

概念和简介
Spark Structured Streaming
Structured Streaming 是在 Spark 2.0 加入的经过重新设计的全新流式引擎。它使用 micro-batch 微批处理引擎,可以做到 100 毫秒的延迟以及 exactly-once 的容错保证。此外,Spark 2.3 增加了一个新的处理模式 Continuous Processing,可以做到 1 毫秒的延迟和 at-least-once 的容错保证。
由于 Structured Streaming 是大势所趋,本文将不介绍 Spark 1.0 中的 Spark Streaming。
是时候放弃 Spark Streaming, 转向 Structured Streaming 了
Datasets and DataFrames
DataFrames and Datasets 是 Spark SQL 中特有的概念。
Dataset 是一个分布数据的集合。你可以用 JVM 对象可以构造出一个 Dataset ,并通过函数 (map, flatMap, filter )改变它。Dataset API 在 Scala 和 Java 中都可用。
DataFrame 是 Dataset 组合成含有列的表格的抽象,它与关系型数据库中的表概念上很相似。你可以用结构化的文本文件,Hive中的表,外部数据库等等数据源来构造 DataFrame。DataFrame API 在 Scala,Java,Python 和 R 中都可用。
Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
Sources and Sinks
Structured Streaming Sources 输入支持情况
| Sources | 是否可重放 | 原生内置支持 | 注解 |
|---|---|---|---|
| HDFS-compatible file system | ✔️ | 已支持 | 包括但不限于 text, json, csv, parquet, orc, ... |
| Kafka | ✔️ | 已支持 | Kafka 0.10.0+ |
| RateStream | ✔️ | 已支持 | 以一定速率产生数据 |
| RDBMS | ✔️ | (待支持) | 预计后续很快会支持 |
| Socket | ✖️ | 已支持 | 主要用途是在技术会议/讲座上做 demo |
| Receiver-based | ✖️ | 不会支持 | Spark Streaming 中的 API,就让这些前浪被拍在沙滩上吧 |
Structured Streaming Sink 输出支持情况
| Sinks | 是否幂等写入 | 原生内置支持 | 注解 |
|---|---|---|---|
| HDFS-compatible file system | ✔️ | 已支持 | 包括但不限于 text, json, csv, parquet, orc, ... |
| ForeachSink (自定操作幂等) | ✔️ | 已支持 | 可定制度非常高的 sink |
| RDBMS | ✔️ | (待支持) | 预计后续很快会支持 |
| Kafka | ✖️ | 已支持 | Kafka 目前不支持幂等写入,所以可能会有重复写入 (但推荐接着 Kafka 使用 streaming de-duplication 来去重) |
| ForeachSink (自定操作不幂等) | ✖️ | 已支持 | 不推荐使用不幂等的自定操作 |
| Console | ✖️ | 已支持 | 主要用途是在技术会议/讲座上做 demo |
表格内容有可能随着 Spark 升级而发生变化,一切以官方的 Guide 为准
Structured Streaming Programming Guide
最简示例代码
val spark = SparkSession.builder().master("...").getOrCreate()
