1.什么是死锁?
2.死锁产生的条件?
3.怎样避免死锁?
4.synchronized和Reentrantlock的区别?
5.ReentrantLock实现原理?
6.可重入锁是什么?
7.springboot自动配置原理?
8.事务的隔离级别?解释
9.volatile关键字
10.单例模式实现
11.cas原理
12.ABA问题
13.HTTP状态码
14.谈谈JMM
15.linux修改文件权限
16.linux查看文件的某一行
17.redis数据结构
18.redis线程模型
19.redis为什么快?除了基于内存还有什么原因?
20.垃圾回收算法?新生代用什么?
21.wait()和sleep()的区别?
22.HTTP短连接和长连接
3.怎样避免死锁?
我们可以通过破坏死锁产生的4个必要条件来 避免死锁,由于资源互斥是资源使用的固有特性是无法改变的。
破坏“不可剥夺”条件:一个进程不能获得所需要的全部资源时便处于等待状态,等待期间他占有的资源将被隐式的释放重新加入到 系统的资源列表中,可以被其他的进程使用,而等待的进程只有重新获得自己原有的资源以及新申请的资源才可以重新启动,执行。
破坏”请求与保持条件”:第一种方法静态分配即每个进程在开始执行时就申请他所需要的全部资源。第二种是动态分配即每个进程在申请所需要的资源时他本身不占用系统资源。
破坏“循环等待”条件:采用资源有序分配其基本思想是将系统中的所有资源顺序编号,将紧缺的,稀少的采用较大的编号,在申请资源时必须按照编号的顺序进行,一个进程只有获得较小编号的进程才能申请较大编号的进程。
4.synchronized和Reentrantlock的区别?
相似点:这两个同步方式有很多相似之处,他们都是加锁方式同步,而且都是阻塞式同步,也就是说当一个线程获取对象锁之后,进入同步块,其他访问该同步块的线程都必须阻塞在该同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的(操作系统需要在用户态和内核态之间来回切换,代价很高,不过可以通过对锁优化进行改善)。
功能区别:这两种方式最大的区别就是对于synchronized来说,它是Java语言关键字,是原生语法层面的互斥,需要jvm实现。而ReentrantLock他是jdk1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句来完成 便利性:很明显Synchronized的使用方便简洁,并且由编译器去保证锁的加锁和释放锁,而ReentrantLock则需要手动声明加锁和释放锁的方法,为了避免忘记手动释放锁,最好是在finally中声明释放锁。
锁的细粒度和灵活度:很明显ReenTrantLock优于Synchronized
性能区别:在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞。
1.Synchronized
Synchronized经过编译后,会在同步块前后分别形成monitorenter和monitorexit两个字节码指令,在执行monitorenter指令时,首先要尝试获取对象锁,如果对象没有别锁定,或者当前已经拥有这个对象锁,把锁的计数器加1,相应的在执行monitorexit指令时,会将计数器减1,当计数器为0时,锁就被释放了。如果获取锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
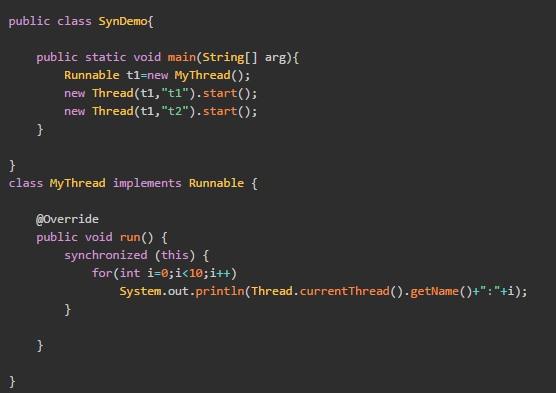
2.ReentrantLock
由于ReentrantLock是java.util.concurrent包下面提供的一套互斥锁,相比Synchronized类提供了一些高级的功能,主要有一下三项:
2.1 等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。通过lock.lockInterruptibly()来实现这个机制。
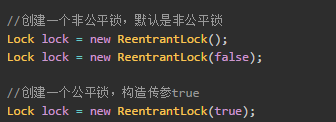
2.2 公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。 公平锁、非公平锁的创建方式:
2.3 锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。ReenTrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。
3.ReenTrantLock实现的原理:
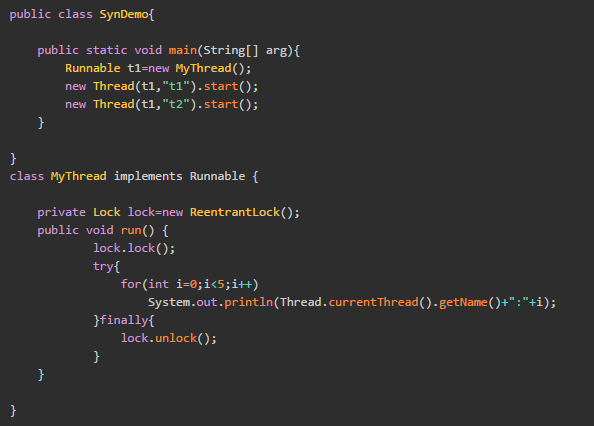
简单来说,ReenTrantLock的实现是一种自旋锁,通过循环调用CAS操作来实现加锁。它的性能比较好也是因为避免了使线程进入内核态的阻塞状态。想尽办法避免线程进入内核的阻塞状态是我们去分析和理解锁设计的关键钥匙。
如果需要使用ReenTrantLock的三个独有功能时,就可以考虑使用ReenTrantLock锁啦。
ReenTrantLock用法如下:
5.可重入锁是什么?
