

在今天的这篇文章中,我们将来学习如何运用Elasticsearch来对我们的数据进行分析及一些关于Analyzer的介绍。在学习这个之前,我们必须完成之前的练习:
开始使用Elasticsearch (1)-- 如何对文档进行操作
开始使用Elasticsearch (2)-- 如何对数据进行搜索
我们使用前面两个练习所使用的文章建立我们的index,并在这篇文章中进行使用。
分析数据对很多的企业非常重要。它可以帮我们很快地分析出生产,运营中出现的问题,并实时地进行纠正或报警。
Aggregation简介
聚合框架有助于基于搜索查询提供聚合数据。它基于称为聚合的简单构建块,可以组合以构建复杂的数据摘要。
聚合可以被视为在一组文档上构建分析信息的工作单元。执行的上下文定义了该文档集的内容(例如,在执行的查询的上下文中执行顶级聚合/搜索请求的过滤器)。
有许多不同类型的聚合,每个聚合都有自己的目的和输出。为了更好地理解这些类型,通常更容易将它们分为四个主要方面:
- Bucketing
构建存储桶的一系列聚合,其中每个存储桶与密钥和文档标准相关联。执行聚合时,将在上下文中的每个文档上评估所有存储桶条件,并且当条件匹配时,文档被视为“落入”相关存储桶。在聚合过程结束时,我们最终会得到一个桶列表 - 每个桶都有一组“属于”它的文档。
- Metric
在一组文档中跟踪和计算指标的聚合。
- Martrix
一系列聚合,它们在多个字段上运行,并根据从请求的文档字段中提取的值生成矩阵结果。与度量标准和存储区聚合不同,此聚合系列尚不支持脚本。
- Pipeline
聚合其他聚合的输出及其关联度量的聚合
接下来是有趣的部分。由于每个存储桶(bucket)有效地定义了一个文档集(属于该bucket的所有文档),因此可以在bucket级别上关联聚合,并且这些聚合将在该存储桶的上下文中执行。这就是聚合的真正力量所在:聚合可以嵌套!
注意一:bucketing聚合可以具有子聚合(bucketing或metric)。 将为其父聚合生成的桶计算子聚合。 嵌套聚合的级别/深度没有硬性限制(可以在“父”聚合下嵌套聚合,“父”聚合本身是另一个更高级聚合的子聚合)。
注意二:聚合可以操作于double类型的上限的数据。 因此,当在绝对值大于2 ^ 53的long上运行时,结果可能是近似的。
Aggregation请求是搜索API的一部分,它可以带有一个query的结构或者不带。
聚合操作
简单地说,聚合的语法是这样的:
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
通常,我们也可以使用aggs来代替上面的“aggregations”。
下面,我们来针对我们的数据来进行一些简单的操作,这样可以使得大家更加明白一些。
range聚合
我们可以把用户进行年龄分段,查出来在不同的年龄段的用户:
GET twitter/_search
{
"size": 0,
"aggs": {
"age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
}
}
}
}
在这里,我们使用range类型的聚合。在上面我们定义了不同的年龄段。通过上面的查询,我们可以得到不同年龄段的bucket。显示的结果是:
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"age" : {
"buckets" : [
{
"key" : "20.0-30.0",
"from" : 20.0,
"to" : 30.0,
"doc_count" : 0
},
{
"key" : "30.0-40.0",
"from" : 30.0,
"to" : 40.0,
"doc_count" : 3
},
{
"key" : "40.0-50.0",
"from" : 40.0,
"to" : 50.0,
"doc_count" : 0
}
]
}
}
}
