较长,执行流程可以用如下流程图表示。
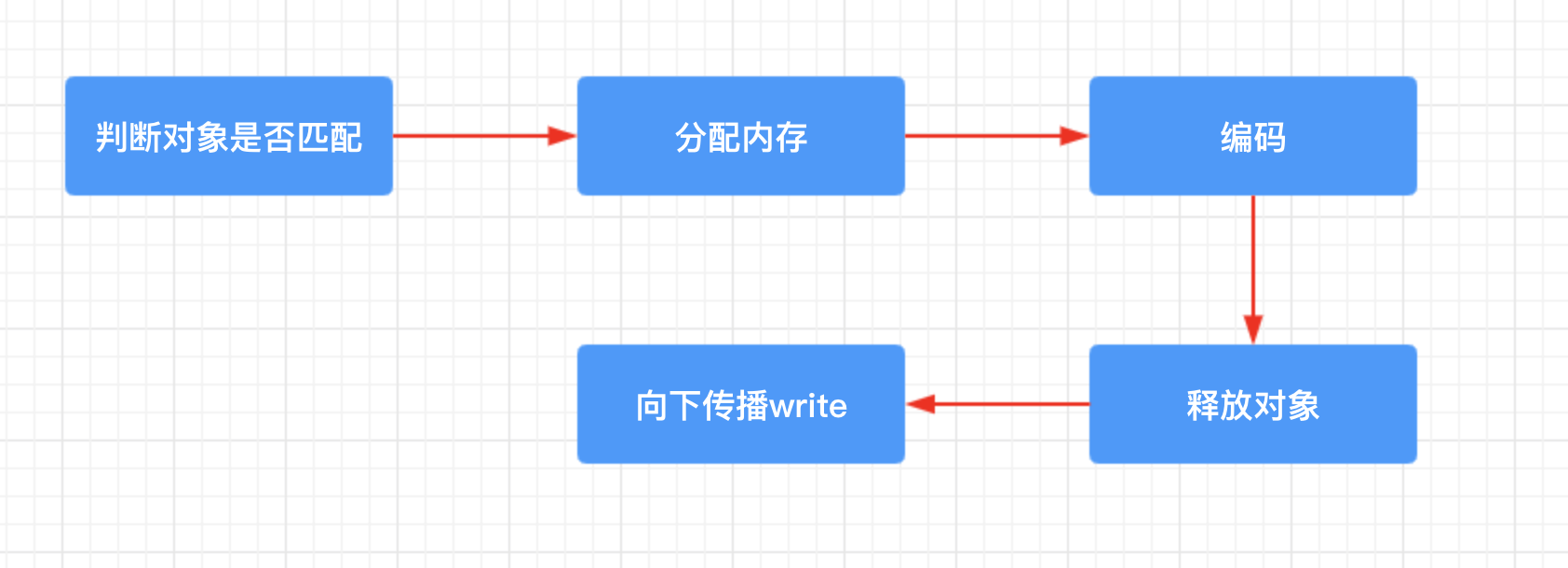
首先会根据 acceptOutboundMessage(msg) 方法判断要写出的数据对象 msg,是否需要当前的 MessageToByteEncoder 来处理。如何判断呢?就根据类中传入的泛型类型和 msg 的实际类型相比较,如果类型匹配成功,那就使用 MessageToByteEncoder 来处理,即会进行编码:encode()。例如本文的示例代码中,DataEncoder 这个编码器中,传入的泛型是 Data 类型,这也就意味着 DataEncoder 这个编码器只会对类型是 Data 的数据进行编码。在 BusinessHandler 中我们发送的数据就是 Data 类型,因此此时 DataEncoder 编码器会对 Data 对象进行编码。如果类型匹配不成功,那么就会直接调用 ctx.write(msg, promise)方法,向下一个 handler 传播执行 write()方法。
当类型匹配成功以后,会先将 msg 的类型强转为指定的泛型类型,在 demo 中就是 Data 类型。然后 allocateBuffer()方法申请一块内存,由于 preferDirect 属性默认是 true,因此会创建一块堆外内存。接着调用 encode()方法进行编码,由于我们定义的 DataEncoder 重写了 encode()方法,所以这里会调用 DataEncoder 的 encode()方法。
protected void encode(ChannelHandlerContext ctx, Data msg, ByteBuf out) throws Exception {
if(msg instanceof Data){
out.writeBytes(msg.getMsg().getBytes());
out.writeLong(msg.getServerTime());
out.writeBytes(LINE.getBytes());
}
}
encode 中传入的第一个参数就是当前持有 DataEncoder 的 context,第二个参数 msg 就是我们在 BusinessHandler 中创建的 Data 对象,第三个参数 out 就是通过 allocateBuffer()创建出来的一块堆外内存。
encode()方法执行完成以后,再次回到父类的 write()中,由于已经对 msg 对象编码完成了,所以后面该对象没有任何用处了,可以直接释放该对象。
如果编码成功,buf 中就会有数据,如果有数据,buf.isReadable()会返回 true,那么就接着调用 write()方法了,最终会调用父类 AbstractChannelHandlerContext 的 write()方法。如果没有数据被编码,那么就将之前申请的 ByteBuf 内存释放,然后依旧是调用父类 AbstractChannelHandlerContext 的 write()方法,只不过传入的 msg 对象是一个空的 ByteBuf。
