

文章作者:xyz,Crawlab 开发组成员
今天我们来说一说如何在Kubernetes(以下简写k8s)集群当中搭建一个Crawlab爬虫平台。阅读本文需要读者熟悉Docker的使用以及了解k8s的一些基本概念。
首先,先介绍下k8s的几个重要概念。
Pod
Pod是k8s集群中最基本的单位,一个Pod包含一组容器(Container)。一个Pod包含多个容器应用场景例如Sidecar模式,业务容器会写日志,日志收集Agent容器读日志并转发,它们挂载在同一个Volume上。在我们的实践当中是一个Pod里面只有一个业务容器,对于日志我们是直接SDK对接阿里云的日志服务。所以这里可以简单理解一个Pod就是一个容器。
Deployment
Deployment对象是用于控制Pod的,例如Pod的副本个数(服务实例个数),Pod的滚动部署配置,Pod的节点亲和等等。一般情况下是对Deployment进行管理和配置,不会直接对Pod的进行管理,通过编写yaml描述文件部署Deployment。
Service
在一个k8s集群当中,会有多台的worker节点,Pod在每次重新部署的时候都会根据Deployment的配置选择对应的节点进行部署,所以每次Pod的IP其实都是不一样的,所以k8s提供了Service对象,用于代理到具体的Pod实例IP上,可以简单理解Service是在Pod前面的一个负载均衡器,当Deployment控制Pod一个或者多个副本的时候,通过Service的IP,可以代理到这些Pod上。
好了,介绍完Pod、Deployment、Service后,我们在说下Crawlab,截止2019年10月5日,Crawlab的最新版本是tikazyq/crawlab:0.3.2
在0.3.2版本的Crawlab对于worker节点和master节点的爬虫同步机制修改为以MongoDB为准:用户通过前端上传爬虫后会存储到MongoDB GridFs,不管是worker或者master节点都会有一个定时器去拉取GridFs上的文件,判断的依据是file对象的md5值。
上传爬虫流程图如下: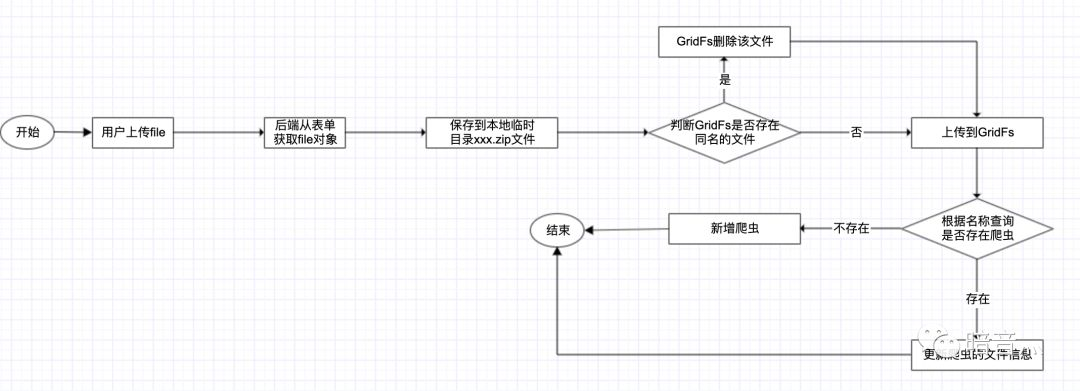
节点同步爬虫流程图如下: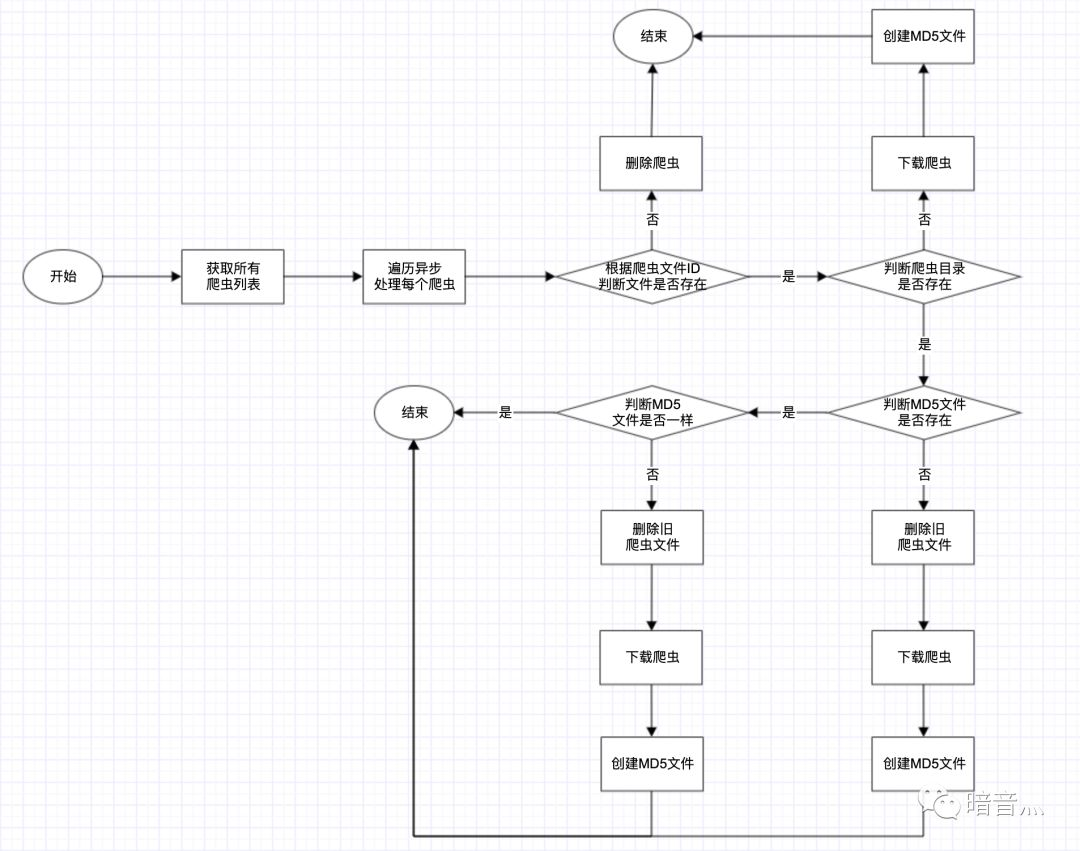
master节点和worker节点是解耦的,它们之间的文件同步是通过GridFs,通讯是通过Redis的pub/sub机制。关于md5文件,是在保存到GridFs后会自动生成一个md5值,这个值会在把爬虫同步到节点本地的时候写在爬虫根目录的md5.txt当中,用于判断当前爬虫文件和GridFs中的文件是否一致。
OK,知道了Crawlab的爬虫同步机制,我们就可以在k8s上部署我们的爬虫平台了。
部署Master
以下三个注意事项:
1、创建ConfigMap对象。我们会把所需配置文件信息写到ConfigMap中,然后再挂载到容器里面,形成config.yml文件。
2、配置Deployment的CRAWLAB_SERVER_MASTER环境变量,因为master节点和worker节点会共用一个ConfigMap对象,所以需要特殊配置。
3、创建Service对象后,会拿到一个ClusterIP,把这个IP再配置到Deployment的CRAWLAB_API_ADDRESS环境变量中,因为这个是前端访问后端的地址配置。如果是生产环境,一般是配置Ingress对象。
ConfigMap配置文件如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: crawlab-conf
namespace: dev
data:
config.yml: |-
api:
address: "localhost:8000"
mongo:
host: "192.168.235.26"
port: 27017
db: crawlab_xyz
username: "root"
password: "example"
authSource: "admin"
redis:
