

前几天的MongoDB被盗真的是把本蒟蒻难受坏了,如果自己当初会sql还用啥MongoDB啊 😭😭
简单的把常用的sql语句整理总结下,主要还是为了方便自己以后操作sql类数据库以及和应付期末考试。
本笔记中的sql语句测试环境为sql-server 2008 R2。
内容总结相对入门和基础,具体语句的详细使用还请您查阅各数据库官方文档。
数据库创建
create database 数据库名
数据库管理
查看数据库
use 数据库名
修改数据库配置
alter database 数据库名
后续sql操作语句
扩大与收缩数据库
--扩大数据库
alter database 数据库名
modify file(
name = 数据库中的主要数据文件名,
size = 修改后的文件大小
)
--收缩整个数据库,使school数据库中的所有文件都有20%的可用空间
dbcc shrinkdatabase(school,20);
--收缩指定数据文件,使school数据库中的class文件收缩到4 MB
dbcc shrinkfile(class,4);
删除数据库
drop database 数据库名
分离和附加数据库
分离
分离数据库是指将数据库从sql server的实例中删除,但文件依然存在,是可以找回来的。
exec sp_detach_db '数据库名','true';
--当后面追加参数true代表分离后跳过显示统计信息
附加
将分离下来的数据库重新附加到sql server上
--将school数据库附加到school数据库实例上去
create database school
on(filename = '数据文件路径')
for attach
表结构的管理
创建表结构
基本语法
create table 表名称(
字段名1 数据类型 约束,
字段名2 数据类型 约束,
字段名3 数据类型 约束,
追加约束...
)
修改表结构
添加
-- 向student表中添加住址和邮政编码字段。
use school
go
alter table student add
address char(40),
code char(6)
修改
-- 将student表中的sdept字段改为varchar类型,长度为30,并设置该字段不能为空
alter table student alter column sdept varchar(30) not
删除
-- 将student表中的address字段删除
alter table student drop column address
重命名
-- 将student表中zipcode字段更名为zip
exec sp_rename 'student.zipcode','zip','column';
-- 将表sc重命名为'score'
exec sp_rename 'sc','score';
删除表
-- 删除数据库中的sc表
use school
go
drop sc
表结构的完整控制
primary key约束
用来唯一标识当前数据表中的某一行
-- 将course表中的cno字段设置为主键
alter table course add constraint pk_cno primary key(cno);
-- 删除上面设置的主键约束
alter table course drop constraint pk_cno;
unique约束
用来保证字段中的所有数据各不相同
-- 创建department表时为id这个字段设置uniqe约束
create table department(
id char(10) constraint u_id uniqe,
dname char(20)
)
-- 为上表中的name字段设置unique约束
alter table department
add constraint u_name uniqe(dname);
check约束和default约束
check约束用来保证列中的所有值必须要满足的条件 default约束用来保证列中数据未指定时的缺省值
-- 创建student表时为sex字段添加check约束并默认设置字段值为‘男’
create table student(
sex char(4) check(sex = '男' or sex = '女') default '男'
)
foreign key约束
用来唯一标识其他数据表中的某一行
-- 创建scorel表,包含sno,cno,和grade字段,在sno和cno上设置主键,同时设置sno字段为student表中sno字段的外键
create table scorel(
sno char(10),
cno char(10),
primary key(snp,cno),
foreign key(sno) references student(sno)
);
-- 手动为上面表中的cno字段设置为course表中cno字段的外键
alter table scorel add constraint fk_cno foreign key(cno) references course(cno);
禁用约束
某些特殊情况我们可能会选择先禁用掉约束,而不是删除约束。
-- 暂时禁止student表中设置的性别约束
alter table student
with nocheck
add constraint ck_sex check(sex = '男' or sex = '女');
-- 启用student表中的性别约束
alter table student check constraint ck_sex;
-- 禁用scorel表中所有的约束
alter table scorel
nocheck constraint all;
表内容的管理
insert
insert into语句用于我们向表中添加新的行
不指定字段名称根据字段顺序插入全部字段值
-- 假设student表中只有id,name,sex这三个字段,并且性别字段可以为空
insert into student values('0001','吴亦凡','男'),('0002','蔡徐坤','男')
指定字段名称插入部分字段值
-- 在student表中添加新的人物
insert into student(id,name) values ('0003','五五开');
