

什么是Category?
category是Objective-C 2.0之后的语言特性,我们通常称之为类别。他最主要的作用就是为已有的类增加方法,属性,协议等等,但是不能增加实例变量,当然,如果是增加属性的话,只会增加属性的声明,并不会生成属性的setter和getter方法。
因为Category的多种特性,所以在开发过程中Category的用法也多种多样,比如在组件化中,我们使用Category来区分各个组件的方法调用,典型的就是Casa大神的CTMediator,除此之外,我们还使用Category来为系统的类扩展出各种不同的工具方法,例如NSString、NSArray、NSDictionary等等,总之,Category在日常开发中不可或缺,那么除了会使用Category之外,Category的本质到底是什么呢?Category到底是如何为类增加方法和协议的呢?通过Category增加的方法和协议是在什么时机加入到原有类中的呢?下面我们会通过阅读源码来一一解答这些问题。
Category的底层结构
通过xcrun来查看编译之后的Category底层结构
我们知道,一个类的对象方法和协议是存放在类对象的方法列表和协议列表中的,而类方法则是存放在元类对象的方法列表中,而且这些方法和协议等等都是在编译时生成的,编译完成之后会存放到内存当中,等待开发者使用。而通过Category增加的方法和协议并不是在编译期就生成,而是在运行时动态的合并到类对象中,我们通过一个简单的Demo来查看一下Category的底层结构。
首先,创建一个XLPerson对象,然后为XLPerson对象增加一个Category,扩展出方法和属性等等,具体代码如下
#pragma mark - XLPerson
@interface XLPerson : NSObject
@end
@interface XLPerson (Test)
#pragma mark - XLPerson+Test
@property(nonatomic, copy)NSString *name;
- (void)run;
@end
@implementation XLPerson (Test)
- (void)run{
NSLog(@"%s", __func__);
}
@end
然后通过以下命令,将XLPerson+Test.m文件文件重写成XLPerson+Test.cpp文件,这个XLPerson+Test.cpp文件其实就相当于编译之后的产物
xcrun -sdk iphoneos clang -arch arm64 -rewrite-objc XLPerson+Test.m -o XLPerson+Test.cpp
_category_t
然后查看XLPerson+Test.cpp文件,可以得到Category在编译之后的结构如下,结构体中存放着方法列表、属性列表和协议列表等等
struct _category_t {
const char *name; //类名
struct _class_t *cls; //存放isa和superclass的结构体
const struct _method_list_t *instance_methods;//实例方法列表
const struct _method_list_t *class_methods;//类方法列表
const struct _protocol_list_t *protocols;//协议列表
const struct _prop_list_t *properties; //属性列表
};
在XLPerson+Test.cpp中,我们还可以找到一个名为OBJC$CATEGORY_XLPerson$_Test的静态结构体变量,它的成员如下:
static struct _category_t _OBJC_$_CATEGORY_XLPerson_$_Test __attribute__ ((used, section ("__DATA,__objc_const"))) =
{
"XLPerson",//类名,对应name
0, // &OBJC_CLASS_$_XLPerson,对应cls
(const struct _method_list_t *)&_OBJC_$_CATEGORY_INSTANCE_METHODS_XLPerson_$_Test, //实例方法列表
0,//类方法列表,此处未在Category中添加类方法,所以为0
0,//协议列表,此处未添加协议,所以为0
(const struct _prop_list_t *)&_OBJC_$_PROP_LIST_XLPerson_$_Test,//属性列表
};
由此可见在编译完成之后,每一个Category中的内容包括方法列表、属性列表等等,都会存放到一个_category_t类型的结构体变量中,而不是在编译时就直接合并到XLPerson类中去。
_method_list_t
然后我们再以_method_list_t为例,来窥探一下分类中实例方法的内部结构,如下
static struct /*_method_list_t*/ {
unsigned int entsize; // sizeof(struct _objc_method),方法的内存大小
unsigned int method_count; //参数的个数
struct _objc_method method_list[1];//方法的具体信息
} _OBJC_$_CATEGORY_INSTANCE_METHODS_XLPerson_$_Test __attribute__ ((used, section ("__DATA,__objc_const"))) = {
sizeof(_objc_method),
1,
{{(struct objc_selector *)"run", "v16@0:8", (void *)_I_XLPerson_Test_run}}
};
我们在分类中添加的实例方法,存放在了_objc_method类型的结构体中,在看一下_objc_method的内部结构如下
struct _objc_method {
struct objc_selector * _cmd; //方法selector
const char *method_type; //返回值类型
void *_imp; //方法实现的地址
};
再对比_method_list_t,可以得出,分类中增加的实例方法,编译之后会转换成_objc_method类型,内部存放着selector,返回值类型和方法实现,然后将转换后的_objc_method存放到结构体变量OBJC$CATEGORY_INSTANCE_METHODS_XLPerson$_Test中去。
由此我们可以得出结论,每个分类在编译完成之后都会生成一个_category_t类型的结构体变量,类似上文中的OBJC$CATEGORY_XLPerson$_Test,内部存放着我们在分类中定义的方法列表、属性列表和协议列表。
通过runtime源码来查看编译之后的Category底层结构
上文中,我们是通过将代码文件通过xcrun编译成cpp文件,然后来查看Category的底层结构,这种方式生成的代码仅供参考,真正的Category内部结构还得通过查看runtime源码来进行学习。可以通过objc4源码地址下载最新的runtime源码。
查看源码中的objc_runtime_new.h文件就可以看到Category的内部结构如下
struct category_t {
const char *name; //类名
classref_t cls; //cls
struct method_list_t *instanceMethods;//实例方法列表
struct method_list_t *classMethods; //类方法列表
struct protocol_list_t *protocols; //协议列表
struct property_list_t *instanceProperties; //属性列表
// Fields below this point are not always present on disk.
