

本文作者欧长坤,德国慕尼黑大学在读博士,Go/etcd/Tensorflow contributor,开源书籍《Go 语言原本》作者,《Go 夜读》SIG 成员/讲师,对 Go 有很深的研究。Github:@changkun,https://changkun.de。
本文首发于 Github 开源项目 《Go-Questions》,点击阅读原文直达。全文不计代码,共 1.7w+ 字,建议收藏后精读。另外,本文结尾有 彩蛋。
按惯例,贴上本文的目录:

本文写于 Go 1.14 beta1,当文中提及目前、目前版本等字眼时均指 Go 1.14,此外,文中所有 go 命令版本均为 Go 1.14。
GC 的认识
1. 什么是 GC,有什么作用?
GC,全称 GarbageCollection,即垃圾回收,是一种自动内存管理的机制。
当程序向操作系统申请的内存不再需要时,垃圾回收主动将其回收并供其他代码进行内存申请时候复用,或者将其归还给操作系统,这种针对内存级别资源的自动回收过程,即为垃圾回收。而负责垃圾回收的程序组件,即为垃圾回收器。
垃圾回收其实一个完美的 “Simplicity is Complicated” 的例子。一方面,程序员受益于 GC,无需操心、也不再需要对内存进行手动的申请和释放操作,GC 在程序运行时自动释放残留的内存。另一方面,GC 对程序员几乎不可见,仅在程序需要进行特殊优化时,通过提供可调控的 API,对 GC 的运行时机、运行开销进行把控的时候才得以现身。
通常,垃圾回收器的执行过程被划分为两个半独立的组件:
-
赋值器(Mutator):这一名称本质上是在指代用户态的代码。因为对垃圾回收器而言,用户态的代码仅仅只是在修改对象之间的引用关系,也就是在对象图(对象之间引用关系的一个有向图)上进行操作。
-
回收器(Collector):负责执行垃圾回收的代码。
2. 根对象到底是什么?
根对象在垃圾回收的术语中又叫做根集合,它是垃圾回收器在标记过程时最先检查的对象,包括:
-
全局变量:程序在编译期就能确定的那些存在于程序整个生命周期的变量。
-
执行栈:每个 goroutine 都包含自己的执行栈,这些执行栈上包含栈上的变量及指向分配的堆内存区块的指针。
-
寄存器:寄存器的值可能表示一个指针,参与计算的这些指针可能指向某些赋值器分配的堆内存区块。
3. 常见的 GC 实现方式有哪些?Go 语言的 GC 使用的是什么?
所有的 GC 算法其存在形式可以归结为追踪(Tracing)和引用计数(Reference Counting)这两种形式的混合运用。
-
追踪式 GC
从根对象出发,根据对象之间的引用信息,一步步推进直到扫描完毕整个堆并确定需要保留的对象,从而回收所有可回收的对象。Go、 Java、V8 对 JavaScript 的实现等均为追踪式 GC。
-
引用计数式 GC
每个对象自身包含一个被引用的计数器,当计数器归零时自动得到回收。因为此方法缺陷较多,在追求高性能时通常不被应用。Python、Objective-C 等均为引用计数式 GC。
目前比较常见的 GC 实现方式包括:
-
追踪式,分为多种不同类型,例如:
-
标记清扫:从根对象出发,将确定存活的对象进行标记,并清扫可以回收的对象。
-
标记整理:为了解决内存碎片问题而提出,在标记过程中,将对象尽可能整理到一块连续的内存上。
-
增量式:将标记与清扫的过程分批执行,每次执行很小的部分,从而增量的推进垃圾回收,达到近似实时、几乎无停顿的目的。
-
增量整理:在增量式的基础上,增加对对象的整理过程。
-
分代式:将对象根据存活时间的长短进行分类,存活时间小于某个值的为年轻代,存活时间大于某个值的为老年代,永远不会参与回收的对象为永久代。并根据分代假设(如果一个对象存活时间不长则倾向于被回收,如果一个对象已经存活很长时间则倾向于存活更长时间)对对象进行回收。
-
引用计数:根据对象自身的引用计数来回收,当引用计数归零时立即回收。
关于各类方法的详细介绍及其实现不在本文中详细讨论。对于 Go 而言,Go 的 GC 目前使用的是无分代(对象没有代际之分)、不整理(回收过程中不对对象进行移动与整理)、并发(与用户代码并发执行)的三色标记清扫算法。原因在于:
-
对象整理的优势是解决内存碎片问题以及“允许”使用顺序内存分配器。但 Go 运行时的分配算法基于 tcmalloc,基本上没有碎片问题。并且顺序内存分配器在多线程的场景下并不适用。Go 使用的是基于 tcmalloc 的现代内存分配算法,对对象进行整理不会带来实质性的性能提升。
-
分代 GC 依赖分代假设,即 GC 将主要的回收目标放在新创建的对象上(存活时间短,更倾向于被回收),而非频繁检查所有对象。但 Go 的编译器会通过逃逸分析将大部分新生对象存储在栈上(栈直接被回收),只有那些需要长期存在的对象才会被分配到需要进行垃圾回收的堆中。也就是说,分代 GC 回收的那些存活时间短的对象在 Go 中是直接被分配到栈上,当 goroutine 死亡后栈也会被直接回收,不需要 GC 的参与,进而分代假设并没有带来直接优势。并且 Go 的垃圾回收器与用户代码并发执行,使得 STW 的时间与对象的代际、对象的 size 没有关系。Go 团队更关注于如何更好地让 GC 与用户代码并发执行(使用适当的 CPU 来执行垃圾回收),而非减少停顿时间这一单一目标上。
4. 三色标记法是什么?
理解三色标记法的关键是理解对象的三色抽象以及波面(wavefront)推进这两个概念。三色抽象只是一种描述追踪式回收器的方法,在实践中并没有实际含义,它的重要作用在于从逻辑上严密推导标记清理这种垃圾回收方法的正确性。也就是说,当我们谈及三色标记法时,通常指标记清扫的垃圾回收。
从垃圾回收器的视角来看,三色抽象规定了三种不同类型的对象,并用不同的颜色相称:
-
白色对象(可能死亡):未被回收器访问到的对象。在回收开始阶段,所有对象均为白色,当回收结束后,白色对象均不可达。
-
灰色对象(波面):已被回收器访问到的对象,但回收器需要对其中的一个或多个指针进行扫描,因为他们可能还指向白色对象。
-
黑色对象(确定存活):已被回收器访问到的对象,其中所有字段都已被扫描,黑色对象中任何一个指针都不可能直接指向白色对象。
这样三种不变性所定义的回收过程其实是一个波面不断前进的过程,这个波面同时也是黑色对象和白色对象的边界,灰色对象就是这个波面。
当垃圾回收开始时,只有白色对象。随着标记过程开始进行时,灰色对象开始出现(着色),这时候波面便开始扩大。当一个对象的所有子节点均完成扫描时,会被着色为黑色。当整个堆遍历完成时,只剩下黑色和白色对象,这时的黑色对象为可达对象,即存活;而白色对象为不可达对象,即死亡。这个过程可以视为以灰色对象为波面,将黑色对象和白色对象分离,使波面不断向前推进,直到所有可达的灰色对象都变为黑色对象为止的过程。如下图所示:
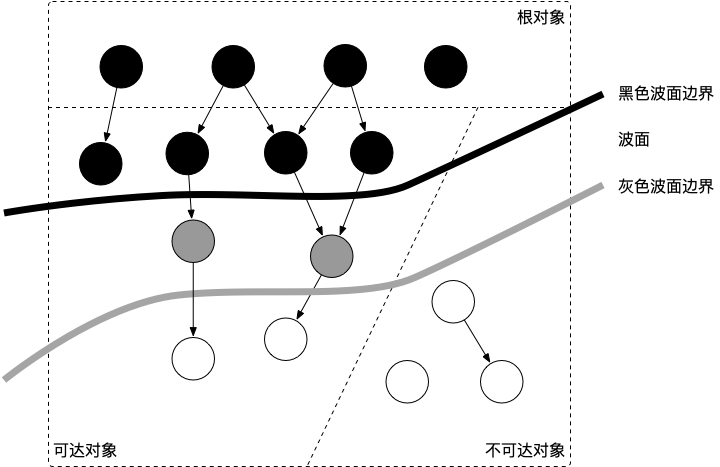
图中展示了根对象、可达对象、不可达对象,黑、灰、白对象以及波面之间的关系。
5. STW 是什么意思?
STW 是 StoptheWorld 的缩写,即万物静止,是指在垃圾回收过程中为了保证实现的正确性、防止无止境的内存增长等问题而不可避免的需要停止赋值器进一步操作对象图的一段过程。
在这个过程中整个用户代码被停止或者放缓执行, STW 越长,对用户代码造成的影响(例如延迟)就越大,早期 Go 对垃圾回收器的实现中 STW 长达几百毫秒,对时间敏感的实时通信等应用程序会造成巨大的影响。我们来看一个例子:
package mainimport ( "runtime" "time")func main() { go func() { for { } }() time.Sleep(time.Millisecond) runtime.GC() println("OK")}上面的这个程序在 Go 1.14 以前永远都不会输出 OK,其罪魁祸首是 STW 无限制的被延长。
尽管 STW 如今已经优化到了半毫秒级别以下,但这个程序被卡死原因在于仍然是 STW 导致的。原因在于,GC 在进入 STW 时,需要等待让所有的用户态代码停止,但是 for{} 所在的 goroutine 永远都不会被中断,从而停留在 STW 阶段。实际实践中也是如此,当程序的某个 goroutine 长时间得不到停止,强行拖慢 STW,这种情况下造成的影响(卡死)是非常可怕的。好在自 Go 1.14 之后,这类 goroutine 能够被异步地抢占,从而使得
STW 的时间如同普通程序那样,不会超过半个毫秒,程序也不会因为仅仅等待一个 goroutine 的停止而停顿在 STW 阶段。
6. 如何观察 Go GC?