在上面,我们也注意到,我们把size设置为0。这是因为针对聚合,我们并不关心返回的结果。加入我们设置为1的话,我们可以看到如下的输出:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"user" : "东城区-老刘",
"message" : "出发,下一站云南!",
"uid" : 3,
"age" : 30,
"city" : "北京",
"province" : "北京",
"country" : "中国",
"address" : "中国北京市东城区台基厂三条3号",
"location" : {
"lat" : "39.904313",
"lon" : "116.412754"
}
}
}
]
},
"aggregations" : {
"age" : {
"buckets" : [
{
"key" : "20.0-30.0",
"from" : 20.0,
"to" : 30.0,
"doc_count" : 0
},
{
"key" : "30.0-40.0",
"from" : 30.0,
"to" : 40.0,
"doc_count" : 3
},
{
"key" : "40.0-50.0",
"from" : 40.0,
"to" : 50.0,
"doc_count" : 0
}
]
}
}
}
从这里,我们可以看出来,在我们的输出中,也看到了其中的一个文档的输出。
terms聚合
我们也可以通过term聚合来查询某一个关键字出现的频率。在如下的term聚合中,我们想寻找在所有的文档出现”Happy birthday”里按照城市进行分类的一个聚合。
GET twitter/_search
{
"query": {
"match": {
"message": "happy birthday"
}
},
"size": 0,
"aggs": {
"city": {
"terms": {
"field": "city.keyword",
"size": 10
}
}
}
}
注意在这里,我们使用的是city.keyword 而不是city。注意这里的10指的是前10名的城市。聚合的结果是:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"city" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "北京",
"doc_count" : 2
},
{
"key" : "上海",
"doc_count" : 1
}
]
}
}
}
在上面,我们可以看出来,在所有的含有"Happy birthday"的文档中,有两个是来自北京的,有一个是来自上海。
我们也可以使用cardinality聚合来统计到底有多少个城市:
GET twitter/_search
{
"size": 0,
"aggs": {
"number_of_cities": {
"cardinality": {
"field": "city.keyword"
}
}
}
}
运行上面的查询,我们可以看到结果是:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 7,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"number_of_cities" : {
"value" : 2
}
}
它显示我们有两个城市:北京及上海。它们在文档中虽然出现多次,但是从唯一性上,只有两个城市。
我们可以使用Metrics来统计我们的数值数据,比如我们想知道所有用户的平均年龄是多少?我们可以用下面的聚合:
GET twitter/_search
{
"size": 0,
"aggs": {
"average_age": {
"avg": {
"field": "age"
}
}
}
}
