

咳咳,大家好,我是韩数,祝大家圣诞节快乐啊啊啊啊啊,我来晚了。
前言:
在上一篇文章Hadoop伪分布式环境搭建中,我们可谓事无巨细地非常完美的配置了Hadoop的伪分布式运行模式,不仅如此,同时我们还学习了一种新的编程思想-面向配置文件编程。
我相信认真看到最后的朋友现在配置一个Hadoop伪分布式环境肯定都是轻轻松松的,可是,当我看到那么一丢丢丢丢阅读量的时候,我就知道最后没多少人配置成功了(不开森)。
上一篇文章我们虽然配置了Hadoop的伪分布式模式,但是我相信很多人内心是很迷糊的,那种感觉就像是好不容易找到了一个女朋友,却没有体会到任何有女朋友的感觉,上一章我们配置了HDFS,Yarn,历史服务器,日志服务器,配置是配置成功了,最后也跑起来了,然后呢?我这半天都配了个啥???而且最重要的MapReduce呢,我连个影子也没见到啊,放心,今天这篇番外篇就是为了回答你们这些疑问的,今天这篇文章,我们将通过运行Hadoop官方示例WordCount,来实地考察一下,日志服务器,历史服务器,Yarn是怎么工作的。
不废话,直接上东西。
官方示例介绍:
之前在Hadoop目录介绍中我们说,Hadoop官方给出了很多示例程序,今天我们主要用的是最最经典的WordCount程序,为什么说它是最经典的呢,这个其实我也不知道,因为非常多的资料都用的是这个例子,所以我们这次也用它。WordCount这个程序是干啥的呢,就是计算一个文件中单词出现的频率,比如下面这段内容:
hanshu is so cool
hanshu zui shuai
hanshu wu di shuai
那最后的运行结果就是:
cool 1
di 1
hanshu 3
is 1
shuai 2
so 1
wu 1
zui 1
这么一看我相信大家都已经明白wordCount是干啥的了。
官方示例WordCount运行:
Hadoop运行官方示例有两种方式,一种是直接运行,另一种则是使用Yarn运行,不用说,肯定是第二种好,为什么我们后面说。
环境准备:
在运行之前呢,我们需要先把我们上一篇文章中配置的NameNode,DataNode,Yarn,历史服务器,文件服务器一溜烟的全都给它跑起来,启动代码如下:
#启动NameNode
sbin/hadoop-daemon.sh start namenode
#启动DtaNode
sbin/hadoop-daemon.sh start datanode
#启动 resourcemanager
sbin/yarn-daemon.sh start resourcemanager
#启动nodemanager
sbin/yarn-daemon.sh start nodemanager
#启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver
这才五天,不会忘了吧。我相信聪明的你们肯定没有。
执行jps命令,当出现下面这些则意味着我们就算全部启动成功了。
[hanshu@hadoop100 hadoop-2.7.2]$ jps
6256 DataNode
6778 NodeManager
7066 JobHistoryServer
6526 ResourceManager
6191 NameNode
7167 Jps
为了方便测试,我们在Hadoop安装目录下新建一个input文件夹,并在input文件夹里面新建一个wc.input文件,内容为:
hanshu is so cool
hanshu zui shuai
hanshu wu di shuai
建文件夹什么的命令我就不展示了,基本操作,基本操作。
