

MongoDB简介
- MongoDB是一个基于分布式文件存储的数据库。由C++语言编写旨在为WEB应用提供可扩展的高性能数据库存储解决方案。
- 分布式算法指的是将一个大型的任务进行分解,将每一个小任务的执行结果组合起来,返回一个整体
- 好处:给其他任务提供了可执行的机会
- MongoDB是非关系型数据库当中功能最丰富,最像关系型数据库的。
MongoDB优点
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
- 面向集合存储,易存储对象类型的数据。
- 模式自由。
- 支持动态查询。
- 支持完全索引,包含内部对象。
- 支持查询。
- 支持复制和故障恢复。
- 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 自动处理碎片,以支持云计算层次的扩展性。
- 支持RUBY,PYTHON,JAVA,C++,PHP等多种语言。
- 文件存储格式为BSON(一种JSON的扩展,超集)。
BSON
-
BSON是一种类似JSON的二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。
-
BSON可以作为网络数据交换的一种存储形式,这个有点类似于Google的Protocol Buffer,但是BSON是一种Schema【骨架】-less的存储形式,它的有点是灵活性,但它的缺点是空间利用率不是很理想。
-
BSON有三个特点:轻量性、可遍历性、高效性。
非关系型数据库与关系型数据库区别
非关系型数据库的优势:
-
性能
NOSQL是基于键值对的,可以想象成比表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
-
可扩展性
同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
关系型数据库的优势:
-
复杂查询
可以用SQL语句方便的在多个表之间做非常复制的数据查询。
-
事务支持
使得对于安全性能很高的数据访问要求得以实现。
-
总结:
-
数据库功能是用来存储数据的。
-
数据库分为关系型数据库和非关系型数据库(NoSQL)
-
关系型数据库是由表和表之间的关系组成的,NOSQL是由集合组成的,集合下面是很多的文档。
-
非关系型数据库文件存储格式为BSON(一种JSON 的扩展)
数据库操作
-
显示数据库列表>show dbs
-
创建数据库 >use dbname
-
显示数据库中的集合 >show collections
-
增加数据
db.web.save({"name":"老李"}) 创建了名为web的集合,并新增了一{"name":"老李"}的数据 db.web.insert({"name":"ghost","age":10}) 在web集合中插入一条新的数据,如果没有web这个集合,mongodb会自动创建 save()和insert()也存在着些许区别: 若新增的数据主键已经存在,insert()会不做操作并提示错误,而save()则更改原来的内容为新内容。 _id是主键,主键是每条数据的唯一标识,不能重复,就像身份证是每个人的编号一样。 存在数据:{ id : ObjectId("57e8d34b4764fb71d0a89caa"), " name " : " 老李"} ,id是主键 insert({ _id : ObjectId("57e8d34b4764fb71d0a89caa"), " name " : " 老王 " }) 会提示错误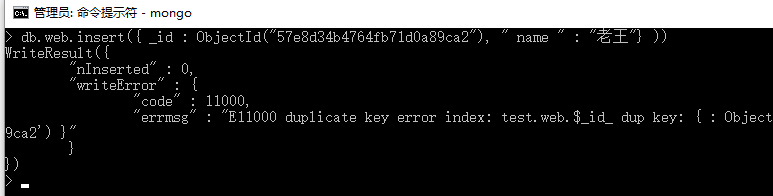
save(ObjectId("57e8d34b4764fb71d0a89caa"), " name " : " 老王 " }) 会把 “老李” 改为 “ 老王” ,有update的作用。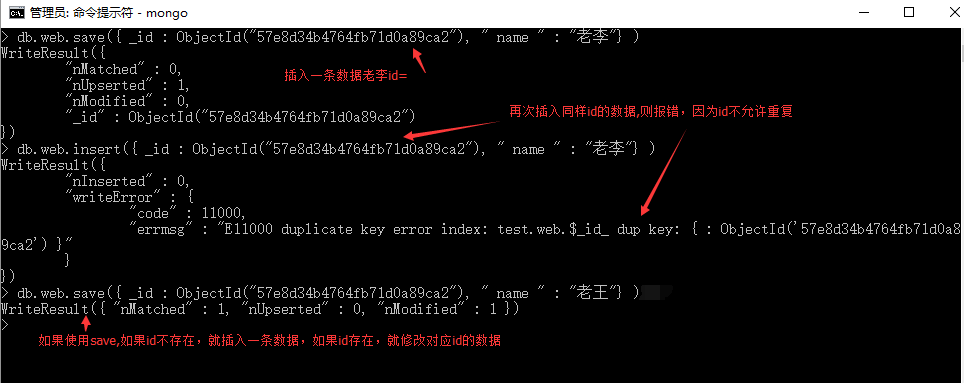
-
删除数据
- 删除文档
- 删除集合
- 删除数据库
db.users.remove({}) *删除**users**集合下所有数据* db.users.remove({"name": "lecaf"}) *删除**users**集合下**name=”lecaf”**的数据* db.users.drop()或db.runCommand({"drop":"users"}) *删除集合**users* db.runCommand({"dropDatabase": 1}) *删除当前数据库,注意* *此处的**1**没加双引号。 -
查找数据
>db.users.find() 查找users集合中所有数据
>db.users.findOne() 查找users集合中的第一条数据
>db.users.find().pretty() 格式化查询到的数据
$gt >
$lt <
$gte >=
$lte <=
Sort 排序 db.webs.find().sort({age: -1 })
Limit 类似截取 db.webs.find().limit( 2 )
- 修改数据
db.web.update({"name":"a1"}, {$set: {sex:”women”}},true,true)
修改name=a1的数据为sex=1,
第一个参数是查找条件,
第二个参数是修改内容,主键不能修改,
第三个参数表示匹配所有符合条件的数据,
第四个参数表示修改所有
匹配到的数据如图