// 创建一个 SparkSession 程序入口
val lines = spark.readStream.textFile("some_dir")
// 将 some_dir 里的内容创建为 Dataset/DataFrame;即 input table
val words = lines.flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
// 对 "value" 列做 count,得到多行二列的 Dataset/DataFrame;即 result table
val query = wordCounts.writeStream
// 打算写出 wordCounts 这个 Dataset/DataFrame
.outputMode("complete")
// 打算写出 wordCounts 的全量数据
.format("console")
// 打算写出到控制台
.start()
// 新起一个线程开始真正不停写出
query.awaitTermination()
// 当前用户主线程挂住,等待新起来的写出线程结束
- Structured Streaming 也是先纯定义、再触发执行的模式,即
- 前面大部分代码是 纯定义 Dataset/DataFrame 的产生、变换和写出
spark.readStream.textFile()定义了 sources,这里是一个文本文件spark..outputMode("complete").format("console")定义了输出模式和 sink,这里是全量输出到控制台。
- 后面位置再真正
start一个新线程,去触发执行之前的定义
- 前面大部分代码是 纯定义 Dataset/DataFrame 的产生、变换和写出
- 在新的执行线程里需要 持续地 去发现新数据,进而 持续地 查询最新计算结果至写出
- 这个过程叫做 continous query(持续查询)
以上内容节选自 Structured Streaming 实现思路与实现概述。
与 Kafka 集成的例子
模拟场景
从 Kafka 中读取模拟实时交易的数据流,对 JSON 格式数据流进行处理(读取,计算一定时间窗口内的最高,最低,平局值,判断是否有异常值)并将结果输出至 Kafka 或控制台。
完整代码
StreamsProcessor:流式处理 Kafka 中的数据
SimpleProducer:向 Kafka 发送 JSON 数据
JSON 结构
运行构造并向 Kafka 发送数据的 SimpleProducer,得到 JSON 数据的结构:
{
"person": {
"firstName": "鹏",
"lastName": "廖",
"birthDate": "1963-07-12T09:12:19.014+0000"
},
"eventTime": "2019-11-25T09:38:25.361+0000",
"eventLocation": "农业大学",
"price": "4.60"
}
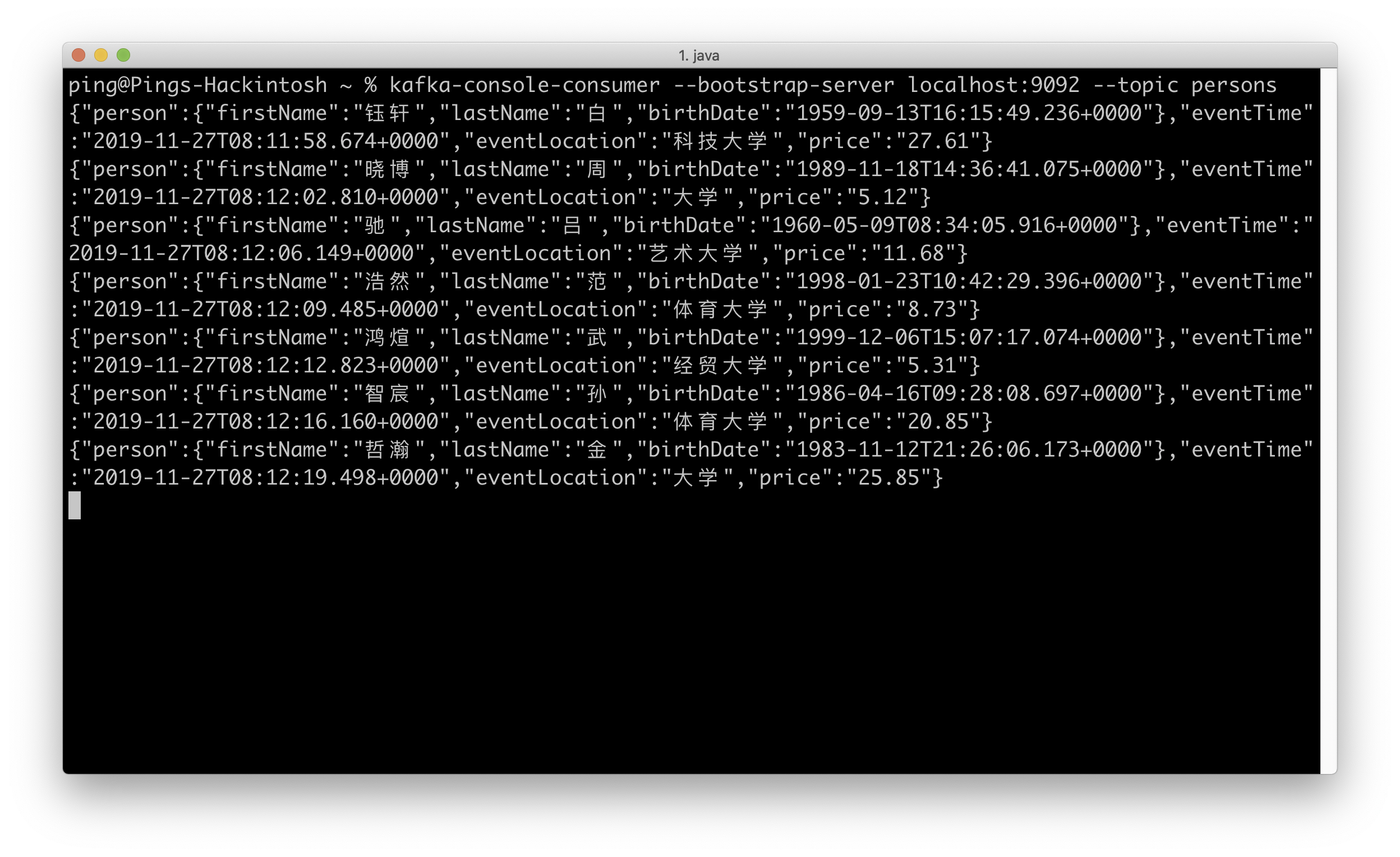
运行 kafka-console-consumer 可以读取到这些数据
读取,解析并扁平化
DataFrame 的 printSchema 方法可以输出结构,以下代码将结果以注释的形式展示:
- inputDf 是从 kafka 读入的 DataFrame,可以看到 kafka 特有的 topic, partition, offset 等列;我们这里只关心 value 列中的 JSON 字符串。
- personJsonDf 是使用
selectExpr("CAST(value AS STRING)")的结果,它只保留了 value 列,并将 binary 转换成 string 类型。 - 构造一个对应 JSON 的 StructType,并通过
select(from_json($"value", struct).as("data"))处理后,得到了一个含有原 JSON 树形结构的 Dataframe,即 personNestedDf。 - 使用