我们以下面的程序为例,先使用四种不同的方式来介绍如何观察 GC,并在后面的问题中通过几个详细的例子再来讨论如何优化 GC。
package mainfunc allocate() { _ = make([]byte, 1<<20)}func main() { for n := 1; n < 100000; n++ { allocate() }}方式1: GODEBUG=gctrace=1
我们首先可以通过:
$ go build -o main$ GODEBUG=gctrace=1 ./maingc 1 @0.000s 2%: 0.009+0.23+0.004 ms clock, 0.11+0.083/0.019/0.14+0.049 ms cpu, 4->6->2 MB, 5 MB goal, 12 Pscvg: 8 KB releasedscvg: inuse: 3, idle: 60, sys: 63, released: 57, consumed: 6 (MB)gc 2 @0.001s 2%: 0.018+1.1+0.029 ms clock, 0.22+0.047/0.074/0.048+0.34 ms cpu, 4->7->3 MB, 5 MB goal, 12 Pscvg: inuse: 3, idle: 60, sys: 63, released: 56, consumed: 7 (MB)gc 3 @0.003s 2%: 0.018+0.59+0.011 ms clock, 0.22+0.073/0.008/0.042+0.13 ms cpu, 5->6->1 MB, 6 MB goal, 12 Pscvg: 8 KB releasedscvg: inuse: 2, idle: 61, sys: 63, released: 56, consumed: 7 (MB)gc 4 @0.003s 4%: 0.019+0.70+0.054 ms clock, 0.23+0.051/0.047/0.085+0.65 ms cpu, 4->6->2 MB, 5 MB goal, 12 Pscvg: 8 KB releasedscvg: inuse: 3, idle: 60, sys: 63, released: 56, consumed: 7 (MB)scvg: 8 KB releasedscvg: inuse: 4, idle: 59, sys: 63, released: 56, consumed: 7 (MB)gc 5 @0.004s 12%: 0.021+0.26+0.49 ms clock, 0.26+0.046/0.037/0.11+5.8 ms cpu, 4->7->3 MB, 5 MB goal, 12 Pscvg: inuse: 5, idle: 58, sys: 63, released: 56, consumed: 7 (MB)gc 6 @0.005s 12%: 0.020+0.17+0.004 ms clock, 0.25+0.080/0.070/0.053+0.051 ms cpu, 5->6->1 MB, 6 MB goal, 12 Pscvg: 8 KB releasedscvg: inuse: 1, idle: 62, sys: 63, released: 56, consumed: 7 (MB)在这个日志中可以观察到两类不同的信息:
gc 1 @0.000s 2%: 0.009+0.23+0.004 ms clock, 0.11+0.083/0.019/0.14+0.049 ms cpu, 4->6->2 MB, 5 MB goal, 12 Pgc 2 @0.001s 2%: 0.018+1.1+0.029 ms clock, 0.22+0.047/0.074/0.048+0.34 ms cpu, 4->7->3 MB, 5 MB goal, 12 P...以及:
scvg: 8 KB releasedscvg: inuse: 3, idle: 60, sys: 63, released: 57, consumed: 6 (MB)scvg: inuse: 3, idle: 60, sys: 63, released: 56, consumed: 7 (MB)...对于用户代码向运行时申请内存产生的垃圾回收:
gc 2 @0.001s 2%: 0.018+1.1+0.029 ms clock, 0.22+0.047/0.074/0.048+0.34 ms cpu, 4->7->3 MB, 5 MB goal, 12 P含义由下表所示:
| 字段 | 含义 |
|---|---|
| gc 2 | 第二个 GC 周期 |
| 0.001 | 程序开始后的 0.001 秒 |
| 2% | 该 GC 周期中 CPU 的使用率 |
| 0.018 | 标记开始时, STW 所花费的时间(wall clock) |
| 1.1 | 标记过程中,并发标记所花费的时间(wall clock) |
| 0.029 | 标记终止时, STW 所花费的时间(wall clock) |
| 0.22 | 标记开始时, STW 所花费的时间(cpu time) |
| 0.047 | 标记过程中,标记辅助所花费的时间(cpu time) |
| 0.074 | 标记过程中,并发标记所花费的时间(cpu time) |
| 0.048 | 标记过程中,GC 空闲的时间(cpu time) |
| 0.34 | 标记终止时, STW 所花费的时间(cpu time) |
| 4 | 标记开始时,堆的大小的实际值 |
| 7 | 标记结束时,堆的大小的实际值 |
| 3 | 标记结束时,标记为存活的对象大小 |
| 5 | 标记结束时,堆的大小的预测值 |
| 12 | P 的数量 |
wall clock 是指开始执行到完成所经历的实际时间,包括其他程序和本程序所消耗的时间;cpu time 是指特定程序使用 CPU 的时间;他们存在以下关系:
wall clock < cpu time: 充分利用多核
wall clock ≈ cpu time: 未并行执行
wall clock > cpu time: 多核优势不明显
对于运行时向操作系统申请内存产生的垃圾回收(向操作系统归还多余的内存):
scvg: 8 KB releasedscvg: inuse: 3, idle: 60, sys: 63, released: 57, consumed: 6 (MB)含义由下表所示:
| 字段 | 含义 |
|---|---|
| 8 KB released | 向操作系统归还了 8 KB 内存 |
| 3 | 已经分配给用户代码、正在使用的总内存大小 (MB)。MB used or partially used spans |
| 60 | 空闲以及等待归还给操作系统的总内存大小(MB)。MB spans pending scavenging |
| 63 | 通知操作系统中保留的内存大小(MB)MB mapped from the system |
| 57 | 已经归还给操作系统的(或者说还未正式申请)的内存大小(MB)。MB released to the system |
| 6 | 已经从操作系统中申请的内存大小(MB)。MB allocated from the system |
方式2: go tool trace
go tool trace 的主要功能是将统计而来的信息以一种可视化的方式展示给用户。要使用此工具,可以通过调用 trace API:
package mainfunc main() { f, _ := os.Create("trace.out") defer f.Close() trace.Start(f) defer trace.Stop() (...)}并通过:
$ go tool trace trace.out2019/12/30 15:50:33 Parsing trace...2019/12/30 15:50:38 Splitting trace...2019/12/30 15:50:45 Opening browser. Trace viewer is listening on http://127.0.0.1:51839命令来启动可视化界面:
选择第一个链接可以获得如下图示:
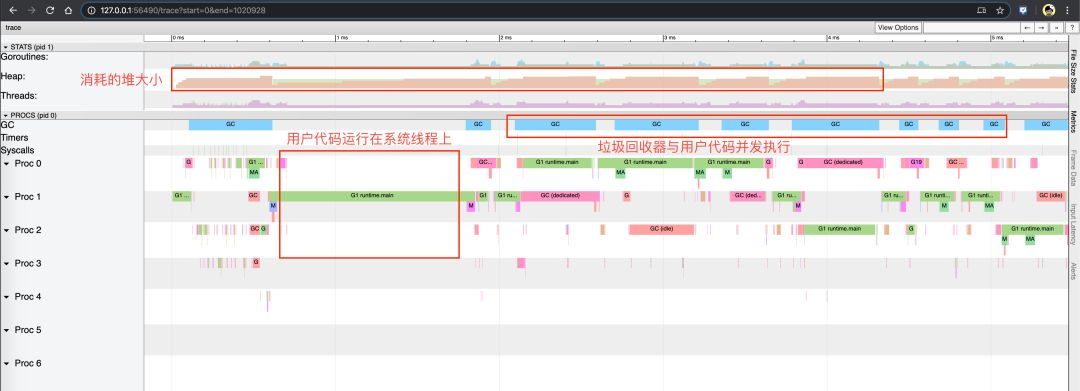
右上角的问号可以打开帮助菜单,主要使用方式包括:
-
w/s 键可以用于放大或者缩小视图
-
a/d 键可以用于左右移动
方式3: debug.ReadGCStats
此方式可以通过代码的方式来直接实现对感兴趣指标的监控,例如我们希望每隔一秒钟监控一次 GC 的状态:
func printGCStats() { t := time.NewTicker(time.Second) s := debug.GCStats{} for { select { case <-t.C: debug.ReadGCStats(&s) fmt.Printf("gc %d last@%v, PauseTotal %v\n", s.NumGC, s.LastGC, s.PauseTotal) } }}func main() { go printGCStats() (...)}我们能够看到如下输出:
$ go run main.gogc 4954 last@2019-12-30 15:19:37.505575 +0100 CET, PauseTotal 29.901171msgc 9195 last@2019-12-30 15:19:38.50565 +0100 CET, PauseTotal 77.579622msgc 13502 last@2019-12-30 15:19:39.505714 +0100 CET, PauseTotal 128.022307msgc 17555 last@2019-12-30 15:19:40.505579 +0100 CET, PauseTotal 182.816528msgc 21838 last@2019-12-30 15:19:41.505595 +0100 CET, PauseTotal 246.618502ms方式4: runtime.ReadMemStats
除了使用 debug 包提供的方法外,还可以直接通过运行时的内存相关的 API 进行监控:
func printMemStats() { t := time.NewTicker(time.Second) s := runtime.MemStats{} for { select { case <-t.C: runtime.ReadMemStats(&s) fmt.Printf("gc %d last@%v, next_heap_size@%vMB\n", s.NumGC, time.Unix(int64(time.Duration(s.LastGC).Seconds()), 0), s.NextGC/(1<<20)) } }}func main() { go printMemStats() (...)}运行:
$ go run main.gogc 4887 last@2019-12-30 15:44:56 +0100 CET, next_heap_size@4MBgc 10049 last@2019-12-30 15:44:57 +0100 CET, next_heap_size@4MBgc 15231 last@2019-12-30 15:44:58 +0100 CET, next_heap_size@4MBgc 20378 last@2019-12-30 15:44:59 +0100 CET, next_heap_size@6MB当然,后两种方式能够监控的指标很多,读者可以自行查看 debug.GCStats 和runtime.MemStats 的字段,这里不再赘述。
7. 有了 GC,为什么还会发生内存泄露?
