

本文将对Kafka做一个入门简介,并展示如何使用Kafka构建一个文本数据流管道,通过本文,读者可以了解一个流处理数据管道(Pipeline)的大致结构:数据生产者源源不断地生成数据流,数据流通过消息队列投递,数据消费者异步地对数据流进行处理。

Kafka简介
2010年,LinkedIn开始了其内部流数据处理平台的开发,2011年将该系统捐献给了Apache基金会,取名Apache Kafka(以下简称Kafka)。Kafka的创始人Jay Kreps觉得这个系统主要用于优化读写,应该用一个作家的名字来命名,加上他很喜欢作家卡夫卡的文学作品,觉得这个名字对于一个开源项目来说很酷,因此取名Kafka。
Kafka是一种面向大数据领域的消息系统。在大数据生态圈中,Hadoop的HDFS或Amazon S3提供数据存储服务,Hadoop MapReduce、Spark和Flink负责计算,Kafka是被用来连接这些系统和应用的消息系统。
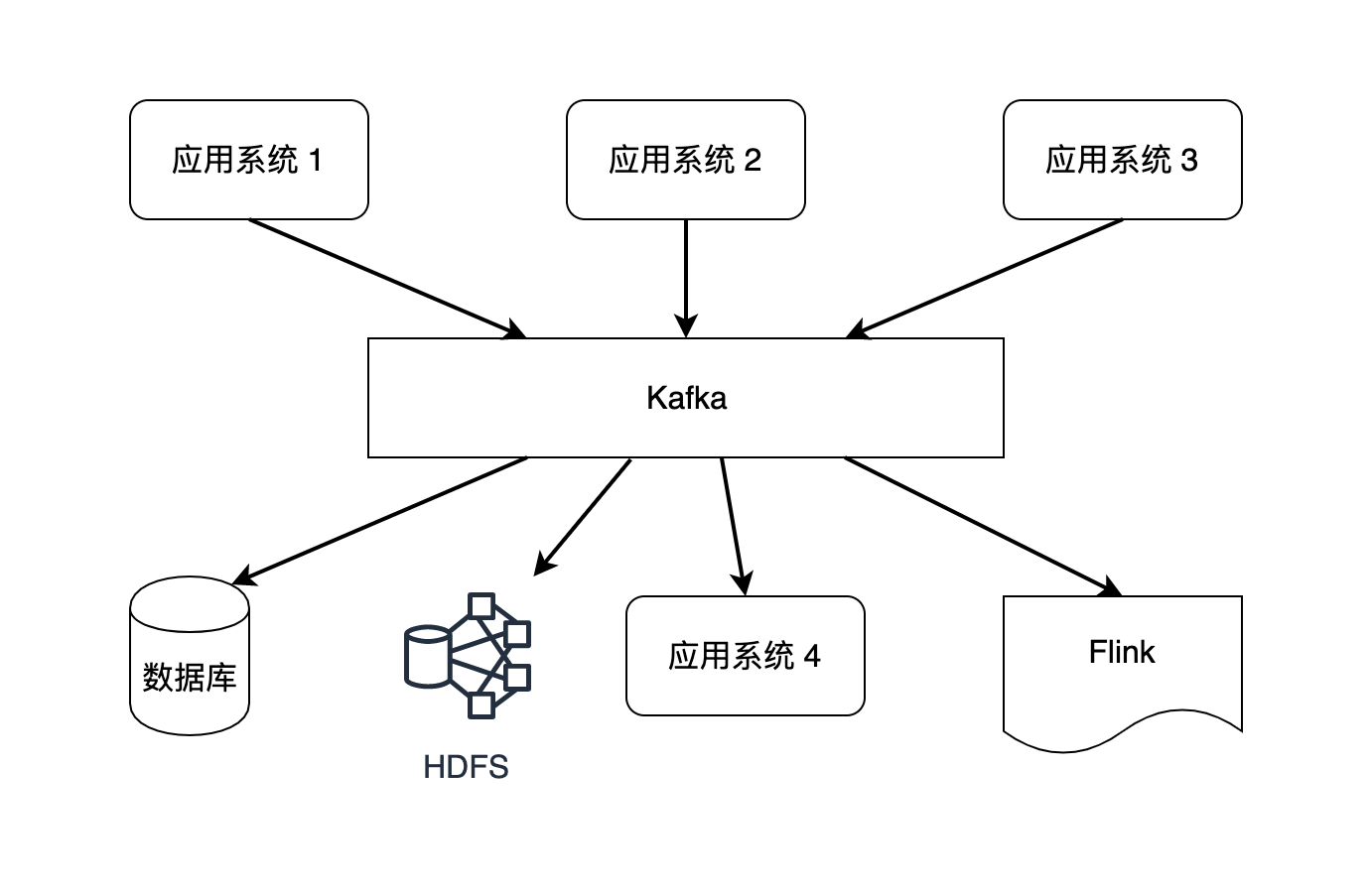
消息系统的功能
消息系统一般使用“生产者-消费者(Producer-Consumer)”模型来解决问题。如下图所示,生产者生成数据,将数据发送到一个缓存区域,消费者从缓存区域中消费数据。
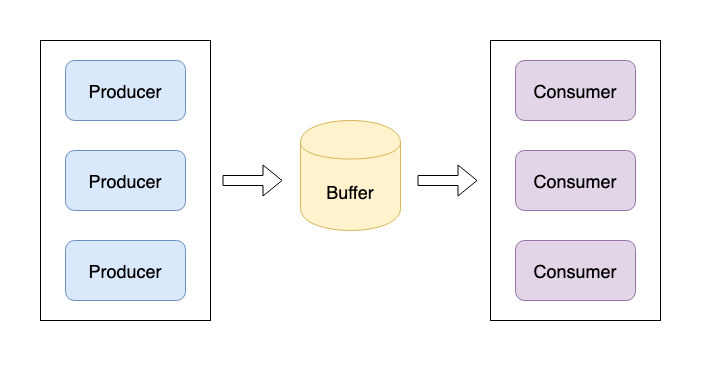
消息系统可以解决以下问题:
- 系统解耦。很多企业内部有众多系统,即使一个APP也包含众多模块,如果将所有的系统和模块都放在一起作为一个庞大的系统来开发,未来很难维护和扩展。如果将各个模块独立出来,模块之间通过消息系统来通信,未来可以轻松扩展每个独立模块。另外,假设没有消息队列,M个生产者和N个消费者通信,会产生M*N个数据管道,消息队列将这个复杂度降到了M+N。
- 异步处理。同步是指如果模块A向模块B发送消息,必须等待返回结果后才能执行接下来的业务逻辑。异步是消息发送方模块A无需等待返回结果即可继续执行,只需要向消息队列中发送消息,至于谁去处理这些消息,消息等待多长时间才能被处理等一系列问题,都是消费者负责的事情。异步处理更像是发布通知,发送方不用去关心谁去接收通知,如何对通知做出响应等问题。
- 流量削峰。电商促销、抢票等场景会对系统产生巨大的压力,瞬时请求暴涨,消息系统的缓存就像一个蓄水池,以很低的成本将上游的洪峰缓存起来,下游的服务按照自身处理能力从缓存中拉取数据,避免服务崩溃。
- 数据冗余。很多情况下,下游的数据处理模块可能发生故障,消息系统将数据缓存起来,直到数据被处理,一定程度上避免了数据丢失风险。
Kafka作为一个消息系统,主要提供三种核心能力:
- 为数据的生产者提供发布功能,为数据的消费者提供订阅功能,即传统的消息队列的能力。
- 将数据流缓存在缓存区,为数据提供容错性,有一定的数据存储能力。
- 提供了一些轻量级流处理能力。
可见Kafka不仅仅是一个消息队列,也有数据存储和流处理的功能,确切地说,Kafka是一个流处理系统。
Kafka的一些核心概念
Topic
Kafka按照Topic来区分不同的数据。以淘宝这样的电商平台为例,某个Topic发布买家用户在电商平台的行为日志,比如搜索、点击、聊天、购买等行为;另外一个Topic发布卖家用户在电商平台上的行为日志,比如上新、发货、退货等行为。
Producer
多个Producer将某种数据发布到某个Topic下。比如电商平台多台线上服务器将买家行为日志发送到名为user_behavior的Topic下。
Consumer
多个Consumer被分为一组,名为Cosumer Group,一组Consumer Group订阅一个Topic下的数据。通常我们可以使用Flink编写的程序作为Kafka的Consumer来对一个数据流做处理。
