

不知大家有没有这种体验,为了知道最近发生了些什么热点事件,我们一次次打开、切换微博、知乎、各大社区、新闻站点……简直累的不要不要的,可作为程序员的我们怎么可以允许这么累自己呢?能用程序搞定的事就不要劳烦自己的双手啦:)
今天我们就来学习一下怎么写一个热榜聚合站(目测很火,很多朋友在做这种信息聚合项目),目的就是就是解放双手,顺带干掉手机上的几大辣鸡客户端(某条为首、你真的知道我关心的是啥吗??),还你以纯净无公害的信息流体验。
比如这种:

既然是写爬虫,那么我们第一想到的便是python啦,这货太厉害了,做啥都行,简直万能胶水。不过今天我们不打算用它,我们选择前端鹅儿喜闻乐见的nodejs来干这件事,顺便学习一下大前端神器Puppeteer。
Puppeteer介绍
来看一段来自Github主页的官方介绍:
Headless Chrome Node.js API.
好简洁有木有!是的,它就是一个Node API库,用来控制DevTools协议上的无头(Headless、无界面)或非无头浏览器(Chrome)。
为什么不用request方式呢?
- 我们想要借此学习一下Puppeteer这个大杀器。
- Request方式虽然足够快,但是碰到协议加密有时候是搞不定的。
- Puppeteer相当于操控浏览器,只要浏览器能显示的我们都能轻松获取。
- 只要优化的足够好,Puppeteer也是可以很快的。
安装Puppeteer
默认你已安装好Node环境,没安装的可以Google一下(下载安装包或通过命令行),很简单:)推荐通过nvm(Node环境管理工具)安装。
然后只需要在你的项目下运行以下命令:
npm i puppeteer
# or "yarn add puppeteer"
这里会默认下载对应版本的Chromium,因为众所周知的原因,下载速度会很慢。解决方案是:
1.通过设置环境变量PUPPETEER_SKIP_CHROMIUM_DOWNLOAD,跳过chromium下载,而后手动下载对应版本chromium使用。
2.下载puppeteer-core(会忽略一切PUPPETEER_*环境变量,默认不下载chromium),使用本地对应版本chrome或下载对应版本chromium。
对应版本号查看,可通过puppeteer包内package.json文件内chromium_revision字段查看。
mac版下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Mac/{chromium版本}/chrome-mac.zip
windows 64位版本下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Win_x64/{chromium版本}/chrome-win.zip
windows 32位版本下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Win/{chromium版本}/chrome-win.zip
Linux X86版本下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Linux/{chromium版本}/chrome-linux.zip