在一个具有 GC 的语言中,我们常说的内存泄漏,用严谨的话来说应该是:预期的能很快被释放的内存由于附着在了长期存活的内存上、或生命期意外地被延长,导致预计能够立即回收的内存而长时间得不到回收。
在 Go 中,由于 goroutine 的存在,所谓的内存泄漏除了附着在长期对象上之外,还存在多种不同的形式。
形式1:预期能被快速释放的内存因被根对象引用而没有得到迅速释放
当有一个全局对象时,可能不经意间将某个变量附着在其上,且忽略的将其进行释放,则该内存永远不会得到释放。例如:
var cache = map[interface{}]interface{}{}func keepalloc() { for i := 0; i < 10000; i++ { m := make([]byte, 1<<10) cache[i] = m }}形式2:goroutine 泄漏
Goroutine 作为一种逻辑上理解的轻量级线程,需要维护执行用户代码的上下文信息。在运行过程中也需要消耗一定的内存来保存这类信息,而这些内存在目前版本的 Go 中是不会被释放的。因此,如果一个程序持续不断地产生新的 goroutine、且不结束已经创建的 goroutine 并复用这部分内存,就会造成内存泄漏的现象,例如:
func keepalloc2() { for i := 0; i < 100000; i++ { go func() { select {} }() }}验证
我们可以通过如下形式来调用上述两个函数:
package mainimport ( "os" "runtime/trace")func main() { f, _ := os.Create("trace.out") defer f.Close() trace.Start(f) defer trace.Stop() keepalloc() keepalloc2()}运行程序:
go run main.go会看到程序中生成了 trace.out 文件,我们可以使用 go tool trace trace.out 命令得到下图:
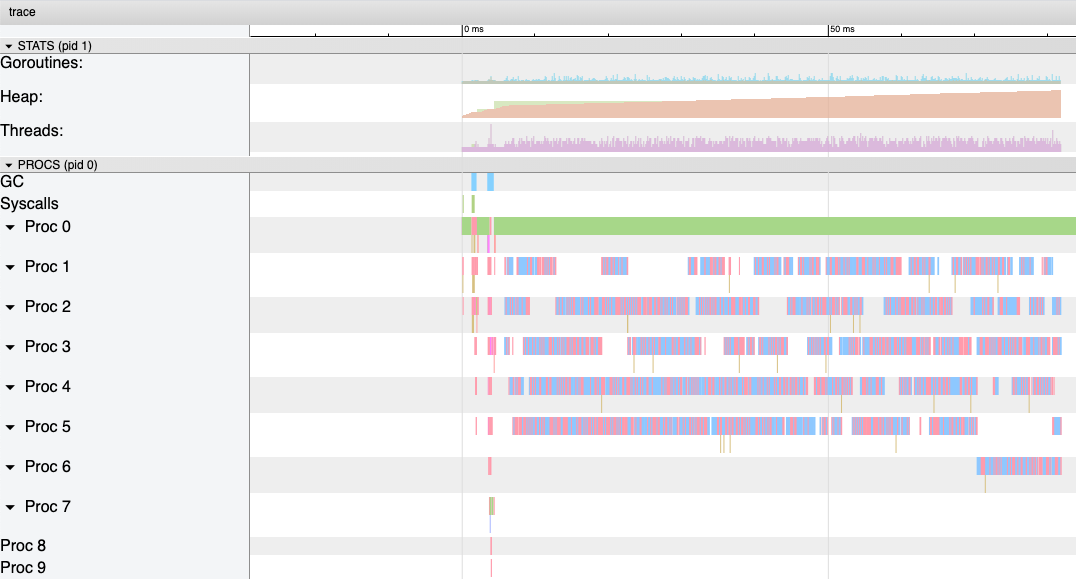
可以看到,途中的 Heap 在持续增长,没有内存被回收,产生了内存泄漏的现象。
值得一提的是,这种形式的 goroutine 泄漏还可能由 channel 泄漏导致。而 channel 的泄漏本质上与 goroutine 泄漏存在直接联系。Channel 作为一种同步原语,会连接两个不同的 goroutine,如果一个 goroutine 尝试向一个没有接收方的无缓冲 channel 发送消息,则该 goroutine 会被永久的休眠,整个 goroutine 及其执行栈都得不到释放,例如:
var ch = make(chan struct{})func keepalloc3() { for i := 0; i < 100000; i++ { // 没有接收方,goroutine 会一直阻塞 go func() { ch <- struct{}{} }() }}8. 并发标记清除法的难点是什么?
在没有用户态代码并发修改 三色抽象的情况下,回收可以正常结束。但是并发回收的根本问题在于,用户态代码在回收过程中会并发地更新对象图,从而造成赋值器和回收器可能对对象图的结构产生不同的认知。这时以一个固定的三色波面作为回收过程前进的边界则不再合理。
我们不妨考虑赋值器写操作的例子:
|
时 序 |
回收器 | 赋值器 | 说明 |
|---|---|---|---|
| 1 | shade(A, gray) | 回收器:根对象的子节点着色为灰色对象 | |
| 2 | shade(C, black) | 回收器:当所有子节点着色为灰色后,将节点着为黑色 | |
| 3 | C.ref3 = C.ref2.ref1 | 赋值器:并发的修改了 C 的子节点 | |
| 4 | A.ref1 = nil | 赋值器:并发的修改了 A 的子节点 | |
| 5 | shade(A.ref1, gray) | 回收器:进一步灰色对象的子节点并着色为灰色对象,这时由于 A.ref1 为 nil,什么事情也没有发生 |
|
| 6 | shade(A, black) | 回收器:由于所有子节点均已标记,回收器也不会重新扫描已经被标记为黑色的对象,此时 A 被着色为黑色, scan(A) 什么也不会发生,进而 B 在此次回收过程中永远不会被标记为黑色,进而错误地被回收 |
-
初始状态:假设某个黑色对象 C 指向某个灰色对象 A ,而 A 指向白色对象 B;
-
C.ref3 = C.ref2.ref1:赋值器并发地将黑色对象 C 指向(ref3)了白色对象 B;
-
A.ref1 = nil:移除灰色对象 A 对白色对象 B 的引用(ref2);
-
最终状态:在继续扫描的过程中,白色对象 B 永远不会被标记为黑色对象了(回收器不会重新扫描黑色对象),进而对象 B 被错误地回收。
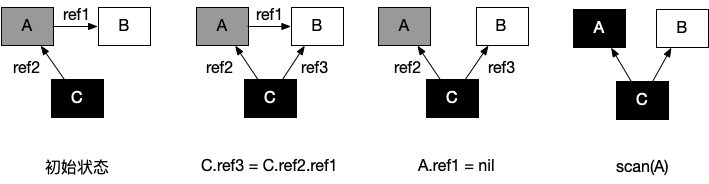
总而言之,并发标记清除中面临的一个根本问题就是如何保证标记与清除过程的正确性。
9. 什么是写屏障、混合写屏障,如何实现?
要讲清楚写屏障,就需要理解三色标记清除算法中的强弱不变性以及赋值器的颜色,理解他们需要一定的抽象思维。写屏障是一个在并发垃圾回收器中才会出现的概念,垃圾回收器的正确性体现在:不应出现对象的丢失,也不应错误的回收还不需要回收的对象。
可以证明,当以下两个条件同时满足时会破坏垃圾回收器的正确性:
-
条件 1: 赋值器修改对象图,导致某一黑色对象引用白色对象;
-
条件 2: 从灰色对象出发,到达白色对象的、未经访问过的路径被赋值器破坏。
只要能够避免其中任何一个条件,则不会出现对象丢失的情况,因为:
-
如果条件 1 被避免,则所有白色对象均被灰色对象引用,没有白色对象会被遗漏;
-
如果条件 2 被避免,即便白色对象的指针被写入到黑色对象中,但从灰色对象出发,总存在一条没有访问过的路径,从而找到到达白色对象的路径,白色对象最终不会被遗漏。
我们不妨将三色不变性所定义的波面根据这两个条件进行削弱:
-
当满足原有的三色不变性定义(或上面的两个条件都不满足时)的情况称为强三色不变性(strong tricolor invariant)
-
当赋值器令黑色对象引用白色对象时(满足条件 1 时)的情况称为弱三色不变性(weak tricolor invariant)
当赋值器进一步破坏灰色对象到达白色对象的路径时(进一步满足条件 2 时),即打破弱三色不变性,也就破坏了回收器的正确性;或者说,在破坏强弱三色不变性时必须引入额外的辅助操作。弱三色不变形的好处在于:只要存在未访问的能够到达白色对象的路径,就可以将黑色对象指向白色对象。
如果我们考虑并发的用户态代码,回收器不允许同时停止所有赋值器,就是涉及了存在的多个不同状态的赋值器。为了对概念加以明确,还需要换一个角度,把回收器视为对象,把赋值器视为影响回收器这一对象的实际行为(即影响 GC 周期的长短),从而引入赋值器的颜色:
-
黑色赋值器:已经由回收器扫描过,不会再次对其进行扫描。
-
灰色赋值器:尚未被回收器扫描过,或尽管已经扫描过但仍需要重新扫描。
赋值器的颜色对回收周期的结束产生影响:
-
如果某种并发回收器允许灰色赋值器的存在,则必须在回收结束之前重新扫描对象图。
-
如果重新扫描过程中发现了新的灰色或白色对象,回收器还需要对新发现的对象进行追踪,但是在新追踪的过程中,赋值器仍然可能在其根中插入新的非黑色的引用,如此往复,直到重新扫描过程中没有发现新的白色或灰色对象。
于是,在允许灰色赋值器存在的算法,最坏的情况下,回收器只能将所有赋值器线程停止才能完成其跟对象的完整扫描,也就是我们所说的 STW。
为了确保强弱三色不变性的并发指针更新操作,需要通过赋值器屏障技术来保证指针的读写操作一致。因此我们所说的 Go 中的写屏障、混合写屏障,其实是指赋值器的写屏障,赋值器的写屏障用来保证赋值器在进行指针写操作时,不会破坏弱三色不变性。
有两种非常经典的写屏障:Dijkstra 插入屏障和 Yuasa 删除屏障。
灰色赋值器的 Dijkstra 插入屏障的基本思想是避免满足条件 1:
// 灰色赋值器 Dijkstra 插入屏障func DijkstraWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) { shade(ptr) *slot = ptr}为了防止黑色对象指向白色对象,应该假设 *slot 可能会变为黑色,为了确保 ptr 不会在被赋值到 *slot 前变为白色, shade(ptr) 会先将指针 ptr 标记为灰色,进而避免了条件 1。但是,由于并不清楚赋值器以后会不会将这个引用删除,因此还需要重新扫描来重新确定关系图,这时需要 STW,如图所示:
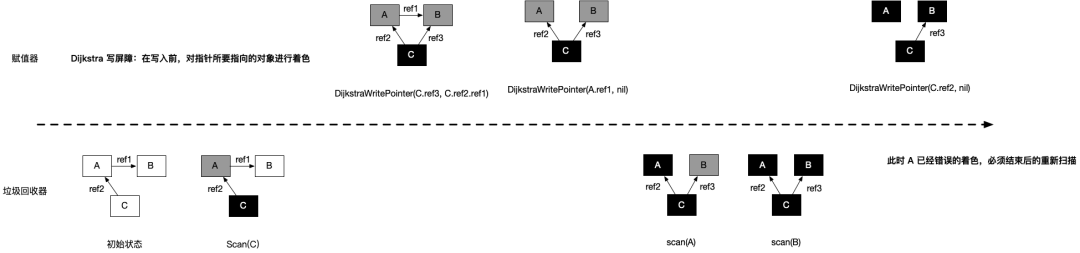
黑色赋值器的 Yuasa 删除屏障的基本思想是避免满足条件 2:
// 黑色赋值器 Yuasa 屏障func YuasaWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) { shade(*slot) *slot = ptr}为了防止丢失从灰色对象到白色对象的路径,应该假设 *slot 可能会变为黑色,为了确保 ptr 不会在被赋值到 *slot 前变为白色, shade(*slot) 会先将 *slot 标记为灰色,进而该写操作总是创造了一条灰色到灰色或者灰色到白色对象的路径,进而避免了条件 2。
Yuasa 删除屏障的优势则在于不需要标记结束阶段的重新扫描,缺陷是依然会产生丢失的对象,需要在标记开始前对整个对象图进行快照。
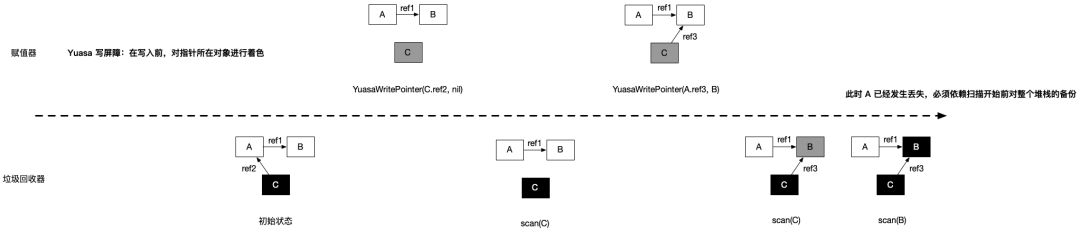
但在最终实现时原提案中对 ptr 的着色还额外包含对执行栈的着色检查,但由于时间有限,并未完整实现过,所以混合写屏障在目前的实现伪代码是:
// 混合写屏障func HybridWritePointerSimple(slot *unsafe.Pointer, ptr unsafe.Pointer) { shade(*slot) shade(ptr) *slot = ptr}在这个实现中,如果无条件对引用双方进行着色,自然结合了 Dijkstra 和 Yuasa 写屏障的优势,但缺点也非常明显,因为着色成本是双倍的,而且编译器需要插入的代码也成倍增加,随之带来的结果就是编译后的二进制文件大小也进一步增加。为了针对写屏障的性能进行优化,Go 1.10 前后,Go 团队随后实现了批量写屏障机制。其基本想法是将需要着色的指针同一写入一个缓存,每当缓存满时统一对缓存中的所有 ptr 指针进行着色。
