

[学习笔记]微博平台的马年春晚大考内幕
主要内容来源:
- 微博平台的马年春晚大考 姚四芳
- DB春节保障:(t.cn/8FI0GvW)@Billy鹏的足迹
- NoSQL春节保障:(t.cn/8Ff37E3 杨海潮(@jackbillow )
1. 马年除夕的特点&挑战
除夕微博将迎来一次全民的“DDOS”,如与春晚的深度合作(两次主持人口播,20次屏幕二维码互动),抢零点时的超级红包大奖等。预计瞬间访问峰值将达到历史峰值,将是平时访问量的几十倍。针对全民的“DDOS”,微博平台都做了哪些事情?
峰值的微博发表量是平时的数十倍,一般在峰值持续时间较短,一般为几十秒,一旦出现问题,几乎来不及解决问题,尤其是考虑到隐含在140个字后面包含了用户、关系、内容、计数、短链、话题等数十个业务服务,数百个功能点。因此,既要考虑扩容解决预期范围内的峰值,也要做好充分准备,应付各种预期之外的各种异常,如发表量超出预期,大量服务变慢,DB大面积crash等等。
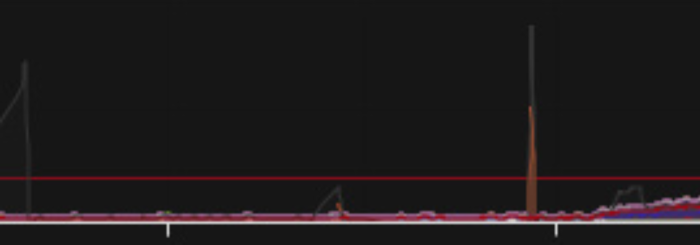
2. 解决处理
2.1 资源扩容
无状态资源线性扩容:
说起扩容,大家第一反应就是线性扩容,加机器。事实上,平台从架构设计就确保了各类资源的线性扩容,如无状态的前端机(web server)、核心/非核心队列处理机、各类业务RPC server 等直接通过增加机器即可线性扩展其QPS/TPS。
cache扩容:
分为读/写两种不同的情况。
- 写入能力扩容:通过re-sharding扩容shard分片的数量来提升写入能力;
- 读取能力扩容:线性增加sharding-group的数量,读请求分散到不同的group,实现读请求的load balance与带宽的均匀分布。这里面存在一个矛盾,group的数量越多,则发表微博时,需要更新的组就越多,反过来会影响写入的性能与复杂度,因此在设计扩容方案时要权衡这两点。
DB扩容:
我们的MySQL团队(t.cn/8FI0GvW)与No… storage等方法将DB的写入能力提升了十余倍,但仍然可能存在峰值超出DB可以承受的极限。
2.2 在线极限压测
资源总是有限的,扩容过程中不可能无限制的添加资源。扩容之后所能够承担的读写能力受影响的因此非常多,比如:
- 有些资源只能在读取能力与写入能力之间进行权衡;
- 重新扩容后的memcached的slab分布是否会影响命中率;
- 不同的介质的访问性能是否的确能够达到所宣称的标准;
- 处理机的并发线程数到达多少时,其整体QPS能够达到最大值;
- 在线性扩容后,给各类资源带来的连接数问题是否会影响吞吐量与性能。
在扩容前,通过对现有机器与资源的评估设计扩容方案,真实的数据只能通过真实环境采集。因此采取在线压测的方式,即:即在凌晨2~6点这段时间,阻塞约百万级别的数据“洪水”,然后瞬间“泄洪”,在短短数秒过程中,采集大量的现场数据,诸如
- 核心处理机的CPU&load在高位运行时(如CPU>1000时)各服务的性能;
- 哪些资源率先变慢达到瓶颈点;