-- 此时五五开就被添加进了学生表,同时性别栏为空
update
update语句用于修改表中的字段值
| ID | NAME | AGE | ADDRESS |
+----+----------+-----+-----------+
| 1 | mike | 19 | beijing |
| 2 | katy | 25 | hangzhou |
| 3 | jason | 20 | shenyang |
| 4 | mimgming | 18 | shanghai |
| 5 | hongh | 21 | zhengzhou |
| 6 | hanghang | 22 | tianjin |
| 7 | peter | 22 | guangzhou |
+----+----------+-----+-----------+
-- 将上述people表中的年龄都改为20岁
update people set age = 20;
<<<<<<< HEAD
-- 基于条件的更新,将id为2的条目地址改为zhejaing
update people set address = zhejiang where id = 2;
=======
<<<<<<< HEAD
-- 基于条件的更新,将id为2的条目地址改为zhejiang,age改为18
update people set address = zhejiang,age = 18 where id = 2;
=======
-- 基于条件的更新,将id为2的条目地址改为zhejaing
update people set address = zhejiang where id = 2;
>>>>>>> a6d99de767cc1db3754c54c25d6b940084f50a9b
>>>>>>> ac6ab2c78f3bb499c9c143bcf1d0fbf7a3eca667
delete
delete语句用于删除表中的一行或者多行数据
-- 删除stu表中的所有行(所有内容)
delete from stu
-- 删除stu表中没有地址的行
delete from stu where address is null
数据基本查询
选择字段
选择指定字段
-- 查询stu表中的学生姓名与性别
select name,sex from stu
选择全部字段
-- 查询stu表中的所有字段的详细信息
select * from stu
查询结果预处理
-- 查询学生姓名及其对应的出生年份(假设表中没有出生年份字段,只有age字段)
select name,2019-age from stu
此时查询结果会显示无列名
| ID | NAME |无列名|
+----+----------+-----+
| 1 | mike | 19 |
| 2 | katy | 25 |
| 3 | jason | 20 |
| 4 | mimgming | 18 |
| 5 | hongh | 21 |
| 6 | hanghang | 22 |
| 7 | peter | 22 |
+----+----------+-----+
-- 查询姓名与出生年份,并在出生年份前加入常量列“出生年份”
select name,'出生年份',2019-age from stu
查询结果
| ID | NAME |无列名 |无列名|
| 1 | mike |出生年份 | 19 |
| 2 | katy |出生年份 | 25 |
| 3 | jason |出生年份 | 20 |
| 4 | mimgming |出生年份 | 18 |
| 5 | hongh |出生年份 | 21 |
| 6 | hanghang |出生年份 | 22 |
| 7 | peter |出生年份 | 22 |
查询结果指定自定义字段名称
-- 查询stu表中的的name和age,并指定各列的字段名称分别为姓名和年龄
select name as 姓名,age as 年龄
from student
查询结果
| ID | 姓名 | 年龄 |
+----+----------+-----+
| 1 | mike | 19 |
| 2 | katy | 25 |
| 3 | jason | 20 |
| 4 | mimgming | 18 |
| 5 | hongh | 21 |
| 6 | hanghang | 22 |
| 7 | peter | 22 |
+----+----------+-----+
选择行
限制结果集
-- 查询stu表中的前5行
select top 5 from stu
消除取值重复的行
select distinct sex from stu
-- 此时在查询结果中只会显示出"男"和“女”这两行。
where条件查询
where语句不仅仅能用于select语句,还能与上面的update,delete语句相结合使用。
等值查询与比较大小
-- 查询jason所在行的全部信息
select * from stu where name = 'jason'
-- 查询年龄在20岁以下的人的全部信息
select * from stu where age < 20
根据连续范围查询
between...and语句和not between...and语句可以用来查找满足指定范围的行或者行中的部分字段。
-- 查询年龄在20-23岁的学生姓名以及家庭住址。
select name,address from stu
where age between 20 and 30;
根据集合范围查询
使用in运算符可以查询满足某个集合的结果。
-- 返回满足20岁和21岁的学生的所有信息
select * from stu
where age in(20,21);
字符匹配查询
使用like运算符可以实现字符的匹配查询
-- 查询性“叶”的学生的详细信息
select * from stu
where name like '叶%'
-- %意思是匹配一个或者多个字符,如果这个百分号在“叶”的前面就会查找姓名中最后一个字为“叶”的学生。
-- 查询名字中第二个字为“云”或“风”的学生的所有信息
select * from stu
where name like '_[小大]%'
-- []意为匹配[]中的任意一个字符,_意为匹配所有字符
-- 查询学号最后一位不是2,3,5的学生的所有信息
