

约会被拒
上次给娜娜教完【金三银四】《HashMap图解原理与数据结构》之后,娜娜自信满满的去面试了。
今天我约娜娜出来看电影。娜娜没心情。
娜娜面试又被虐了,辛巴哥哥很难受,因为周末没人陪我去看电影了,我决定要帮帮娜娜小姐姐。
回到过去
先自我介绍下 你好,早上、中午、下午、晚上好。我是狮子王辛巴。一名无缘985,日常996工程师。

JDK1.8以前HashMap底层数据结构和算法:
数组+链表+哈希算法
数组
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);对于一般的插入删除操作, 涉及到数组元素的移动,其平均复杂度也为O(n)

//数组:采用一段连续的存储单元来存储数据。
//特点:指定下标O(1) 删除插入O(N) 数组:查询快 插入慢 ArrayList
public static void main(String[] args) {
Integer[] integers = new Integer[10];
integers[0]=0;//王五
integers[1]=1;
integers[2]=2;
integers[9]=9;
链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1), 而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
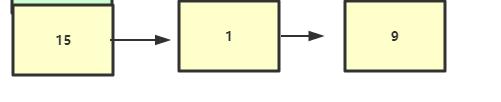
public class Node {
public Node next;
private Object data;
public Node(Object data) {
this.data = data;
}
//链表:链表是一种物理存储单元上非连续、非顺序的存储结构
//特点:插入、删除时间复杂度O(1) 查找遍历时间复杂度0(N) 插入快 查找慢
public static void main(String[] args) {
Node node=new Node(15);
node.next=new Node(1);
node.next.next=new Node(9);
}
哈希算法
哈希算法(也叫散列),就是把任意长度值(Key)通过散列算法变换成固定长度的key地址,通过这个地址进行访问的数据结构。 它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
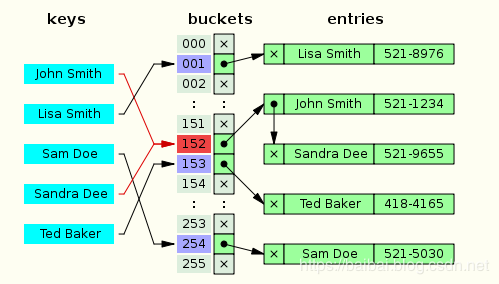
JDK1.8以后HashMap底层数据结构变化:
数组+链表+红黑树+哈希算法 嗯新增了红黑树。