使用Kafka构建一个文本数据流
下载和安装
绝大多数的大数据框架基于Java,因此在进行开发之前要先搭建Java编程环境,主要是下载和配置JDK(Java Development Kit)。网络上针对不同操作系统安装JDK的相关教程已经很多,这里不再赘述。
接下来我们从Kafka官网(kafka.apache.org/downloads)下…
$ tar -xzf kafka_2.12-2.3.0.tgz
$ cd kafka_2.12-2.3.0
注意,$符号表示该行命令在类Unix操作系统(Linux和macOS)命令行中执行,而不是在Python交互命令或其他任何交互界面中。Windows的命令行提示符是大于号>。
注意,bin目录默认为Linux和macOS设计,本文基于macOS,直接了使用bin目录中的文件。Windows用户要进入bin\windows\来启动相应脚本,且脚本文件后缀要改为.bat。
启动服务
Kafka使用ZooKeeper来管理集群,因此需要先启动ZooKeeper。刚刚下载的Kafka包里已经包含了ZooKeeper的启动脚本,可以使用这个脚本快速启动一个ZooKeeper服务。
$ bin/zookeeper-server-start.sh config/zookeeper.properties
启动成功后将有对应日志打印到屏幕上。
接下来在新开启一个命令行会话,启动Kafka:
$ bin/kafka-server-start.sh config/server.properties
以上两个操作均使用config文件夹下的默认配置文件,需要注意配置文件的路径是否写错。生产环境下的配置文件比默认配置文件复杂得多。
创建Topic
新开启一个命令行会话,创建一个名为Shakespeare的Topic:
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic Shakespeare
也可以使用命令查看已有的Topic:
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092
Shakespeare
发送消息
接下来我们模拟Producer,假设这个Producer是莎士比亚本人,它不断向Shakespeare这个Topic下发送自己的最新作品:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Shakespeare
>To be, or not to be, that is the question:
每一行作为一条消息事件,被发送到了Kafka集群上,虽然这个集群只有本机这一台服务器。
消费数据
另外一些人想了解莎士比亚向Kafka发送过哪些新作,所以需要使用一个Consumer来消费刚刚发送的数据。我们启动一个命令行会话来模拟Consumer:
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Shakespeare --from-beginning
To be, or not to be, that is the question:
Producer端和Consumer端在不同的命令行会话中,我们可以在Producer的命令行会话里不断输入一些文本,切换到Consumer端后,可以看到相应的文本被发送了过来。
至此,模拟了一个实时数据流数据管道:不同人可以创建属于自己的Topic,发布属于自己的内容,其他人可以订阅一到多个Topic,根据自身需求设计后续处理逻辑。
小结
Kafka是一种消息系统,提供了数据流“发布/订阅”功能,保证了数据冗余。