struct property_list_t *_classProperties;
method_list_t *methodsForMeta(bool isMeta) {
if (isMeta) return classMethods;
else return instanceMethods;
}
property_list_t *propertiesForMeta(bool isMeta, struct header_info *hi);
};
可以看出,在源码中Category的底层结构category_t和上文中我们得到的_category_t结构基本一致,这也验证了我们的观点,在编译之后,每个Category确实会生成一个category_t类型的结构体。
Category的加载流程
Category在编译时生成category_t类型的静态变量,然后在运行时合并到类中。下面我们就通过runtime的执行流程来查看Category的合并过程。
具体加载流程
- 首先,在objc-os.mm中找到runtime的入口,也就是_objc_init函数,它内部会通过dyld去注册images(模块)
void _objc_init(void)
{
static bool initialized = false;
if (initialized) return;
initialized = true;
// fixme defer initialization until an objc-using image is found?
environ_init();
tls_init();
static_init();
lock_init();
exception_init();
_dyld_objc_notify_register(&map_images, load_images, unmap_image);
}
_dyld_objc_notify_register函数中是直接通过map_images的内存地址调用map_images函数。
- 查看map_images函数,内部调用map_images_nolock函数
void map_images(unsigned count, const char * const paths[],
const struct mach_header * const mhdrs[])
{
mutex_locker_t lock(runtimeLock);
return map_images_nolock(count, paths, mhdrs);
}
- map_images_nolock函数是用来执行所有类注册和修复操作,并调用+load方法。,它内部会调用_read_iamges函数,核心代码如下
void _read_images(header_info **hList, uint32_t hCount, int totalClasses, int unoptimizedTotalClasses)
{
......
for (EACH_HEADER) {
//获取项目中所以的Category,得到一个二维数组
category_t **catlist =
_getObjc2CategoryList(hi, &count);
bool hasClassProperties = hi->info()->hasCategoryClassProperties();
//遍历二维数组,得到每一个category_t类型的结构体变量
for (i = 0; i < count; i++) {
category_t *cat = catlist[i];
//通过cat->cls拿到当前Category所属的类
Class cls = remapClass(cat->cls);
//判断class是否存在
bool classExists = NO;
//如果Category中存在实例方法,协议或者是实例属性
if (cat->instanceMethods || cat->protocols
|| cat->instanceProperties)
{
//将cls的未合并的所有Category存放到以cls为key的一个映射表中去
addUnattachedCategoryForClass(cat, cls, hi);
if (cls->isRealized()) {
//将Category中的方法、属性、协议等等附加到cls的实例方法列表、实例属性列表和协议列表中去
remethodizeClass(cls);
classExists = YES;
}
}
//如果Category中存在类方法,协议或者是类属性
if (cat->classMethods || cat->protocols
|| (hasClassProperties && cat->_classProperties))
{
addUnattachedCategoryForClass(cat, cls->ISA(), hi);
if (cls->ISA()->isRealized()) {
//将Category中的类方法、类属性、协议等等附加到cls的元类的类方法列表、类属性列表和协议列表中去
remethodizeClass(cls->ISA());
}
}
}
}
......
}
在内存中会维护着一张NXMapTable类型的映射表,他以cls为key,category_list为value。在编译之后将所有未进行合并的Category存放到category_list,然后存放到映射表中。等到合适的时机,会将所有的分类取出,将其中的方法、属性等等合并到类和元类中去。对应的addUnattachedCategoryForClass函数源码如下
static void addUnattachedCategoryForClass(category_t *cat, Class cls,
header_info *catHeader)
{
runtimeLock.assertLocked();
// DO NOT use cat->cls! cls may be cat->cls->isa instead
NXMapTable *cats = unattachedCategories();
category_list *list;
list = (category_list *)NXMapGet(cats, cls);
if (!list) {
list = (category_list *)
calloc(sizeof(*list) + sizeof(list->list[0]), 1);
} else {
list = (category_list *)
realloc(list, sizeof(*list) + sizeof(list->list[0]) * (list->count + 1));
}
list->list[list->count++] = (locstamped_category_t){cat, catHeader};
NXMapInsert(cats, cls, list);
}
- 继续查看上文中所提到的remethodizeClass函数,会发现remethodizeClass函数内部调用的attachCategories函数就是真正执行Category合并的核心代码,如下重要的代码可以对照注释进行查看。
//将方法列表、属性列表、协议列表附加到类中去
//假设cats中的所有的类别都是按顺序进行加载和排序的,最早装载进内存的类别是第一个
static void
attachCategories(Class cls, category_list *cats, bool flush_caches)
{
if (!cats) return;
if (PrintReplacedMethods) printReplacements(cls, cats);
//用来判断是否是元类
bool isMeta = cls->isMetaClass();
//申请连续内存空间,创建一个二维数组,里面存放着所有的method_list_t
method_list_t **mlists = (method_list_t **)
malloc(cats->count * sizeof(*mlists));
//申请连续内存空间,创建一个二维数组,里面存放着所有的property_list_t
property_list_t **proplists = (property_list_t **)
malloc(cats->count * sizeof(*proplists));
//申请连续内存空间,创建一个二维数组,里面存放着所有的protocol_list_t
protocol_list_t **protolists = (protocol_list_t **)
malloc(cats->count * sizeof(*protolists));
// Count backwards through cats to get newest categories first