可重入锁,从字面来理解,就是可以重复进入的锁。
可重入锁,也叫做递归锁,指的是同一线程外层函数获得锁之后,内层递归函数仍然有获取该锁的代码,但不受影响。
在JAVA环境下ReentrantLock和synchronized都是可重入锁。
synchronized是一个可重入锁。在一个类中,如果synchronized方法1调用了synchronized方法2,方法2是可以正常执行的,这说明synchronized是可重入锁。否则,在执行方法2想获取锁的时候,该锁已经在执行方法1时获取了,那么方法2将永远得不到执行。
可重入锁在什么场景使用呢?
可重入锁主要用在线程需要多次进入临界区代码时,需要使用可重入锁。具体的例子,比如上文中提到的一个synchronized方法需要调用另一个synchronized方法时。
可重入锁的实现原理是怎么样的?
加锁时,需要判断锁是否已经被获取。如果已经被获取,则判断获取锁的线程是否是当前线程。如果是当前线程,则给获取次数加1。如果不是当前线程,则需要等待。
释放锁时,需要给锁的获取次数减1,然后判断,次数是否为0了。如果次数为0了,则需要调用锁的唤醒方法,让锁上阻塞的其他线程得到执行的机会。
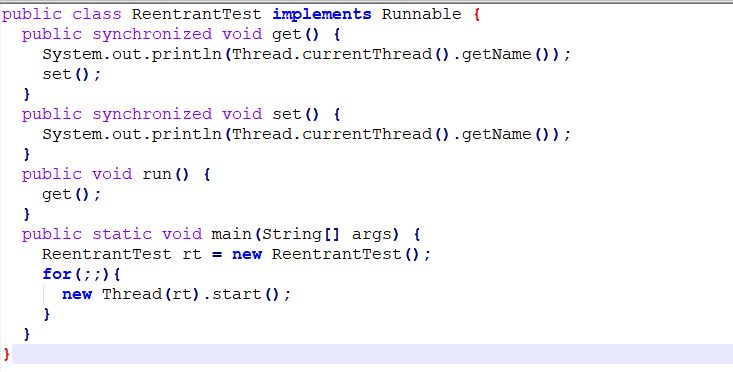
下面是一个用synchronized实现的例子:
Thread-8492
Thread-8492
Thread-8494
Thread-8494
Thread-8495
Thread-8495
Thread-8493
Thread-8493
set()和get()同时输出了线程名称,表明即使递归使用synchronized也没有发生死锁,证明其是可重入的。
15.linux修改文件权限
在终端输入:
chmod o w xxx.xxx
表示给其他人授予写xxx.xxx这个文件的权限 chmod go-rw xxx.xxx
表示删除xxx.xxx中组群和其他人的读和写的权限
其中:
u 代表所有者(user)
g 代表所有者所在的组群(group)
o 代表其他人,但不是u和g (other)
a 代表全部的人,也就是包括u,g和o
r 表示文件可以被读(read)
w 表示文件可以被写(write)
x 表示文件可以被执行(如果它是程序的话) 其中:rwx也可以用数字来代替
r ------------4
w -----------2
x ------------1
- ------------0
行动:
表示添加权限
- 表示删除权限
= 表示使之成为唯一的权限
当大家都明白了上面的东西之后,那么我们常见的以下的一些权限就很容易都明白了:
-rw------- (600) 只有所有者才有读和写的权限
-rw-r--r-- (644) 只有所有者才有读和写的权限,组群和其他人只有读的权限
-rwx------ (700) 只有所有者才有读,写,执行的权限
-rwxr-xr-x (755) 只有所有者才有读,写,执行的权限,组群和其他人只有读和执行的权限
-rwx--x--x (711) 只有所有者才有读,写,执行的权限,组群和其他人只有执行的权限
-rw-rw-rw- (666) 每个人都有读写的权限
-rwxrwxrwx (777) 每个人都有读写和执行的权限
16.linux查看文件的某一行
查看从第5行开始的100行内容,并把结果重定向到一个新的文件
cat file | tail -n +5 | head -n 100 > newfile.txt
查看第5行到100行的内容,并把结果重定向到一个新的文件
cat file | head -n 100 | tail -n +5
备注:还可以使用sed命令查看第5行到100行的内容:
sed -n '5,100p' file
19.redis为什么快?除了基于内存还有什么原因?
