

FAQ
效率
- 哈希表是一种典型的空间换时间的做法
- 由于哈希函数和数组元素定位都是O(1),所以无论是搜索、添加还是删除都是O(1)
- 在哈希表中,学术性地称每个数组位置为一个桶(Bucket),整个哈希表成为桶数组(Bucket Array)
- 为了避免在实例化时就创建囊括样本所有可能性数量级长度的桶数组,一开始我们通常选取较短的长度,如8、16,如此必然会出现经过哈希函数多个
key被映射到一个桶的情况,这种现象称为哈希冲突。
哈希冲突
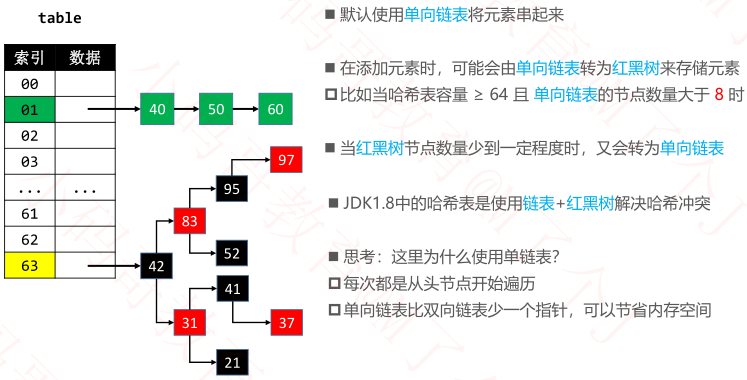
- 哈希冲突的解决存在以下方案:
- 重定位地址:发现冲突之后,从该位置按照一定的跳跃规则(如跃过3个桶)向后查找空的桶进行插入
- 再哈希:预备多个哈希函数,当发生哈希冲突后使用预备函数重新计算哈希值并定位桶位置
- JDK8如何解决哈希冲突
- 方案:单链表+红黑树
- 当桶数量和桶内记录(键值对)达到一定数量时,会将链表升级为红黑树(如桶数量达到64且桶内记录数超过8时);当记录数减少到一定程度后(如桶内记录数减少到9以下),又会由红黑树退化为单链表
- 为何使用单链表而不使用双链表
- 使用双链表虽然可以利用尾指针使得尾插法为O(1),但是记录插入到链表之中既不能使用头插法也不能使用尾插法,因为我们需要从头遍历链表,如果发现key相同(
equals返回true)那么应该使用插入的键值对覆盖该原有的键值对,否则遍历到达了链表尾部 - 双链表更占内存,且在此场景下用不上
prev指针
- 使用双链表虽然可以利用尾指针使得尾插法为O(1),但是记录插入到链表之中既不能使用头插法也不能使用尾插法,因为我们需要从头遍历链表,如果发现key相同(
桶长度
- 为何桶数组长度最好为2^n
- 因为在将
key的哈希值映射到桶下标时,我们通常采用取模的方式,很容易联想到hash_code % bucket_length,但是%运算符的效率较低,我们应尽量采用(与——同为1则为1、异或——相同为0不同为1、或——有1则为1)等位运算符代替,而当bucket_length为2^n时,hash_code & (bucket_length - 1)的值与前者是一致的,举例易证(bucket_length - 1为2^n对应最高二进制位为0其余位为1。
- 因为在将
哈希值计算
-
哈希值计算原则
- 哈希值的计算要求样本记录能够较均匀的散列在各个桶中,这样能减少哈希冲突,提升哈希表性能
-
如何计算哈希值
-
尽量让key的哈希值是唯一的
-
尽量让key的所有信息参与运算
-
以JDK中的常用key类型为例:
-
Integer:数值本身作为哈希值
@Override public int hashCode() { return Integer.hashCode(value); } public static int hashCode(int value) { return value; } -
Float:占32位,将该32位二进制对应的整型数值作为哈希值
@Override public int hashCode() { return Float.hashCode(value); } public static int hashCode(float value) { return floatToIntBits(value); } -
Long:占64位,由于Java中Object规定
hashCode返回int,又要考虑到尽量让这64位都参与运算,因此将64中高32位和第32位的异或结果作为哈希值@Override public int hashCode() { return Long.hashCode(value); } public static int hashCode(long value) { return (int)(value ^ (value >>> 32)); // 无符号右移,高位补零 } -
Double:占64位,先将该64对应的整型数值换算出来,再同Long一样处理
@Override public int hashCode() { return Double.hashCode(value); } public static int hashCode(double value) { long bits = doubleToLongBits(value); return (int)(bits ^ (bits >>> 32)); } -
String:由于字符串由一个个字符组成,而每个字符又可以转换成整数,因此我们可以将每个字符乘以其在字符串中位置到末尾字符的权重,如对于
"ABCD"=65 * n^3 + 66 * n^2 + 67 * n + 68。在JDK中,n取31,这是因为65 * n^3 + 66 * n^2 + 67 * n + 68 = ((65*n + 66)*n + 67)*n + 68其中*n出现较多,而**JVM会将i * 31优化成(i<<5)-i**以提高计算效率(这相当于面向JVM编程,31*i=(32-1)*i=(2<<5)*i - i,且31是一个奇素数,以素数作为乘数比其他方式更容易产生结果的唯一性,减少哈希冲突,经过观测分布结果,31是比15、7等更好的选择)private int hash; // Default to 0 public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