MongoDB高级命令
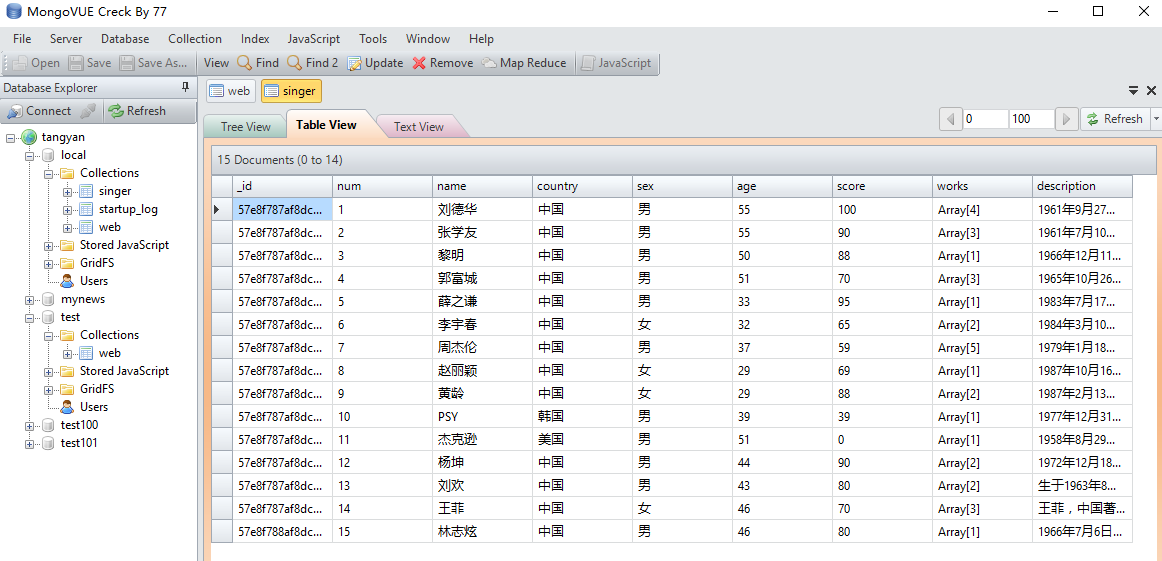
- 条件查找 歌手的json数据,我们可以把他导入到数据库,练习查找命令。
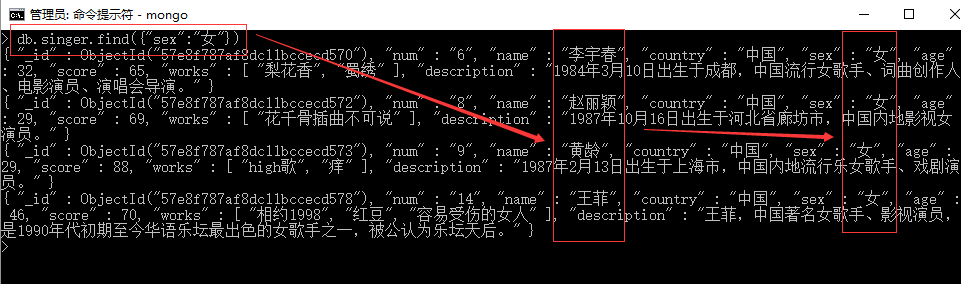
语法1:db.collection.find({ "key" : value }) 查找key=value的数据.
例1:查找女歌星。
思路:查找sex=”女”的歌星。
具体命令:
语法2: db.collection.find({ "key" : { $gt: value } }) key > value
例2:查找年龄大于53的歌星。