为什么要红黑树
在jdk7之前hashmap极端情况可能会出现这种情况
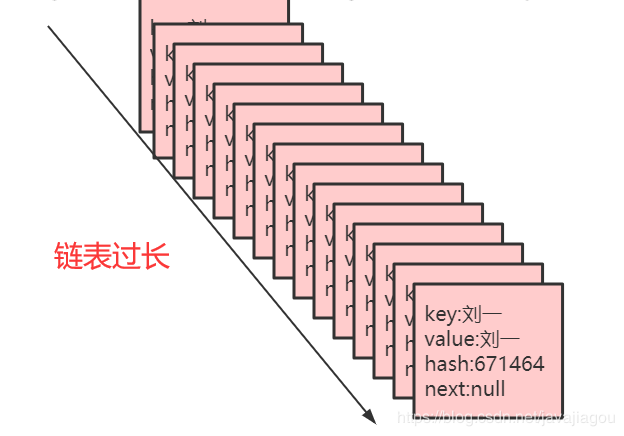

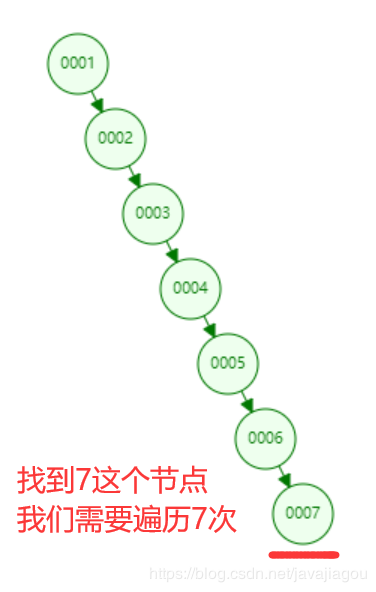
链表过长会出现什么问题了?
链表过长会出现遍历过长,我们说一个算法好与坏时间复杂度来决定,而这种链表的特点是:插入快,查询慢。所以其时间复杂度为O(N)。如图所示:
什么是红黑树
红黑树定义和性质
红黑树是一种含有红黑结点并能自平衡的二叉查找树。它必须满足下面性质:
- 性质1:每个节点要么是黑色,要么是红色。
- 性质2:根节点是黑色。
- 性质3:每个叶子节点(NIL)是黑色。
- 性质4:每个红色结点的两个子结点一定都是黑色。
- 性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
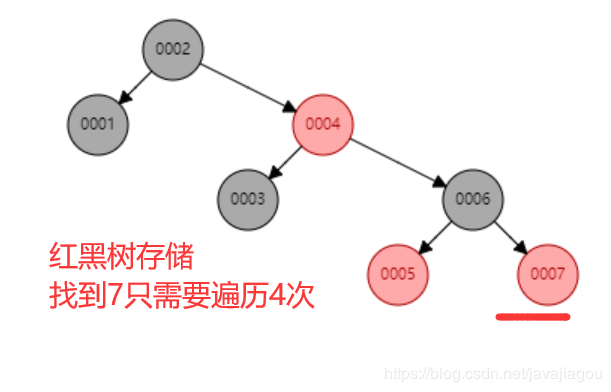
具体是怎么样存储的,我们直接上图 大家就明白了。
遍历规则是:
小中大,左中右
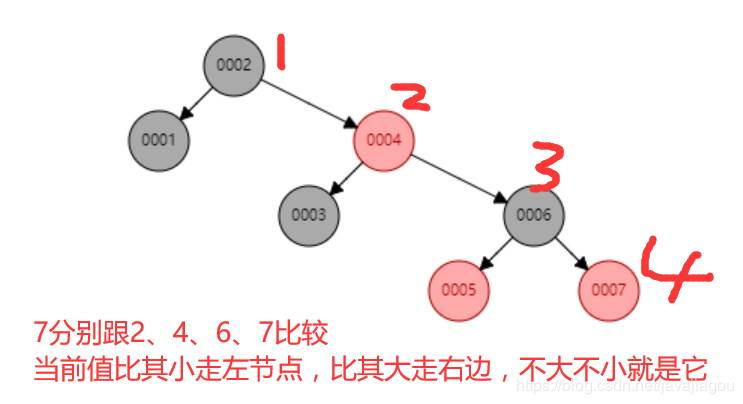
根据上面链表和红黑树查找的规则,我们发现链表找到数字7需要查询7次时间复杂度为O(n),而我们的红黑树只需要查询4次,时间复杂度为O(logn)
HashMap 怎么用红黑树的?
通过上诉列子我们发现红黑树是可以加快遍历查询速度的,因为减少了次数,自然就提高了效率。但是hashmap并不是一上来就直接用红黑树的,来我们看下源码。

