

我们都知道一般单值类别特征加入到CTR预估模型的方法是先对单值类别特征进行one-hot,然后和embedding 矩阵相乘转换成多维稠密特征,如下图 1 所示:
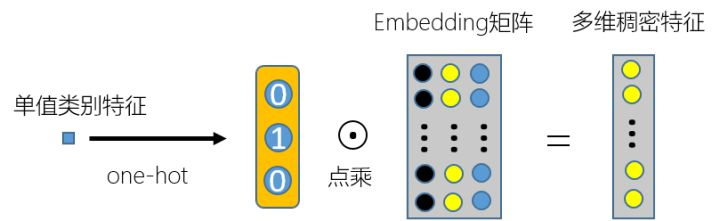 ▲ 图1. 单值类别特征处理方法
▲ 图1. 单值类别特征处理方法上一篇文章不为人知的稠密特征加入CTR预估模型的方法中又总结了稠密特征加入到CTR预估模型中的方法。而在现实实际问题中,往往还会出现多值类别特征,比如我接触到的2019腾讯广告算法大赛中用户的行为兴趣特征就是多值类别特征,也就是一个用户可以有多个类别的兴趣,比如打篮球,乒乓球和跳舞等,并且不同用户的兴趣个数不一样。还有2019知乎看山杯比赛中的用户感兴趣的话题特征,也就是一个用户感兴趣的话题可以有多个,并且不同的用户感兴趣的话题个数不一,这些特征的形式都一般是如下结构(拿用户感兴趣的话题特征来说):

在CTR预估模型中,对这种多值类别特征的常用处理方法总结归纳如下:
▌非加权法
最常规的也最简单的是先对所有‘话题’集合进行one hot编码,然后按照图 1 方式对多值类别特征中的每一项进行稠密特征的转换,最后对转换后的稠密特征向量进行拼接,然后按项求均值或最大值或最小值等,整个过程可以用如图 2 表示:
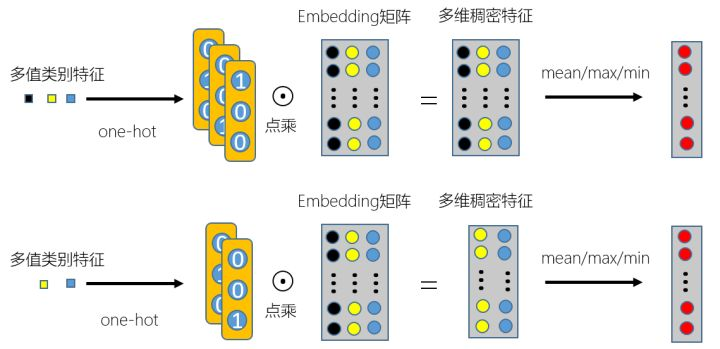
可以看出,这样对多值类别特征进行处理之后,可以把每个多值类别特征转换在同一维度空间中,这样输入到神经网络中不用为了保持输入维度一致而进行padding,使输入变稀疏,也方便和其他特征做交叉特征。
▌加权法
仔细一想,如果对多值类型特征直接求均值似乎不是很符合常理,毕竟用户对每个感兴趣话题的喜爱程度不一样,这就有了权重的引入,而不是简单粗暴的求均值了,具体引入权重的做法如图 3 示意图:
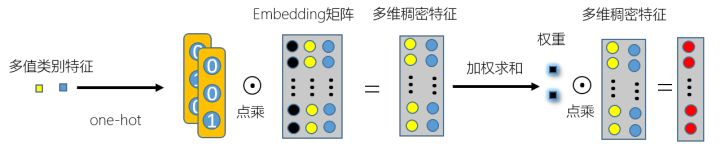
那么权重是怎样得来的,总结以下:
❶ 通过数据挖掘得到多值特征中每个值的权重
例如用户感兴趣话题这个多值类型特征的权重可以这样获得:用户在相关话题问题下回答问题的个数或相关话题回答点赞的次数,也就是回答相关话题问题的个数越多,表明越对该话题越感兴趣,权重越大;点赞相关话题回答的次数越多,表明越对该话题越感兴趣,权重越大。
❷ 通过神经网络自动学习多值特征中每个值的权重
1.借鉴论文FiBiNET[1]中把SE模块用在学习不同embedding vector权重的思想。主要过程如图 4 :
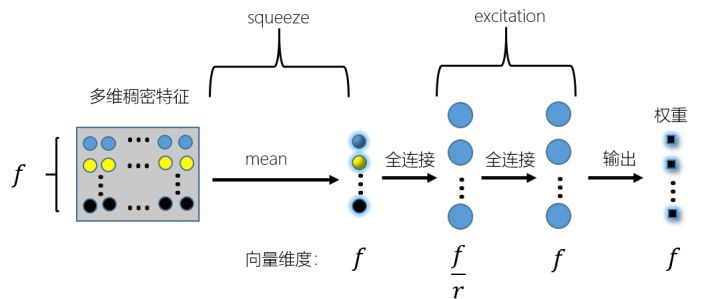
先对得到的多维稠密特征横向求均值,这部分在SE[2]模块中称作squeeze,也就是压缩的意思,然后再用两个全连接层进行全连接操作,这部分在SE模块中称作excitation,也就是激励提取的意思,最终的输出也就是学习得到的多值类别特征中每个值对应的权重。由于是针对多值类别特征的处理,因此这里在编程实现的时候需要按照max length 进行padding之后,再进行one hot编码等后续操作。
2.借鉴论文AutoInt[3]中学习transformer[4]注意力机制的思想来学习得到embedding vector ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/1/6/16f7ad58e525ab60~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 在Value空间上的权重信息。具体操作如图 5 所示,M是多值类别特征值的个数:
在Value空间上的权重信息。具体操作如图 5 所示,M是多值类别特征值的个数:
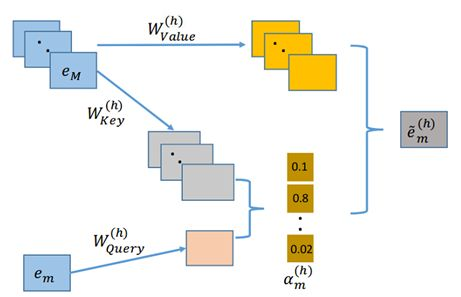
先通过矩阵乘法线性变换将每个投射到多个子空间中,分别是Query,Key和Value三个空间,计算公式分别如下:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/1/6/16f7ad58ea080826~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,
, ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/1/6/16f7ad58ea130be4~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,
, ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/1/6/16f7ad58ec20054d~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
然后计算当前与多值类别特征中其他embedding vector ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/1/6/16f7ad58ec3bb1e4~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 的相似度,即通过如下向量内积公式得到:
的相似度,即通过如下向量内积公式得到:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/1/6/16f7ad59355c7166~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
然后利用softmax对计算得到的相似度进行归一化,公式为:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/1/6/16f7ad5935ac7d73~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
该归一化后的值即为学习得到的每个在Value空间的权重,因此加权求和不是对加权,而是对映射到Value空间的特征进行加权求和,用公式表示如下:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/1/6/16f7ad593540afb0~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
总的来说,通过神经网络学习得到权重相比较通过数据挖掘得到权重来说计算复杂,计算量大,因此在选择时需要权衡一下。
除了多值类别特征,还有行为序列特征,他们的处理方法也有相似之处,可以互相借鉴学习,后面有时间介绍一些简单的行为序列特征的处理方法,感兴趣的可以关注一下公众号,精彩下期见~
▌参考文献
[1][FiBiNET] Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction (RecSys 2019)
[2][SENet] Squeeze-and-Excitation Networks (CVPR 2018)
[3][AutoInt] AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks (2018 arxiv)
[4][Transformer] Attention is all you need