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
以上几点都比较好理解,下边我们针对多路 I/O 复用模型进行简单的探讨:
(1)多路 I/O 复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
22.HTTP短连接和长连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
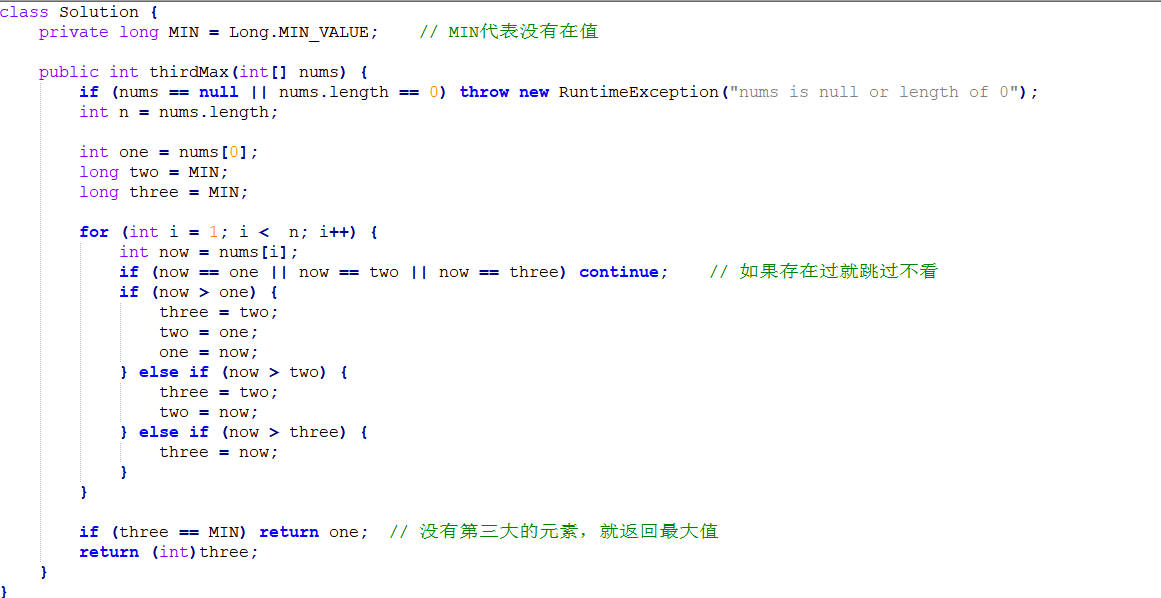
手撕代码: 给定一个非空数组,返回此数组中第三大的数。如果不存在,则返回数组中最大的数。要求算法时间复杂度必须是O(n)。
示例 1: 输入: [3, 2, 1] 输出: 1 解释: 第三大的数是 1.
示例 2: 输入: [1, 2] 输出: 2 解释: 第三大的数不存在, 所以返回最大的数 2 .
示例 3: 输入: [2, 2, 3, 1] 输出: 1 解释: 注意,要求返回第三大的数,是指第三大且唯一出现的数。 存在两个值为2的数,它们都排第二。
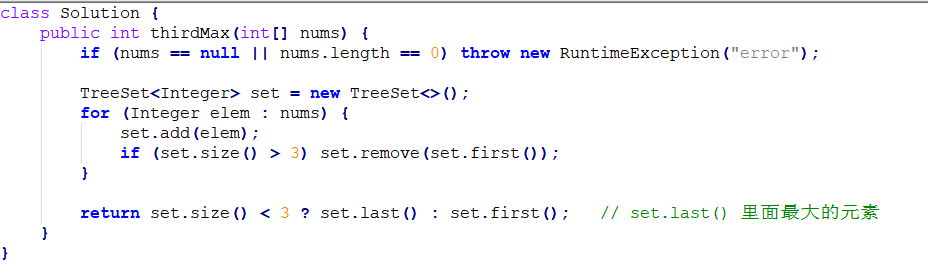
思路一: 借用TreeSet(红黑树) O(n) 维护一个只有3个元素的TreeSet,如果大于三个元素就就把Set中的最小最小值remove掉。 最后如果Set中元素小于3就返回Set最大值,否则返回最小值。 时间复杂度: O(n * log3) == O(n)
思路二: 用三个变量来存放第一大,第二大,第三大的元素的变量,分别为one, two, three; 遍历数组,若该元素比one大则往后顺移一个元素,比two大则往往后顺移一个元素,比three大则赋值个three; 最后得到第三大的元素,若没有则返回第一大的元素。