当然,大家如果对自己的颜值有信心且脸皮比较厚的话也可以把hanshu替换成自己的名字,不过不管你们怎么换,反正我是凭实力写上去的。(哼)
运行WordCount:
首先在我们的文件系统中新建一个文件夹,路径为/user/hanshu/input
[hanshu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/hanshu/input
然后将我们上文中的测试文件wc.input上传到我们的文件系统中
[hanshu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -put input/wc.input /user/hanshu/input/
查看文件是否上传成功:
[hanshu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -ls /user/hanshu/input/
Found 1 items
-rw-r--r-- 1 hanshu supergroup 54 2019-12-26 16:45 /user/hanshu/input/wc.input
如果有就是意味着上传成功了。
运行我们的官方WordCount程序:
[hanshu@hadoop100 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hanshu/input/ /user/hanshu/output
19/12/26 16:58:40 INFO client.RMProxy: Connecting to ResourceManager at localhost/127.0.0.1:8032
...略
19/12/26 16:59:23 INFO mapreduce.Job: map 100% reduce 0%
19/12/26 16:59:40 INFO mapreduce.Job: map 100% reduce 100%
19/12/26 16:59:40 INFO mapreduce.Job: Job job_1577349009148_0001 completed successfully
最后这三行map 100% reduce 0%,代表就是我们MapReduce中的,Map和Reduce过程,可以看到是先执行Map,然后再执行Reduce,不理解? 没关系,后面我们MR专题我们再详细的分析MR的一个执行流程是怎么样的,保证讲的透透的。
运行成功之后,我们通过命令行看一下最后的计算结果是什么样的:
[hanshu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/hanshu/output/*
cool 1
di 1
hanshu 3
is 1
shuai 2
so 1
wu 1
zui 1
我们的词频就正确的统计出来了,这个时候肯定有小伙伴要问了
这个答案和你刚开始猜的那个答案一摸一样!,太厉害了吧,韩数,你是心算出来的答案吗?
哈哈哈哈哈哈,nonono,其实我刚开始前面就没填答案,运行结果出来我复制过去的,机智如我。
访问一下HDFS的在线web管理程序,看看output里面都有啥,发现只有两个文件,去掉那个_SUCCESS,结果自然就存在我们的part-r-00000文件里面了,当然也可以在网页端下载到本地,然后打开查看结果,还是用命令行吧。
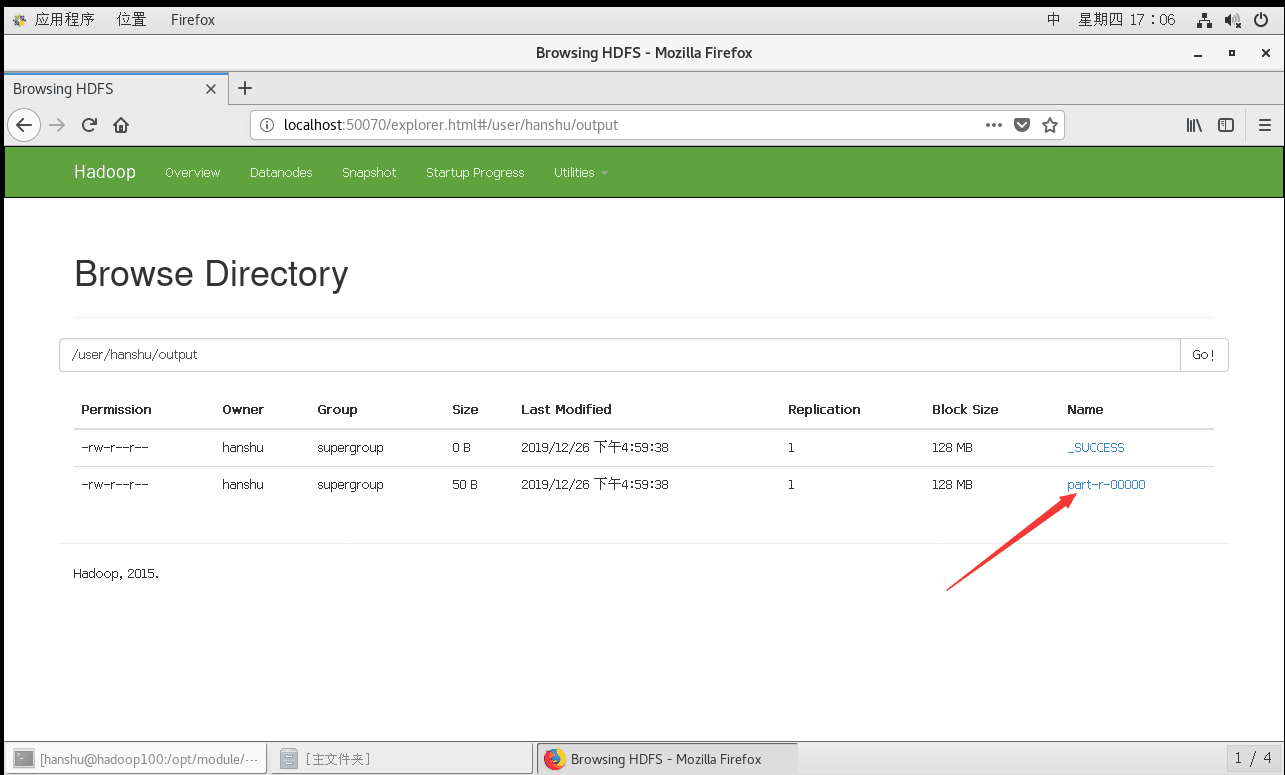
这个时候又有人要问了,为啥要去掉_SUCCESS这个文件,为什么结果就一定不在_SUCCESS这个文件里面?