最终又会调用到 AbstractChannelHandlerContext 类中的 write(msg,flush,promise)方法(在前面分析 tail 节点的时候已经贴出了该方法的源码),与之前不同的是,此时传入的第二个参数 flush 为 false,表示不调用 flush。同样先通过 pipeline 找到下一个 Outbound 节点,对于本文 demo 中,下一个节点就是 Head 节点,由于 flush 传入的是 false,因此会调用 next.invokeWrite(m, promise),也就是最终会调用 head 节点的 write()方法。head 节点的 write()方法源码如下。
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
// 对于客户端Channel而言,unsafe对象是NioSocketChannelUnsafe类型的实例
unsafe.write(msg, promise);
}
可以看到,在 head 节点中最终是通过 unsafe 对象来写数据的,此时由于 channel 是 NioSocketChannel,所以 unsafe 是 NioSocketChannelUnsafe 对象实例。最终调用的是 AbstractChannel 类的 write()方法。源码如下。
public final void write(Object msg, ChannelPromise promise) {
assertEventLoop();
// 非空判断
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
safeSetFailure(promise, newClosedChannelException(initialCloseCause));
ReferenceCountUtil.release(msg);
return;
}
int size;
try {
// 将msg转化成DirectByteBuf
msg = filterOutboundMessage(msg);
size = pipeline.estimatorHandle().size(msg);
if (size < 0) {
size = 0;
}
} catch (Throwable t) {
// 异常处理
safeSetFailure(promise, t);
ReferenceCountUtil.release(msg);
return;
}
// 将待写的数据添加到待写队列中,待写队列是一个entry组成的链表
outboundBuffer.addMessage(msg, size, promise);
}
这该方法中有两个比较重要的逻辑,第一处逻辑:如果 msg 不是堆外内存,会先将 msg 转换为 DirectByteBuf 类型(也就是堆外内存);第二处逻辑:也就是该方法的最后一行,这一行代码的作用是啥呢?将待写的数据添加到待写队列中,待写队列是一个 entry 组成的链表,被存放在 ChannelOutboundBuffer 这个缓冲区中。下面详细分析一下这一行代码的实现原理。