select * from stu
where no like '%[^235]'
-- [^]意为不匹配[]中的字符
涉及到null的情况
如果遇到空值要用is进行判断。
--查询缺少地址信息的学生的全部信息。
select * from stu
where address is null;
and和or
and和or可以组合成多重条件查询
-- 查询家住在beijing并且年龄为20岁以下的同学的全部信息。
select * from stu
where address = 'beijing' and age < 20;
数据排序查询
-- 将查询出来的学生的信息按照年龄升序排序
select * from stu order by age
-- 将查询出来的学生信息按照年龄降序排序,年龄如果相同的按成绩升序排序
select * from stu order by age desc,score;
使用计算函数
count()函数
-- 统计学生的总人数
select count(*) from student
--统计学生表中的地址种类一共有多少个
select count(distinct address) from stu
sum()函数和avg()函数
-- 计算stu表中的所有学生的年龄总值和平均值。
select sum(age),avg(age) from stu
max()函数和min()函数
-- 查询家住beijing的同学中年龄最小的和年龄最大的。
select min(age),max(age) from stu
where address = 'beijing';
对查询结果分组计算
使用group by语句
-- 统计不同区域的学生人数
select address,count(*)
from stu group by address
into语句
into语句用于将查询的结果放到一个新表中
-- 查询家住beijing的同学的所有信息,并将结果保存到beijing_stu表中
select * into beijing_stu
from stu
where address = 'beijing';
子查询
单值嵌套查询
-- 查询stu中地址为beijing的学生的学号和成绩
select no,grade
from stu
where area = (select area from area_table where address = 'beijing')
--先从内查询中找出北京的区域号,然后再根据北京的区域号确定学生的学号和成绩
多值嵌套查询
使用in运算符
-- 查询成绩大于90分的学生的姓名和英语成绩
-- 假设stu表中没有学生的英语成绩,但score表中有学号对应的成绩
select name,english_score from stu
where no in(
select no from score
where grade > 90
)
使用子查询进行比较测试
-- 查询选修了"数据结构"并且成绩高于该课程平均分的学生的全部信息
select * from stu
where course = '数据结构'
and grade > (select avg(grade) from stu where course = '数据结构')
使用any及all运算符
-- 查询选修“数据结构”的学生成绩比选修"离散数学"的学生最低成绩高的学生全部信息
select * from stu
where course = '数据结构'
and grade > any(select grade from stu where course = '离散数学');
-- any(或some)意为满足其中任意一个值就返回true,条件较为宽松
-- 查询选修"数据结构"的学生成绩比选修“离散数学”的学生最高成绩还要高的学生全部信息
select * from stu
where course = '数据结构'
and grade > all(select grade from stu where course = '离散数学');
-- all意为满足所有查询条件才会给你返回true,条件较为严格
连接查询
customers表中存储的消费者的详细信息
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 24 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
order表是也是顾客的消费信息,不过没有名字,只有对应的id
+-----+---------------------+-------------+--------+
|OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+
自连接
-- 查询与muffy年龄相同的人的全部信息
select * from customers cus1 join customers cus2
on cus1.age = cus2.age
where cus1.name = 'muffy' and cus2.name != 'muffy';
-- 自连接是指一个表自己与自己建立连接,因此在逻辑上要分成两个表,并取别名。
内部连接
-- 根据orders表的内容查询其对应的id,姓名,购买量,消费日期。
select id,name,amount,date
from customers
inner join orders on customers.id = orders.id;
-- 查询顾客购买量为3000的顾客的姓名和年龄。
select name,age from customers
inner join orders on customer.id = orders.id
where orders.amount = 3000;
外部连接
左外连接
-- 根据顾客表查询全部顾客的id,姓名,购买量,购买日期。
select id,name,amount,date from customers
left outer join orders
on customers.id = orders.id
-- 左外连接的意思就是将自己从左边连接一个表然后查询,此时查询的“视角”是自己,主要限制另一张表
输出结果