int mcount = 0;
int propcount = 0;
int protocount = 0;
int i = cats->count;
bool fromBundle = NO;
//获取到category_list之后,通过逆序遍历来取出Category内部的方法、属性和协议列表
while (i--) {
auto& entry = cats->list[i];
//遍历cls所有的category_t,将category_t中的method_list_t取出,存放到二维数组mlists中
method_list_t *mlist = entry.cat->methodsForMeta(isMeta);
if (mlist) {
mlists[mcount++] = mlist;
fromBundle |= entry.hi->isBundle();
}
// 将category_t中的property_list_t取出,存放到二维数组proplists中
property_list_t *proplist =
entry.cat->propertiesForMeta(isMeta, entry.hi);
if (proplist) {
proplists[propcount++] = proplist;
}
//将category_t中的protocol_list_t取出,存放到二维数组protolists中
protocol_list_t *protolist = entry.cat->protocols;
if (protolist) {
protolists[protocount++] = protolist;
}
}
//拿到类对象cls的class_rw_t类型的成员data,它是可读可写的
auto rw = cls->data();
prepareMethodLists(cls, mlists, mcount, NO, fromBundle);
//将方法列表合并到rw的方法列表中去,并且插入到表头位置
rw->methods.attachLists(mlists, mcount);
free(mlists);
if (flush_caches && mcount > 0) flushCaches(cls);
//将属性列表合并到rw的属性列表中去,并且插入到表头位置
rw->properties.attachLists(proplists, propcount);
free(proplists);
//将协议列表合并到rw的协议列表中去,并且插入到表头位置
rw->protocols.attachLists(protolists, protocount);
free(protolists);
}
此处需要注意的是,每个类的Category附加的顺序和Category装载进内存的顺序有关,最先装载进内存的Category最后进行attach操作。至于class_rw_t和class_ro_t的区别可参考之前的文章。
- 通过逆序遍历获取到的方法列表、属性列表和协议列表,最后会通过attachLists函数合并到对应的class中去,核心代码如下:
void attachLists(List* const * addedLists, uint32_t addedCount) {
if (addedCount == 0) return;
//这里以方法列表为例
//array()->lists表示原来类中的方法列表
//addedLists表示所有Category中的方法列表
if (hasArray()) {
//获取原来类中方法列表的长度
uint32_t oldCount = array()->count;
//得到方法合并之后的新的数组长度
uint32_t newCount = oldCount + addedCount;
//给array重新分配长度为newCount的内存空间
setArray((array_t *)realloc(array(), array_t::byteSize(newCount)));
array()->count = newCount;
//将原来array()->lists中的数据移动到数组中oldCount的位置
//也就是相当于将array()->lists的数据在内存中往后移动了addedCount个位置
memmove(array()->lists + addedCount, array()->lists,
oldCount * sizeof(array()->lists[0]));
//将Category中的方法列表copy到array()->lists中
//并且是从数组的起始地址开始存放
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
else if (!list && addedCount == 1) {
// 0 lists -> 1 list
list = addedLists[0];
}
else {
// 1 list -> many lists
List* oldList = list;
uint32_t oldCount = oldList ? 1 : 0;
uint32_t newCount = oldCount + addedCount;
setArray((array_t *)malloc(array_t::byteSize(newCount)));
array()->count = newCount;
if (oldList) array()->lists[addedCount] = oldList;
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
}
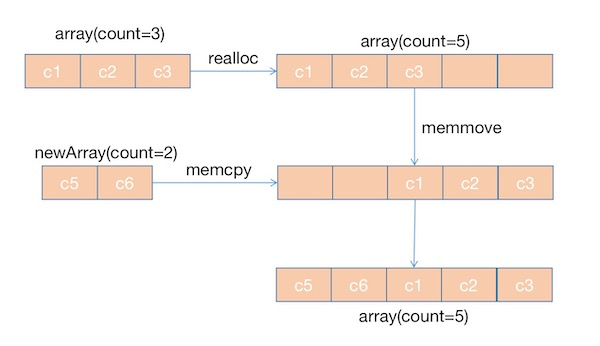
下面以合并方法列表为例,attachLists函数有两个参数addedLists和addedCount,addedLists表示所有Category中的方法列表。addedCount表示新增加的方法个数。addedLists中存放的内容如下:
addedLists:[[method_t, method_t],
[method_t, method_t],
[method_t, method_t],
......]
首先会通过原来类方法列表的长度和新添加方法列表的长度,得到合并之后的数组大小,然后重新为数组分配新的内存空间。然后调用memmove函数将原来array()->lists中的元素往后移动addedCount个位置,最后调用memcpy函数将addedLists中的元素复制到array()->lists中,从第0个位置开始存放。由此可以看出,所有分类中的方法,在合并到类原来的方法列表中时,是插入到原来的数据之前。
大致流程图如下:
总结
通过阅读runtime的源码,我们可以得出如下结论:
- 程序在编译完成之后,会将所有的Category转换成category_t类型的结构体
- 然后通过runtime加载某个类的所有Category数据,包括方法列表、属性列表和协议列表
- 把Category的方法列表、属性列表和协议列表存放到一个大的数组中去,这里需要注意的是,由于是逆序遍历,最先装载进内存的Category数据会存放到数组的最后面。
- 将合并后的分类数据(方法列表、属性列表和协议列表)通过memmove函数和memcpy函数插入到类原来的数据之前。因此,如果类和它的分类用于相同名称的方法,那么只会调用分类中的方法,不会调用父类中的方法。
OC的方法调用核心其实就是消息发送机制,方法底层会转换成objc_msgSend函数进行消息发送,如果当前类方法列表没有找到方法,会通过isa指针到元类对象的方法列表中查找,如果还没有找到会通过superClass到父类的方法列表中查找。一旦找到会立即执行方法。因此,一旦类和分类中有相同方法名的方法,分类的方法会放在类方法列表的最前面,当查找方法时,会直接拿到分类的方法执行。
Category补充
memmove和memcpy
memmove和memcpy两个函数的作用都是进行内存拷贝,唯一的区别就是当要拷贝的内存区域和目标内存区域有重叠部分的时候,memmove能够保证拷贝之后的结果是正确的,但是memcpy就不能保证拷贝之后的结果是正确的。
memmove
memmove的函数声明如下
void *memmove(void *dest, const void *src, size_t n);
memmove() 函数从src内存中拷贝n个字节到dest内存区域,但是源和目的的内存可以重叠,具体拷贝流程如下:
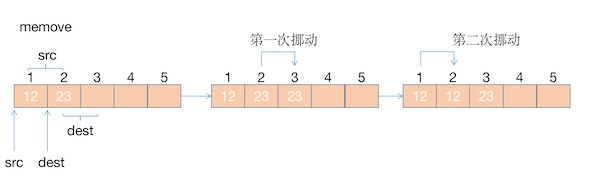
可以看到,src和dest的区域存在重叠部分,并且dest的区域在src的后面,所有在执行memmove操作时,会从src的最后一个内存中的元素开始,依次往后挪动,所以挪动完成之后就完成了拷贝操作,而且结果是正确的。