netty 在发送数据时,是先 write(),然后再 flush(),这样才会把数据发送到操作系统的套接字中。如果仅仅是调用 write()方法,数据是不会被发送出去的,而是先存放在 ChannelOutboundBuffer 缓冲区,该缓冲区里面维护了一个队列,每调用一次 write()方法,就向队列中添加一个 entry。对于同一个 NioSocketChannel 而言,可能存在一边调用 write(),一边调用 flush()方法,因此就需要区分出这个缓冲队列中,哪些数据是刚刚 write 进来的,哪些数据是已经被 flush 过了,怎么区分呢?netty 为这个缓冲区提供了两个指针:flushedEntry 和 unflushedEntry,分别指向的是第一个已经被 flush 的数据和第一个没有被 flush 的数据(注意:这里强调一下一个词:第一个,因为可能连续有还几条数据等待被 flush 或者已经被 flush,所以指针指向的是第一个),另外由于是队列,我们需要维护一个指向队列头部的指针或者尾部的指针,因此还提供了一个 tailEntry 指针用来指向队列的尾部。
初始状态下,这三个指针均指向 null,因为还没有数据没写入缓冲队列。当调用 write()方法和 flush()方法后,三个指针的指向变化关系如下图所示。
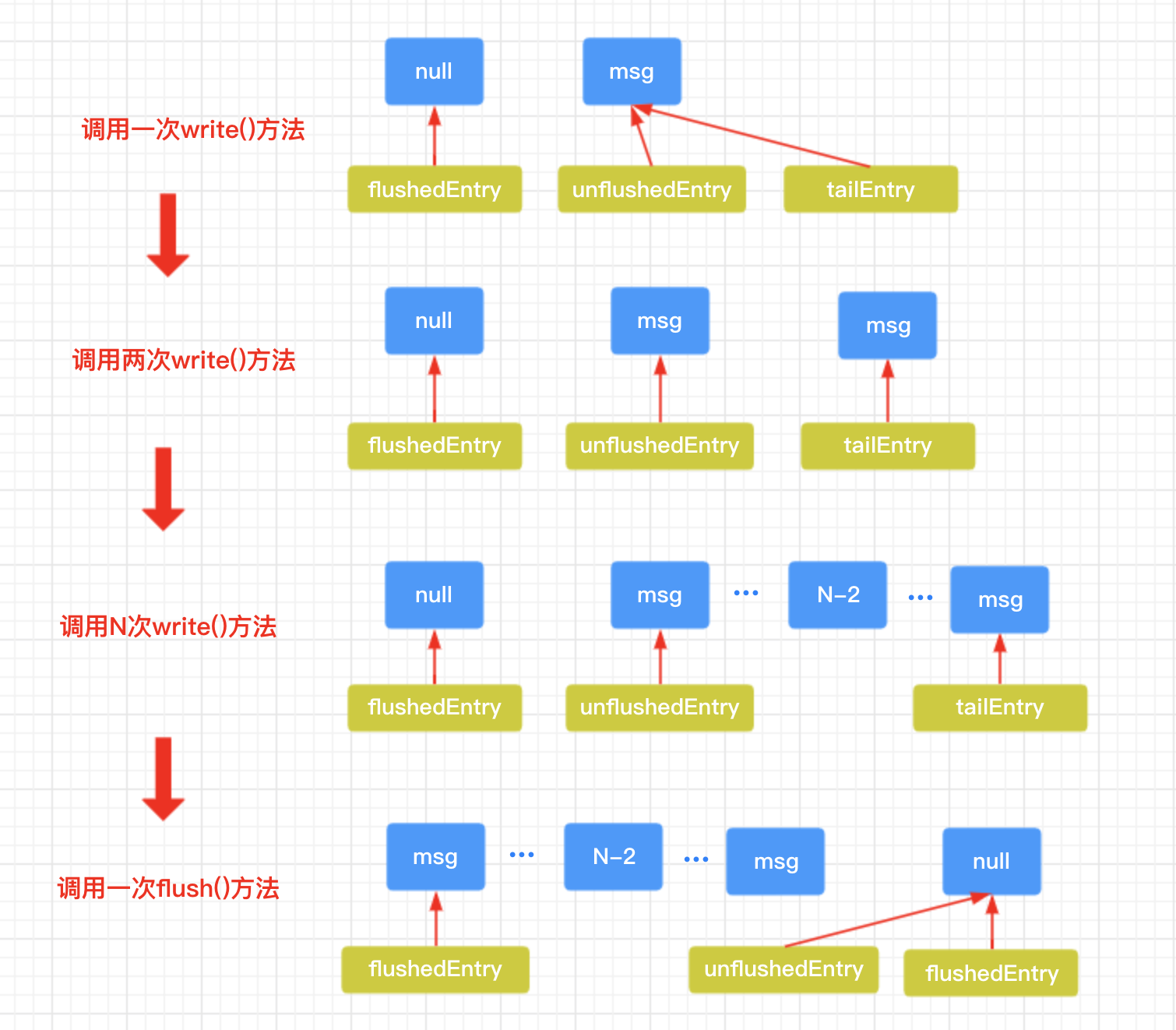
调用 write()方法时,最终会调用 outboundBuffer.addMessage()方法来移动这三个指针,下面看下该方法的源码。
public void addMessage(Object msg, int size, ChannelPromise promise) {
// 将要写的数据封装成一个Entry
Entry entry = Entry.newInstance(msg, size, total(msg), promise);
// 移动相关的指针
if (tailEntry == null) {
flushedEntry = null;
} else {
Entry tail = tailEntry;
tail.next = entry;
}
tailEntry = entry;
if (unflushedEntry == null) {
unflushedEntry = entry;
}
// 累计要写的字节数
incrementPendingOutboundBytes(entry.pendingSize, false);
}
addMessage()方法的逻辑大致可以分为两部分,第一部分:将传入的数据封装成一个 Entry,然后移动三个指针,至于如何移动的,可以参考上面的示意图,那样会更清晰。第二部分:累计写数据的字节数,因为操作系统的套接字缓冲区会有限制,我们不能不停地向缓冲区中写入数据,因此 netty 在写数据时,会累加当前要发送数据的字节数,如果超过了限制,就会将当前 channel 设置为不可写状态,直到要写的数据量低于某个值后,channel 的状态又会被设置成可写状态。incrementPendingOutboundBytes()方法的源码如下。
private void incrementPendingOutboundBytes(long size, boolean invokeLater) {
if (size == 0) {