这个很好猜的好吧,因为SUCCESS的文件大小是0.
对了,忘了一个东西,历史服务器给忘了,这个时候我们打开之前配置的历史服务器:
http://localhost:19888/jobhistory
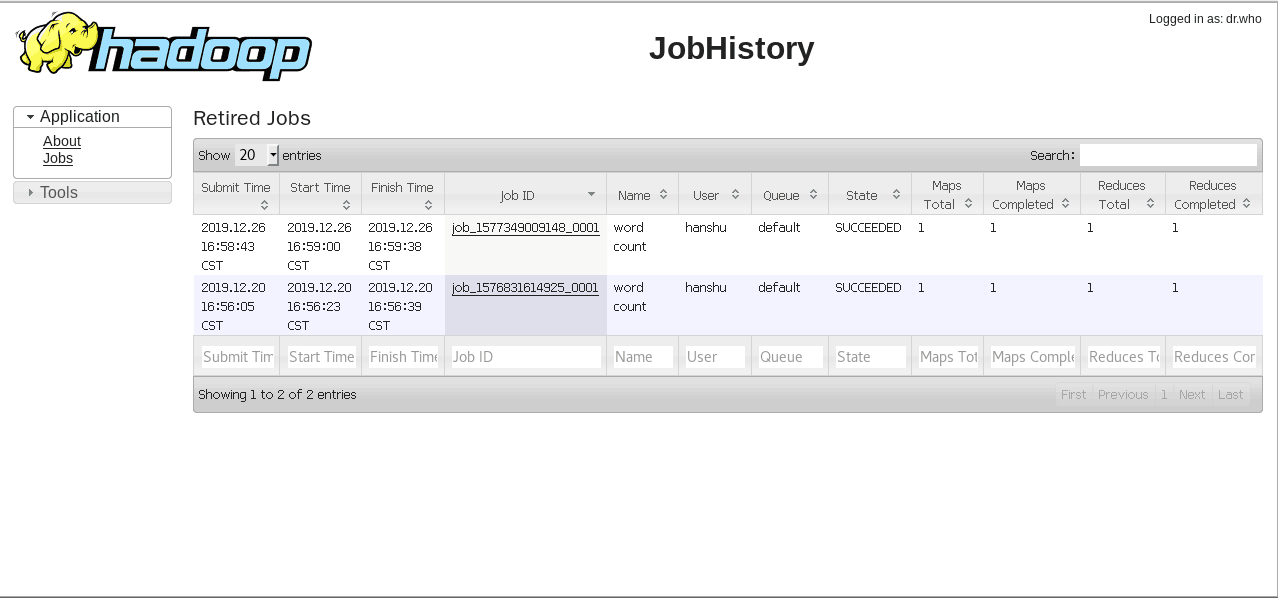
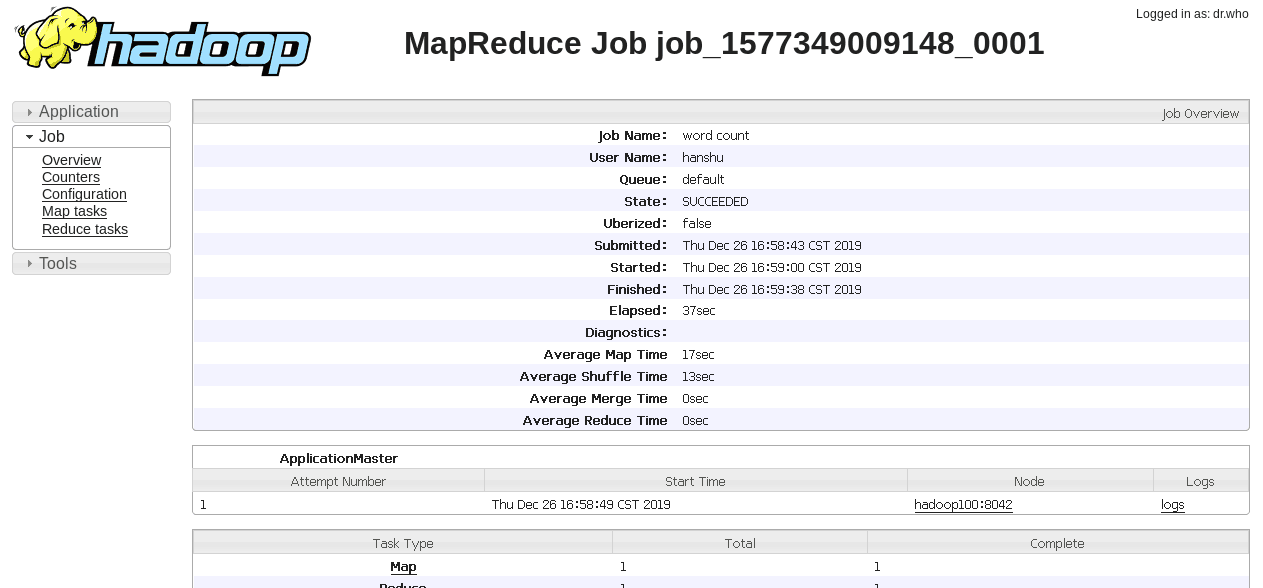
看到了吧,起作用了,随便点进去看看,发现日志服务器也起作用了。
再看Yarn
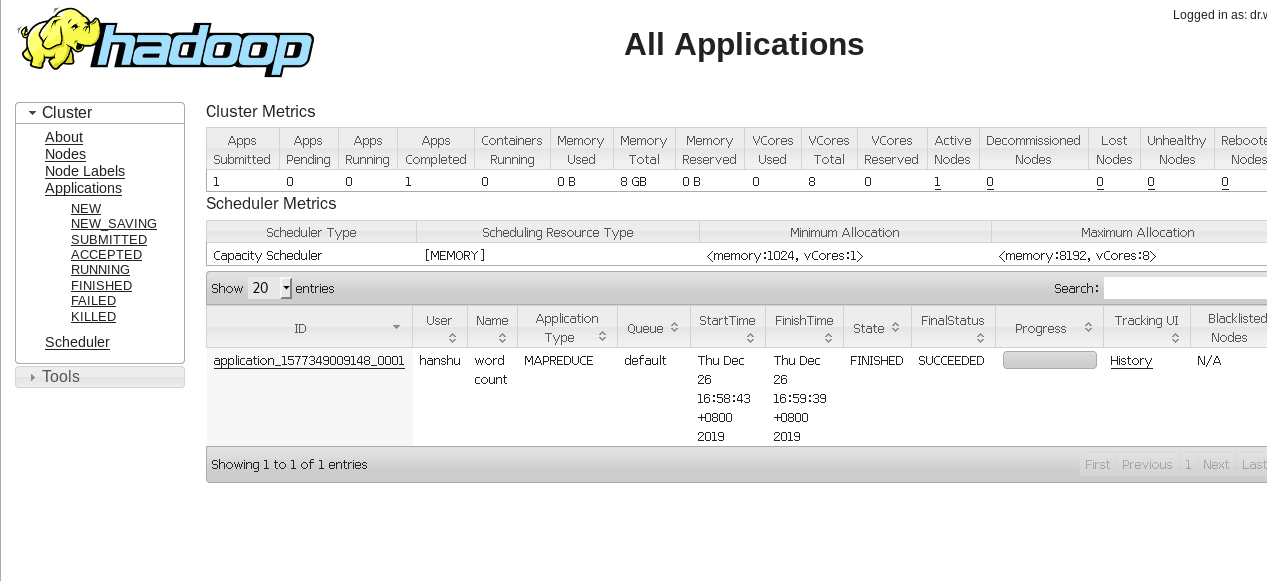
这个时候可能又有人要疑问了,不对啊,按理说,你这不是直接运行吗,没有经过Yarn,可为什么Yarn上也有内容呢,这个时候就要请大家仔细回忆一下,我们上一篇文章中配置Yarn的时候,是不是加入了这么一行配置:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
到这里真相就大白了,由于我们之前指定只要是MR程序,就要交给Yarn托管运行,Yarn负责资源的调度,由于之前我们配置了Yarn,自然我们这次运行的wordCount也会出现在Yarn web管理工具上面显示了。