address: 192.168.235.0
password: redis-1.0
database: 18
port: 16379
log:
level: info
path: "/opt/crawlab/logs"
isDeletePeriodically: "N"
deleteFrequency: "@hourly"
server:
host: 0.0.0.0
port: 8000
master: "Y"
secret: "crawlab"
register:
# mac地址 或者 ip地址,如果是ip,则需要手动指定IP
type: "mac"
ip: ""
spider:
path: "/opt/crawlab/spiders"
task:
workers: 4
other:
tmppath: "/opt/crawlab/tmp"
Deployment和Service的配置如下:
apiVersion: apps/v1beta2
kind: Deployment
metadata:
labels:
app: crawlab-master
name: crawlab-master
namespace: dev
spec:
replicas: 1
# 标签选择器
selector:
matchLabels:
app: crawlab-master
# 滚动部署策略
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
# pod的源数据信息
metadata:
labels:
app: crawlab-master
spec:
containers:
- env:
- name: CRAWLAB_API_ADDRESS
value: "cluster_ip:8000"
# 配置为master节点,因为worker节点和master节点会共用一个ConfigMap,
# 所以CRAWLAB_SERVER_MASTER需要额外配置
- name: CRAWLAB_SERVER_MASTER
value: "Y"
image: 192.168.224.194:5001/vanke-center/crawlab:0.3.2
imagePullPolicy: Always
name: crawlab-master
# 资源配置
resources:
limits:
cpu: '2'
memory: 1024Mi
requests:
cpu: 30m
memory: 256Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
# 配置文件挂载配置
volumeMounts:
- mountPath: /app/backend/conf/
name: crawlab-conf
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
# 挂载卷从ConfigMap读取
- configMap:
defaultMode: 420
name: crawlab-conf
name: crawlab-conf
---
apiVersion: v1
kind: Service
metadata:
name: crawlab-master
namespace: dev
spec:
ports:
- port: 8000
protocol: TCP
# crawlab 后端服务监听的端口
targetPort: 8000
name: backend
- port: 80
protocol: TCP
# crawlab 前端监听的端口
targetPort: 8080
name: frontend
selector:
# 需要与deployment定义的pod相关的metadata.labels一致,用于选择对应的pod进行流量代理
app: crawlab-master
sessionAffinity: None
type: ClusterIP
当你按以上步骤部署完后,通过Service的ClusterIP就可以访问到登录界面了。