selectExpr方法将 personNestedDf 扁平化,得到 personFlattenedDf。
val inputDf = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", brokers)
.option("subscribe", Constants.personsTopic)
.load()
// print(inputDf.printSchema())
// root
// |-- key: binary (nullable = true)
// |-- value: binary (nullable = true)
// |-- topic: string (nullable = true)
// |-- partition: integer (nullable = true)
// |-- offset: long (nullable = true)
// |-- timestamp: timestamp (nullable = true)
// |-- timestampType: integer (nullable = true)
val personJsonDf = inputDf.selectExpr("CAST(value AS STRING)")
// print(personJsonDf.printSchema())
// root
// |-- value: string (nullable = true)
val struct = new StructType().add(
"person", new StructType()
.add("firstName", DataTypes.StringType)
.add("lastName", DataTypes.StringType)
.add("birthDate", DataTypes.StringType)
)
.add("eventTime", DataTypes.StringType)
.add("eventLocation", DataTypes.StringType)
.add("price", DataTypes.StringType)
val personNestedDf = personJsonDf.select(from_json($"value", struct).as("data"))
// print(personNestedDf.printSchema())
// root
// |-- data: struct (nullable = true)
// | |-- person: struct (nullable = true)
// | | |-- firstName: string (nullable = true)
// | | |-- lastName: string (nullable = true)
// | | |-- birthDate: string (nullable = true)
// | |-- eventTime: string (nullable = true)
// | |-- eventLocation: string (nullable = true)
// | |-- price: string (nullable = true)
val personFlattenedDf = personNestedDf.selectExpr("data.person.firstName", "data.person.lastName", "data.person.birthDate","data.eventTime","data.eventLocation","data.price")
// print(personFlattenedDf.printSchema())
// root
// |-- firstName: string (nullable = true)
