

整篇文章是在学习了多篇其他作者的文章的一个结合,若有冒犯侵权,还请及时告知,但也是我对于Hadoop的心得体会,如果有理解错误的地方也还请大家指点, 那么下面我们就步入正文
Hadoop
Hadoop是什么
百度百科给出的答案是:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
上面提到了两个醒目的名词分布式、大数据,在学习Hadoop之前我们有必要知道这两个部分,所以我们先进行简单的学习了解一下
分布式
说到分布式就不得不提到集群和负载均衡,所以我也会介绍一下,注:只是让大家了解一个大概(理论知识),但不会细化
分布式: 例如一个饭店的厨房,有炒菜的,有洗菜的,有刷碗的,那么每个功能(每个功能代表着一个人)都在独立的一个机器上运行,相互工作,这就是分布式
集群:当这个饭店的客流量增大,那可能一个厨师就忙不过来,因为有太多的客人等着上菜,这时我们就会多招聘几个厨师,这种相同功能的机器增加了就被认为是集群,而且集群也可以避免一个机器坏掉了,就无法工作,因为还有其他的机器在运行
负载均衡:解决了客流量增大的问题,但又出现一个新问题,此时假如有50道菜要去炒,我们的服务员(相当于请求)会去厨房告诉哪个厨师炒什么菜,那我们有三个厨师,分别为A,B,C,那就可能会出现这种情况(这里只是举例,也有可能是其他情况):A炒了40道菜,B炒了5道菜,C炒了5道菜,那A炒的菜比较多,第二天就累趴下了,此时负载均衡就解决了这样的一个问题,避免了一个机器的访问量过大,均衡的分配给每个机器,当然负载均衡也可以建立集群
大数据
大数据,不是随机样本,而是所有数据;不是精确性,而是混杂性;不是因果关系,而是相关关系。—————Schönberger
就拿电商举例子,五花八门的商品,各种各样的营销商,不同需求的用户,那你现在需要对这些数据进行分析,那么这环环相扣的复杂计算要怎么去完成呢?那么下面我们带着疑问正式学习Hadoop
Hadoop的特性
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低
Hadoop的生态系统

HDFS是什么
Hadoop的分布式文件系统
HDFS的架构
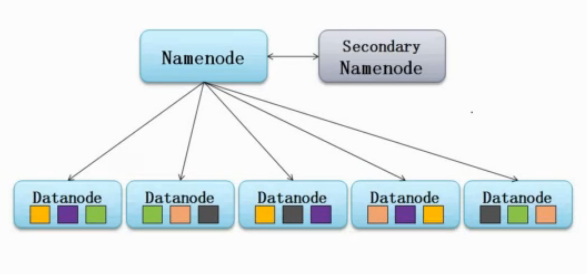
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组datanode上。namenode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体datanode的映射。datanode负责处理文件系统客户端的文件读写,并在namenode的统一调度下进行数据库的创建、删除和复制工作。namenode是所有HDFS元数据的管理者,用户数据永远不会经过namenode。
总结一下:
namenode负责:
-
接收用户操作请求
-
维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表
文件包含:
- fsimage:元数据镜像文件。存储某一时段namenode内存元数据信息。
- edits:操作日志文件。
- fstime:保存最近一次checkpoint(保证数据库的一致性,这是指将脏数据写入到硬盘,保证内存和硬盘上的数据是一样的)的时间。
-
管理文件与block之间关系,block与datanode之间关系
datanode负责:
- 存储文件
- 文件被分成block存储在磁盘上
- 为保证数据安全,文件会有多个副本
namenode的架构
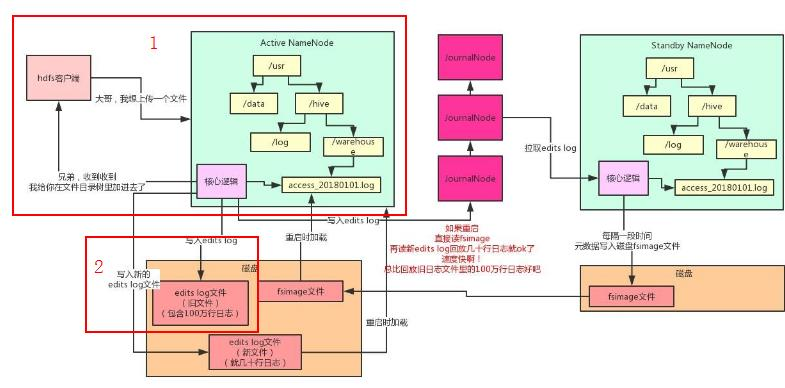
上面我引用了其他作者的图片并加以修改,也给出了其链接(我参考文章其中之一),下面开始具体讲一下流程:
- 首先客户端想要上传一个大文件,namenode收到请求后,会在其内存的文件目录树创建一个新的文件对象,此时区域一就结束了(图片中红色方框标记为1的地方),但产生问题:如果内存中的元数据丢失怎么办?