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
+----+----------+--------+---------------------+
右外连接
-- 根据顾客表查询全部顾客的id,姓名,购买量,购买日期。
select id,name,amount,date from customers
right outer join orders
on customers.id = orders.id
-- 右外连接的意思就是将自己从右边连接一个表然后查询,此时查询的“视角”是另一张表,主要限制自己
查询结果
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+------+----------+--------+---------------------+
全连接
-- 全连接会返回两个表的所有行,不管他们是否满足连接条件
select id,name,amount,date from customers
full outer join orders
on customers.id = orders.id
查询结果
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+------+----------+--------+---------------------+
交叉连接
交叉连接会返回两个连接表的所有数据行的笛卡尔积。
-- 将上面两个表全连接
select id, name, amount, date
from customers, orders;
查询结果一共是4x7=28行
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 1 | Ramesh | 3000 | 2009-10-08 00:00:00 |
| 1 | Ramesh | 1500 | 2009-10-08 00:00:00 |
| 1 | Ramesh | 1560 | 2009-11-20 00:00:00 |
| 1 | Ramesh | 2060 | 2008-05-20 00:00:00 |
| 2 | Khilan | 3000 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 2 | Khilan | 2060 | 2008-05-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 2060 | 2008-05-20 00:00:00 |
| 4 | Chaitali | 3000 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | 3000 | 2009-10-08 00:00:00 |
| 5 | Hardik | 1500 | 2009-10-08 00:00:00 |
| 5 | Hardik | 1560 | 2009-11-20 00:00:00 |
| 5 | Hardik | 2060 | 2008-05-20 00:00:00 |
| 6 | Komal | 3000 | 2009-10-08 00:00:00 |
| 6 | Komal | 1500 | 2009-10-08 00:00:00 |
| 6 | Komal | 1560 | 2009-11-20 00:00:00 |
| 6 | Komal | 2060 | 2008-05-20 00:00:00 |
| 7 | Muffy | 3000 | 2009-10-08 00:00:00 |
| 7 | Muffy | 1500 | 2009-10-08 00:00:00 |
| 7 | Muffy | 1560 | 2009-11-20 00:00:00 |
| 7 | Muffy | 2060 | 2008-05-20 00:00:00 |
+----+----------+--------+---------------------+
集合运算查询
并运算
union操作符可以可以将最终的查询结果取并集 注意:参与任何集合运算的查询表结构应该相同
-- 用union语句将之前的左外连接和右外连接并起来
select id,name,amount,date from customers
left outer join orders
on customers.id = orders.id
union
select id,name,amount,date from customers
right outer join orders
on customers.id = orders.id;
查询结果
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
+------+----------+--------+---------------------+
交运算
intersect语句,用法和union语句类似,只不过最终是从两个查询结果里取交集。
差运算
except语句,用法同上,会将第一个select结果中有,但是第二个select结果中没有的行返回。
case函数查询
简单case函数
/*
假设学生表中有学生的选课信息
查询选了数据结构的学生的姓名,所在系和成绩。
其中所在系子段进行如下处理:
当所在系为数学系时,显示为"MA"
当所在系为计算机系时,显示为"CS"
*/
select name,
case majored
when '数学系' then 'MA'
when '计算机系' then 'CS'
end,grade from stu where course = '数据结构';
搜索case函数
搜索case函数可以完成范围内的情况判断。
/*
查询选修了数据结构的学生的考试情况,列出姓名以及是否及格
其中成绩大于60分显示及格
成绩小于60分显示不及格
*/
select name,case
when data_structure_score >= 60 then '及格'
when data_structure_score < 60 then '不及格'
end as 是否及格 from stu where course = '数据结构'
索引