Linux X64版本下载地址:
https://commondatastorage.googleapis.com/chromium-browser-snapshots/Linux_x64/{chromium版本}/chrome-linux.zip
注意你的Node版本:
Puppeteer v1.18.1之前至少需要Node v6.4.0,所有后续版本都基于Node v8.9.0+及以上。
如何用它爬取信息呢?
以v2ex最热为例(www.v2ex.com/?tab=hot),我们分析下它的页面结构:
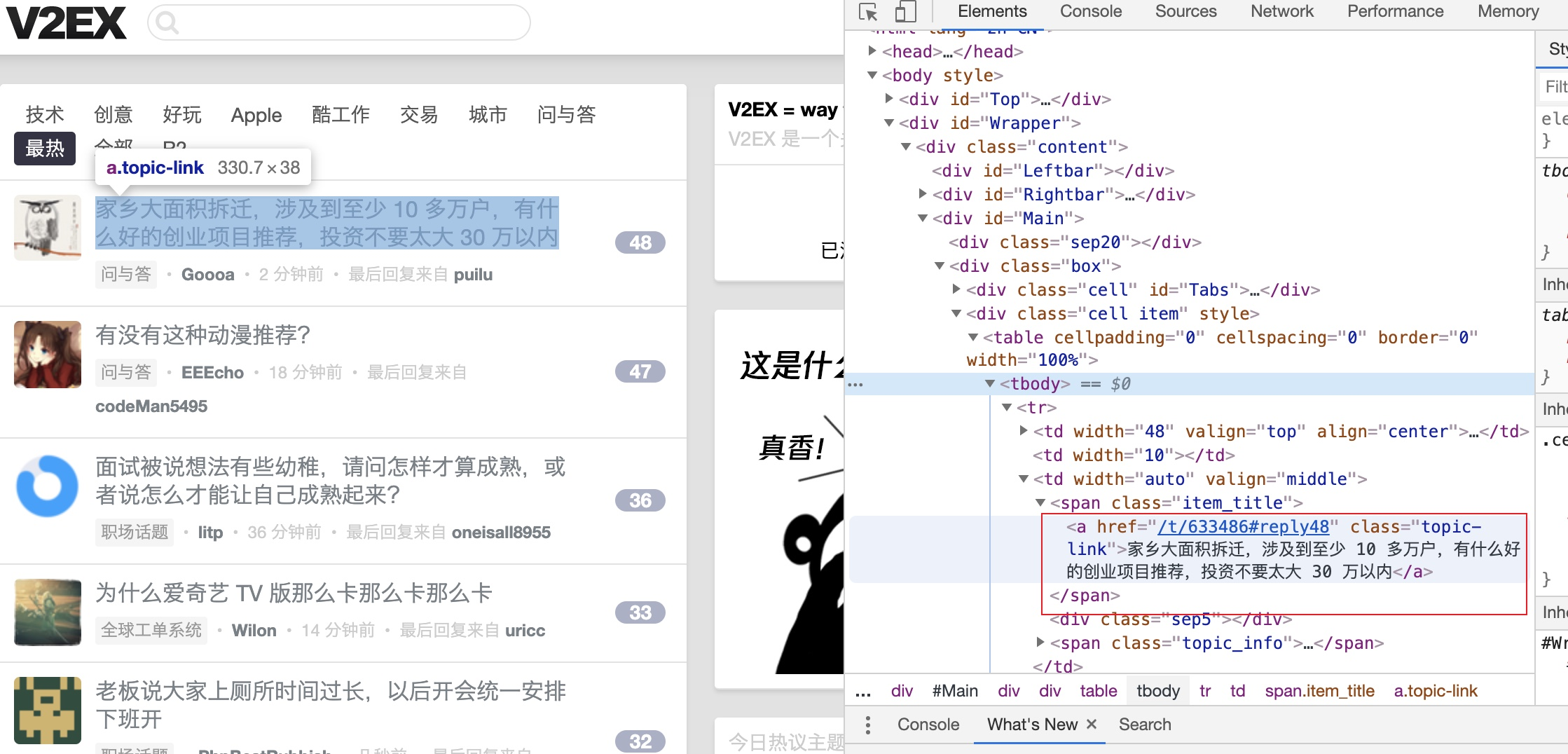
我们已经看到我们想要的Dom节点,我们需要做的就是把它抓下来并组合成json数据,提供给客户端使用。
来看下用puppeteer,代码该怎么写(为了演示,省去了优化项):
const puppeteer = require("puppeteer");
const url = "https://www.v2ex.com/?tab=hot";
(async function run() {
let browser = await puppeteer.launch({
executablePath: "./chrome-mac/Chromium.app/Contents/MacOS/Chromium",
headless: true
});//使用设置参数运行一个浏览器
let newPage = await browser.newPage();// 浏览器创建一个新tab页
newPage.setDefaultTimeout(1000 * 10);// 设置默认请求超时时间
await Promise.all([
newPage.setJavaScriptEnabled(false)// 设置禁止js,这样会快一些
]);
await newPage.goto(url, {waitUntil: "domcontentloaded"});//请求页面
let list = await newPage.?eval(`.item_title a`, eles => eles.map(ele => {
return {title: ele.innerText, url: ele.href}
}));// 获取Dom中我们想要的数据
if (list) {
list.forEach((item) => {
console.log(item)// 打印结果
})
}
browser.close();// 关闭浏览器
})();

运行后如上图所示,我们已经拿到文章的title和url(这里做演示只拿了这俩个数据),拿到了数据,剩下该怎么玩就看你了想(wei)怎(suo)么(yu)玩(wei)了。
后记
当然如果想做一个成品的聚合站,还有很多工作要做,比如定时爬取、守护进程、缓存和数据库管理、写Server、写前端等等。篇幅所限,写到这里我们只把爬虫最核心的地方写完了,剩下的相信聪明的你会有很多花(姿)样(势)要玩:)
公众号: 「优雅的程序员呀」程序员赚钱之道。优雅的技术,优雅的赚钱。关注公众号,进群技术交流。