语法3:db.collection.find({ "key" : { $lt: value } }) key < value
例3:查询年龄小于35岁的歌星。

语法4:db.collection.find({ "key" : { $gte: value } }) key >= value
例4:查询成绩大于等于95的歌星。

语法5:db.collection.find({ "key" : { $lte: value } }) key <= value
例5:查询年龄在小于等于32岁的歌星。

语法6:db.collection.find({ "key" : { $gt: value1 , $lt: value2 } }) value1 < key <value2
例6:查找年龄在30-40岁之间的歌星。

语法7:db.collection.find({ "key" : { $ne: value } }) key <> value
例7:查询外国歌手。
分析:条件为 country不等于”中国”

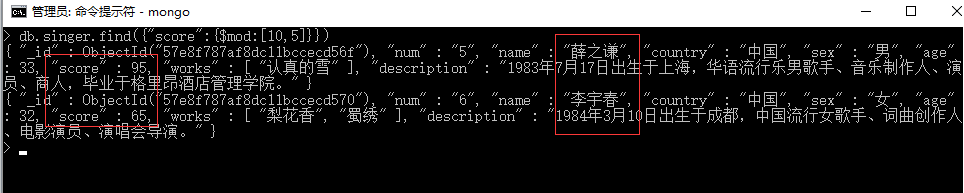
语法8:db.collection.find({ "key" : { $mod : [ 10 , 1 ] } })
取模运算,条件相当于key % 10 == 1 即key除以10余数为1的
例8:查询成绩为5 、15、25、。。。。95的歌星。
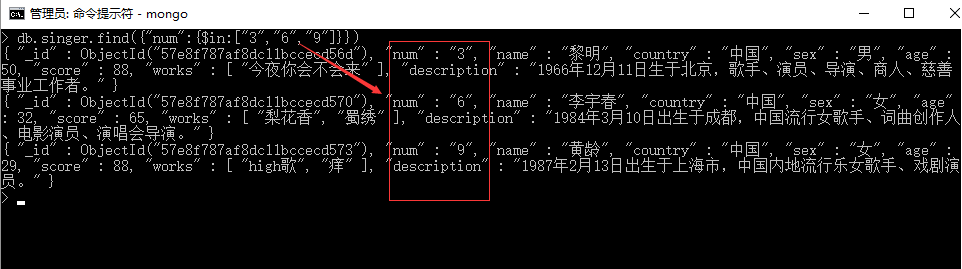
语法9:db.collection.find({ "key" : { $in: [ 1, 2, 3 ] } }) 属于
条件相当于key等于[ 1, 2, 3 ]中任何一个.
例9:查询序号(num)为3或者6或者9的歌星。
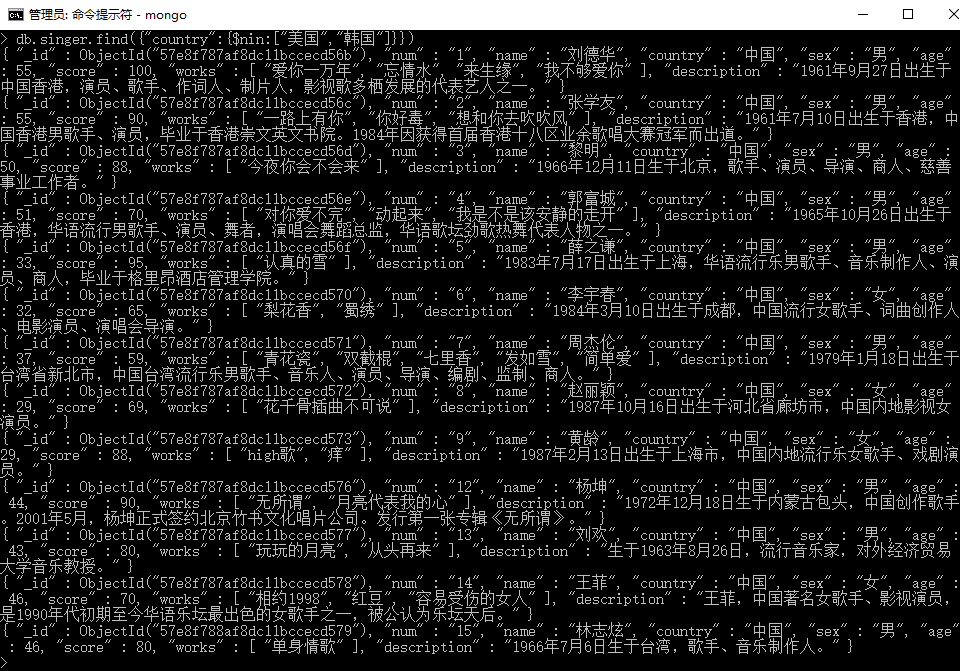
语法10:db.collection.find({ "key" : { $nin: [ 1, 2, 3 ] } }) 不属于
条件相当于key的值不属于[ 1, 2, 3 ]中任何一个。
例10:查询国籍不为美国和韩国的歌手。
语法11:db.collection.find({ "key" : { $size: 1 } }) $size数量、尺寸
条件相当于key对应的值的数量是1(值必须是数组)
这个有点难理解,通过例子理解容易些:
每个歌星都有代表作,并且代表作是数组。
例11:查询有3个代表作品的歌手。