- 是否有新增的错误日志以及异常日志占比是否显著增加。
这其中发现了一些非常有意思的现象,如cache更新的耗时比想象的高许多,DB并不是率先到达瓶颈的,连接数问题对DB的影响远超预期,部署了JDK7的处理机平均处理性能比JDK6要好等等。
第一次压测后,依据保留的日志与现场,将各类业务按脆弱性(即最先可能达到瓶颈的业务与资源)进行排序,有针对性的调整扩容方案后,进行了二次压测,与预期行为基本一致。
2.3 SLA&异常处理&降级
微博平台在进行架构设计时,避免单点是一个基本的原则,也是不可跨越的红线,某台机器,甚至全部的DB宕机后,微博仍然能够提供完整的服务。另外,所有服务与资源都必须提供SLA,承诺其可用性与性能百分位。但人算不如天算,某些服务在压力过大时,并未crash而是变慢,这将是恶梦的开始,会大幅度降低吞吐量。因此,必须快速发现并摘除变慢的业务,避免影响整体流程。 目前微博平台运维团队研发的dashboard包含监控系统、报警系统、降级系统,可以在数秒钟内发现问题,并将相关的系统以电话&短信&邮件的方式通知给相关的运维人员与开发人员,可以依据通知的内容大概判断受影响的资源与服务,并可在1分钟内完成服务降级摘除。
目前微博平台的所有资源与服务都是可降级的,包括openapi接口,前端机,队列处理机,redis,memcached,MCQ,mysql、http请求、RPC请求以及所有的关键路径上依赖的服务等等。在这些服务与资源超出相应的SLA时,即可触发相应的异常处理。
2.4 核心与非核心业务部署隔离
非核心业务投入的资源与关注度相对较低,抗压能力相对较弱,因此更容易受访问量的影响,从物理部署上将核心与非核心业务进行隔离,在极端情况下“舍车保帅”,直接降级非核心业务。
业务服务化
不同的业务服务在设计、实现、部署上都进行解耦合,相互间通过RPC进行调用,从而确保每一个业务在出现异常情况时,可以快速失败,并进行摘除,最大程度上降低了业务之间的相互影响。
延迟处理队列
当处理机的负载持续在高位运行,处理性与TPS持续恶化时,会延迟处理业务消息,将业务消息直接写入延迟队列,部分用户的微博会出现延迟,避免所有服务不能自恢复。
服务降级示意图
微博平台春晚紧急预案示意图
3. DB/NoSQL扩容详细说明
- DB春节保障:(t.cn/8FI0GvW)
- NoSQL春节保障:(t.cn/8Ff37E3)
3.1 DB春节保障:
3.1.1 兵马未动粮草先行
数据库作为整个系统最底层的数据存储单元,承担着数据落地和数据一-致性的责任。 而正是由于数据-致性的原因,也造成数据库的扩容和拆分也将是最耗时的。所以数据库- -定 要提前进入临战状态,我们在3个月之前即开始进入春节准备工作,着手进行设备采购,容量评估。
3.1.2 知己知彼
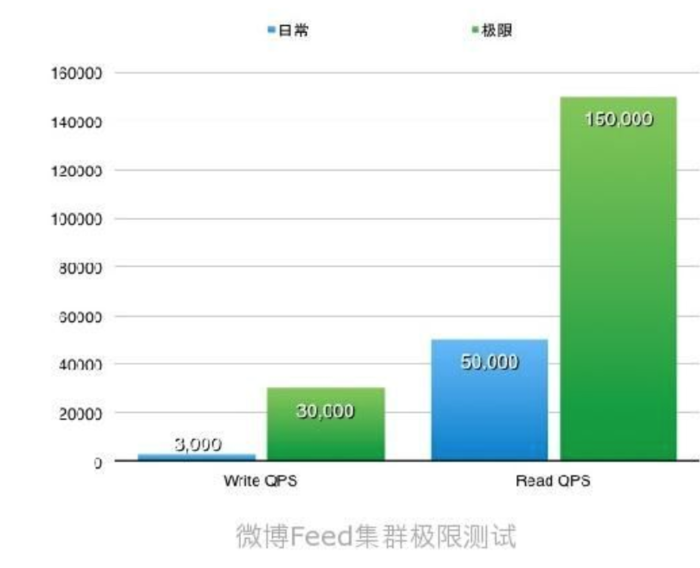
先后进行了基准性能测试->业务读取压力测试->业务写入压力测试。通过使用sysbench -> tcpcopy ->线上泄洪测试,最终确认的核心feed集群可以承担10倍的写入压力,3倍的读取压力。