我们的返回的结果是:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"average_age" : {
"value" : 47.0
}
}
}
所有人的平均年龄是47岁。我们也可以对整个年龄进行一个统计,比如:
GET twitter/_search
{
"size": 0,
"aggs": {
"age_stats": {
"stats": {
"field": "age"
}
}
}
}
统计的结果如下:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"age_stats" : {
"count" : 5,
"min" : 30.0,
"max" : 90.0,
"avg" : 47.0,
"sum" : 235.0
}
}
}
在这里,我们可以看到到底有多少条数据,并且最大,最小的,平均值及加起来的合都在这里一起显示。
我们也可以只得到这个年龄的最大值:
GET twitter/_search
{
"size": 0,
"aggs": {
"age_max": {
"max": {
"field": "age"
}
}
}
}
显示的结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"age_max" : {
"value" : 90.0
}
}
}
聚合通常适用于从聚合文档集中提取的值。可以使用聚合体内的字段键从特定字段提取这些值,也可以使用脚本提取这些值。我们可以通过script的方法来对我们的aggregtion结果进行重新计算:
GET twitter/_search
{
"size": 0,
"aggs": {
"average_age_1.5": {
"avg": {
"field": "age",
"script": {
"source": "_value * params.correction",
"params": {
"correction": 1.5
}
}
}
}
}
}
上面的这个聚合可以帮我们计算平均值再乘以1.5倍的结果。运行一下的结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"average_age_1.5" : {
"value" : 70.5
}
}
}
显然我们的结果是之前的47的1.5倍。
我们也可以直接使用script的方法来进行聚合。在这种情况下,我们可以不指定特定的field。我们可能把很多项进行综合处理,并把这个结果来进行聚合:
GET twitter/_search
{
"size": 0,
"aggs": {
"average_2_times_age": {
"avg": {
"script": {
"source": "doc['age'].value * params.times",
"params": {
"times": 2.0
}
}
}
}
}
}
在这里我们完全没有使用field这个项。我们直接使用script来形成我们的聚合:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"average_2_times_age" : {
"value" : 94.0
}
}
}
Percentile aggregation
百分位数(percentile)表示观察值出现一定百分比的点。例如,第95个百分位数是大于观察值的95%的值。该聚合针对从聚合文档中提取的数值计算一个或多个百分位数。 这些值可以从文档中的特定数字字段中提取,也可以由提供的脚本生成。
百分位通常用于查找离群值。 在正态分布中,第0.13和第99.87个百分位数代表与平均值的三个标准差。 任何超出三个标准偏差的数据通常被视为异常。这在统计的角度是非常有用的。
我们现在来通过一个简单的例子来展示Percentile aggregation的用法:
GET twitter/_search
{
"size": 0,
