


因为计算机只能处理数字,所以如果要处理文本,就得先把文本转换成数字才能处理。
ASCII
最早计算机在设计时采用8bit作为一个字节(byte),所以一个字节能标识的最大整数就是255「11111111(B) = 255」,0-255被用来标识大小写英文字母、数字和一些符号,这个编码表就被称为ASCII编码。
Unicode
如果要用来表示中文(汉字数量大约近10w个),显然一个字节是不够的,至少需要两个字节。而且还不能和ASCII编码表冲突,所以中国指定了GB2312编码,用来编码中文。 类似的,其他语言也面临这个问题,为了统一所有文字的编码,Unicode应运而生。
Unicode通常使用两个字节来表示一个字符,所有的英文编码从单字节变成了双字节,把高字节全部填0补齐。
目前Unicode字符分为17组编排,0x0000至0x10FFFF,每组称为平面(Plane),而没平面拥有65535个码位,共1114112个,然而目前只用了少数平面。
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode可变长度字符编码。
UTF-8 与 Unicode区别
- Unicode 是 「字符集」
- UTF-8 是 「编码规则」
字符集:为每一个字符分配一个唯一的ID(码位/码点/Code Point) 编码规则:将码位转换为字节序列的规则(编码/解码 => 加密/解密)
UTF-8编码规则
UTF-8是一种变长字节编码方式。最小编码单位(code unit)为一个字节。一个字节的前1-3个bit为描述性部分,后面为实际序号部分。
- 对于单字节字符,占用一个字节空间。0之后的所有部分(7个bit)代表Unicode中的序号。因此对于英文字母,UTF-8编码和ASCII码是相同的。
- 对于n字节字符,第一个字节的前n为都为1,第n+1为0,后面字节的前两位上为10.剩下没有提及的二进制位为这个符号的unicode码。
| Unicode符号范围「十六进制」 | UTF-8编码「二进制」 |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx |
综上:如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前占用多少个字节。
举例:
秃的unicode为79C3「0111 1001 1100 0011(B)」,根据上表处于 (0000 0080-0000 FFFF)范围内,因此UTF-8需要三个字节,即格式为1110xxxx 10xxxxxx 10xxxxxx,将unicode从最后一位往前依次填入格式x中,多出的补0。可以得出UTF-8编码为11100111 10100111 10000011,转为十六进制为E7A783。
Little endian & Big endian
