


文/缺月
随着深度学习的发展,智能化已经开始赋能各行各业,前端作为互联网中离用户最近的一环,也希望借助 AI 的能力大幅提高效率,减少人力成本,给用户创建更好的体验。因此,前端智能化也被看作是前端的未来的重要发展方向。
然而,在这条道路上,有几个问题一直阻碍着智能化的发展:
- 熟悉机器学习的算法工程师对前端的业务没有体感,对前端所积累的数据和这些数据可能产生的价值也并不了解,很难参与到这个过程中来。
- 传统的前端工程师对机器学习常用的语言,诸如 python, c++ 等并不了解,学习和转换的成本很高。
- 传统的前端工程师对深度学习本身的算法和原理不了解,导致很难直接使用一些现有的机器学习框架 (tensorflow, pytorch 等)来进行训练。
为了解决这些问题,推动前端智能化发展,我们开发了 pipcook。 pipcook 使用对前端友好的 JS 环境,基于 Tensorflow.js 框架作为底层算法能力并且针对前端业务场景包装了相应算法,从而让前端工程师可以快速简单的运用起机器学习的能力。
此篇文章将主要讨论 pipcook 是如何和 Tensorflow.js 结合的,重点探讨一下如何利用 tfjs-node 的底层模型和计算能力搭建一个高阶机器学习流水线,关于 pipcook,您可以参考这篇文章。
为什么采用 Tensorflow.js 作为底层算法框架
Tensorflow.js 是 google 在 2018 年发布的基于 js 的机器学习框架,google 也开源了相关代码。pipcook 在数据处理和模型训练中使用 tfjs-node 作为底层依赖的框架,在 Tensorflow.js 之上开发 pipcook 插件并组装成流水线。我们使用 Tensorflow.js 主要有以下几个原因:
- pipcook 定位于服务前端工程师,所以主要采用 JS 语言开发,所以我们更倾向于采用 JS 的运算框架,避免桥接其他语言等方式带来的性能损失和出错风险
- 相对于一些其他的 JS 的机器学习框架,Tensorflow 本身在 C++ 和 Python 上非常流行,js 版本也复用了 C++ 的底层能力和很多算子, 支持大量的网络层,激活函数,优化器和其他组件,并且具有良好的性能并提供 GPU 支持。
- 官方提供了 tfjs-converter 等工具,可以将 SavedModel 或者 Keras 等模型转化为 JS 模型,从而可以复用很多 Python 成熟的模型
- JS 在对数学运算这一方面的生态并不成熟,没有一个如同 numpy 这样的科学计算库,一些类似的库也很难和其他的运算框架无缝结合。而 tfjs 本身提供了 tensor 的封装,相当于 numpy arary 的能力,并且可以直接传入到 tfjs 模型中进行训练,同时性能非常高效
- tfjs 提供了 Dataset API, 可以对数据进行抽象,为数据封装了简单高效的接口,同时可以进行批数据处理。Dataset API 的数据流的方式也可以和 pipcook 管道的方式高效结合。
使用 Tensorflow.js 处理数据
