

背景
搜索推荐中需要结合用户的偏好特征对商品进行重排序,一个商品需要召回8个特征。理论上商品越多,rt越长。现有200个商品需要批量计算。 # 优化过程:
第一阶段:
刚开始按正向逻辑编写完代码,整个rt在800ms左右,平均到每个商品是4ms左右。对于一般的业务场景,这个rt算比较正常的,但还有优化空间
第二阶段:
使用arthas查看 每次查询特征都是redis,1ms不到。那就用多线程并发请求看看。理论上 4核的cpu,开4个线程,可以提升到200ms。然而在实测过程中,发现rt变长了达到了8000ms,进程直接卡死。 总结一下有两个原因: 1.forkJoin确实是并行在走,但对于每个商品的特征总长度有123个,200个就是246800个。join的过程反而会成为瓶颈 2.redis的server是单线程的nio,多线程查询不会带来实质上的性能优化
第三阶段:
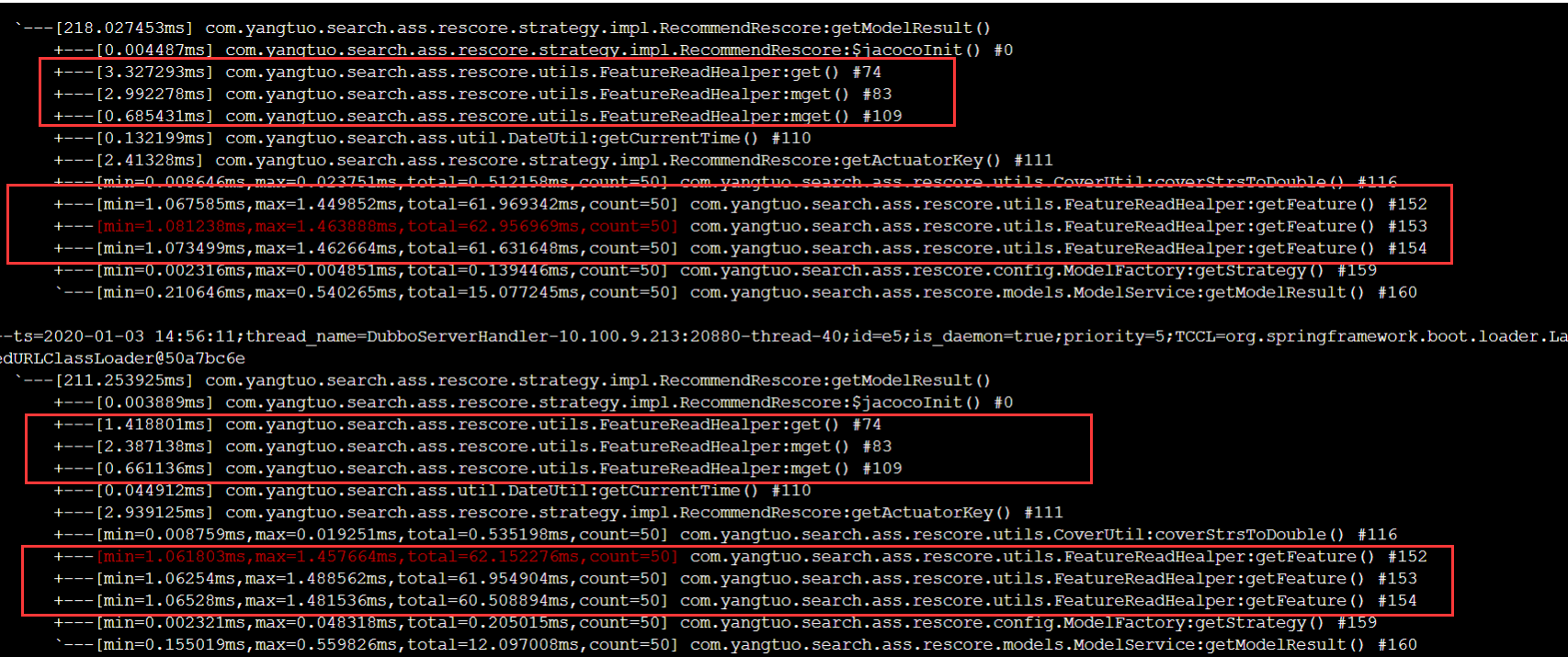
特征时间比较乱,有的是k-v结构,有的是hash结构。k-v结构的可以使用mget一次获取多个key,可以减少很大一部分消耗
经过优化,rt在300ms左右
第四阶段:
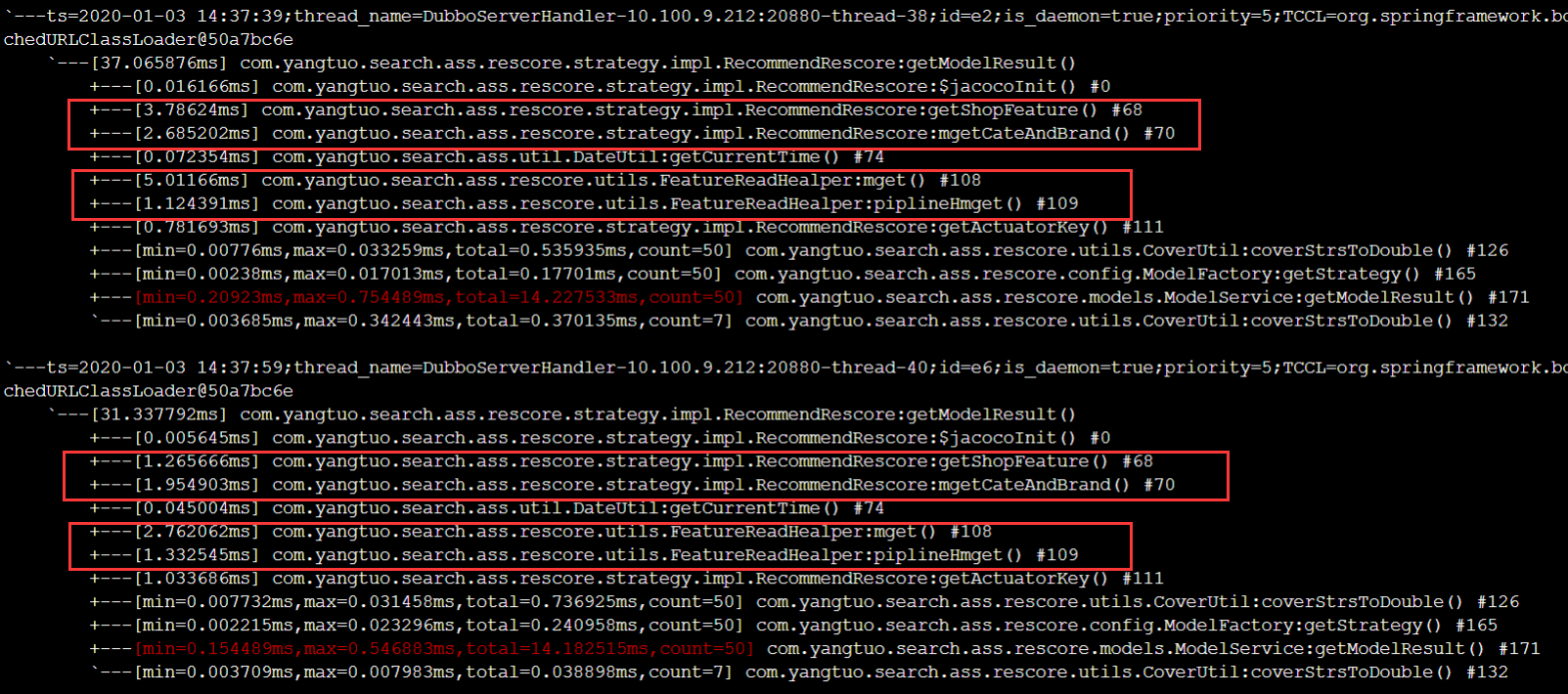
接下来优化hash结构的redis数据,这部分无法批量获取,但多次的redis的通信耗时表现在网络层。如果能减少这部分的时间,性能会有较大提升。于是用管道查询的方式,一次提交请求redis处理完以后,一次返回,rt在40ms左右。
结果:
最终,rt从一开始的800ms,提升到40ms。优化了20倍。
