

大多时候,当我们设计关于获取或者搜索业务数据API的时候,经常要提供分页能力以避免当数据过多的时候,会一次性把所有数据加在到内存中造成OOM(out of memory),或因为大量的数据读取造成数据库响应超时。
因此,分页逻辑的存在更多的是出于对系统性能考虑而添加的,而对于API本身的业务表达并没有任何帮助,反而会让你的API看上去臃肿和啰嗦。
我们用一个例子来说明这种分页逻辑为什么会造成污染——臃肿和啰嗦。假设我们要提供一个API实现“根据员工姓名来搜索所有的员工”,以Java语言为例,我们会有如下的一个声明:
List<EmployeeRecord> searchEmployeeByName(String name, Pagination pagination);
这里的Pagination为分页参数对象,里面会包含如,起始页startPage,每页记录数pageSize,当然还可以有排序条件sortingField和ASC/DESC。这么看上来,其实也还好,但是,这只是一个开始,这个Pagination就如同一瓶打翻了的硫酸,会在所有其经过的各层代码接口上“腐蚀”出一个“洞”。比如,数据持久层的EmployeeDAO上相应的接口就会需要接受这个Pagination:
List<EmployeeDO> selectByName(String name, Pagination pagination)
而在很多系统中,都会有一个业务核心层(Business Layer)用来封装业务逻辑,所以,在这一层中,我们一般会有一个对应的EmployeeManager或者EmployeeRepository之类的聚合对象用来返回对应的业务模型对象,所以,我们也需要在这个API上提供这个参数Pagination,以便在其内部使用EmployeeDAO去获取EmployeeDO的过程中可以透穿分页参数:
List<Employee> findEmployeeByName(String name, Pagination pagination)
可以看到,只是如此简单的一个API就会使得每一层的相关代码上添加Pagination这个参数,可以想象一下,如果你的系统提供了更多更复杂的查询API呢?这种为了支撑分页逻辑的接口设计一旦遍布整个系统各个代码模块,另一个更让人头痛的事情就会发生——当你对Pagination这个参数做了一次不兼容性的更新之后,你会突然间发现,整个代码到处都会出现编译错误,我相信这种场景是没有人希望看到。而如果这种情况发生在ruby这类动态语言上,其结果就是,有可能一些问题只有到了线上被执行的时候才会发现。
不可否认的,分页逻辑无论如何还是不能取消的,这是系统稳定性和代码可维护性博弈之后的胜利。所以,剩下的可以给我们选择就只能是:“要如何设计分页逻辑才能做到尽量少的污染呢?”
解决这个问题,我们需要应用一种设计模式——Delegate模式。而我的整个解决方案会分为两个部分:
首先,我们需要从新设计API,把Pagination这个参数拿掉。
PaginatedResult<List<EmployeeRecord>> searchEmployeeByName(String name);
拿掉了Pagination之后,我们要提供另一种方式来实现分页,这里可以看到,为了实现不同的分页交互,返回值的类型从List变成了PaginatedResult<List>,新的返回类型本身就带有了分页能力和对应的接口:
int pageSize = 50;
PaginatedResult<List<EmployeeRecord>> result = searchEmployeeByName(String name);
result = result.start(1, pageSize);
List<EmployeeRecord> employees = result.getResult();
do {
//do something with employees...