使用索引可以提高查询的速度,但是会降低更新和插入数据的速度。
创建索引
-- 为stu表的name字段再单独创建出一个非聚集索引
create index name_index on stu(name);
-- 为stu的id子段创建出一个唯一的聚集索引
create unique clustered index id_index on stu(id);
-- 聚集索引用来确定表中数据的物理顺序。
管理索引
查看索引
-- 查看stu表的索引信息
exec sp_helpindex stu
-- 禁用id_index索引
alter index id_index on stu disable;
-- 将name_index更改为xingming_index
exec sp_rename 'stu.name_index','xingming_index','index';
-- 删除stu表中的name_index索引。
drop index name_index;
视图
视图简单来说就是存储在数据库中被封装好的select语句。
创建视图
单表视图
-- 创建能够查询customers表中的姓名和年龄的视图
create view customers_view as
select name,age
from customers;
带检查项的视图
-- 在通过下面这个视图插入或者修改数据的时候就会拒绝age为null的条目。
create view customers_view as
select name,age
from customers
where age is not null
with check option;
多表视图
-- 在stu和stu_detail上创建stu_info视图
create stu_info (id,name,age)
as select stu.id,stu.name,stu_detail.age
from stu,stu_detail
where stu.id = stu_detail.id;
加密视图
-- 创建能够查询customers表中姓名和年龄的加密视图
create view stu_encry with encryption
as
select name,age
from customers;
通过视图查询数据
select * from customers_view;
查询结果
+----------+-----+
| name | age |
+----------+-----+
| Ramesh | 32 |
| Khilan | 25 |
| kaushik | 23 |
| Chaitali | 25 |
| Hardik | 27 |
| Komal | 22 |
| Muffy | 24 |
+----------+-----+
通过视图修改数据
-- 向customers_view中手动添加一个新的记录
insert into customers_view
values('jason',19);
-- 更新customers_view中的某段记录
update customers_view
set name = 'muffy'
where name = 'yffum';
-- 删除customers_view中的某段记录
delete from customers_view
where name = 'Komal';
查看和重命名视图
-- 使用sp_helptext存储过程查看name_view视图的定义信息
exec sp_helptext 'sql.stu.name_view';
-- 把视图name_view重命名为xingming_view
sp_rename name_view,xingming_view;
修改和删除视图
-- 修改上面创建的customers_view,使其显示所有字段
alter view customers_view
as
select * from customers;
-- 删除创建的视图
drop view customers_view;
函数
创建和调用函数
创建和调用标量函数
sql server的标量函数会接收n个参数并返回单个值。如果单独print调用函数最终会在打印结果上显示无列名。
-- 现有一张产品购买记录表,设计一个自定义函数,输入产品id,返回这个产品的购买数量。
create function dbo.count_products(@ product_id int)
return int
as
begin
return (
select count(*) from dbo.products
where id = @ product_id
)
end
-- 调用刚才创建的函数
print 'id号为3的产品购买了'+ convert(varchar(3),dbo.count_products(3)+'种');
-- 这里在打印的时候需要通过convert函数将类型转换一下。
创建和调用内联表值函数
表值函数最终返回的是表类型的数据
-- 创建表值函数,该函数根据产品年份返回产品信息,包括产品名称,年份和价格。
create function udfProductInyear(@year int)
returns table
as
return
select name,year,price from dbo.products
where
year = @year;
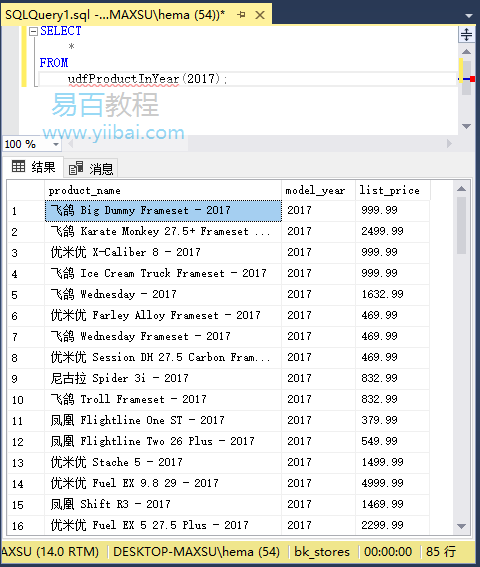
-- 执行上面创建的函数
select * from udfProductInyear(2017);
执行结果
多语句表值函数
多语句表值函数可以在函数内执行多个查询并将结果聚合到查询的表中。
-- 下面的函数会将员工和客户合并到同一张联系人表中
create function udfContacts()
return @contacts table(
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(255),
phone VARCHAR(25),
)
as
begin
insert into @contacts
select
first_name,
last_name,
email,
phone,
'Staff'
from
sales.staffs;