memcpy
memcpy的函数声明如下
void *memcpy(void *dest, const void *src, size_t n);
memcpy()函数从src内存中拷贝n个字节到dest内存区域,但是源和目的的内存区域不能重叠,具体拷贝流程如下
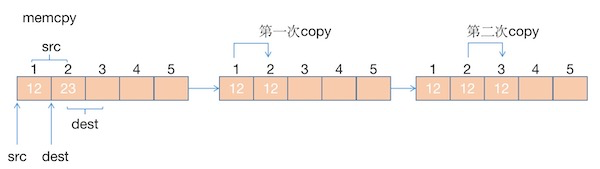
可以看到src和dest的区域存在重叠部分,在执行memcpy操作时,会从src起始内存地址开始,依次向后copy,在图中即表示为将src中第一个元素拷贝到dest第一个地址中,将src第二个元素拷贝到dest的第二个地址中,所以就造成了覆盖操作。
+load()方法
在OC中,+load()方法会在runtime加载类和分类到内存中的时候调用,而且每个类或者分类的+load()方法只会调用一次。而且如果同时存在子类和分类的情况下,会先调用父类的+load()方法,再调用子类的+load()方法,最后调用分类的+load()方法。下面我们通过源码来验证这一结论。
- 首先,我们还是同上文一样,找到_objc_init函数,此处是runtime的入口函数,省略了部分代码,只保留我们需要的代码。_objc_init函数中的load_images函数就是用来执行所有类的+load()方法。
void _objc_init(void)
{
......
_dyld_objc_notify_register(&map_images, load_images, unmap_image);
}
- 继续查看load_images的源码如下,通过注释我们能发现prepare_load_methods函数用来发现所有的+load()方法,而call_load_methods函数则用来调用所有的+load()方法。
void load_images(const char *path __unused, const struct mach_header *mh)
{
// Return without taking locks if there are no +load methods here.
if (!hasLoadMethods((const headerType *)mh)) return;
recursive_mutex_locker_t lock(loadMethodLock);
// Discover load methods
{
mutex_locker_t lock2(runtimeLock);
prepare_load_methods((const headerType *)mh);
}
// Call +load methods (without runtimeLock - re-entrant)
call_load_methods();
}
Discover load methods
- 查看prepare_load_methods函数,发现它内部是通过调用_getObjc2NonlazyClassList函数来获取到所有不是懒加载的类,由于_getObjc2NonlazyClassList不开源,所以我们猜测通过这个函数获取到的classlist它的顺序和类编译的顺序相同。
void prepare_load_methods(const headerType *mhdr)
{
size_t count, i;
runtimeLock.assertLocked();
classref_t *classlist =
_getObjc2NonlazyClassList(mhdr, &count);
for (i = 0; i < count; i++) {
schedule_class_load(remapClass(classlist[i]));
}
category_t **categorylist = _getObjc2NonlazyCategoryList(mhdr, &count);
for (i = 0; i < count; i++) {
category_t *cat = categorylist[i];
Class cls = remapClass(cat->cls);
if (!cls) continue; // category for ignored weak-linked class
if (cls->isSwiftStable()) {
_objc_fatal("Swift class extensions and categories on Swift "
"classes are not allowed to have +load methods");
}
realizeClassWithoutSwift(cls);
assert(cls->ISA()->isRealized());
add_category_to_loadable_list(cat);
}
}
- 当获取到所有类的集合之后,通过遍历来调用schedule_class_load函数来递归调度类的+load方法和所有它的父类的+load方法,而且通过schedule_class_load(cls->superclass);这句可以看出,在调度+load方法是,是先父类再子类的顺序,如下
static void schedule_class_load(Class cls)
{
if (!cls) return;
assert(cls->isRealized()); // _read_images should realize
if (cls->data()->flags & RW_LOADED) return;
// Ensure superclass-first ordering
schedule_class_load(cls->superclass);
add_class_to_loadable_list(cls);
cls->setInfo(RW_LOADED);
}
- 查看add_class_to_loadable_list函数源码,可以发现通过递归来调度的类以及它的+load方法最后被添加到了一个全局的loadable_classes列表中去了,这个列表中存放的是所有需要被调用+load方法的类,所有的类都被包装成了struct loadable_class类型的结构体。
struct loadable_class {
Class cls; // may be nil
IMP method;
};
void add_class_to_loadable_list(Class cls)
{
IMP method;
loadMethodLock.assertLocked();
method = cls->getLoadMethod();
if (!method) return; // Don't bother if cls has no +load method
if (PrintLoading) {
_objc_inform("LOAD: class '%s' scheduled for +load",
cls->nameForLogging());
}
if (loadable_classes_used == loadable_classes_allocated) {
loadable_classes_allocated = loadable_classes_allocated*2 + 16;
loadable_classes = (struct loadable_class *)
realloc(loadable_classes,
loadable_classes_allocated *
sizeof(struct loadable_class));
}
loadable_classes[loadable_classes_used].cls = cls;
loadable_classes[loadable_classes_used].method = method;
loadable_classes_used++;
}
这里有个注意点,因为是通过递归来添加,所以父类总是会优先调用add_class_to_loadable_list函数,因此在loadable_classes中,父类总是存放在最前面。而且通过查看结构体loadable_class可以发现,它内部是直接存放了IMP类型的成员变量,也就是说直接保存的+load方法的内存地址,后续可以直接通过内存地址来调用+load方法
- 加载完所有类的+load方法之后,接下来会加载所有分类的+load方法,分类同类一样,也是通过内部函数_getObjc2NonlazyCategoryList获取到项目中所有的分类列表,然后通过遍历调用add_category_to_loadable_list函数,将分类中的+load方法加到全局的list中去。如下
void add_category_to_loadable_list(Category cat)
{
IMP method;
loadMethodLock.assertLocked();
......