// |-- lastName: string (nullable = true)
// |-- birthDate: string (nullable = true)
// |-- eventTime: string (nullable = true)
// |-- eventLocation: string (nullable = true)
// |-- price: string (nullable = true)
判断是否有异常值
这里使用了 filter 方法将所有 price 大于 20 的列取出,并将结果保存至两列,列 key = 名 + 空格 + 姓 ,列 value = 姓 + 名 + 空格 + 价格。
val filterDf = personFlattenedDf.filter("price > 20").select(concat($"firstName", lit(" "), $"lastName").as("key"),
concat($"lastName", $"firstName", lit(" "), $"price").as("value"))
基于时间窗口分组并使用聚合计算
这里使用 groupBy 以及 window 方法基于 eventTime 做时间分组;窗口间隔为 15 秒,滑动间隔为 10秒。使用 agg 方法以及内置的方法聚合计算窗口内的最大值、最小值、平均值、总数。
val windowedDf = personFlattenedDf.groupBy(
window($"eventTime", "15 seconds", "10 seconds").as("时间窗口"))
.agg(round(avg("price"),2).as("平均交易额"),
min("price").as("最低"),
max("price").as("最高"),
count("price").as("区间总数"))
输出结果
将时间窗口分组的结果 windowedDf 输出至控制台,将异常值结果输出 kafka 的主题 alerts。
注意:kafka 的 checkpointLocation 需要根据本地路径修改。另外,Kafka 目前不支持幂等写入,可能需要进一步去重。
val consoleOutput = windowedDf.writeStream
.outputMode("complete")
.format("console").option("truncate", "false")
.start()
val kafkaOutput = filterDf.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", brokers)
.option("topic", "alerts")
.option("checkpointLocation", "/Users/Ping/kafka-tutorials/spark/checkpoints")
.start()
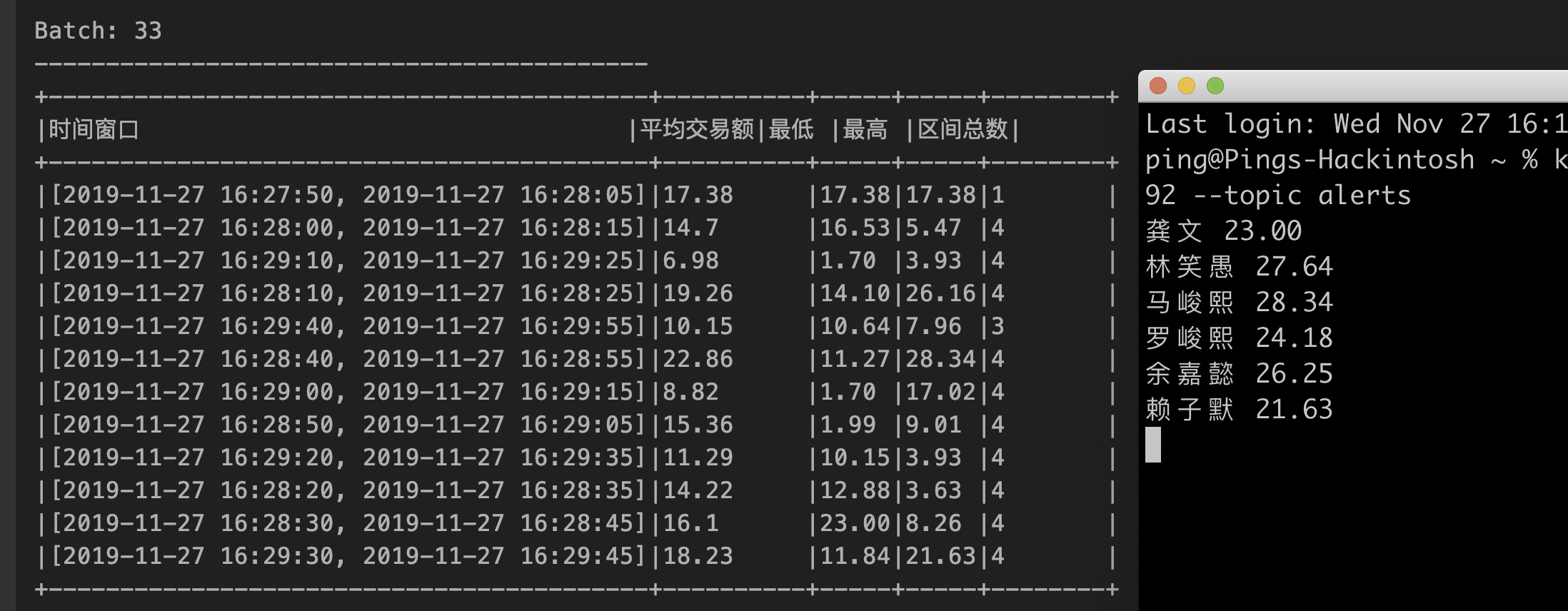
附录
Kafka & Zookeeper (macOS)
安装
brew install kafka
brew install zookeeper
运行
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties &
kafka-server-start /usr/local/etc/kafka/server.properties
创建主题
kafka-topics --zookeeper localhost:2181 --create --topic persons --replication-factor 1 --partitions 1
简单消费
kafka-console-consumer --bootstrap-server localhost:9092 --topic persons