以上面秃为例,unicode码为79C3,需要两个字节存储,一个字节是79,另一个字节是C3。存储的方式79在前,C3在后,就是Big endian(大头方式);C3在前,79在后就是Little endian(小透方式)
Base64
Base64是一种基于64个可打印的字符来标识二进制数据的标识方法。可打印的字符包括字母A-Z、a-z、数字0-9,这样公有62个字符,此外两个可打印的符号在不同系统中而不同。
在MIME格式的的电子邮件中,另外两个符号为加号+和斜杠/,等号=用来做后缀用途。
编码转换方式
- 将每三个字节作为一组,一共24个二进制位。
- 将这24个二进制位分为4组,每个组有6个二进制位。
- 在每组前面加两个00,扩展成32个二进制位,及四个字节。
- 然后根据下表得到扩展后的每个字节的编号,这就是Base64的编码值。
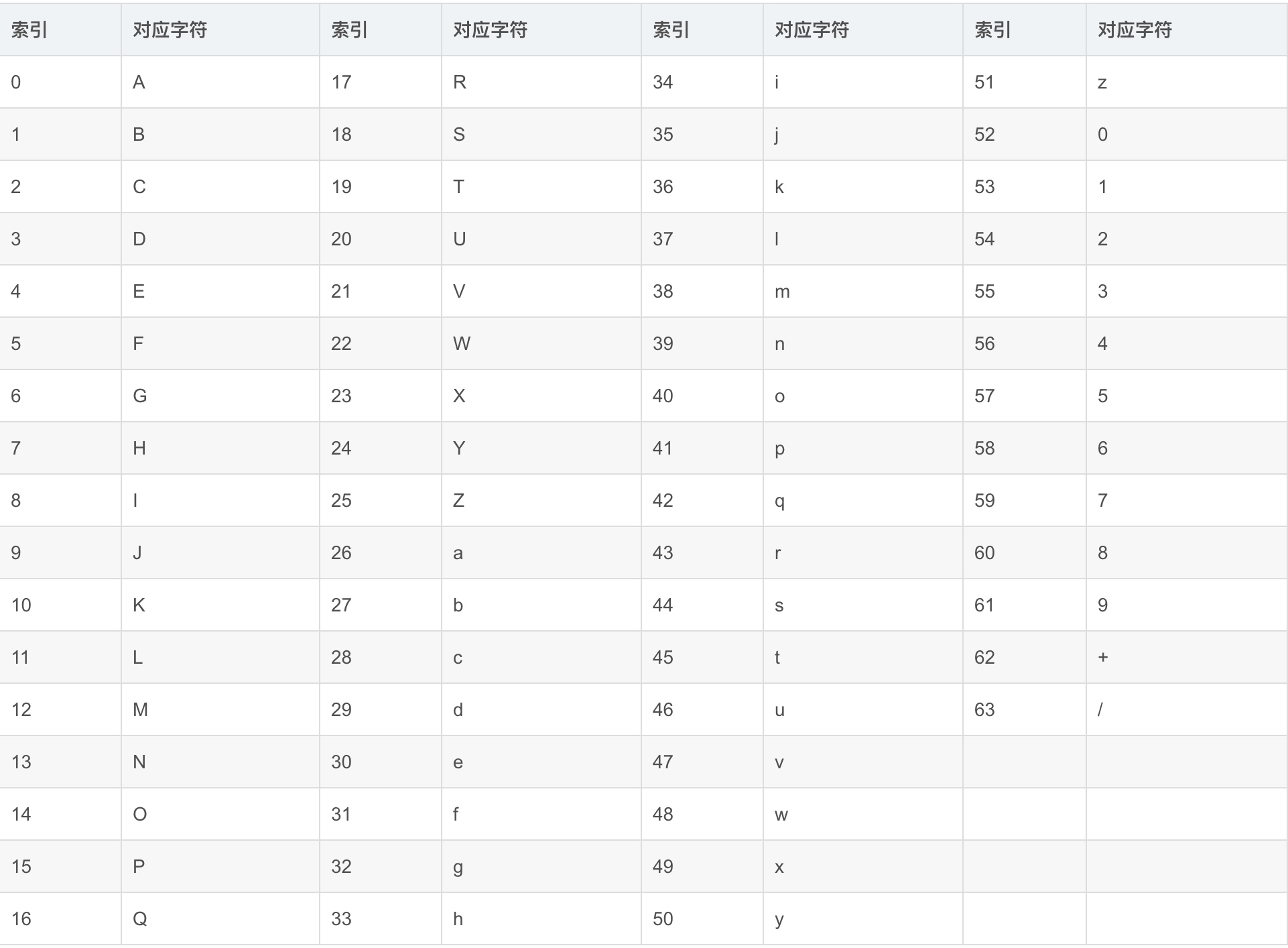
综上得出:
- Base64字符标中的字符原本用6bit就可以表示,现在前面添加2个0,变为8bit,导致Base64编码后的文本大小比原文大约三分之一
- 为什么使用3个字节一组呢?因为6和8的最小公倍数是24,三个字节正好24个二进制位,每6bit一组,恰好能够分为4组。
举例如下:

- "Man"、"a"、"n"的ASCII值分别为77、97、110,对应的二进制值为01001101、01100001、01101110,将他们连成24位的二进制字符串010011010110000101101110。
- 将24位的二进制字符串分为四组,即:010011、010110、000101、101110。
- 在每组前面加00,扩展成32个二进制位,即00010011、00010110、00000101、00101110。
- 根据上表,得到Base64编码为T、W、F、u。
位数不足3位处理
- 二位的情况:两个字节工共16个二进制位,按照上面方式分组,每6个一组,则第三组缺少2位,用0补齐。如"Ma"可以转换为三组00010011、00010110、00010000,对应的Base64值分别为T、W、E,再补上一个"="号,因此"Ma"的Base64编码为"TWE="
- 一位的情况:一字节工8个二进制位,按照上面方式分组,每6个一组,则第二组缺少4位,用0补齐。如"M"可以转换为00010011、00010000,对应的Base64位的值分别为:T、Q,再补上两个"="号,因此"M"的Base64编码就是TQ==
注意事项
- 大多数编码都是由字符串转换为二进制的过程,而Base64的编码则是从二进制转为字符串。
- Base64主要用在传输,存储,表示二进制领域,不能算得上加密,只是无法直接看到铭文。
- 中文有很多编码(比如:UTF-8、GB2312、GBK等),不同的编码对应的Base64编码结果不一样。