method = _category_getLoadMethod(cat);
if (loadable_categories_used == loadable_categories_allocated) {
loadable_categories_allocated = loadable_categories_allocated*2 + 16;
loadable_categories = (struct loadable_category *)
realloc(loadable_categories,
loadable_categories_allocated *
sizeof(struct loadable_category));
}
loadable_categories[loadable_categories_used].cat = cat;
loadable_categories[loadable_categories_used].method = method;
loadable_categories_used++;
}
此处将所有的分类以及它的+load方法封装成了一个struct loadable_category类型的结构体,然后存放到全局的struct loadable_categories列表中去,实现方法和上文中类的方式相同,唯一不同的是Category的加载不是通过递归来进行的。
- 此时在全局列表loadable_classes和loadable_categories中就存放了所有需要调用+load方法的类和分类的信息,而且类和它的+load方法直接存放在了struct loadable_class中,而分类和它的+load方法则直接存放在了struct loadable_category中。
Call +load methods
经过prepare_load_methods函数之后,所有类和分类的+load方法分别存放到了loadable_classes和loadable_categories中,之后通过调用call_load_methods函数对所有的+load方法进行调用
- 查看call_load_methods的源码,发现是通过call_class_loads来调用所有类的+load方法,通过call_category_loads函数来调用所有分类的+load方法
void call_load_methods(void)
{
static bool loading = NO;
bool more_categories;
loadMethodLock.assertLocked();
// Re-entrant calls do nothing; the outermost call will finish the job.
if (loading) return;
loading = YES;
void *pool = objc_autoreleasePoolPush();
do {
// 1. Repeatedly call class +loads until there aren't any more
while (loadable_classes_used > 0) {
call_class_loads();
}
// 2. Call category +loads ONCE
more_categories = call_category_loads();
// 3. Run more +loads if there are classes OR more untried categories
} while (loadable_classes_used > 0 || more_categories);
objc_autoreleasePoolPop(pool);
loading = NO;
}
此处有个objc_autoreleasePoolPush()函数和objc_autoreleasePoolPop()函数,这两个函数的作用其实就是创建一个自动释放池autoreleasepool,有兴趣的可以查看自动释放池的底层实现。
- 首先查看call_class_loads函数的源码,发现其实就是拿到上文所说的全局列表loadable_classes,然后通过遍历拿到里面的loadable_class,依次取出cls和+load方法的内存地址,直接调用+load方法
static void call_class_loads(void)
{
int i;
// Detach current loadable list.
struct loadable_class *classes = loadable_classes;
int used = loadable_classes_used;
loadable_classes = nil;
loadable_classes_allocated = 0;
loadable_classes_used = 0;
// Call all +loads for the detached list.
for (i = 0; i < used; i++) {
Class cls = classes[i].cls;
load_method_t load_method = (load_method_t)classes[i].method;
if (!cls) continue;
if (PrintLoading) {
_objc_inform("LOAD: +[%s load]\n", cls->nameForLogging());
}
(*load_method)(cls, SEL_load);
}
// Destroy the detached list.
if (classes) free(classes);
}
- call_category_loads函数的实现方式和call_class_loads函数基本相同。
总结
- +load方法是在runtime加载类、分类是进行调用的
- 每个类、分类的+load方法,在程序运行过程中只会调用一次
- 如果存在多个子类,则会先调用父类的+load方法,再调用子类的+load方法,子类+load方法的调用顺序和子类的编译顺序相同,先编译的子类优先调用
- 如果同时存在多个分类和多个子类,那么首先会调用父类的+load方法,再调用子类的+load方法,最后才会调用分类的+load方法,多个分类+load方法的调用顺序和编译顺序相同,先编译的分类先调用。
- 不管是类还是分类,+load方法都是通过直接拿到方法的内存地址进行调用,而不是通过消息发送机制来调用
+initialize()方法
+initialize执行时机
+initialize方法会在类第一次接收到消息的时候调用,也就是说当我们调用+initialize方法时,最后都会转换成objc_msgSend(obj, @selector(initialize)),所以想要查看+initialize方法的调用流程,就可以查看runtime进行方法查找的源码。具体查看objc-runtime-new.mm下的class_getInstanceMethod函数,这个函数就是用来查找某一个类下的实例方法
Method class_getInstanceMethod(Class cls, SEL sel)
{
if (!cls || !sel) return nil;
#warning fixme build and search caches
// Search method lists, try method resolver, etc.
lookUpImpOrNil(cls, sel, nil,
NO/*initialize*/, NO/*cache*/, YES/*resolver*/);
#warning fixme build and search caches
return _class_getMethod(cls, sel);
}
- 通过lookUpImpOrNil函数来查找类的方法列表,在函数内部又通过lookUpImpOrForward函数来进行方法查找
IMP lookUpImpOrNil(Class cls, SEL sel, id inst,
bool initialize, bool cache, bool resolver)
{
IMP imp = lookUpImpOrForward(cls, sel, inst, initialize, cache, resolver);
if (imp == _objc_msgForward_impcache) return nil;
else return imp;
}
- 继续查看lookUpImpOrForward函数的源码,找到其中的核心代码,如果函数参数initialize为YES并且当前类没有进行过初始化,则会调用initializeAndLeaveLocked函数。
IMP lookUpImpOrForward(Class cls, SEL sel, id inst,
bool initialize, bool cache, bool resolver)
{
......
//当参数initialize为YES,并且cls没有进行过Initialized操作
if (initialize && !cls->isInitialized()) {
cls = initializeAndLeaveLocked(cls, inst, runtimeLock);
}
......