3.1.3 知己知彼
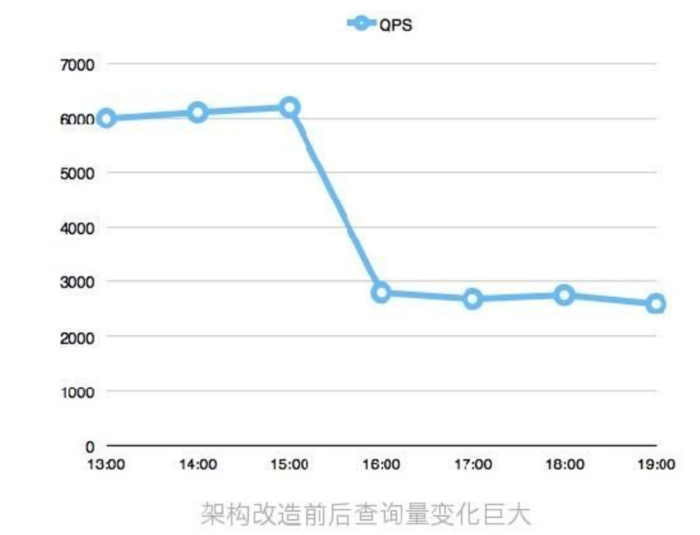
任何优化方案都涉及方方面面。首先我们着眼于自身,先通过调整IO调度算法、替换Flash设备、优化慢查询等方法scale up提高单机性能。 再通过业务的垂直拆分、水平拆分及线性扩容等方法scale out提高 整个集群的可承载量。 之后我们着眼于自身之外的上下游,和cache单元及计算单元共同进行整体结构的优化。 本着缓存为王和最近距离这2个原则,我们对核心集群进行了2个优化: 第一、详细记录分析数据库查询数量及占比,将所有kv类查询前移到cache层,查询瞬间下降近50%。
第二、对核心集群进行多IDC本地化访问改造。 从前端、到缓存最后到数据库,全部实现物理级别的本地化。 实现各个IDC均可以独立承担服务,任何一个IDC出现问题都不会影响其他IDC访问。即实现了业务分流,也实现了业务容灾。
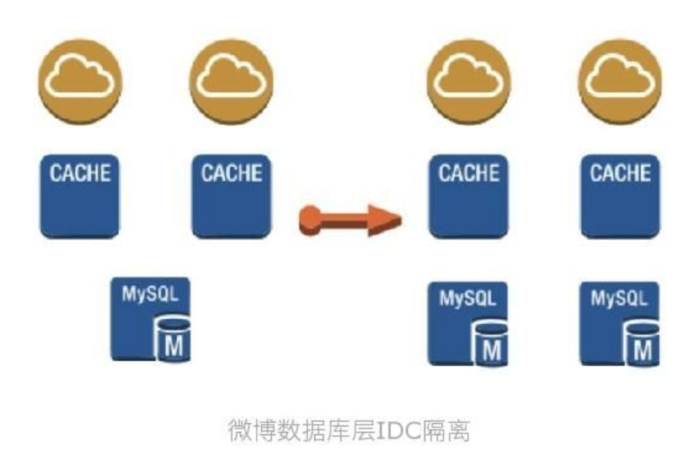
3.1.4 防患于未然
世界上没有不透风的墙,世界也没有不宕机的服务,我们永远都要做最坏的打算。所以针对各种情况我们制定了对应的故障应急预案和业务降级预案,并进行针对性的演习,保证预案是可执行的,并可以实现降级效果,我们相信只有验证过的预案才是预案。 其中故障应急预案主要为主库宕机预案,从库宕机预案。
并且在此基础上,我们几年而外注意对数据库自身的防护,通过和业务提前预定好查询的执行阀值,部署自主开发的sina-kill程序对于超过约定阀值的所有SQL全部进行kil操作,保护数据库自身服务的稳定。
而业务降级预案主要解决写入瓶颈问题,联合开发团队、运维团队,基于write back策略, 将原有先写DB后写cache的顺序调整为先写cache后写queue最后写DB的顺序,通过queue来保 证数据的最终一致性。
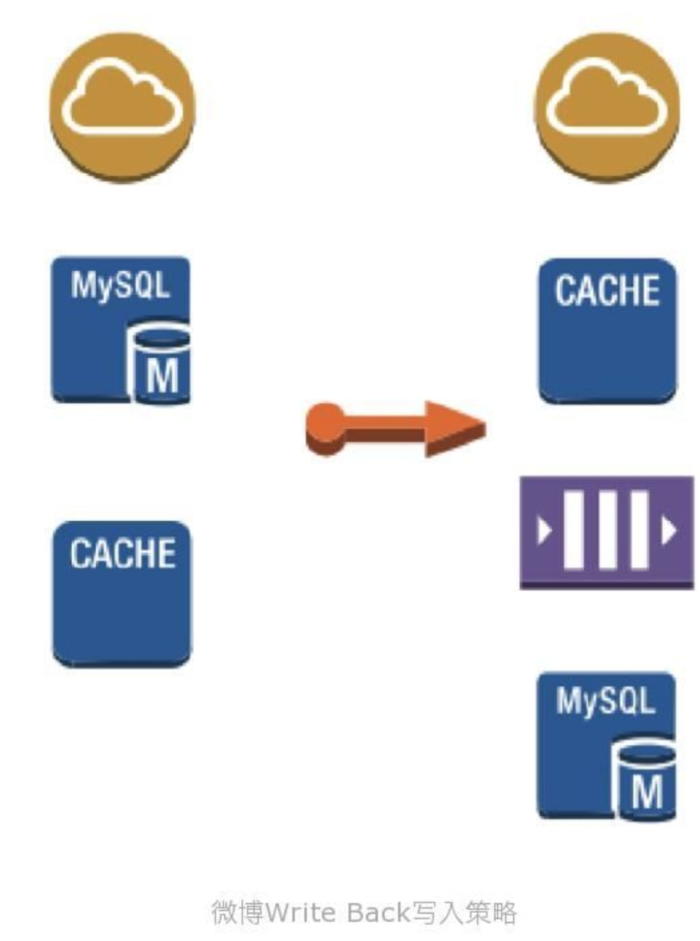
3.1.5 天下武功唯快不破
做完以上的事情之后,就差最后一件了 ,那就是秒级监控。只有尽早的发现问题,才能尽早的解决问题,我们通过终端部署agent,中心机收集分析的方式对核心业务部署了秒级监控,做到实时观察压力趋势,并依据各种阀值线来进行降级操作。
3.2 NoSQL 春节措施
3.2.1 背景介绍
微博数据服务平台是一个2013年Q1刚刚成立的团队,很多新加入的小伙伴们还没来得及熟悉环境,就要在春节期间面临史无前例的挑战。
曾经在一些官方和非官方的场合,提到我们以Memcache为核心的缓存平台和以Redis为核心的内存数据库平台,目前日请求量量已经超过1 5万亿! 峰值请求量超过1500万/秒! 40TB的内存容量,承担着微博99%的请求,是新浪数据服务系统中最核心的力量。面对海量社交衍生数据的爆发,分布式系统呼之欲出,以HBase为代表的分布式数据平台中已经存储着65TB的数据,在线业务已有单表超过9TB!