put方法

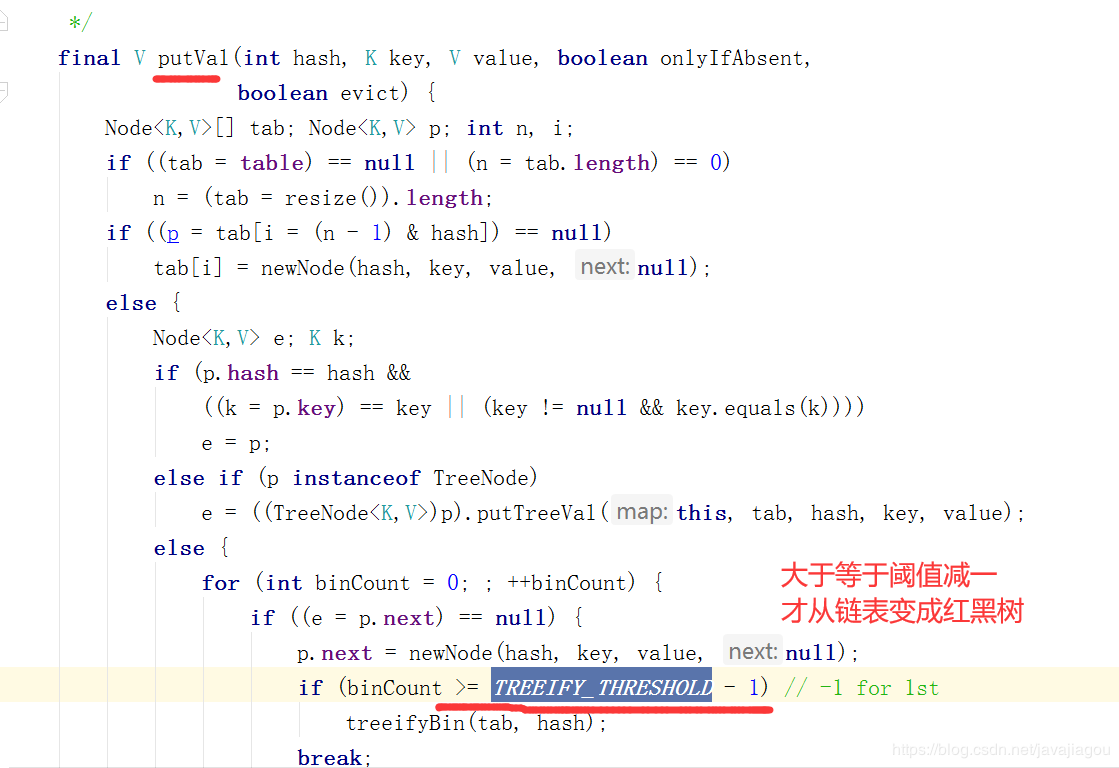
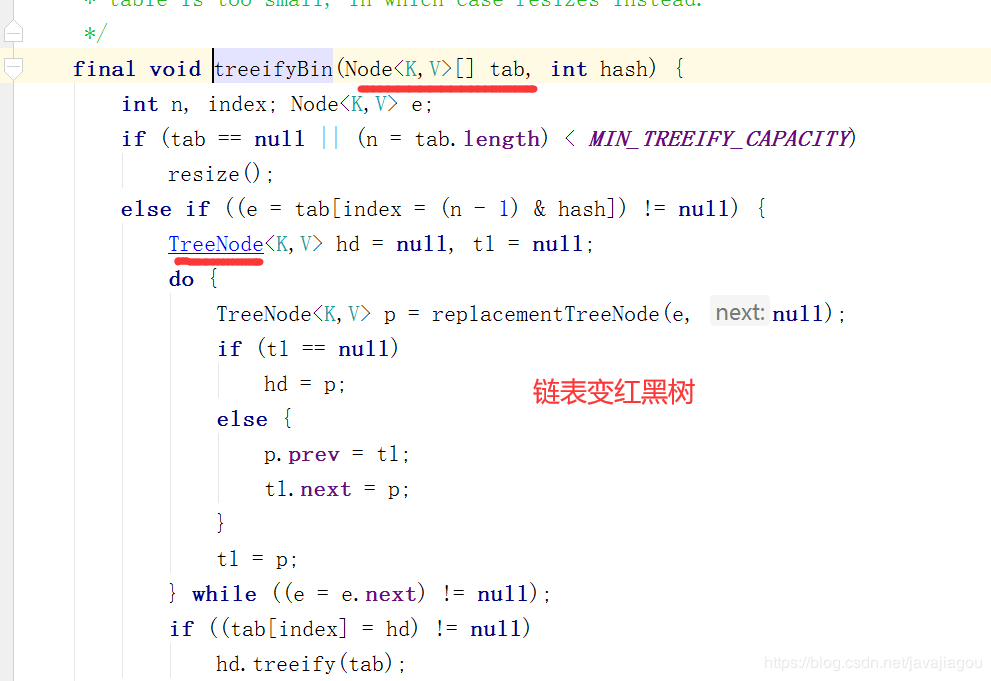
大致源码如图所示。明白了吗?明白了帮我点个赞或者评论下吧。

总结与调优:
当然我还要考考你,为什么要设置阈值8?为什么一上来还是链表了?而是达到阈值条件了才变成红黑树了?
这个问题其实跟鱼和熊掌不可兼得一样的道理:
链表:插入快、查询慢
红黑树:查询快、插入慢
也就是说红黑树虽然遍历快,但是其插入的时候是没有链表快的。因为链表next引用即可,而红黑树需要数据左右交换。所以阈值int TREEIFY_THRESHOLD = 8; 的时候才变成红黑树,这个阈值是根据统计学定理来的哦?
你们想不想知道是什么定理了?可以关注我们的公众号:java大型网站架构 。里头有答案。
调优:
之前娜娜面试的时候被问到过,我们如何对hashmap在开发的时候性能优化?
答:如果我们知道查询出来的数据是固定某个大小的,我们可以事先指定其大小,这样可以加快对put
操作的效率。知道为什么吗?欢迎评论哦

求关注
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是牛人。 白嫖不好,创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见! 微信搜索:Java大型网站架构