result = result.next(); //翻到下一页
employees = result.getResult();
} while (employees.size() >= pageSize);
通过去掉Pagiation这个参数,API本身的业务表达更为清晰,而PaginatedResult所提供的分页的方法start和next也具有更具有自描述性,代码可维护性也有一定提高。而为了支持PaginatedResult这种分页方式,我们需要另外的几个类来配合,这里就是Delegate设计模式所应用的地方,下面,我用一个Sequence Diagram(序列图)来更为直观的解释如何实现的:
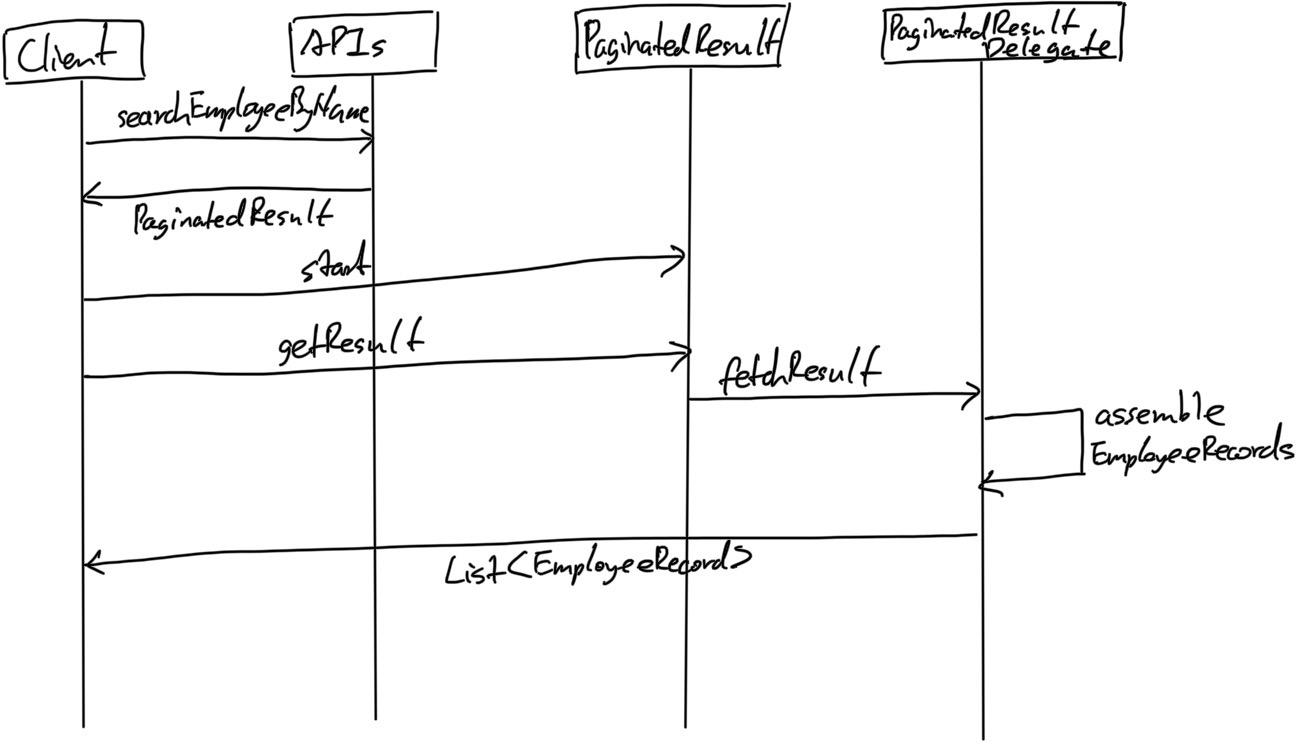
从上面的序列图中我们可以看出来,调用侧(client)在调用PaginatedResult上的getResult方法获得数据的时候其实是在跟对应的PaginatedResultDelegate接口的fetchResult进行通信。
在解决了去掉Pagination这参数之后,我们另一个要解决的问题就是,基于上面的PaginatedResultDelegate设计,是不是每层代码还是会出现打翻了的硫酸效果呢——每层代码都会有一个“洞”?
这里,我把searchEmployeeByName这个API的实现实现逻辑相关代码展示出来来回答上面的问题:
public PaginatedResult<List<EmployeeRecord>> searchEmployeeByName(String name) {
return new PaginatedResult<>(this::_searchEmployeeByName);
}
private List<EmployeeRecord> _searchEmployeeByName(ResultFetchRequest request) {
String name = (String) request.getArguments()[0];
PaginatedResult<List<Employee>> result = employeeRepository.findByName(name);
result.start(result.getPage());
return toEmployeeRecords(result.getResult());
}
private List<EmployeeRecord> toEmployeeRecords(List<Employee>) {
//some logic to convert Employee list to EmployeeRecord list.