对于机器学习,访问和处理大量数据是一个关键问题。对于一些传统数据量不大的场景,我们可以把数据一次性读入内存进行操作,但是对于深度学习来说,很多时候数据远远超出了内存大小,因此,我们需要按需从数据源逐段访问数据的能力。而 tfjs 提供的 Dataset API 对这种场景的处理进行了包装。
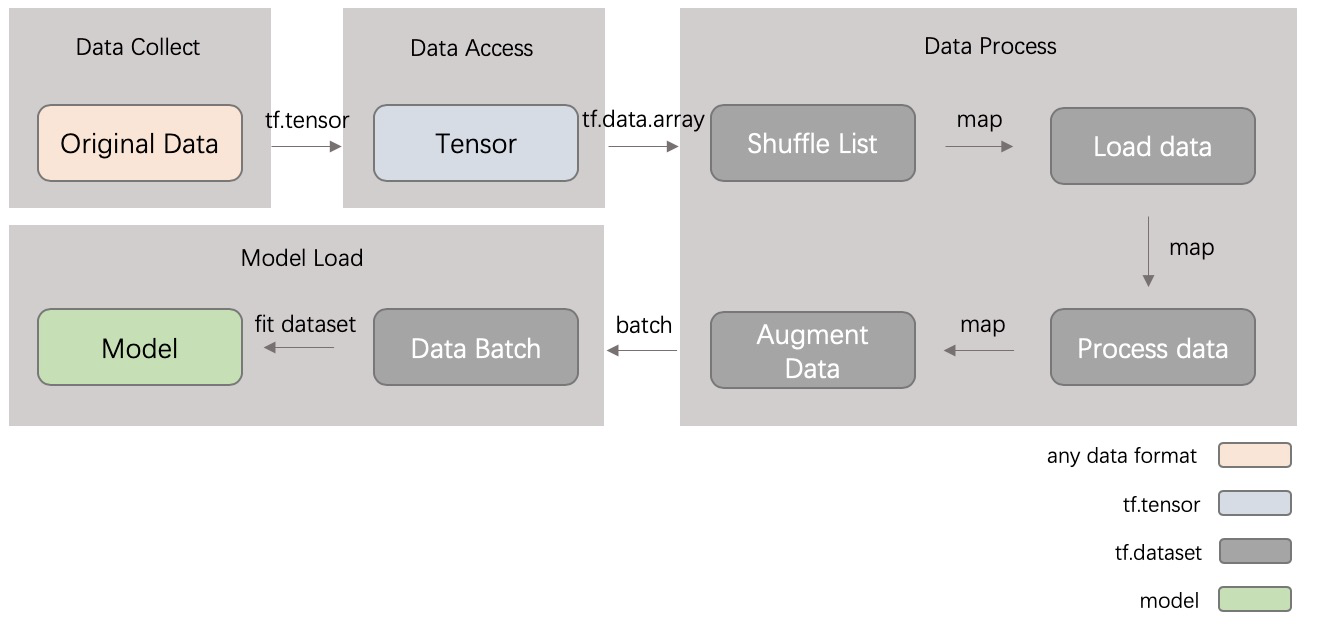
在一个标准的 pipcook pipeline 中,我们会使用 Dataset API 对数据进行包装和处理。如图所示是一个典型的数据流通的过程。
- 一开始,原始的训练数据会通过 data collect 插件进入到管道中,这种原始数据可能是一些本地文件或者存储在云上的数据,插件会把这些数据读进管道
- data collect 插件在读入这些数据之后,会对数据的格式进行判断,并且封装成相应的 tensor
- data access 插件负责对这些数据进行接入,将 tensor 包装成 tf.Dataset,方便后面进行批量数据处理和训练
- 在 data process 插件中,我们将会对数据做具体的某种处理,包括 shuffle, augment 等操作,这些操作会用到 Dataset 封装的一些诸如 map 等操作符,从而在数据流中实时的进行批量处理
- 随后,在 model load 中,数据会以 batch 的形式读入模型进行训练
至此,我们可以将数据集想象为一组训练数据的可迭代集合,如同 Node.js 中的 Stream。每当从数据集中请求下一个元素时,内部实现都会根据需要进行访问,并且执行预先设置好的数据处理操作函数。这种抽象使得模型可以轻松训练大量的数据。当我们有多个数据集时,Dataset 还便于将数据集共享和组织为同一组抽象。
训练模型
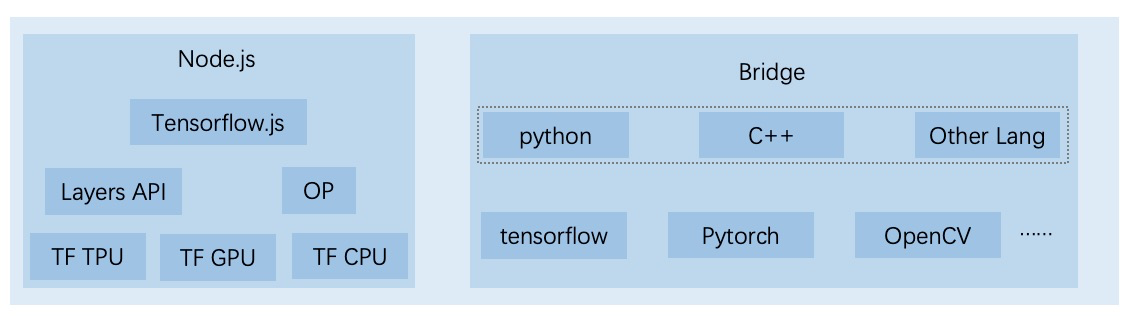
TensorFlow.js 分成低阶与高阶两组 API。低阶的 API 是由 deeplearn.js 衍生,包含搭建模型所需要的 operator (OP), 负责处理一些低阶如线性代数的数据运算等等,来协助我们处理机器学习中的数学运算部分。而高阶的 Layers API 则是用来包装一些常用的机器学习的算法,同时允许我们载入训练好的模型,像是由 Keras 学习的模型等等。
pipcook 通过插件的方式开发和运行模型,每个 model load 插件会负责加载某一具体的模型,大部分模型基于 tfjs 实现。同时 tfjs-node 还提供了 gpu 加速等功能,可以提高模型训练的速度。当然,现阶段由于生态等原因,对于一些特定的模型在 tfjs 里面实现的成本比较高,对于这一部分问题,pipcook 同时还提供了 python 桥接等方式,可以直接在 js 的运行环境里调用 python 进行训练,对于这一部分桥接的细节,我们将会在后续的篇章里详细介绍。
部署
对于一条工业级的机器学习流水线,在训练模型完成之后,还需要有一种方式部署您的模型,从而让模型可以为真实的业务服务,目前 pipcook 部署的方案主要有以下几种,这些方案都是通过 model deploy 插件完成的
- 快速验证方案:很多时候您可能想要对您的数据和模型进行快速的实验,例如使用小批量的数据和数量较少的 epoch,对于这种场景,我们不需要将模型部署到远程再进行验证。对此,pipcook 内置了本地部署的插件,在机器上训练完成之后,pipcook 将会在本地启动一个预测服务器,进行预测服务