}
- 查看initializeAndLeaveLocked函数发现它的内部会调用initializeAndMaybeRelock函数来获取cls的类对象,并且通过isRealized判断当前类是否初始化。
static Class initializeAndMaybeRelock(Class cls, id inst,
mutex_t& lock, bool leaveLocked)
{
lock.assertLocked();
assert(cls->isRealized());
if (cls->isInitialized()) {
if (!leaveLocked) lock.unlock();
return cls;
}
Class nonmeta = getMaybeUnrealizedNonMetaClass(cls, inst);
//isRealized()方法用来判断当前类中cls->data是class_rw_t还是class_ro_t
//也就是判断类是否被初始化
if (nonmeta->isRealized()) {
lock.unlock();
} else {
nonmeta = realizeClassMaybeSwiftAndUnlock(nonmeta, lock);
cls = object_getClass(nonmeta);
}
// runtimeLock is now unlocked, for +initialize dispatch
assert(nonmeta->isRealized());
//调用+initialize方法
initializeNonMetaClass(nonmeta);
if (leaveLocked) runtimeLock.lock();
return cls;
}
- 最后,initializeNonMetaClass函数就是最核心的函数,它的作用就是根据需要向任意的未初始化的类发送一个“+initialize”消息,并且会首先执行超类的初始化,具体实现查看以下源码,源码中省略了部分关于初始化状态设置的一些代码,保留了核心的函数调用,如果想看完整代码,可以自行查看最新的objc4的源码
void initializeNonMetaClass(Class cls)
{
assert(!cls->isMetaClass());
Class supercls;
bool reallyInitialize = NO;
//此处通过cls->superclass来找到cls的父类,然后通过递归来查看父类是否被初始化,从而确保在初始化cls之前,它的父类已经初始化完毕
supercls = cls->superclass;
if (supercls && !supercls->isInitialized()) {
initializeNonMetaClass(supercls);
}
{
monitor_locker_t lock(classInitLock);
//如果当前类并未初始化,则设置类的状态为“正在初始化”
if (!cls->isInitialized() && !cls->isInitializing()) {
cls->setInitializing();
reallyInitialize = YES;
}
}
......
//如果当前的类未进行初始化,则调用callInitialize进行初始化
if (reallyInitialize) {
callInitialize(cls);
return;
}
......
}
- 可以看到,首先会通过递归找到cls的父类,判断父类是否进行过初始化,如果父类未进行初始化,则通过callInitialize函数调用父类的+initialize,然后再调用子类的+initialize。并且callInitialize内部其实也是通过objc_msgSend来发送+initialize消息。
总结
- +initialize方法是在类第一次接收到消息时调用
- 如果存在多个子类,并且实现了+initialize方法,会先初始化父类,调用父类的+initialize方法,然后再初始化子类,调用子类的+initialize方法
- 如果子类没有实现+initialize方法,则会调用父类的+initialize方法,所以父类的+initialize可能会被调用多次。
- 如果分类实现了+initialize方法,则会覆盖类本身的+initialize调用,因为+initialize方法的调用本质上是通过objc_msgSend来发送一个+initialize消息,所以一旦分类实现了+initialize方法,则会将分类的+initialize方法插入到类方法列表的最前面,会覆盖原来类的+initialize方法。
给分类添加成员变量?(关联对象)
默认情况下,由于分类的底层结构的限制,不能在分类中添加成员变量,但是我们可以通过runtime提供的Api为类增加关联对象。
关联对象的实现
关联对象主要通过以下三个函数进行实现
- 添加关联对象
void objc_setAssociatedObject(id object, const void * key,
id value, objc_AssociationPolicy policy)
- 获取关联对象
id objc_getAssociatedObject(id object, const void * key)
- 移除所有的关联对象
void objc_removeAssociatedObjects(id object)
以一个简单的例子来看关联对象的实现
@interface XLPerson (Test)
@property(nonatomic, copy)NSString *name;
@end
@implementation XLPerson (Test)
- (NSString *)name{
return objc_getAssociatedObject(self, _cmd);
}
- (void)setName:(NSString *)name{
objc_setAssociatedObject(self, @selector(name), name, OBJC_ASSOCIATION_COPY);
}
@end
这里key需要传入一个内存地址,可以自己定义,只要保证在setter和getter中用的是相同的key就行。最常用的方式就是使用当前getter方法的内存地址,也就是上文中的@selector(name),_cmd其实和@selector(name)等同,都是表示指向name()方法的指针。
- 使用关联对象时会用到objc_AssociationPolicy,它其实和我们OC中的属性修饰符一一对应,使用什么修饰符,取决于你定义的属性的类型,对应关系如下
| objc_AssociationPolicy | 修饰符 |
|---|---|
| OBJC_ASSOCIATION_ASSIGN | assign |
| OBJC_ASSOCIATION_RETAIN_NONATOMIC | strong, nonatomic |
| OBJC_ASSOCIATION_COPY_NONATOMIC | copy, nonatomic |
| OBJC_ASSOCIATION_RETAIN | strong, atomic |
| OBJC_ASSOCIATION_COPY | copy, atomic |
关联对象的实现原理
objc_setAssociatedObject
了解了关联对象的使用,接着我们通过runtime源码来更深层次的了解关联对象的实现原理。
- 首先在objc-runtime.mm文件中找到objc_setAssociatedObject函数调用
void objc_setAssociatedObject(id object, const void *key, id value, objc_AssociationPolicy policy) {
_object_set_associative_reference(object, (void *)key, value, policy);
}
- 再次查看_object_set_associative_reference函数,就能看到完整的设置关联对象的流程
void _object_set_associative_reference(id object, void *key, id value, uintptr_t policy) {
if (!object && !value) return;
// retain the new value (if any) outside the lock.