return;
}
// 累加字节数
long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);
// 如果待写的数量超过了设置的最高水位线,那么就会将channel设置为不可写状态
if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) {
setUnwritable(invokeLater);
}
}
从代码中可以看到,如果累计的字节数超过了缓冲区配置的高水位线,那么就会将 channel 设置为不可写状态。和高水位线相对应的是低水位线,当要写的字节数低于低水位线时,channel 会被重新设置成可写状态。什么时候会判断低水位线呢?那就是在调用 flush()方法时,flush()方法会在下一篇文章中详细分析。
在 netty 中,默认的高水位线的值是 64KB,低水位线是 32KB。也就是说,当累计要发送的数据大于 64KB 时,channel 会被暂时设置为不可写状态,直到 channel 缓冲区中的数据低于 32KB 时,会重新变为可写状态。
private static final int DEFAULT_LOW_WATER_MARK = 32 * 1024;
private static final int DEFAULT_HIGH_WATER_MARK = 64 * 1024;
总结
至此,关于写数据时的 write()方法的源码就分析完了。
最后总结一下,当调用 channel 的 writeAndFlush()方法发送数据时,会从 pipleline 的 tail 节点开始向前传播执行 writeAndFlush()方法。先从 tail 节点向前依次调用 OutBound 类型 handler 的 write()方法,对于编码器而言,在 write()方法中会调用 encode()方法,将数据进行编码,最终 write()方法会被传播执行到 head 节点中,在 head 节点中,会将要写的数据存储到缓冲区,这个缓冲区是由一个队列组成的,由 3 个指针来维护关联关系,每当调用 write()方法或者 flush()方法时,会移动这 3 个指针。最后当等待发送的数据超过 64KB 时,channel 会暂时变为不可写状态,直到堆积的数据量低于 32KB 时,才会重新变为可写状态。
关于 flush()方法的源码会在下一篇文章中详细分析。
推荐
- 如何从BIO演进到NIO,再到Netty
- Netty源码分析系列之Reactor线程模型
- Netty源码分析系列之服务端Channel初始化
- Netty源码分析系列之服务端Channel注册
- Netty源码分析系列之服务端Channel的端口绑定
- Netty源码分析系列之NioEventLoop的创建与启动
- Netty源码分析系列之NioEventLoop的执行流程
- Netty源码分析系列之新连接的接入
- Netty源码分析系列之TCP粘包、半包问题以及Netty是如何解决的
- Netty源码分析系列之常用解码器(上)
- Netty源码分析系列之常用解码器(下)——LengthFieldBasedFrameDecoder