-
-
自定义对象:自定义对象由若干基本类型和其他自定义类型字段组成,我们可以将这一个个的类型的哈希值计算出来,再乘上不同的权重,最后求和(和字符串的求解过程类似)
public class Person{ private int age; private float height; private String name; private Car car; @Override public int hashCode(){ int hash = age; int heightHash = Float.floatToIntBits(height); hash = hash * 31 + heightHash; int nameHash = name == null ? 0 : name.hashCode(); hash = hash * 31 + nameHash; int carHash = car == null ? 0 : car.hashCode(); hash = hash * 31 + carHash; return hash; } }
-
equals&hashCode
hashCode何时被调用
当向哈希表中put一个键值对的时候,key的hashCode方法会被调用得出key的哈希值,再通过对通数组长度进行去摸运算得出一个桶下标,这个下标对应的桶就是该键值对的存放位置
两个对象相等吗
如果经过上述运算发现该同内已有其他键值对,此时会遍历这些记录,并比较插入记录的key与被遍历访问记录的key是否相等,如果相等则用插入记录替换该遍历记录并终止遍历;如果遍历结束,则向链表尾部新增插入记录。那么如何判定两个key是否相等?
Java中为我们提供了以下思路:
-
==,比较这两个对象的内存地址,这是一种严格的相等,实际上是在判定两个指针是否指向同一块内存,用来实现我们语义上的“两个对象是否相等”不太恰当 -
compareTo返回0,这要求对象实现Comparable接口,即是可比较的,而哈希表设计的初衷就是摒弃像红黑树那样维护元素直接的有序性从而使得性能提升为O(1),即被添加到哈希表中的记录不应该被要求具备可比较性 -
hashCode,如果认为两个对象的哈希值是相等的则认为这两个对象就是相等的,这也是不严谨的,以Integer:1071476900和Float:1.73f为例,两者在内存中存储的32位二进制数是一致的,但两者表达的含义天差地别 -
equals,所有对象都继承了Object中的equals方法,该方法默认使用==进行比较,我们应该为添加到哈希表中的对象自定义实现equals方法复写判定是否相等的逻辑,常用的做法是比较对象的各成员变量是否相等,如public class Person{ private int age; private float height; private String name; @Override public int hashCode(){ int hash = age; int heightHash = Float.floatToIntBits(height); hash = hash * 31 + heightHash; int nameHash = name == null ? 0 : name.hashCode(); hash = hash * 31 + nameHash; return hash; } @Override public boolean equals(Object o){ if(this == o) return true; // 如果内存相同,则肯定相等 // 如果要比较的为null(能够走到这里说明this不为null) 或 类型不同 if(o == null || this.getClass() != o.getClass()) return false; Person p = (Person)o; return age == p.age && height == p.height && (name == null ? p.name == null : name.equals(p.name)); } }
只重写hashCode和只重写equals都不是理智的
如果只重写hashCode而不重写equals,由于equals默认比较内存地址,因此等效的两个对象在被添加到哈希表中时,不会互相覆盖,因此你无法达到向哈希表中添加新记录(person2, "aaa")从而覆盖哈希表中的老记录(person1, "bbb")的目的,即无法实现通过以等效的key来更新桶中已有记录的功能
如果只重写equals而不重写hashCode(默认返回内存地址),那么被认为相等的两个对象(equals返回true),在被先后添加到哈希表中时,虽然两个不同内存的对象hashCode不同:
- 如果取模得出的桶下标相同,那么后添加的会覆盖先添加的 => 更新
- 如果取模得出的桶下标不同,后添加的会被添加到一个新的桶中 => 添加
这会导致哈希表功能的不稳定性
重写两者需遵循的原则:
equals返回true的两个对象的哈希值应该一致,哈希值相同的两个对象不要求equals返回true
重写规范

红黑树比较逻辑
被加入到哈希表中的对象不应该被要求是可比较的,那么桶中的红黑树该如何有序组织哈希冲突的记录呢?