- 服务器 docker 镜像:pipcook 提供了官方镜像,此官方镜像包含了 pipcook 训练和预测的必要环境, 您可以直接将此镜像部署到您的部署主机上,也可以使用 k8s 等集群解决方案管理 docker 镜像
- 云服务打通:pipcook 将会在后续开发中逐渐打通各云服务厂商的机器学习部署服务,现阶段实际上 Gcloud 已经提供了 tfjs 和 automl 的结合,后续 pipcook 将会逐渐支持阿里云, AWS 等服务
和 TFX (Tensorflow Extended) 的对比
我们最终的目标是一个成熟的工业级的机器学习 pipeline,这个 pipeline 可以将出色的模型运用于生产环境,实际上为了解决这种需求,google 官方基于长期的实践发布了 TFX,并且开源了此项目。那么外界可能会有一些疑问,我们所做的事情和 TFX 的区别是什么,实际上,pipcook 的核心并不是取代任何其他的框架,尤其是基于 python 生态的产品,因为 pipcook 的使命是推动前端的智能化发展,因此,pipcook 所采用的技术栈以及产品化方式都是面向前端的,像是
- TFX 采用的是 DAG 的方式,因为其涉及到数据生成,对数据进行统计分析,对数据进行验证,转化数据等多种操作,而这些操作可以自由组合,实际上,对于很多前端域的场景,我们并不需要很多复杂的组合操作,因此,pipcook 采用了 pipeline 的方式,对于数据的操作抽象为简单的管道中的插件,可以减少前端工程师的使用成本
- TFX 采用 Apache Airfow 等进行调度,而 pipcook 采用的是前端技术栈进行这类操作,例如,我们使用 Rxjs 等响应式框架对不同的 plugin 进行响应和串联,方便前端理解和贡献代码
- 同时,我们设计的 API 也是基于 JS 习惯的,对前端来说学习和上手的成本较低
基于以上这些设计,我们尽量尝试去构建一个对前端友好的机器学习环境,从而达到我们的预期和目标
未来展望
pipcook 自开源以来已经有一个月的时间,期间,也收到了一些用户的反馈,同时,根据我们的规划,我们还有很多需要做的事情,我们也期望可以借助开源社区的力量,不断完善 pipcook,使其可以真正助力前端智能化。
- 与各云服务厂商 (阿里云,AWS, Gcloud 等)合作,打通 pipcook 到各个云服务机器学习部署链路
- 生态完善,建立起 pipcook 的试玩广场等从而降低用户的上手成本
- 更好的支持分布式训练
- 插件丰富,模型完善,支持更多的 pipeline
未来我们希望通过阿里内部前端智能化小组和整个开源社区的力量结合在一起,不断完善 pipcook 和 pipcook 背后所代表的前端智能化战役,让前端智能化技术方案普惠化,沉淀更具竞争力的样本和模型,提供准确度更高、可用度更高的代码智能生成服务;切实提高前端研发效率,减少简单的重复性工作,不加班少加班,一起专注更有挑战性的工作内容!
如何贡献?
如果您对我们的项目有兴趣并且想要为前端智能化贡献一份力量,欢迎您前往我们的 github 开源仓库