在k8s集群外访问服务一般是通过Ingress或者NodePort的方式,因为我们是直接打通了本地和k8s集群的网络,所以是可以直接访问Service对象的ClusterIP,正常情况是不能访问的。
但是你会发现无法正常登录,因为我们刚说的第三个步骤还没处理,所以还无法正常登录,在谷歌浏览器下按F12,查看以下异常信息。
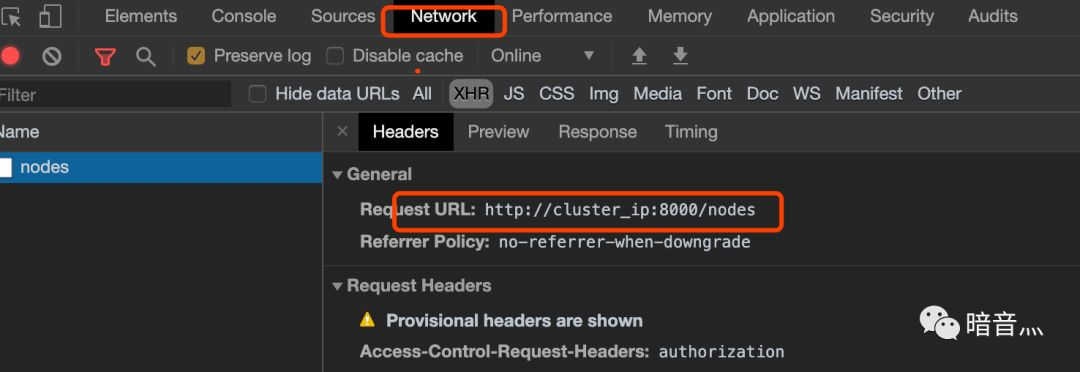
有没有发现很熟悉的地方,这个其实就是刚在Deployment配置的CRAWLAB_API_ADDRESS环境变量。实际的值,我们需要替换为Service的ClusterIP。
通过以下命令查看Service的ClusterIP
kubectl get svc -n dev | grep crawlab
所以我们需要替换CRAWLAB_API_ADDRESS环境变量的值,Deployment的片段修改如下:
containers:
- env:
- name: CRAWLAB_API_ADDRESS
value: "172.21.9.55:8000"
# 配置为master节点,因为worker节点和master节点会共用一个ConfigMap,
# 所以CRAWLAB_SERVER_MASTER需要额外配置
- name: CRAWLAB_SERVER_MASTER
value: "Y"
然后重新apply下Deployment,然后master节点重启更新配置即可。
重新访问后,即可进入后台了。
部署Worker
部署worker就比较简单了,Deployment的配置文件和master是基本一样的,只要修改CRAWLAB_SERVER_MASTER环境变量的值为N,删除Service对象的定义即可,当然还有修改名称哟。如下:
apiVersion: apps/v1beta2
kind: Deployment
metadata:
labels:
app: crawlab-worker
name: crawlab-worker
namespace: dev
spec:
replicas: 1
# 标签选择器
selector:
matchLabels:
app: crawlab-worker
# 滚动部署策略
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
# pod的源数据信息
metadata:
labels:
app: crawlab-worker
spec:
containers:
- env:
# 配置为master节点,因为worker节点和master节点会共用一个ConfigMap,
# 所以CRAWLAB_SERVER_MASTER需要额外配置
- name: CRAWLAB_SERVER_MASTER
value: "N"
image: 192.168.224.194:5001/vanke-center/crawlab:0.3.2
imagePullPolicy: Always
name: crawlab-worker
# 资源配置
resources:
limits:
cpu: '2'
memory: 1024Mi
requests:
cpu: 30m
memory: 256Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
# 配置文件挂载配置
volumeMounts:
- mountPath: /app/backend/conf/
name: crawlab-conf
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
# 挂载卷从ConfigMap读取
- configMap:
defaultMode: 420
name: crawlab-conf
name: crawlab-conf
# worker 不需要定义Service,因为不需要暴露访问地址
worker部署完成后,就可以在后台的节点列表查看了。
这里的IP并不是Service的IP,而是Pod的IP。
至此,在k8s平台上部署Crawlab爬虫平台完成 ~