GC 的实现细节
10. Go 语言中 GC 的流程是什么?
当前版本的 Go 以 STW 为界限,可以将 GC 划分为五个阶段:
| 阶段 | 说明 | 赋值器状态 |
|---|---|---|
| GCMark | 标记准备阶段,为并发标记做准备工作,启动写屏障 | STW |
| GCMark | 扫描标记阶段,与赋值器并发执行,写屏障开启 | 并发 |
| GCMarkTermination | 标记终止阶段,保证一个周期内标记任务完成,停止写屏障 | STW |
| GCoff | 内存清扫阶段,将需要回收的内存归还到堆中,写屏障关闭 | 并发 |
| GCoff | 内存归还阶段,将过多的内存归还给操作系统,写屏障关闭 | 并发 |
具体而言,各个阶段的触发函数分别为:

11. 触发 GC 的时机是什么?
Go 语言中对 GC 的触发时机存在两种形式:
-
主动触发,通过调用 runtime.GC 来触发 GC,此调用阻塞式地等待当前 GC 运行完毕。
-
被动触发,分为两种方式:
-
使用系统监控,当超过两分钟没有产生任何 GC 时,强制触发 GC。
-
使用步调(Pacing)算法,其核心思想是控制内存增长的比例。
由于本问题剩余内容公式太多,无法完美在公众号文章展示,建议点击阅读原文 ,直达原文,享受更好的阅读体验。
12. 如果内存分配速度超过了标记清除的速度怎么办?
目前的 Go 实现中,当 GC 触发后,会首先进入并发标记的阶段。并发标记会设置一个标志,并在 mallocgc 调用时进行检查。当存在新的内存分配时,会暂停分配内存过快的那些 goroutine,并将其转去执行一些辅助标记(Mark Assist)的工作,从而达到放缓继续分配、辅助 GC 的标记工作的目的。
编译器会分析用户代码,并在需要分配内存的位置,将申请内存的操作翻译为 mallocgc 调用,而 mallocgc 的实现决定了标记辅助的实现,其伪代码思路如下:
func mallocgc(t typ.Type, size uint64) { if enableMarkAssist { // 进行标记辅助,此时用户代码没有得到执行 (...) } // 执行内存分配 (...)}
GC 的优化问题
13. GC 关注的指标有哪些?
Go 的 GC 被设计为成比例触发、大部分工作与赋值器并发、不分代、无内存移动且会主动向操作系统归还申请的内存。因此最主要关注的、能够影响赋值器的性能指标有:
-
CPU 利用率:回收算法会在多大程度上拖慢程序?有时候,这个是通过回收占用的 CPU 时间与其它 CPU 时间的百分比来描述的。
-
GC 停顿时间:回收器会造成多长时间的停顿?目前的 GC 中需要考虑 STW 和 Mark Assist 两个部分可能造成的停顿。
-
GC 停顿频率:回收器造成的停顿频率是怎样的?目前的 GC 中需要考虑 STW 和 Mark Assist 两个部分可能造成的停顿。
-
GC 可扩展性:当堆内存变大时,垃圾回收器的性能如何?但大部分的程序可能并不一定关心这个问题。
14. Go 的 GC 如何调优?
Go 的 GC 被设计为极致简洁,与较为成熟的 Java GC 的数十个可控参数相比,严格意义上来讲,Go 可供用户调整的参数只有 GOGC 环境变量。当我们谈论 GC 调优时,通常是指减少用户代码对 GC 产生的压力,这一方面包含了减少用户代码分配内存的数量(即对程序的代码行为进行调优),另一方面包含了最小化 Go 的 GC 对 CPU 的使用率(即调整 GOGC)。
GC 的调优是在特定场景下产生的,并非所有程序都需要针对 GC 进行调优。只有那些对执行延迟非常敏感、当 GC 的开销成为程序性能瓶颈的程序,才需要针对 GC 进行性能调优,几乎不存在于实际开发中 99% 的情况。除此之外,Go 的 GC 也仍然有一定的可改进的空间,也有部分 GC 造成的问题,目前仍属于 Open Problem。
总的来说,我们可以在现在的开发中处理的有以下几种情况:
-
对停顿敏感:GC 过程中产生的长时间停顿、或由于需要执行 GC 而没有执行用户代码,导致需要立即执行的用户代码执行滞后。
-
对资源消耗敏感:对于频繁分配内存的应用而言,频繁分配内存增加 GC 的工作量,原本可以充分利用 CPU 的应用不得不频繁地执行垃圾回收,影响用户代码对 CPU 的利用率,进而影响用户代码的执行效率。
从这两点来看,所谓 GC 调优的核心思想也就是充分的围绕上面的两点来展开:优化内存的申请速度,尽可能的少申请内存,复用已申请的内存。或者简单来说,不外乎这三个关键字:控制、减少、复用。
我们将通过三个实际例子介绍如何定位 GC 的存在的问题,并一步一步进行性能调优。当然,在实际情况中问题远比这些例子要复杂,这里也只是讨论调优的核心思想,更多的时候也只能具体问题具体分析。
例1:合理化内存分配的速度、提高赋值器的 CPU 利用率
我们来看这样一个例子。在这个例子中, concat 函数负责拼接一些长度不确定的字符串。并且为了快速完成任务,出于某种原因,在两个嵌套的 for 循环中一口气创建了 800 个 goroutine。在 main 函数中,启动了一个 goroutine 并在程序结束前不断的触发 GC,并尝试输出 GC 的平均执行时间:
package mainimport ( "fmt" "os" "runtime" "runtime/trace" "sync/atomic" "time")var ( stop int32 count int64 sum time.Duration)func concat() { for n := 0; n < 100; n++ { for i := 0; i < 8; i++ { go func() { s := "Go GC" s += " " + "Hello" s += " " + "World" _ = s }() } }}func main() { f, _ := os.Create("trace.out") defer f.Close() trace.Start(f) defer trace.Stop() go func() { var t time.Time for atomic.LoadInt32(&stop) == 0 { t = time.Now() runtime.GC() sum += time.Since(t) count++ } fmt.Printf("GC spend avg: %v\n", time.Duration(int64(sum)/count)) }() concat() atomic.StoreInt32(&stop, 1)}这个程序的执行结果是:
$ go build -o main$ ./mainGC spend avg: 2.583421msGC 平均执行一次需要长达 2ms 的时间,我们再进一步观察 trace 的结果:
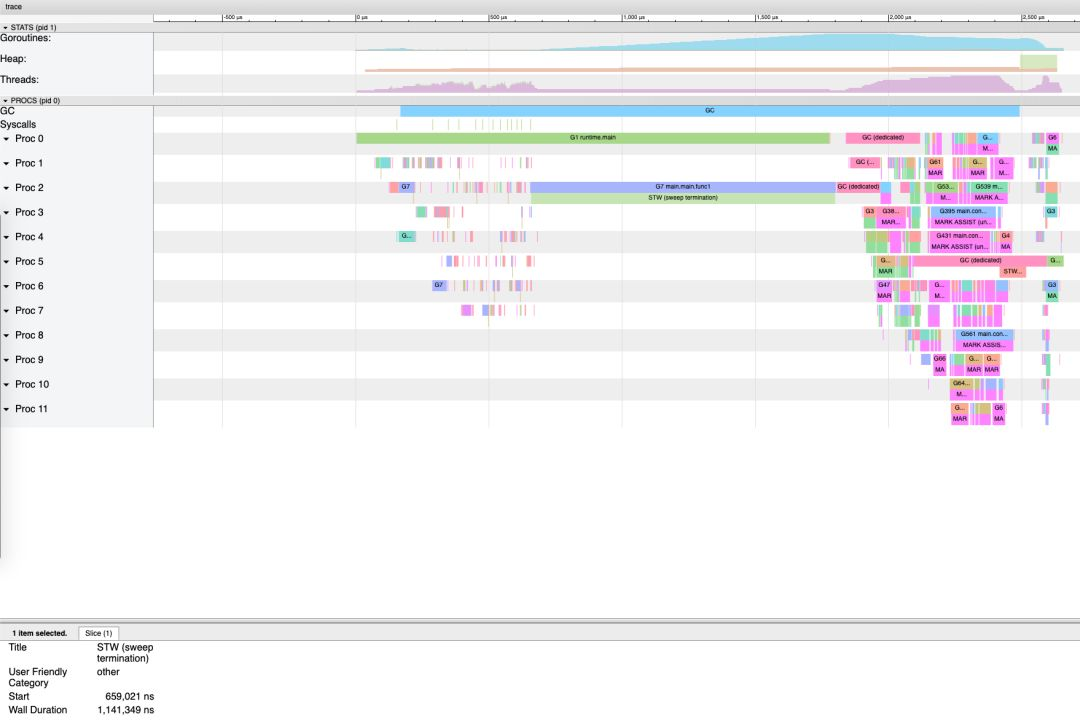
程序的整个执行过程中仅执行了一次 GC,而且仅 Sweep STW 就耗费了超过 1 ms,非常反常。甚至查看赋值器 mutator 的 CPU 利用率,在整个 trace 尺度下连 40% 都不到:
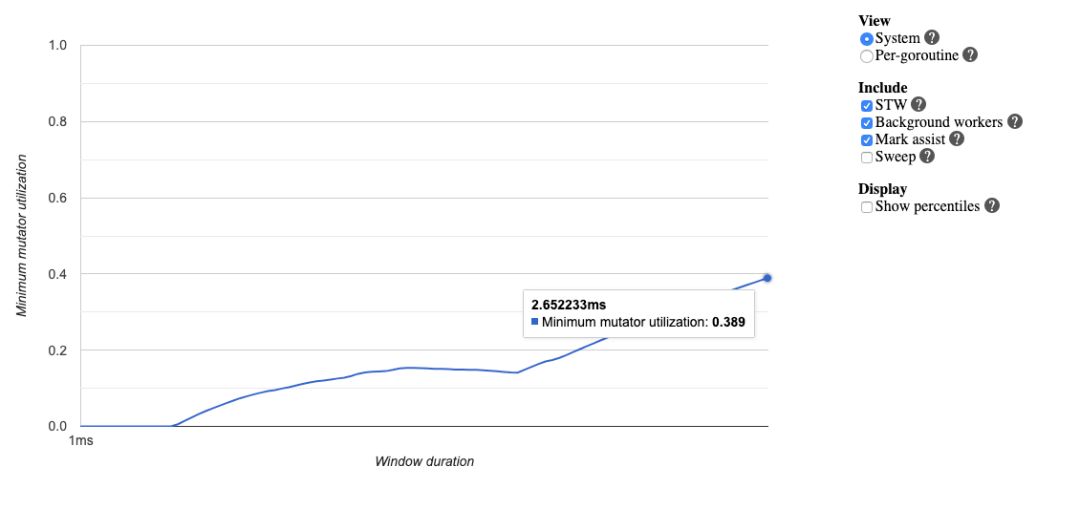
主要原因是什么呢?我们不妨查看 goroutine 的分析:
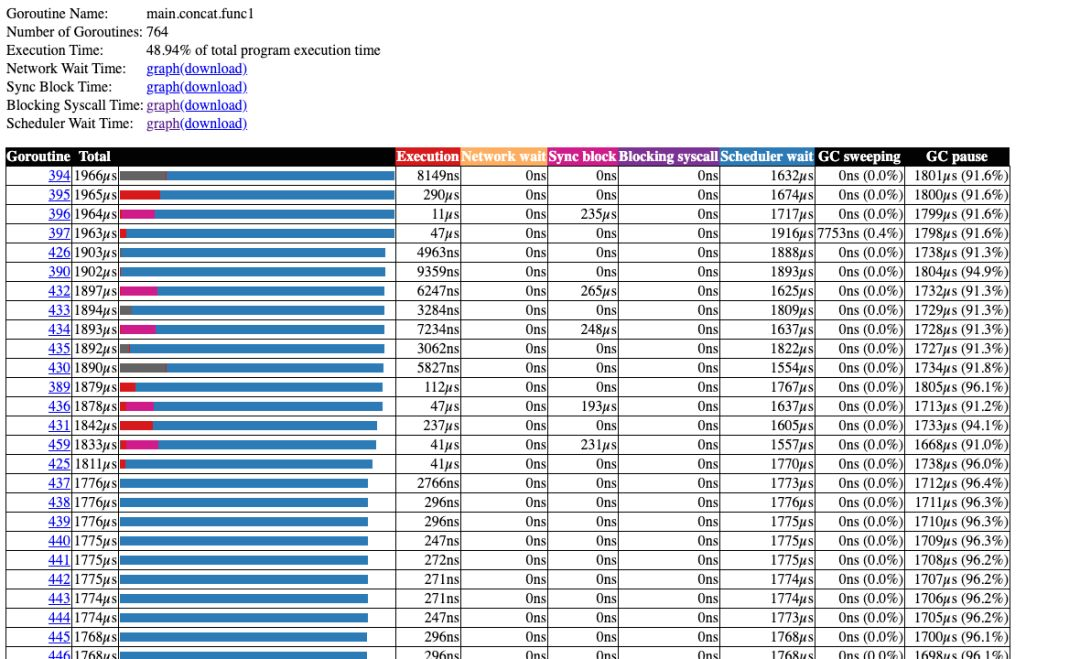
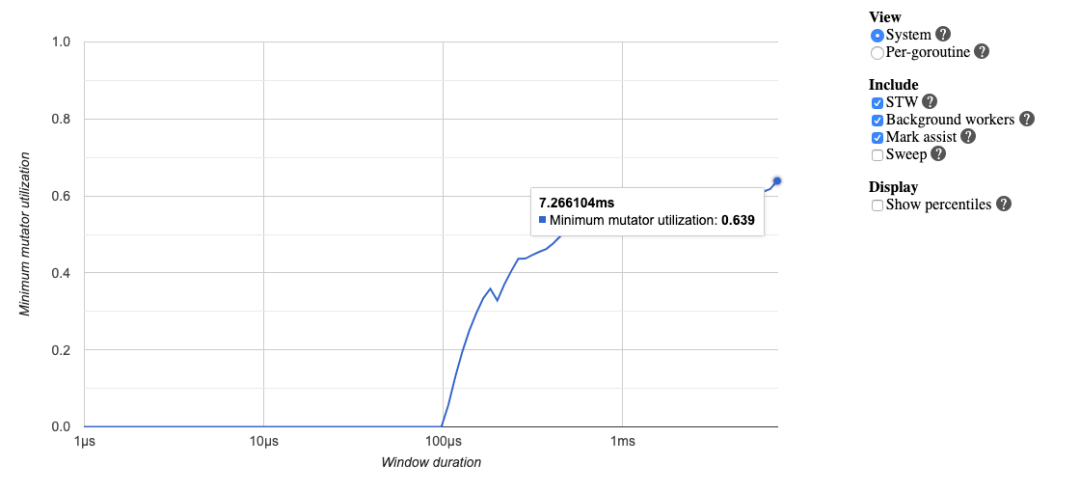
func concat() { wg := sync.WaitGroup{} for n := 0; n < 100; n++ { wg.Add(8) for i := 0; i < 8; i++ { go func() { s := "Go GC" s += " " + "Hello" s += " " + "World" _ = s wg.Done() }() } wg.Wait() }}这时候我们再来看:
$ go build -o main$ ./mainGC spend avg: 328.54µsGC 的平均时间就降到 300 微秒了。这时的赋值器 CPU 使用率也提高到了 60%,相对来说就很可观了:
例2:降低并复用已经申请的内存
我们通过一个非常简单的 Web 程序来说明复用内存的重要性。在这个程序中,每当产生一个 /example2的请求时,都会创建一段内存,并用于进行一些后续的工作。
package mainimport ( "fmt" "net/http" _ "net/http/pprof")func newBuf() []byte { return make([]byte, 10<<20)}func main() { go func() { http.ListenAndServe("localhost:6060", nil) }() http.HandleFunc("/example2", func(w http.ResponseWriter, r *http.Request) { b := newBuf() // 模拟执行一些工作 for idx := range b { b[idx] = 1 } fmt.Fprintf(w, "done, %v", r.URL.Path[1:]) }) http.ListenAndServe(":8080", nil)}为了进行性能分析,我们还额外创建了一个监听 6060 端口的 goroutine,用于使用 pprof 进行分析。我们先让服务器跑起来:
$ go build -o main$ ./main我们这次使用 pprof 的 trace 来查看 GC 在此服务器中面对大量请求时候的状态,要使用 trace 可以通过访问 /debug/pprof/trace 路由来进行,其中 seconds 参数设置为 20s,并将 trace 的结果保存为 trace.out :
$ wget http://127.0.0.1:6060/debug/pprof/trace\?seconds\=20 -O trace.out--2020-01-01 22:13:34-- http://127.0.0.1:6060/debug/pprof/trace?seconds=20Connecting to 127.0.0.1:6060... connected.HTTP request sent, awaiting response...这时候我们使用一个压测工具 ab,来同时产生 500 个请求( -n 一共 500 个请求, -c 一个时刻执行请求的数量,每次 100 个并发请求):
$ ab -n 500 -c 100 http://127.0.0.1:8080/example2This is ApacheBench, Version 2.3 <$Revision: 1843412 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 127.0.0.1 (be patient)Completed 100 requestsCompleted 200 requestsCompleted 300 requestsCompleted 400 requestsCompleted 500 requestsFinished 500 requestsServer Software: Server Hostname: 127.0.0.1Server Port: 8080Document Path: /example2Document Length: 14 bytesConcurrency Level: 100Time taken for tests: 0.987 secondsComplete requests: 500Failed requests: 0Total transferred: 65500 bytesHTML transferred: 7000 bytesRequests per second: 506.63 [#/sec] (mean)Time per request: 197.382 [ms] (mean)Time per request: 1.974 [ms] (mean, across all concurrent requests)Transfer rate: 64.81 [Kbytes/sec] receivedConnection Times (ms) min mean[+/-sd] median maxConnect: 0 1 1.1 0 7Processing: 13 179 77.5 170 456Waiting: 10 168 78.8 162 455Total: 14 180 77.3 171 458Percentage of the requests served within a certain time (ms) 50% 171 66% 203 75% 222 80% 239 90% 281 95% 335 98% 365 99% 400 100% 458 (longest request)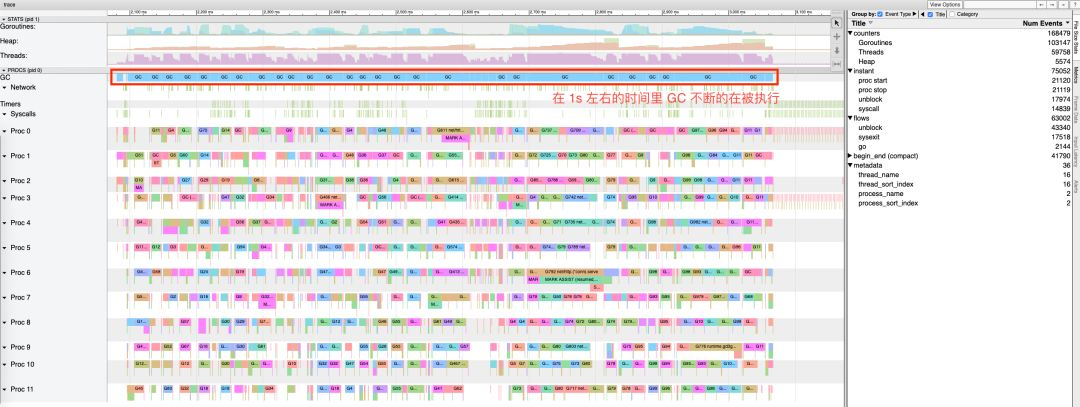 GC 反复被触发,一个显而易见的原因就是内存分配过多。我们可以通过
GC 反复被触发,一个显而易见的原因就是内存分配过多。我们可以通过 go tool pprof 来查看究竟是谁分配了大量内存(使用 web 指令来使用浏览器打开统计信息的可视化图形):
$ go tool pprof http://127.0.0.1:6060/debug/pprof/heapFetching profile over HTTP from http://localhost:6060/debug/pprof/heapSaved profile in /Users/changkun/pprof/pprof.alloc_objects.alloc_space.inuse_objects.inuse_space.003.pb.gzType: inuse_spaceTime: Jan 1, 2020 at 11:15pm (CET)Entering interactive mode (type "help" for commands, "o" for options)(pprof) web(pprof)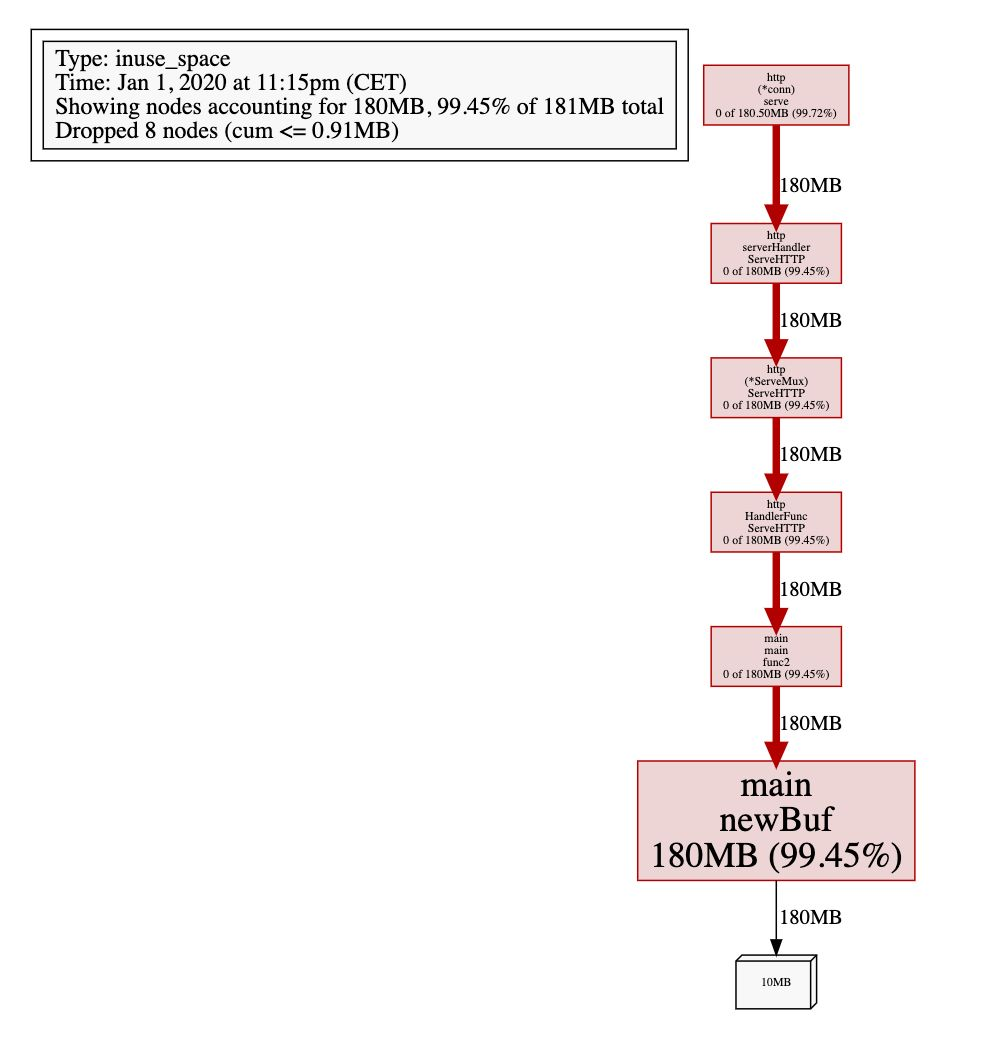
newBuf 产生的申请的内存过多,现在我们使用 sync.Pool 来复用 newBuf 所产生的对象:
package mainimport ( "fmt" "net/http" _ "net/http/pprof" "sync")// 使用 sync.Pool 复用需要的 bufvar bufPool = sync.Pool{ New: func() interface{} { return make([]byte, 10<<20) },}func main() { go func() { http.ListenAndServe("localhost:6060", nil) }() http.HandleFunc("/example2", func(w http.ResponseWriter, r *http.Request) { b := bufPool.Get().([]byte) for idx := range b { b[idx] = 0 } fmt.Fprintf(w, "done, %v", r.URL.Path[1:]) bufPool.Put(b) }) http.ListenAndServe(":8080", nil)}其中 ab 输出的统计结果为:
$ ab -n 500 -c 100 http://127.0.0.1:8080/example2This is ApacheBench, Version 2.3 <$Revision: 1843412 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 127.0.0.1 (be patient)Completed 100 requestsCompleted 200 requestsCompleted 300 requestsCompleted 400 requestsCompleted 500 requestsFinished 500 requestsServer Software: Server Hostname: 127.0.0.1Server Port: 8080Document Path: /example2Document Length: 14 bytesConcurrency Level: 100Time taken for tests: 0.427 secondsComplete requests: 500Failed requests: 0Total transferred: 65500 bytesHTML transferred: 7000 bytesRequests per second: 1171.32 [#/sec] (mean)Time per request: 85.374 [ms] (mean)Time per request: 0.854 [ms] (mean, across all concurrent requests)Transfer rate: 149.85 [Kbytes/sec] receivedConnection Times (ms) min mean[+/-sd] median maxConnect: 0 1 1.4 1 9Processing: 5 75 48.2 66 211Waiting: 5 72 46.8 63 207Total: 5 77 48.2 67 211Percentage of the requests served within a certain time (ms) 50% 67 66% 89 75% 107 80% 122 90% 148 95% 167 98% 196 99% 204 100% 211 (longest request)但从 Requestsper second 每秒请求数来看,从原来的 506.63 变为 1171.32 得到了近乎一倍的提升。从 trace 的结果来看,GC 也没有频繁的被触发从而长期消耗 CPU 使用率:

concat 函数可以预先分配一定长度的缓存,而后再通过 append 的方式将字符串存储到缓存中:
func concat() { wg := sync.WaitGroup{} for n := 0; n < 100; n++ { wg.Add(8) for i := 0; i < 8; i++ { go func() { s := make([]byte, 0, 20) s = append(s, "Go GC"...) s = append(s, ' ') s = append(s, "Hello"...) s = append(s, ' ') s = append(s, "World"...) _ = string(s) wg.Done() }() } wg.Wait() }}原因在于 + 运算符会随着字符串长度的增加而申请更多的内存,并将内容从原来的内存位置拷贝到新的内存位置,造成大量不必要的内存分配,先提前分配好足够的内存,再慢慢地填充,也是一种减少内存分配、复用内存形式的一种表现。
例3:调整 GOGC
我们已经知道了 GC 的触发原则是由步调算法来控制的,其关键在于估计下一次需要触发 GC 时,堆的大小。可想而知,如果我们在遇到海量请求的时,为了避免 GC 频繁触发,是否可以通过将 GOGC 的值设置得更大,让 GC 触发的时间变得更晚,从而减少其触发频率,进而增加用户代码对机器的使用率呢?答案是肯定的。
我们可以非常简单粗暴的将 GOGC 调整为 1000,来执行上一个例子中未复用对象之前的程序:
$ GOGC=1000 ./main这时我们再重新执行压测:
$ ab -n 500 -c 100 http://127.0.0.1:8080/example2This is ApacheBench, Version 2.3 <$Revision: 1843412 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 127.0.0.1 (be patient)Completed 100 requestsCompleted 200 requestsCompleted 300 requestsCompleted 400 requestsCompleted 500 requestsFinished 500 requestsServer Software: Server Hostname: 127.0.0.1Server Port: 8080Document Path: /example2Document Length: 14 bytesConcurrency Level: 100Time taken for tests: 0.923 secondsComplete requests: 500Failed requests: 0Total transferred: 65500 bytesHTML transferred: 7000 bytesRequests per second: 541.61 [#/sec] (mean)Time per request: 184.636 [ms] (mean)Time per request: 1.846 [ms] (mean, across all concurrent requests)Transfer rate: 69.29 [Kbytes/sec] receivedConnection Times (ms) min mean[+/-sd] median maxConnect: 0 1 1.8 0 20Processing: 9 171 210.4 66 859Waiting: 5 158 199.6 62 813Total: 9 173 210.6 68 860Percentage of the requests served within a certain time (ms) 50% 68 66% 133 75% 198 80% 292 90% 566 95% 696 98% 723 99% 743 100% 860 (longest request)可以看到,压测的结果得到了一定幅度的改善( Requestsper second 从原来的 506.63 提高为了 541.61),
并且 GC 的执行频率明显降低:

当然,这种做法其实是治标不治本,并没有从根本上解决内存分配过于频繁的问题,极端情况下,反而会由于 GOGC 太大而导致回收不及时而耗费更多的时间来清理产生的垃圾,这对时间不算敏感的应用还好,但对实时性要求较高的程序来说就是致命的打击了。
因此这时更妥当的做法仍然是,定位问题的所在,并从代码层面上进行优化。
小结
通过上面的三个例子我们可以看到在 GC 调优过程中 go tool pprof 和 go tool trace 的强大作用是帮助我们快速定位 GC 导致瓶颈的具体位置,但这些例子中仅仅覆盖了其功能的很小一部分,我们也没有必要完整覆盖所有的功能,因为总是可以通过http pprof 官方文档、runtime pprof官方文档以及trace 官方文档来举一反三。
现在我们来总结一下前面三个例子中的优化情况:
-
控制内存分配的速度,限制 goroutine 的数量,从而提高赋值器对 CPU 的利用率。
-
减少并复用内存,例如使用 sync.Pool 来复用需要频繁创建临时对象,例如提前分配足够的内存来降低多余的拷贝。
-
需要时,增大 GOGC 的值,降低 GC 的运行频率。
这三种情况几乎涵盖了 GC 调优中的核心思路,虽然从语言上还有很多小技巧可说,但我们并不会在这里事无巨细的进行总结。实际情况也是千变万化,我们更应该着重于培养具体问题具体分析的能力。