而第一种方式我们说的直接运行MR程序,则是在我们仅仅只配置好HDFS的时候运行的,当然,感兴趣的小伙伴可以自己试一下,不过,我已经替各位试过了, 我们删除之前的配置代码,使其不运行在Yarn上,并重启resourcemanager和nodemanager使修改生效。
什么?不会重启?先stop 再 start。
第二个也是最重要的一步,删除我们之前生成的/user/hanshu/ouput文件夹,因为如果输出文件夹存在的话,运行MR程序是会报错误的,所以在执行前我们一定把它删掉。
[hanshu@hadoop100 hadoop-2.7.2]$ hadoop fs -rm -r /user/hanshu/output
再次执行我们的WordCount程序(非Yarn)
[hanshu@hadoop100 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hanshu/input/ /user/hanshu/output
查看结果,依然是正确的结果。
注意了,这个时候我们点开Yarn的web管理工具,会发现什么,空空如也,当然我现在没办法给你们截图了,因为我刚才忘了,现在回不去那个界面了,emmm,反正大家知道就行了,Yarn管理网页里面空空如也,并没有出现新的记录,同时我们的历史服务器,也并没有出现新的记录,不配置Yarn简直就是裸奔式的运行,我悄悄的来了,不留下一丝云彩。
所以,并不建议大家直接运行MR,要不Yarn人家干啥,对吧,所以以后还是一定要把MR程序托管到Yarn上运行,调度起来,跑起来,发挥出我们分布式并行计算的威力,当然,现在我们谈不上分布式,一台电脑,分布式分不动,后面我们多台虚拟机的时候,就会体验到真实的分布式并行计算的魅力了。
下面开始技术总结:
今天呢,我们并没有讲很多太新鲜的知识,而是通过运行官方给出的wordCount程序,知道了Yarn,日志服务器,历史服务器是干啥用的,这个非常重要,不知道他们干啥用的,我们配置他们干啥。下一篇文章是不是就上真的分布式了?这个还不能,因为配置真正的分布式集群我们需要很多的准备工作,下一步呢,我们主要是实现一个分布式的分发脚本,这样以后改了配置就可以直接分发到各个机器上,而不需要我们在那施展半天乾坤大挪移了。
非常感谢能读到这里的朋友,你们的支持和关注是我坚持高质量分享下去的动力。
相关代码和文档已经上传至本人github。一定要点个star啊啊啊啊啊啊啊
万水千山总是情,给个star行不行
欢迎点赞,关注我,有你好果子吃(滑稽)
溜了溜了,作业还没写完,emmm。拜拜,我们下一篇文章再见!