- 每当操作完内存后,往磁盘文件内顺序追加一条元数据修改的操作日志,每当namenode重启的时候,把edits log里的操作日志读到内存里回放一下,就解决第一步产生的问题了,此时区域二就结束了(图片中红色方框标记为2的地方),问题会迟到但不会缺席:edits log越来越大,重启影响效率
- 现在需要我们结合整张图片去看了,执行第二步后将元数据修改的操作日志,也写入到JournalNodes集群,让Standby NameNode去JournalNodes集群拉取edits log,应用到自己内存的文件目录树里,每过一段时间,Standby NameNode把自己内存里的元数据写入到到磁盘上的fsimage(checkpoint检查点操作),然后把这个fsimage上传到到Active NameNode,接着清空掉Active NameNode的旧的edits log文件,如此反复以上操作
然后再结合上面标题HDFS的架构下面的图片,了解到,客户端上传的大文件会被拆分为多个block,然后放到不同的datanode,也能够发现图片中的datanode的block的颜色会有三个是一样的,这并不是偶然,是因为HDFS会默认给每个block搞3个副本,一模一样的副本,分放在不同的机器上,防止数据丢失
最后再讲一下:secondaryNamenode 和 StandbyNamenode
secondarynamenode并不是Standbynamenode,这两者有本质的区别。
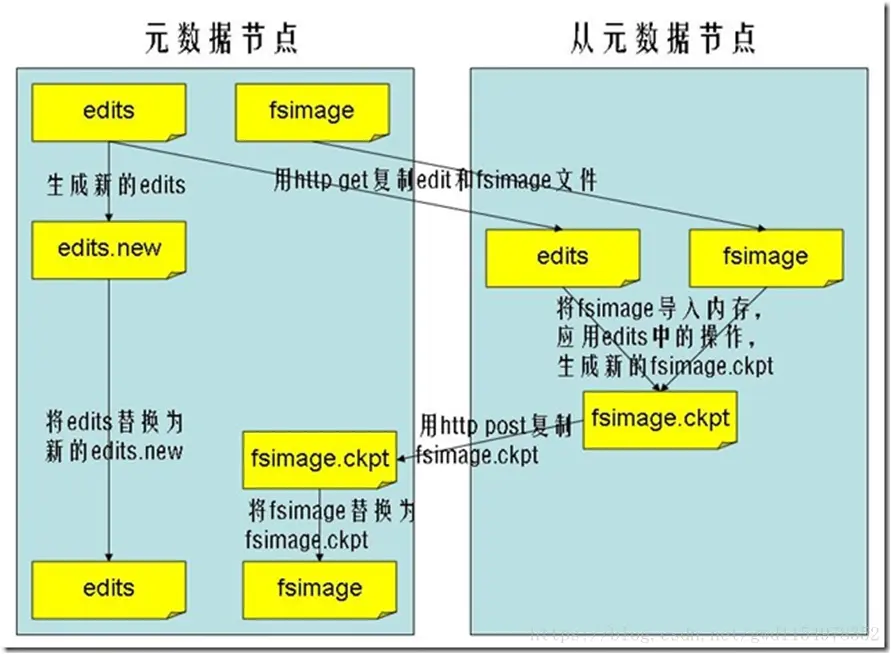
- secondarynamenode:看上图,相当于namenode的助手,定时拉取namenode的edit logs,给它合并成fsimage,然后再把这个最新的fsimage还回namenode。
- standbynamenode:这个就相当于是namenode的替身,完全一样的替身,通过journalnode来同步数据,保证与namnode一样,namenode挂了的话,替身立刻顶上去。
HDFS的读写过程
先讲一下,block,packet,chunk:(这里就直接引用其他作者的文章:blog.csdn.net/whdxjbw/art…
block: 这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不过不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
packet: packet是第二大的单位,它是client端向datanode,或datanode的PipLine之间传数据的基本单位,默认64KB。
chunk: chunk是最小的单位,它是client向datanode,或datanode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
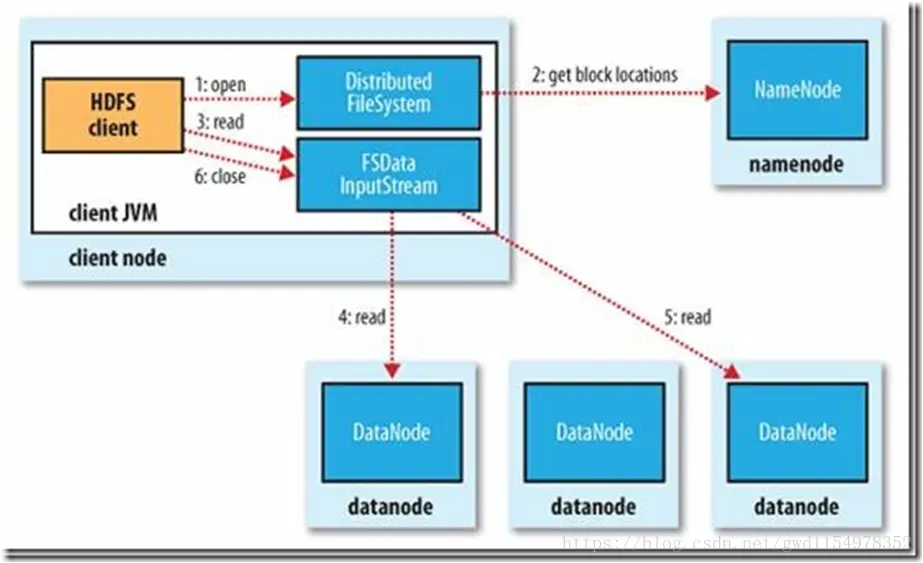
-
客户端向namenode发出写文件请求。
-
检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。 (注:WAL,write ahead log,先写log,再写内存,因为editLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入editlog中了,故editlog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中datanode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)