当然,我们还应该谨记 过早优化是万恶之源这一警语,在没有遇到应用的真正瓶颈时,将宝贵的时间分配在开发中其他优先级更高的任务上。
15. Go 的垃圾回收器有哪些相关的 API?其作用分别是什么?
在 Go 中存在数量极少的与 GC 相关的 API,它们是
-
runtime.GC:手动触发 GC
-
runtime.ReadMemStats:读取内存相关的统计信息,其中包含部分 GC 相关的统计信息
-
debug.FreeOSMemory:手动将内存归还给操作系统
-
debug.ReadGCStats:读取关于 GC 的相关统计信息
-
debug.SetGCPercent:设置 GOGC 调步变量
-
debug.SetMaxHeap(尚未发布):设置 Go 程序堆的上限值
GC 的历史及演进
16. Go 历史各个版本在 GC 方面的改进?
Go 1:串行三色标记清扫
Go 1.3:并行清扫,标记过程需要 STW,停顿时间在约几百毫秒
Go 1.5:并发标记清扫,停顿时间在一百毫秒以内
Go 1.6:使用 bitmap 来记录回收内存的位置,大幅优化垃圾回收器自身消耗的内存,停顿时间在十毫秒以内
Go 1.7:停顿时间控制在两毫秒以内
Go 1.8:混合写屏障,停顿时间在半个毫秒左右
Go 1.9:彻底移除了栈的重扫描过程
Go 1.12:整合了两个阶段的 Mark Termination,但引入了一个严重的 GC Bug 至今未修(见问题 20),尚无该 Bug 对 GC 性能影响的报告
Go 1.13:着手解决向操作系统归还内存的,提出了新的 Scavenger
Go 1.14:替代了仅存活了一个版本的 scavenger,全新的页分配器,优化分配内存过程的速率与现有的扩展性问题,并引入了异步抢占,解决了由于密集循环导致的 STW 时间过长的问题
可以用下图直观地说明 GC 的演进历史:
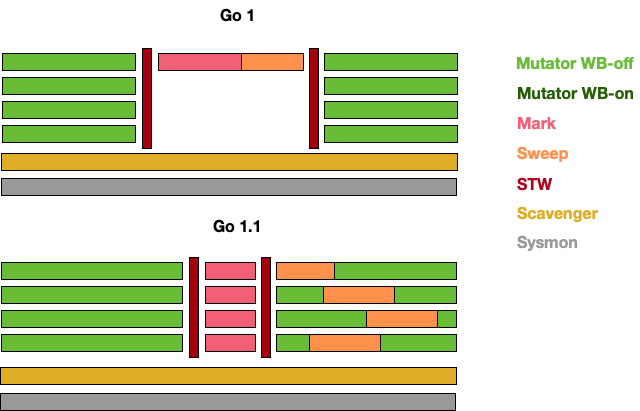
这一想法很自然,因为并行化导致算法结果不一致的情况仅仅发生在标记阶段,而当时的垃圾回收器没有针对并行结果的一致性进行任何优化,因此才需要在标记阶段进入 STW。对于 Scavenger 而言,早期的版本中会有一个单独的线程来定期将多余的内存归还给操作系统。
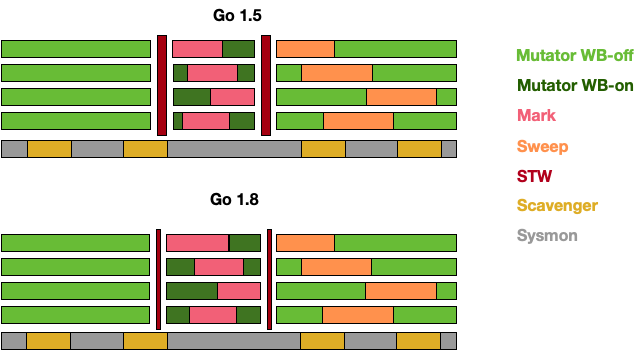 而到了 Go 1.5 后,Go 团队花费了相当大的力气,通过引入写屏障的机制来保证算法的一致性,才得以将整个 GC 控制在很小的 STW 内,而到了 1.8 时,由于新的混合屏障的出现,消除了对栈本身的重新扫描,STW 的时间进一步缩减。
而到了 Go 1.5 后,Go 团队花费了相当大的力气,通过引入写屏障的机制来保证算法的一致性,才得以将整个 GC 控制在很小的 STW 内,而到了 1.8 时,由于新的混合屏障的出现,消除了对栈本身的重新扫描,STW 的时间进一步缩减。
从这个时候开始,Scavenger 已经从独立线程中移除,并合并至系统监控这个独立的线程中,并周期性地向操作系统归还内存,但仍然会有内存溢出这种比较极端的情况出现,因为程序可能在短时间内应对突发性的内存申请需求时,内存还没来得及归还操作系统,导致堆不断向操作系统申请内存,从而出现内存溢出。
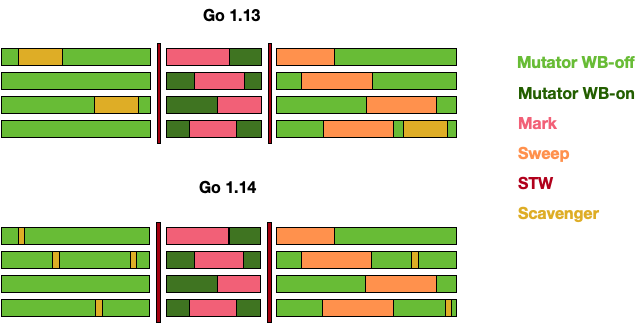
17. Go GC 在演化过程中还存在哪些其他设计?为什么没有被采用?
并发栈重扫
正如我们前面所说,允许灰色赋值器存在的垃圾回收器需要引入重扫过程来保证算法的正确性,除了引入混合屏障来消除重扫这一过程外,有另一种做法可以提高重扫过程的性能,那就是将重扫的过程并发执行。然而这一方案并没有得以实现,原因很简单:实现过程相比引入混合屏障而言十分复杂,而且引入混合屏障能够消除重扫这一过程,将简化垃圾回收的步骤。
ROC
ROC 的全称是面向请求的回收器(Request Oriented Collector),它其实也是分代 GC 的一种重新叙述。它提出了一个请求假设(Request Hypothesis):与一个完整请求、休眠 goroutine 所关联的对象比其他对象更容易死亡。这个假设听起来非常符合直觉,但在实现上,由于垃圾回收器必须确保是否有 goroutine 私有指针被写入公共对象,因此写屏障必须一直打开,这也就产生了该方法的致命缺点:昂贵的写屏障及其带来的缓存未命中,这也是这一设计最终没有被采用的主要原因。
传统分代 GC
在发现 ROC 性能不行之后,作为备选方案,Go 团队还尝试了实现传统的分代式 GC。但最终同样发现分代假设并不适用于 Go 的运行栈机制,年轻代对象在栈上就已经死亡,扫描本就该回收的执行栈并没有为由于分代假设带来明显的性能提升。这也是这一设计最终没有被采用的主要原因。
18. 目前提供 GC 的语言以及不提供 GC 的语言有哪些?GC 和 No GC 各自的优缺点是什么?
从原理上而言,所有的语言都能够自行实现 GC。从语言诞生之初就提供 GC 的语言,例如:
-
Python
-
JavaScript
-
Java
-
Objective-C
-
Swift
而不以 GC 为目标,被直接设计为手动管理内存、但可以自行实现 GC 的语言有:
-
C
-
C++
也有一些语言可以在编译期,依靠编译器插入清理代码的方式,实现精准的清理,例如:
-
Rust
垃圾回收使程序员无需手动处理内存释放,从而能够消除一些需要手动管理内存才会出现的运行时错误:
-
在仍然有指向内存区块的指针的情况下释放这块内存时,会产生悬挂指针,从而后续可能错误的访问已经用于他用的内存区域。
-
多重释放同一块申请的内存区域可能导致不可知的内存损坏。
当然,垃圾回收也会伴随一些缺陷,这也就造就了没有 GC 的一些优势:
-
没有额外的性能开销
-
精准的手动内存管理,极致的利用机器的性能
19. Go 对比 Java、V8 中 JavaScript 的 GC 性能如何?
无论是 Java 还是 JavaScript 中的 GC 均为分代式 GC。分代式 GC 的一个核心假设就是分代假说:将对象依据存活时间分配到不同的区域,每次回收只回收其中的一个区域。
V8 的 GC
在 V8 中主要将内存分为新生代和老生代。新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长、常驻内存、占用内存较大的对象:
-
新生代中的对象主要通过副垃圾回收器进行回收。该回收过程是一种采用复制的方式实现的垃圾回收算法,它将堆内存一分为二,这两个空间中只有一个处于使用中,另一个则处于闲置状态。处于使用状态的空间称为 From 空间,处于闲置的空间称为 To 空间。分配对象时,先是在 From 空间中进行分配,当开始垃圾回收时,会检查 From 空间中的存活对象,并将这些存活对象复制到 To 空间中,而非存活对象占用的空间被释放。完成复制后,From 空间和 To 空间的角色互换。也就是通过将存活对象在两个空间中进行复制。
-
老生代则由主垃圾回收器负责。它实现的是标记清扫过程,但略有不同之处在于它还会在清扫完成后对内存碎片进行整理,进而是一种标记整理的回收器。
Java 的 GC
Java 的 GC 称之为 G1,并将整个堆分为年轻代、老年代和永久代。包括四种不同的收集操作,从上往下的这几个阶段会选择性地执行,触发条件是用户的配置和实际代码行为的预测。
-
年轻代收集周期:只对年轻代对象进行收集与清理
-
老年代收集周期:只对老年代对象进行收集与清理
-
混合式收集周期:同时对年轻代和老年代进行收集与清理
-
完整 GC 周期:完整的对整个堆进行收集与清理
在回收过程中,G1 会对停顿时间进行预测,竭尽所能地调整 GC 的策略从而达到用户代码通过系统参数(
-XX:MaxGCPauseMillis
)所配置的对停顿时间的要求。
这四个周期的执行成本逐渐上升,优化得当的程序可以完全避免完整 GC 周期。
性能比较
在 Go、Java 和 V8 JavaScript 之间比较 GC 的性能本质上是一个不切实际的问题。如前面所说,垃圾回收器的设计权衡了很多方面的因素,同时还受语言自身设计的影响,因为语言的设计也直接影响了程序员编写代码的形式,也就自然影响了产生垃圾的方式。
但总的来说,他们三者对垃圾回收的实现都需要 STW,并均已达到了用户代码几乎无法感知到的状态(据 Go GC 作者 Austin 宣称 STW 小于 100 微秒)。当然,随着 STW 的减少,垃圾回收器会增加 CPU 的使用率,这也是程序员在编写代码时需要手动进行优化的部分,即充分考虑内存分配的必要性,减少过多申请内存带给垃圾回收器的压力。
20. 目前 Go 语言的 GC 还存在哪些问题?