ObjcAssociation old_association(0, nil);
id new_value = value ? acquireValue(value, policy) : nil;
{
//关联对象的管理类
AssociationsManager manager;
//关联对象的哈希表,里面存放着的key为object的地址,value为ObjectAssociationMap类型的映射表
AssociationsHashMap &associations(manager.associations());
//通过DISGUISE,传入object,计算出所需要的disguised_object值
disguised_ptr_t disguised_object = DISGUISE(object);
if (new_value) {
//如果传过来的value有值,通过object计算出来的disguised_object,到哈希表中找到对应的ObjectAssociationMap类型的映射表
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
//找到object对应的映射表
ObjectAssociationMap *refs = i->second;
//通过传递过来的key,到refs中找到对应的ObjcAssociation对象
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
//这里保留旧的ObjcAssociation对象,之后需要释放
old_association = j->second;
//通过policy和new_value创建新的ObjcAssociation对象,替换映射表中旧的对象
j->second = ObjcAssociation(policy, new_value);
} else {
//如果通过key未找到对应的ObjcAssociation对象,则新建一个ObjcAssociation对象插入到映射表中
(*refs)[key] = ObjcAssociation(policy, new_value);
}
} else {
//如果通过disguised_object找不到对应的映射表,则创建新的映射表插入到哈希表associations中
ObjectAssociationMap *refs = new ObjectAssociationMap;
associations[disguised_object] = refs;
//创建新的ObjcAssociation对象存放到映射表中
(*refs)[key] = ObjcAssociation(policy, new_value);
object->setHasAssociatedObjects();
}
} else {
//如果传递过来的value为ni,则通过disguised_object查找到object对应的映射表
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
ObjectAssociationMap *refs = i->second;
//遍历映射表,找到key对应的ObjcAssociation,执行擦除操作
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
old_association = j->second;
refs->erase(j);
}
}
}
}
//如果存在旧的ObjcAssociation对象,则释放旧的对象
if (old_association.hasValue()) ReleaseValue()(old_association);
}
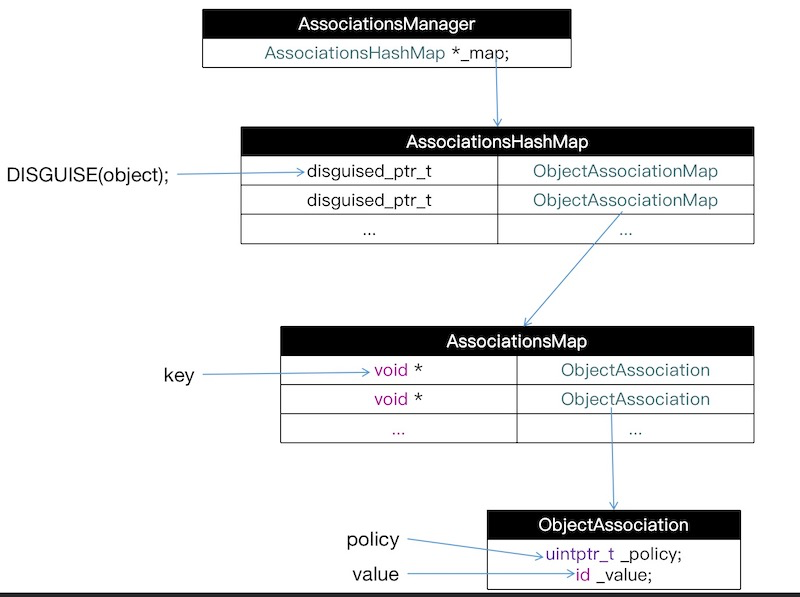
上述源码中,有几个非常重要的类,AssociationsManager、AssociationsHashMap、ObjectAssociationMap、ObjcAssociation
- 首先AssociationsManager是一个关联对象的管理类,它内部有一个AssociationsHashMap类型的静态变量
class AssociationsManager {
// associative references: object pointer -> PtrPtrHashMap.
static AssociationsHashMap *_map;
public:
//构造函数
AssociationsManager() { AssociationsManagerLock.lock(); }
//析构函数
~AssociationsManager() { AssociationsManagerLock.unlock(); }
AssociationsHashMap &associations() {
if (_map == NULL)
_map = new AssociationsHashMap();
return *_map;
}
};
- AssociationsHashMap是一个哈希表,通过当前的object调用DISGUISE(object)来得到索引值,然后通过索引值来获取或者存放ObjectAssociationMap类型的映射表。
//关联对象哈希表disguised_ptr_t表示索引,ObjectAssociationMap则存放着所有关联对象的具体信息
class AssociationsHashMap : public unordered_map<disguised_ptr_t, ObjectAssociationMap *, DisguisedPointerHash, DisguisedPointerEqual, AssociationsHashMapAllocator> {
public:
void *operator new(size_t n) { return ::malloc(n); }
void operator delete(void *ptr) { ::free(ptr); }
};
- ObjectAssociationMap是一个映射表,是以参数中传过来的key值作为映射表的key,以ObjcAssociation类型的对象作为映射表的value
//映射表的key是void *类型,value是ObjcAssociation类型的对象
class ObjectAssociationMap : public std::map<void *, ObjcAssociation, ObjectPointerLess, ObjectAssociationMapAllocator> {
public:
void *operator new(size_t n) { return ::malloc(n); }
void operator delete(void *ptr) { ::free(ptr); }
};
- ObjcAssociation对象中其实只有两个属性,_policy和_value,分别对应参数中的value和policy。
class ObjcAssociation {
uintptr_t _policy; //策略
id _value; //当前关联对象的值
public:
ObjcAssociation(uintptr_t policy, id value) : _policy(policy), _value(value) {}
ObjcAssociation() : _policy(0), _value(nil) {}
uintptr_t policy() const { return _policy; }
id value() const { return _value; }
bool hasValue() { return _value != nil; }
};
objc_getAssociatedObject
相对于objc_setAssociatedObject函数来说,objc_getAssociatedObject的实现要简单的多
id objc_getAssociatedObject(id object, const void *key) {
return _object_get_associative_reference(object, (void *)key);
}
- 查看核心函数_object_get_associative_reference的实现如下
id _object_get_associative_reference(id object, void *key) {
id value = nil;
//策略默认是OBJC_ASSOCIATION_ASSIGN
uintptr_t policy = OBJC_ASSOCIATION_ASSIGN;