insert into @contacts
select
first_name,
last_name,
email,
phone,
'Customer'
from
sales.customers;
return
end;
管理用户定义函数
查看用户自定义函数
sp_helptext 函数名
-- 可用来查看用户定义函数的文本信息
sp_help 函数名
-- 可用来查看用户定义函数的一般信息
删除用户自定义函数
-- 删除上面创建的函数
drop function if exists udfContacts;
游标
有时候需要我们从结果中取一条条的记录,此时使用游标就会很有帮助
声明游标
-- 声明一个标准游标
declare stu_cursor cursor for
select id from stu;
-- 声明一个只读游标
declare stu_cursor cursor for
select * from stu for read only;
-- 声明一个可更新游标
declare stu_cursor cursor for
select * from stu for update;
-- 声明一个动态游标
declare stu_cursor CURSORScroll for
select * from stu;
打开游标
open stu_cursor;
读取游标数据
-- 读取第一行的数据,并将游标放到第一行
fetch first from stu_cursor;
-- 读取从当前行开始的第3行
fetch relative 3 from stu_cursor;
-- 读取当前行的下一行数据
fetch next from stu_cursor;
-- 读取第四行的数据
fetch absolute 4 from stu_cursor;
-- 读取最后一行的数据,并将游标放到最后一行
fetch last from stu_cursor;
-- 取出stu_cursor的数据,并保存到变量中
declare @stu_id nvarchar(20);
fetch first from stu_cursor into @stu_id;
用游标修改和删除数据
-- 通过游标修改当前行数据
update stu set name = 'jason' where current of stu_cursor;
-- 通过游标删除当前数据
delete stu where current of stu_cursor;
关闭和删除游标
-- 关闭游标
close stu_cursor;
-- 删除游标
deallocate stu_cursor;
事务
事务是在数据库上按照一定逻辑顺序执行的任务队列,具有不可分割性。一旦操作失败,就会回滚到操作前的状态。
-- 假设现在要进行两个操作,这两个操作要被看做是一个整体的事务,一旦有一个操作失败,则回滚到之前的状态。
begin try
begin tran --设置事务的恢复点
delete from stu where age = 18;
delete from stu where name = 'jason';
commit tran --如果都成功,就提交事务
end try
begin catch
rollback tran -- 一旦失败报异常就回滚
end catch
存储过程
存储过程简单来说就是封装好的一段sql语句,其中有些存储过程像系统自带的函数一样已经被封装好了。 存储过程相对于函数而言操作权限更高,功能也更为复杂,函数实现的功能针对性要更强一些。
存储过程创建
-- 创建一个简单的存储过程p1,查询所有学生信息,并按照成绩的降序排列
create proc p1
as
select * from stu order by score desc;
-- 创建存储过程p2,查询指定课程号的学生信息.
create proc p2
@course_id int --外部参数
as
select * from stu where course_id = @course_id
-- 创建存储过程p3,查询指定学号学生的英语成绩并返回。
create proc p3
@stu_id int,@english_score int output
as
select english_score from stu where stu_id = @stu_id;
存储过程执行
-- 执行p1
exec p1;
-- 执行p2
exec p2 002;
-- 执行p3
declare @tmp char(20);
-- 指定时要把返回值保存到变量中。
exec p3 002,@tmp output;
print '英语成绩为'+ @tmp;
删除存储过程
drop proc p1;
触发器
触发器是一种特殊的存储过程,它们会自动的响应数据库的某些变动。
DML触发器
数据操作语言触发器,用于响应表中的insert,delete,update事件。
-- 创建一个关于学生表的触发器,一旦要变更学生表的内容时,就执行回滚操作。
create trigger tr1 on stu after delete,insert,update
as
rollback tran
print'学生表的内容不能动!'
-- after的位置如果换成了insted of就成了替代触发器
DDL触发器
数据定义语言触发器,用于响应表中的create,alter,drop事件。
-- 在school数据库中创建一个DDL触发器,用来防止该数据库中的任一表被修改或删除
use school
go
create trigger tr2 on database after drop_table,alter_table
as
begin
raiserror('不能修改表结构',16,2)
rollback
end
管理触发器
-- 查看用户创建的触发器,和存储过程的操作是一样的
exec sp_help 触发器名
exec sp_helptext 触发器名
exec sp_depends 触发器名 --用于显示和触发器相关的数据库对象
-- 删除触发器
drop trigger 触发器名
-- 禁用触发器
disable trigger 触发器名 on 表名 --禁用对表的DML触发器
disable trigger 触发器名 on database --禁用DDL触发器