"aggs": {
"age_quartiles": {
"percentiles": {
"field": "age",
"percents": [
25,
50,
75,
100
]
}
}
}
}
在上面,我们使用了以叫做age的字段。它是一个数值的字段。我们通过percentile aggregation可以得到25%,50%及75%的人在什么范围。显示结果是:
"aggregations" : {
"age_quartiles" : {
"values" : {
"25.0" : 30.0,
"50.0" : 32.5,
"75.0" : 50.0,
"100.0" : 90.0
}
}
}
我们可以看到25%的人平均年龄是低于30岁,而50%的人的年龄是低于32.5岁,而所有的人的年龄都是低于90岁的。这里的50%的年龄和我们之前计算的平均年龄是不一样的。
GET twitter/_search
{
"size": 0,
"aggs": {
"avarage_age": {
"avg": {
"field": "age"
}
}
}
}
这个平均年龄是:
"aggregations" : {
"avarage_age" : {
"value" : 42.5
}
}
如果你想对aggregation有更多的了解的话,那么可以阅读我的另外文章
Analyzer简介
我们知道Elasticsearch可以实现秒级的搜索速度,其中很重要的一个原因就当一个文档被存储的时候,同时它也对文档的数据进行了索引(indexing)。这样在以后的搜索中,就可以变得很快。简单地说,当一个文档进入到Elasticsearch时,它会经历如下的步骤:
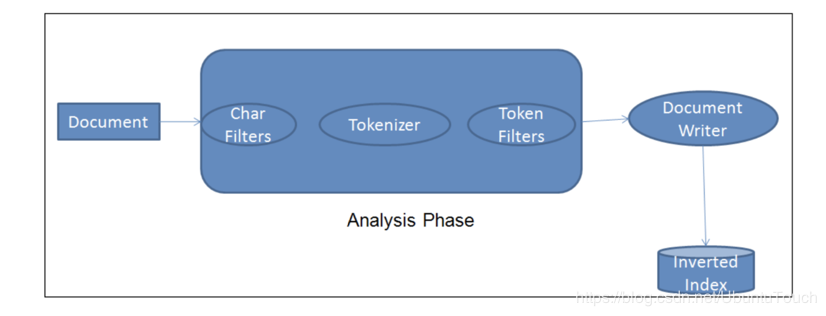
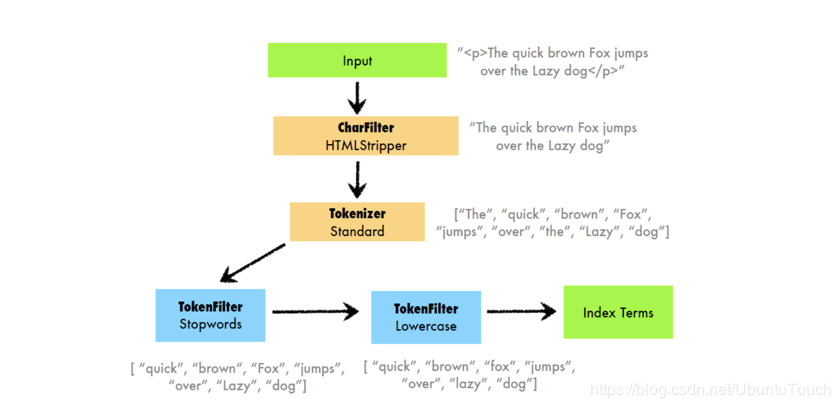
中间的那部分就叫做Analyzer。我们可以看出来,它分为三个部分:Char Filters, Tokenizer及 Token Filter。它们的作用分别如下:
-
Char Filter: 字符过滤器的工作是执行清除任务,例如剥离HTML标记。
-
Tokenizer: 下一步是将文本拆分为称为标记的术语。 这是由tokenizer完成的。 可以基于任何规则(例如空格)来完成拆分。 有关tokennizer的更多详细信息,请访问以下URL:www.elastic.co/guide/en/el…
-
Token filter: 一旦创建了token,它们就会被传递给token filter,这些过滤器会对token进行规范化。 Token filter可以更改token,删除术语或向token添加术语。
Elasticsearch已经提供了比较丰富的analyzer。我们可以自己创建自己的token analyzer,甚至可以利用已经有的char filter,tokenizer及token filter来重新组合成一个新的analyzer,并可以对文档中的每一个字段分别定义自己的analyzer。如果大家对analyzer比较感兴趣的话,请参阅我们的网址https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html。
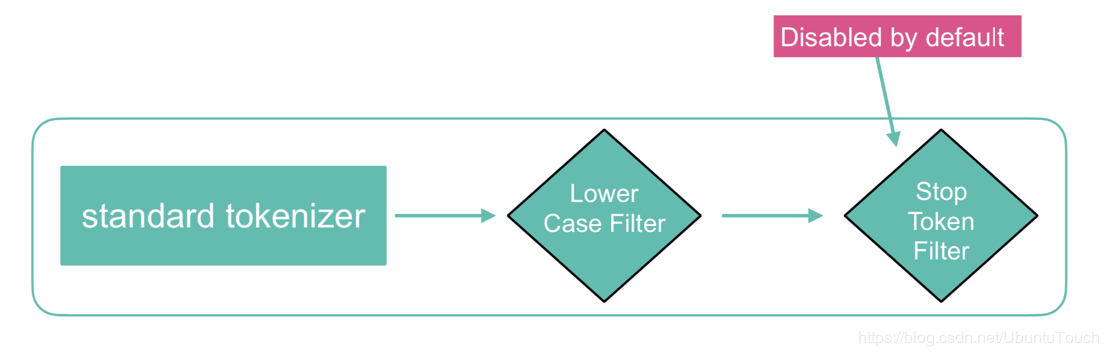
在默认的情况下,standard analyzer是Elasticsearch的缺省分析器:
-
没有 Char Filter
-
使用standard tokonizer
-
把字符串变为小写,同时有选择地删除一些stop words等。默认的情况下stop words为_none_,也即不过滤任何stop words。
下面我们简单地展示一下我们的analyzer是如何实现的。
GET twitter/_analyze
{
"text": [
"Happy Birthday"
],
"analyzer": "standard"