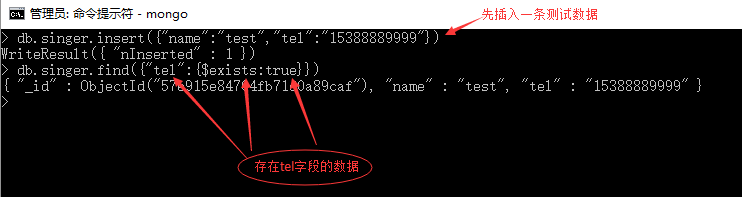
语法12:db.collection.find({ "key" : { $exists : true|false } })
$exists 字段存在,true返回存在字段key的数据,false返回不存在字段key的数据
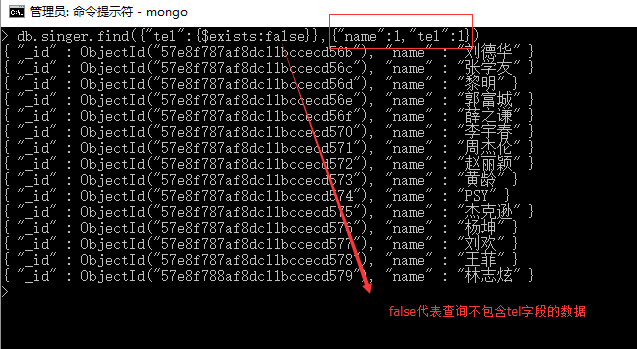
例12-1:查询包含tel字段的数据。
之前的数据字段都是一样的,此时插入一条数据{"name":"test","tel":"15388889999"}
然后查询:
例12-2 :查询不包含tel字段的数据
语法13:db.collection.find({ $or : [{a : 1}, {b : 2} ] })
符合两个条件中任意一个的数据。$or语法表示或的意思。
(注意:MongoDB 1.5.3后版本可用),符合条件a=1的或者符合条件b=2的数据都会查询出来。
例13:
某个娱乐公司15个人,资料都在数据库里面,某个活动必须要刘德华参加,
另外需要团队的全部女歌手配合演出,领导安排你帮忙打印歌手的资料。

db.collection.find({ "key.subkey" :value }) 内嵌对象中的值匹配,注意:"key.subkey"必须加引号。
例14:插入一条测试数据
db.singer.insert({"name":"test2",score:{"yy":80,"sx":79,"wy":95}})
此数据的score对应的值是一个对象。
例14:查询语文成绩为80的同学。

db.collection.find().sort({ "key1" : -1 ,"key2" : 1 }) 这里的1代表升序,-1代表降序
例1:对所有歌星安年龄排序。

3. 索引

索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。 这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。 索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构

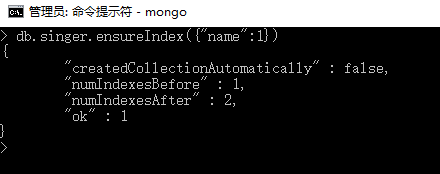
ensureIndex()方法基本语法格式如下所示:
>db.COLLECTION_NAME.ensureIndex({KEY:1})
对name 字段建立一个索引如下:
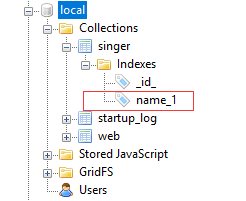
可视化工具里面可以看到刚创建的索引:
语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可。
实例
>db.col.ensureIndex({"title":1})>
ensureIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。
> db.col.ensureIndex({"title":1,"description":-1})
- 其他
db.collection.find().limit(5) 控制返回结果数量,如果参数是0,则没有约束,limit()将不起作用

db.collection.find().skip(5) 控制返回结果跳过多少数量,如果参数是0,则当作没有约束,skip()将不起作用,或者说跳过了0条
db.collection.find().skip(5).limit(5) 可用来做分页,跳过5条数据再取5条数据
db.collection.find().count() count()返回结果集的条数
db.collection.find().skip(5).limit(5).count(true)
在加入skip()和limit()这两个操作时,
要获得实际返回的结果数,需要一个参数true,
否则返回的是符合查询条件的结果总数
模糊查询:
db.collection.find({"name":/ab/})
以上是常见的查询,如果工作中遇到更加复杂的需求,可以通过查文档来解决。