-
client端按128MB的块切分文件。
-
client将namenode返回的分配的可写的datanode列表和Data数据一同发送给最近的第一个datanode节点,此后client端和namenode分配的多个datanode构成pipeline管道,client端向输出流对象中写数据。client每向第一个datanode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…datanode。 (注:并不是写好一个块或一整个文件后才向后分发)
-
每个DataNode写完一个块后,会返回确认信息。 (注:并不是每写完一个packet后就返回确认信息,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生)
-
写完数据,关闭输输出流。
-
发送完成信号给namenode。 (注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有datanode写完后才向namenode汇报。最终一致性则其中任意一个datanode写完后就能单独向amenode汇报,HDFS一般情况下都是强调强一致性)
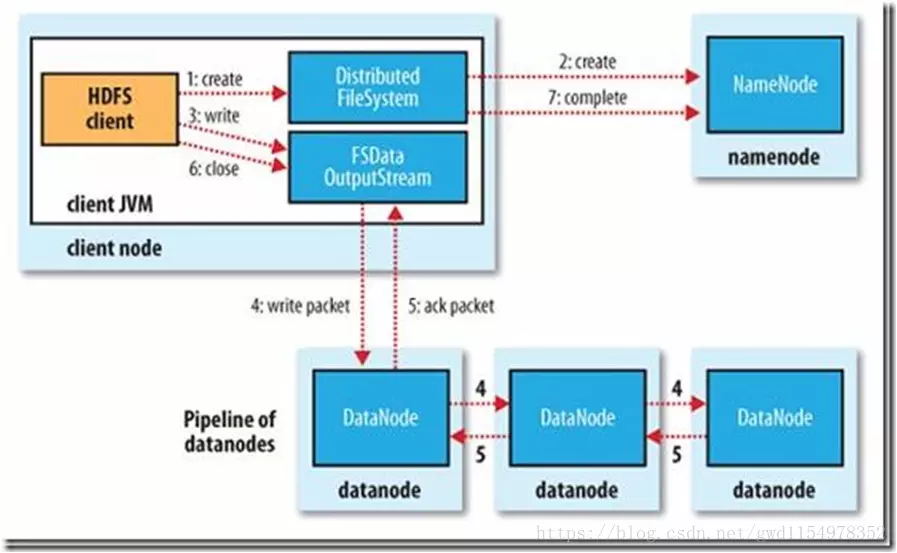
-
client访问namenode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
-
就近挑选一台datanode服务器,请求建立输入流 。
-
datanode向输入流中中写数据,以packet为单位来校验。
-
关闭输入流
MapReduce是什么
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组,该模型主要分为两个过程,即 Map 和 Reduce。 MapReduce 的整体思想是: 将输入的数据分成 M 个 tasks, 由用户自定义的 Map 函数去执行任务,产出<Key, Value>形式的中间数据,然后相同的 key 通过用户自定义的 Reduce 函数去聚合,得到最终的结果。
- MapReduce将复杂的,运行大规模集群上的并行计算过程高度地抽象两个函数:Map和Reduce
- MapReduce采用“分而治之”策略,将一个分布式文件系统中的大规模数据集,分成许多独立的分片。这些分片可以被多个Map任务并行处理。
- MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,原因是,移动数据需要大量的网络传输开销
- MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave,Master上运行JobTracker,Slave运行TaskTracker
- Hadoop框架是用JAVA来写的,但是,MapReduce应用程序则不一定要用Java来写。
- JobTracker:初始化作业,分配作业,TaskTracker与其进行通信,协调监控整个作业
- TaskTracker:定期与JobTracker通信,执行Map和Reduce任务
- HDFS:保存作业的数据、配置、jar包、结果
关于MapReduce还有很多东西,这里我就直接给出几个链接: blog.csdn.net/qq_36617639… zou.cool/2018/11/27/…
总结
我发现在这一段的时间里,通过掘金、简书等各大网站、书籍资料,对于Hadoop也有了一定的认识,但是现在想要写出自己的理解还是有一定的难度,这里也请大家谅解,目前自身还达不到这样的高度,还有待进一步的学习,也希望日后能写出更好的文章