{
//拿到manager中的哈希表
AssociationsManager manager;
AssociationsHashMap &associations(manager.associations());
//通过object生成哈希表的索引
disguised_ptr_t disguised_object = DISGUISE(object);
//通过索引disguised_object去哈希表中找到object对应的映射表
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
ObjectAssociationMap *refs = i->second;
//通过传递过来的key去映射表中找到对应的ObjcAssociation类型的关联对象
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
//获取到ObjcAssociation类型的对象,拿到其中存储的value和policy
ObjcAssociation &entry = j->second;
value = entry.value();
policy = entry.policy();、
//如果是OBJC_ASSOCIATION_GETTER_RETAIN策略,则对value进行一次retain操作
if (policy & OBJC_ASSOCIATION_GETTER_RETAIN) {
objc_retain(value);
}
}
}
}
//如果value存在,并且policy为OBJC_ASSOCIATION_GETTER_AUTORELEASE,则对value进行一次autorelease操作,将其放入自动释放池中
if (value && (policy & OBJC_ASSOCIATION_GETTER_AUTORELEASE)) {
objc_autorelease(value);
}
return value;
}
objc_removeAssociatedObjects
之前说到调用objc_setAssociatedObject函数函数时如果value传nil,就会从映射表中移除关联对象,但是这一次只能移除一个关联对象,而objc_removeAssociatedObjects函数则可以移除一个object的所有关联对象。
void objc_removeAssociatedObjects(id object)
{
//判断当前object是否存在关联对象
if (object && object->hasAssociatedObjects()) {
_object_remove_assocations(object);
}
}
_object_remove_assocations中就是完整的移除关联对象的操作
void _object_remove_assocations(id object) {
vector< ObjcAssociation,ObjcAllocator<ObjcAssociation> > elements;
{
//拿到manager中的哈希表
AssociationsManager manager;
AssociationsHashMap &associations(manager.associations());
if (associations.size() == 0) return;
//通过object生成哈希表的索引
disguised_ptr_t disguised_object = DISGUISE(object);
//通过索引disguised_object去哈希表中找到object对应的映射表
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
//通过传递过来的key去映射表中找到对应的ObjcAssociation类型的关联对象
ObjectAssociationMap *refs = i->second;
for (ObjectAssociationMap::iterator j = refs->begin(), end = refs->end(); j != end; ++j) {
elements.push_back(j->second);
}
// remove the secondary table.
delete refs;
//遍历映射表,移除所有的对象
associations.erase(i);
}
}
// the calls to releaseValue() happen outside of the lock.
for_each(elements.begin(), elements.end(), ReleaseValue());
}
关联对象总结
- 使用runtime的Api可以在分类中为类设置关联对象。
- 关联对象并不是存放在被关联对象本身的内存中,而是存储在一个全局统一的AssociationsManager中
- 每一个类都有一个对应的映射表ObjectAssociationMap,存放在全局的哈希表AssociationsHashMap中,通过类对象的内存地址计算出哈希表的索引。
- 类的每一个关联对象的值都封装成了一个ObjectAssociation对象,存放在映射表中。
关联对象的关系图如下
Category面试题
1、Category有哪些使用场景?
- 如果一个类相对庞大,可以使用Category对类进行功能分类,减小类的体积
- 给系统类入NSString、NSObject等等增加方法,协议,也可以通过关联对象增加属性
- 可以创建私有方法的前向引用,例如在类中有个私有方法,外部需要使用,那么就可以通过给类定义一个Category,在Category中声明方法不做实现即可。原理其实还是利用消息转发机制来进行方法调用。
- 可以用来添加非正式的协议
2、Category的内部实现原理是什么?
- Category在程序编译之后会生成category_t类型的结构体,内部存放着分类中的对象方法、类方法、属性列表和协议列表等等
- 在程序运行时,runtime会将所有的category_t中的方法列表、属性列表和协议列表存放到一个大的数组中,然后通过逆序变量合并到类或者元类信息中(类方法存放到元类方法列表中,对象方法存放到类方法列表中)
3、Category和Class Extension的区别是什么?
- Category中的方法在编译时会生成一个静态的结构体变量,在运行时才会将内部数据合并到类信息中
- Class Extension中所定义的方法、属性和协议在编译的时候就已经包含在了类信息当中
4、在Category中+load()方法什么时候调用?
- 如果一个类存在多个Category,那么在runtime加载类的时候,会首先调用类的+load方法,然后会调用Category的+load方法,Category的+load方法的调用顺序和Category编译顺序有关,先编译的Category优先调用。
- 如果类存在多个子类和多个Category,那么在runtime加载类的时候会先调用父类的+load方法,然后调用子类的+load方法,调用顺序和子类的编译顺序相同,最后会调用分类的+load方法。
5、+load()和+initialize()方法的区别是什么?如果存在分类,它们的调用顺序是怎样的?如果存在继承,它们的调用顺序又是怎样的?
- +load()方法是在runtime第一次加载类的时候调用
- +initialize()方法是在类第一次接收到消息时调用
- 如果存在分类,会首先通过内存地址直接调用父类的+load方法,然后调用分类的+load方法,分类+load的方法的调用顺序和编译顺序相同。
- 如果存在分类,会覆盖类本身的+initialize方法,只会调用分类的+initialize方法
- 如果存在继承,会首先通过内存地址直接调用父类的+load方法,然后调用子类的+load方法,子类的调用顺序和编译顺序相同
- 如果存在继承,会首先调用父类的+initialize方法,然后调用子类的+initialize方法,如果子类没有实现+initialize方法,则会调用父类的+initialize方法,因此,父类的+initialize方法可能会被调用多次。
6、Category能否添加成员变量?怎么添加?
- 可以给Category添加属性,但是添加的属性是无法生成成员变量的。因此,我们在分类中添加的属性是无法使用的。想要在分类中给类增加类似属性的效果,可以使用关联对象来间接实现。就是通过runtime提供的objc_setAssociatedObject函数和objc_getAssociatedObject函数来实现。
- 关联对象的原理其实是将所有的关联对象存放到了一个全局的映射表中,以我们传过去的key为映射表的key。