}
在上面的接口中,我们使用标准的analyzer来对字符串"Happy birthday"来分析,那么如下就是我我们看到的结果。
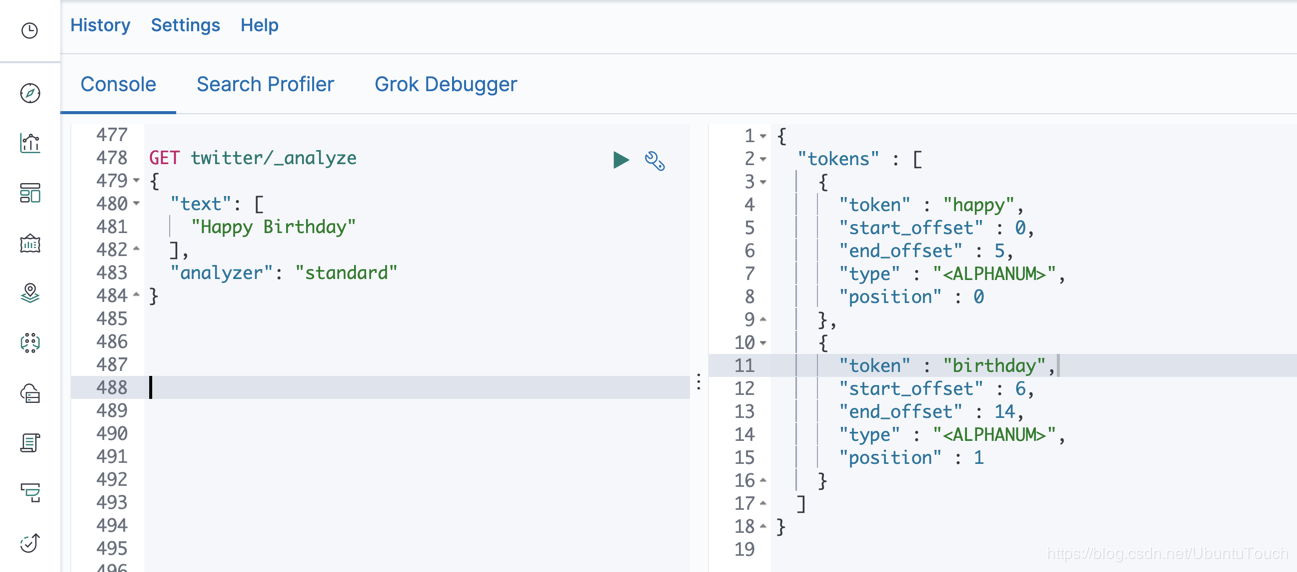
我们可以看到有两个token: happy和birthday。两个token都变成小写的了。同时我们也可以看到它们在文档中的位置信息。
很多人很好奇,想知道中文字的切割时怎么样的。我们下面来做一个简单的实验。
GET twitter/_analyze
{
"text": [
"生日快乐"
],
"analyzer": "standard"
}
那么下面就是我们想看到的结果:
{
"tokens" : [
{
"token" : "生",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "日",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "快",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "乐",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
}
]
}
我们可以看到有四个token,并且它们的type也有所变化。
GET twitter/_analyze
{
"text": [
"Happy.Birthday"
],
"analyzer": "simple"
}
显示的结果是:
{
"tokens" : [
{
"token" : "happy",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
},
{
"token" : "birthday",
"start_offset" : 6,
"end_offset" : 14,
"type" : "word",
"position" : 1
}
]
}
我们可以看到在我们的字符串中的"."也被正确认识,并作为分隔符把Happy.Birthday切割为两个token。
GET twitter/_analyze
{
"text": ["Happy Birthday"],
"tokenizer": "keyword"
}
当我们使用keyword分析器时,我们可以看到上面的整个字符串无论有多长,都被当做是一个token。这个对我们的term相关的搜索及聚合是有很大的用途的。上面的分析结果显示:
{
"tokens" : [
{
"token" : "Happy Birthday",
"start_offset" : 0,
"end_offset" : 14,
"type" : "word",
"position" : 0
}
]
}
我么也可以使用filter处理我们的token,比如:
GET twitter/_analyze
{
"text": ["Happy Birthday"],
"tokenizer": "keyword",
"filter": ["lowercase"]
}
经过上面的处理,我们的token变成为:
{
"tokens" : [
{
"token" : "happy birthday",
"start_offset" : 0,
"end_offset" : 14,
"type" : "word",
"position" : 0
}
]
}
大家如果对anaylyzer感兴趣的话,可以读更多的资料:www.elastic.co/guide/en/el…
大家可以参阅我更及进一步的学习文档:Elasticsearch: analyzer。
至此,我们基本上已经完成了对Elasticsearch最基本的了解。上面所有的script可以在如下的地址下载:
如果你想了解更多关于Elastic Stack相关的知识,请参阅我们的官方网站:www.elastic.co/guide/index…