尽管 Go 团队宣称 STW 停顿时间得以优化到 100 微秒级别,但这本质上是一种取舍。原本的 STW 某种意义上来说其实转移到了可能导致用户代码停顿的几个位置;除此之外,由于运行时调度器的实现方式,同样对 GC 存在一定程度的影响。
目前 Go 中的 GC 仍然存在以下问题:
1. Mark Assist 停顿时间过长
package mainimport ( "fmt" "os" "runtime" "runtime/trace" "time")const ( windowSize = 200000 msgCount = 1000000)var ( best time.Duration = time.Second bestAt time.Time worst time.Duration worstAt time.Time start = time.Now())func main() { f, _ := os.Create("trace.out") defer f.Close() trace.Start(f) defer trace.Stop() for i := 0; i < 5; i++ { measure() worst = 0 best = time.Second runtime.GC() }}func measure() { var c channel for i := 0; i < msgCount; i++ { c.sendMsg(i) } fmt.Printf("Best send delay %v at %v, worst send delay: %v at %v. Wall clock: %v \n", best, bestAt.Sub(start), worst, worstAt.Sub(start), time.Since(start))}type channel [windowSize][]bytefunc (c *channel) sendMsg(id int) { start := time.Now() // 模拟发送 (*c)[id%windowSize] = newMsg(id) end := time.Now() elapsed := end.Sub(start) if elapsed > worst { worst = elapsed worstAt = end } if elapsed < best { best = elapsed bestAt = end }}func newMsg(n int) []byte { m := make([]byte, 1024) for i := range m { m[i] = byte(n) } return m}运行此程序我们可以得到类似下面的结果:
$ go run main.goBest send delay 330ns at 773.037956ms, worst send delay: 7.127915ms at 579.835487ms. Wall clock: 831.066632ms Best send delay 331ns at 873.672966ms, worst send delay: 6.731947ms at 1.023969626s. Wall clock: 1.515295559s Best send delay 330ns at 1.812141567s, worst send delay: 5.34028ms at 2.193858359s. Wall clock: 2.199921749s Best send delay 338ns at 2.722161771s, worst send delay: 7.479482ms at 2.665355216s. Wall clock: 2.920174197s Best send delay 337ns at 3.173649445s, worst send delay: 6.989577ms at 3.361716121s. Wall clock: 3.615079348s
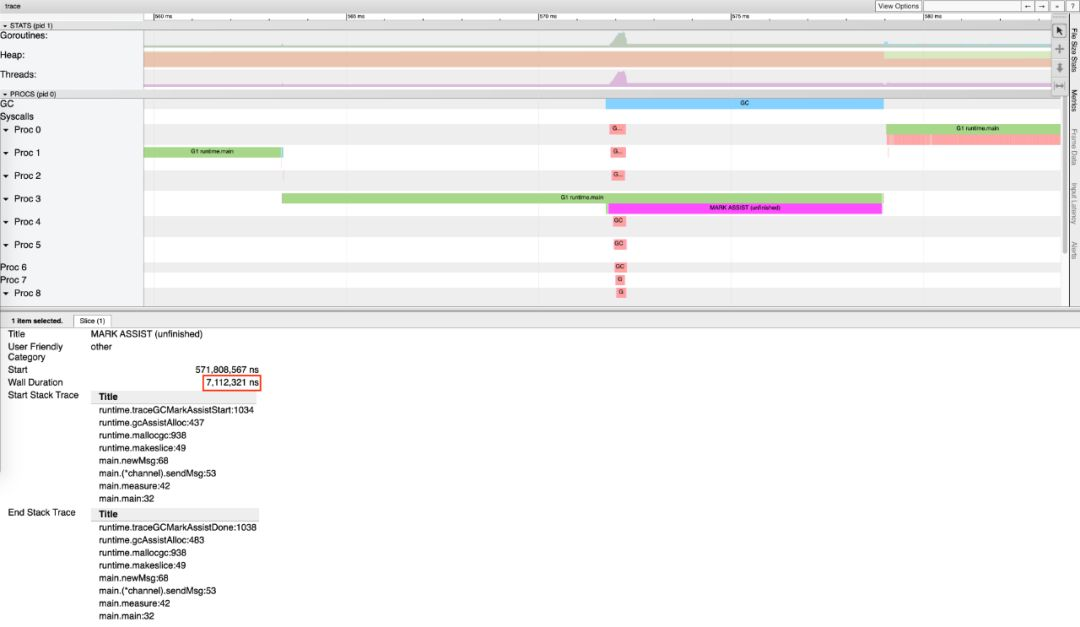
go
tool
trace
可以发现,这个时间段中,Mark Assist 执行了 7112312ns,约为 7.127915ms; 可见,此时最坏情况下,标记辅助拖慢了用户代码的执行,是造成 7 毫秒延迟的原因。
2. Sweep 停顿时间过长
同样还是刚才的例子,如果我们仔细观察 Mark Assist 后发生的 Sweep 阶段,竟然对用户代码的影响长达约 30ms,根据调用栈信息可以看到,该 Sweep 过程发生在内存分配阶段:
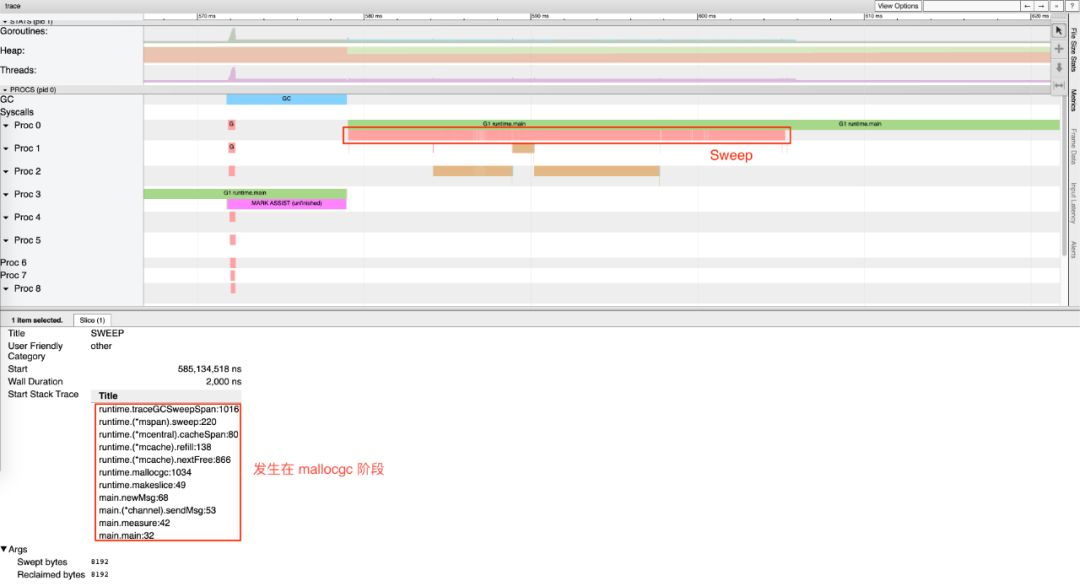
3. 由于 GC 算法的不正确性导致 GC 周期被迫重新执行
此问题很难复现,但是一个已知的问题,根据 Go 团队的描述,能够在 1334 次构建中发生一次,我们可以计算出其触发概率约为 0.0007496251874。虽然发生概率很低,但一旦发生,GC 需要被重新执行,非常不幸。
4. 创建大量 Goroutine 后导致 GC 消耗更多的 CPU
这个问题可以通过以下程序进行验证:
func BenchmarkGCLargeGs(b *testing.B) { wg := sync.WaitGroup{} for ng := 100; ng <= 1000000; ng *= 10 { b.Run(fmt.Sprintf("#g-%d", ng), func(b *testing.B) { // 创建大量 goroutine,由于每次创建的 goroutine 会休眠 // 从而运行时不会复用正在休眠的 goroutine,进而不断创建新的 g wg.Add(ng) for i := 0; i < ng; i++ { go func() { time.Sleep(100 * time.Millisecond) wg.Done() }() } wg.Wait() // 现运行一次 GC 来提供一致的内存环境 runtime.GC() // 记录运行 b.N 次 GC 需要的时间 b.ResetTimer() for i := 0; i < b.N; i++ { runtime.GC() } }) }}其结果可以通过如下指令来获得:
$ go test -bench=BenchmarkGCLargeGs -run=^$ -count=5 -v . | tee 4.txt$ benchstat 4.txtname time/opGCLargeGs/#g-100-12 192µs ± 5%GCLargeGs/#g-1000-12 331µs ± 1%GCLargeGs/#g-10000-12 1.22ms ± 1%GCLargeGs/#g-100000-12 10.9ms ± 3%GCLargeGs/#g-1000000-12 32.5ms ± 4%这种情况通常发生于峰值流量后,大量 goroutine 由于任务等待被休眠,从而运行时不断创建新的 goroutine,旧的 goroutine 由于休眠未被销毁且得不到复用,导致 GC 需要扫描的执行栈越来越多,进而完成 GC 所需的时间越来越长。一个解决办法是使用 goroutine 池来限制创建的 goroutine 数量。
总结
GC 是一个复杂的系统工程,本文讨论的二十个问题尽管已经展现了一个相对全面的 Go GC。但它们仍然只是 GC 这一宏观问题的一些较为重要的部分,还有非常多的细枝末节、研究进展无法在有限的篇幅内完整讨论。
从 Go 诞生之初,Go 团队就一直在对 GC 的表现进行实验与优化,但仍然有诸多未解决的问题,我们不妨对 GC 未来的改进拭目以待。
推荐阅读
【Why golang garbage-collector not implement Generational and Compact gc?】https://groups.google.com/forum/#!msg/golang-nuts/KJiyv2mV2pU/wdBUH1mHCAAJ 【写一个内存分配器】http://dmitrysoshnikov.com/compilers/writing-a-memory-allocator/#more-3590 【观察 GC】https://www.ardanlabs.com/blog/2019/05/garbage-collection-in-go-part2-gctraces.html 【煎鱼 Go debug】https://segmentfault.com/a/1190000020255157 【煎鱼 go tool trace】https://eddycjy.gitbook.io/golang/di-9-ke-gong-ju/go-tool-trace 【trace 讲解】https://www.itcodemonkey.com/article/5419.html 【An Introduction to go tool trace】https://about.sourcegraph.com/go/an-introduction-to-go-tool-trace-rhys-hiltner 【http pprof 官方文档】https://golang.org/pkg/net/http/pprof/ 【runtime pprof 官方文档】https://golang.org/pkg/runtime/pprof/ 【trace 官方文档】https://golang.org/pkg/runtime/trace/下面是彩蛋时间:
新建立了一个 免费 的知识星球, 大家可以在这里分享 Go 相关的面试、笔试经验,提出Go 相关的问题,分享 Go 相关的文章等等。
我也会邀请一些 业界大佬 来分享经验,解答问题。
当然,星球不会仅限于 Go,也不仅限于技术,任何能帮助大家在职场中成长的内容都欢迎分享。
最重要的是希望大家都能得到成长!成为更好的自己!
欧神和多位大佬已经在星球等你了,你不来吗?