}
从上面的代码中我们可以看到可以看到,首先,每一次调用searchEmployeeByName的时候,我们都会创建一个新的PaginatedResult,并且,把PaginatedResultDelegate的实现类通过Lambda方式(this::_searchEmployeeByName)注入进去,然后,在_searchEmployeeByName内部使用EmployeeRepository的findByName方法来获取真实数据。其次,另一个比较值得注意的地方就是,EmployeeRepository#findyByName这个方法中也没有“洞”了 —— 我们也成功的把这个接口的Pagination参数去掉了,并且,也复用了PaginatedResult的返回值设计。通过这种串联PaginatedResult的方式,我们可以让每一层的代码接口都保持其不被分页逻辑污染。这里为了更好的说明这个串联是如何实现的,我用另一个序列图来解释:
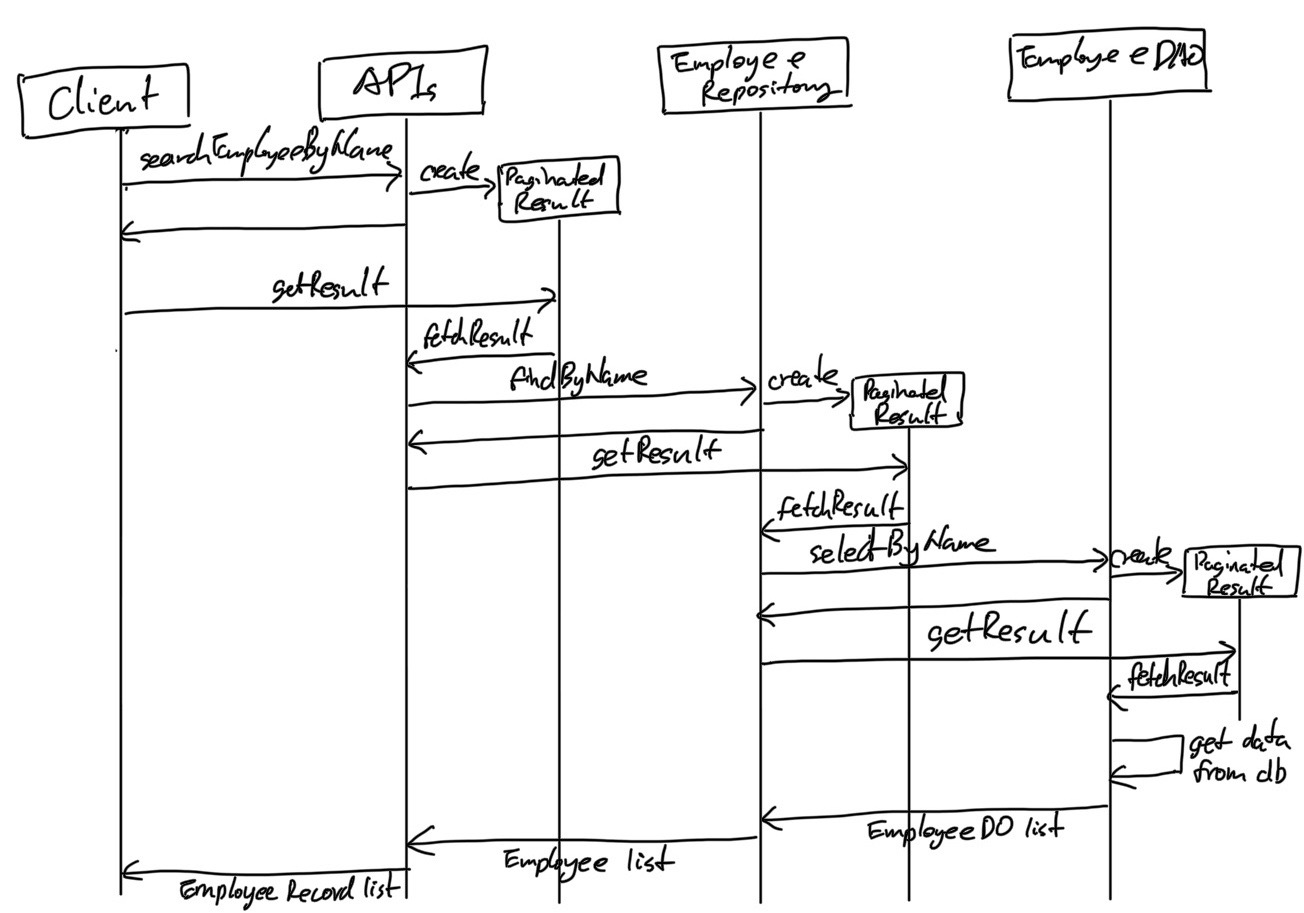
可以看出,每一次我们调用另一层代码的接口的时候,其分页逻辑都是通过PaginatedResult的方式进行透穿的,searchEmployeeByName实现逻辑使用了EmployeeRepository#findByName返回的PaginatedResult,而EmployeeRepository#findByName实现逻辑中又使用了EmployeeDAO#selectByName的PaginatedResult。如此,一层一层的串联,最终做到了分页的透穿而又不会造成每一层代码的污染。
以上,就是我关于如何实现一个绿色无污染的分页逻辑的设计思路和实现方法,希望对你可以有一定的启发作用。

如果,你对上面的解决方案还算认可,又希望可以立刻使用在你的项目中,那么这里有一个好消息,我已经把它做成了一个开源的工具放到了github上,整个工具非常小,而且,完全不依赖于其他第三方工具,所以,你可以放心的使用它。
github项目地址:github.com/Coding-Zero…
最后,如果你觉得这篇文章对你还算有帮助,请分享给其他人吧,独乐乐,不如众乐乐。