其实对于两个对象,有很多可以提取的信息来帮我们强制比较他们的大小:
- 哈希值,
hashCode - 语义上相等,
equals。如果哈希值相等应该调用equals进一步判断,如果哈希值不等那么根据重写原则equals也会返回false - 如果两个对象实现了
Comparable<T>,且类型T一致,那么可以通过compareTo判断大小 - 在左子树和右子树中递归查找记录是否已存在
- 对象唯一身份ID:内存地址,
System.identityHashCode(Object x)
注意减法陷阱,例如
hash1>0, hash2<0,hash1-hash2可能发生溢出导致结果小于0,因此最好直接进行比较if (hash1 > hash2)
向红黑树中添加记录
public V put(K key, V value) {
resize();
int index = index(key);
// 取出index位置的红黑树根节点
Node<K, V> root = table[index];
if (root == null) {
root = createNode(key, value, null);
table[index] = root;
size++;
fixAfterPut(root);
return null;
}
// 添加新的节点到红黑树上面
Node<K, V> parent = root;
Node<K, V> node = root;
int cmp = 0;
K k1 = key;
int h1 = hash(k1);
Node<K, V> result = null;
boolean searched = false; // 是否已经搜索过这个key
do {
parent = node;
K k2 = node.key;
int h2 = node.hash;
if (h1 > h2) {
cmp = 1;
} else if (h1 < h2) {
cmp = -1;
} else if (Objects.equals(k1, k2)) {
cmp = 0;
} else if (k1 != null && k2 != null
&& k1 instanceof Comparable
&& k1.getClass() == k2.getClass()
// compare相等并不意味着equals相等,cmp=0会在后续的case中被覆盖
&& (cmp = ((Comparable)k1).compareTo(k2)) != 0) {
} else if (searched) { // 已经扫描了,树中不存在和新增记录相等的key
cmp = System.identityHashCode(k1) - System.identityHashCode(k2);
} else { // searched == false; 还没有扫描,然后再根据内存地址大小决定左右
if ((node.left != null && (result = node(node.left, k1)) != null)
|| (node.right != null && (result = node(node.right, k1)) != null)) {
// 已经存在这个key
node = result;
cmp = 0;
} else { // 不存在这个key
searched = true; // 已经扫描过整棵树了
cmp = System.identityHashCode(k1) - System.identityHashCode(k2);
}
}
if (cmp > 0) {
node = node.right;
} else if (cmp < 0) {
node = node.left;
} else { // 相等
V oldValue = node.value;
node.key = key;
node.value = value;
node.hash = h1;
return oldValue;
}
} while (node != null);
// 看看插入到父节点的哪个位置
Node<K, V> newNode = createNode(key, value, parent);
if (cmp > 0) {
parent.right = newNode;
} else {
parent.left = newNode;
}
size++;
// 新添加节点之后的处理
fixAfterPut(newNode);
return null;
}
从红黑树中查找记录
private Node<K, V> node(K key) {
Node<K, V> root = table[index(key)];
return root == null ? null : node(root, key);
}
private Node<K, V> node(Node<K, V> node, K k1) {
int h1 = hash(k1);
// 存储查找结果
Node<K, V> result = null;
int cmp = 0;
while (node != null) {
K k2 = node.key;
int h2 = node.hash;
// 先比较哈希值
if (h1 > h2) {
node = node.right;
} else if (h1 < h2) {
node = node.left;
} else if (Objects.equals(k1, k2)) {
return node;
} else if (k1 != null && k2 != null
&& k1 instanceof Comparable
&& k1.getClass() == k2.getClass()
&& (cmp = ((Comparable)k1).compareTo(k2)) != 0) {
node = cmp > 0 ? node.right : node.left;
} else if (node.right != null && (result = node(node.right, k1)) != null) {
return result;
} else { // 右子树中没有,只能往左边找,避免递归调用在左子树中查找
node = node.left;
}
}
return null;
}
扰动计算
为了避免添加到哈希表中记录哈希值有特征性(如低位0较多,高位1较多),我们通常会将记录的哈希值进行扰动计算后重新赋值:
hash = (hash >>> 16) ^ hash;
在与、或、非、异或等位运算中,只有异或运算才能混合高低位的所有位信息到低位中,这样在计算桶下标时(桶数组长度减1的二进制数高位均为0,低位均为1),能让记录更加散列地分布
扩容
负载载因子 Load Factor
负载因子 = 记录数 / 桶数组长度
当负载因子超高阈值时,应该对哈希表进行扩容以提高性能(桶中冲突记录数过多会导致O(1)转变为O(n)),JDK8中HashMap的默认负载因子阈值为0.75,这是经过试验、统计后得出最佳选择。
再哈希 rehash
新创建一个桶数组长度为原来2倍的新表,遍历每个桶以及每个桶中的记录(如果桶中是红黑树根节点,可用层序遍历法),将记录rehash到新表中。
rehash:重新计算桶下标,将遍历记录从旧表移至新表中,在此之前还需解除该记录在原先桶中维护的连接关系,如next; left, right, parent,在此之后需建立新的连接关系,如prev, prev.next; parent, parent.left/right以及染红新增的红黑树节点。
