

很久没更新JS逆向方面的文章了,一个原因是因为最近爬虫这方面管的比较严,相信大家都看过很多违法的案例了,就不细说了。另一个原因是我换坑了,现在的工作内容基本上和爬虫不相关了。
不过大家请放心这方面的内容会持续慢慢...更新下去,当然还有web这方面的内容以及Python其他方向的,各位看官勿催,我会尽量保证几天更新一篇,毕竟保质的同时不能保量,还是以质优先!哈哈哈~虽然质也不怎么地...
好吧~编不下去了了~~其实真实原因是我太懒了,我太菜了,我太难了,我真的太...进入正题...
开搞
今天的登录是 某果TV 网站,网站地址自行度娘把~~先抓包看下究竟是何方妖怪
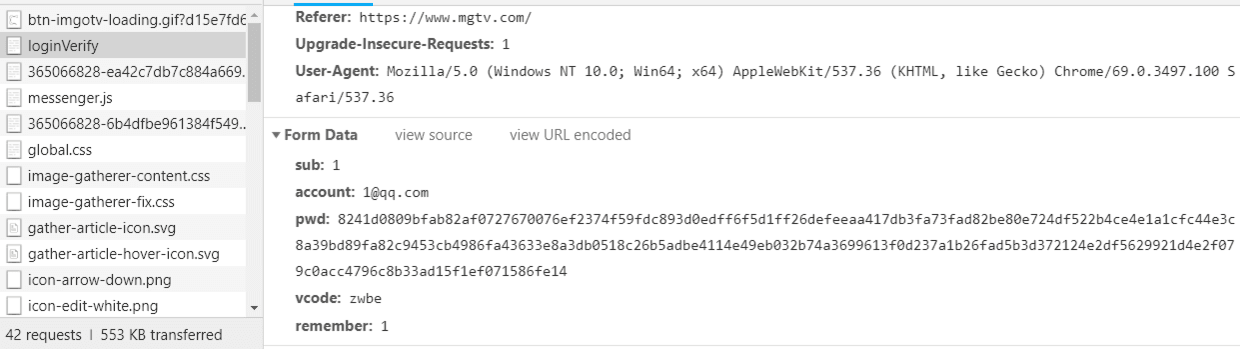
这么长一大串,啥加密啊,看不出来了。你看出来了?那你就🐂比了...接下来要怎么办?定位加密! 套路都是这样,这套路走不通,那就换个套路..
根据 pwd 搜出来只有一个 JS 文件,八九不离十就是它了。点进去
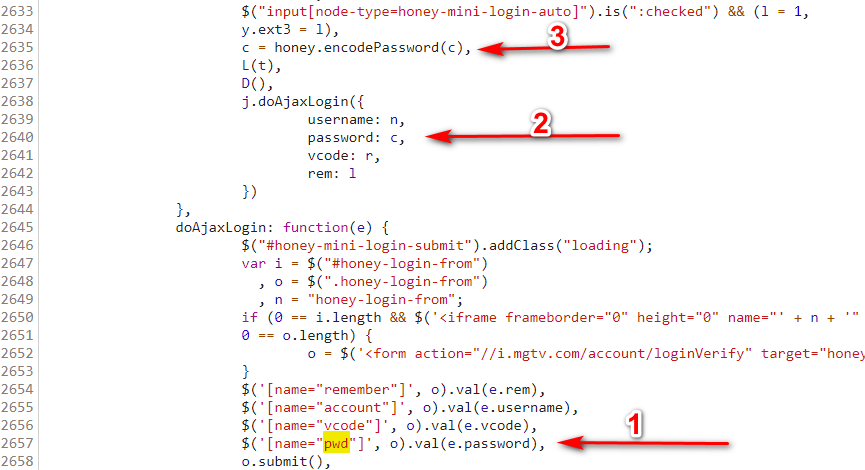
真好!都在一个文件里面,这加密简单啊,一锅端!关键就是 honey.encodePassword() 这个函数了。
扣代码
找到加密位置了,这时候函数是点不进去的,需要你重发请求,然后按住 ctrl 左击点击进去,记得提前打上断点噢
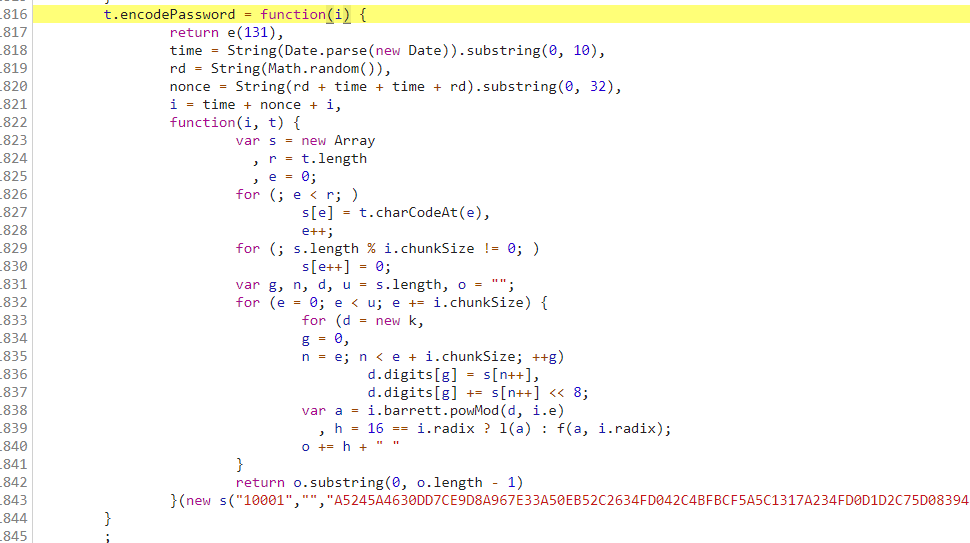
直接复制到本地调试下吧,不出意外的话,后面的代码你都需要复制下来,而不是图片上面这一点点...本地调试需做小小改动,如下:
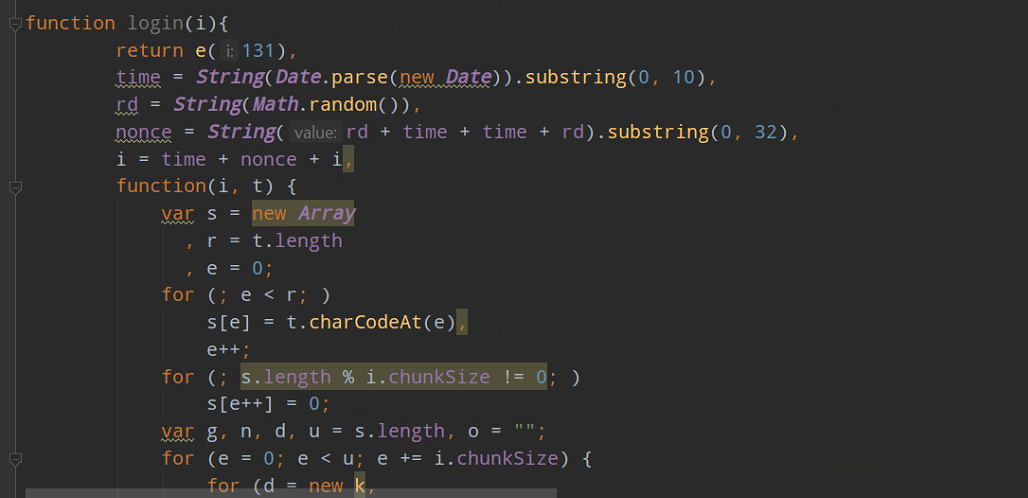
直接在本地输入密码,运行走一波,

我以为破案了。嗯哼,本地运行的结果和抓包的 pwd 不同,出问题啦? 还是用代码来做个小小的验证吧...
验证
这个网站登录需要输入图片验证码,其实这验证码是很规整的那种,这里只是验证一下,就手动输入一下吧。。。同理也是要先抓包,看请求,手动输入验证码部分代码..
captcha_url = f"https://i.mgtv.com/vcode?from=pcclient&time={int(time.time() * 1000)}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36"
}
captcha_res = session.get(captcha_url, headers=headers)
with open("captcha.jpg", "wb") as f:
f.write(captcha_res.content)
code = input("请输入验证码: ")
下面的是执行 JS 获取加密后结果部分
def get_pwd(s):
js_path = "login.js"
with open(js_path, 'r', encoding="utf-8") as f:
js_content = f.read()
ctx = execjs.compile(js_content)
new_pwd = ctx.call("login", s)
return new_pwd
前面两部分都完成了,剩下就是构造请求 data,发送请求,验证结果了..这就不需要贴了吧.. 记得,记得要用 session 噢,就是发送验证码以及登录的请求记得用 session 来请求,否则你就自己加 cookie, 我想没人会那么做....结果验证是正确的..
嗯。摸鱼的时光就这么过去了,下次再见~看到这里就帮忙点个赞吧...