一方面要面对家常便饭式的服务器宕机,机房调整,网络中断。另-方面要面对类似微博阅读数的每秒数百万的更新,春晚+红包飞的海量在线用户并发抽奖,粉丝服务平台大V数百万每秒的消息群发,跨年一秒数十倍写入峰值,随时可能出现得微博热点等等“疯狂”的业务需求。
不能因为几十台服务器宕机就出现整体系统的波动,仅仅做到能应对这些波动对于我们来说只有60分,我们要保证的是在如此海量的高并发访问下,7x24小时的绝对稳定和超高速响应!
3.2.2 NoSQL平台如何应对高并发读取与写入的海量数据存储?

3.2.3 异步消息队列服务(消息平台)如何处理削峰填谷?
如何应对跨年零点微博峰值写入? !缓存-致性如何维护?跨机房消息如果同步所有这些问题得解决异步队列消息服务在其中都承担了重要角色。
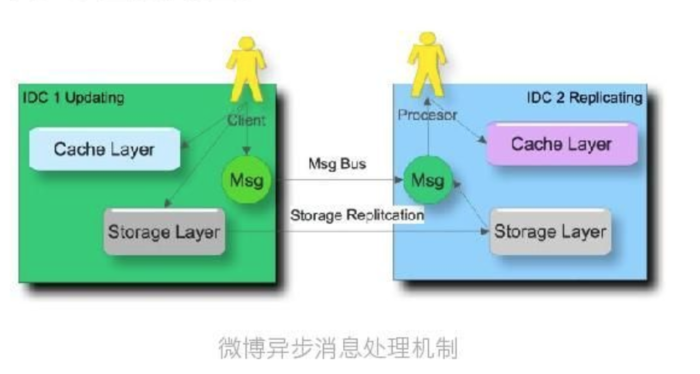
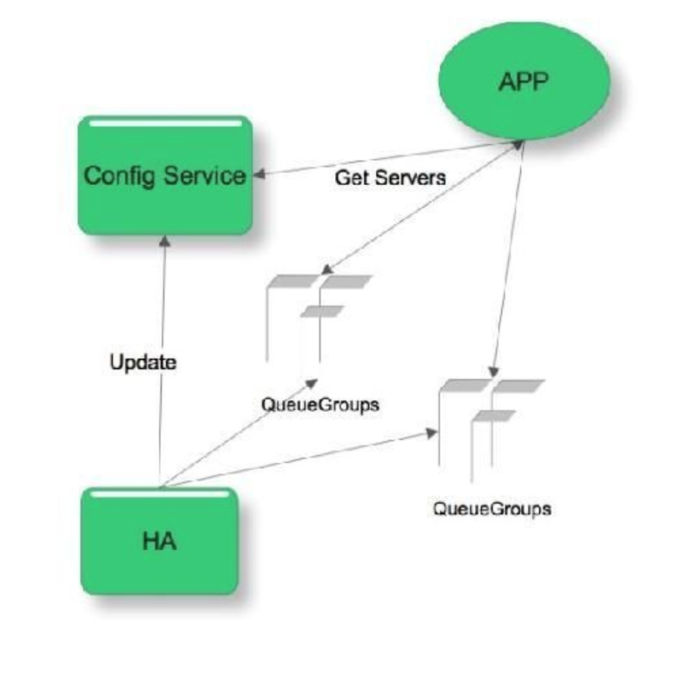
为了应对春节峰值写入得快速扩容和变更,我们引入configserver:
3.2.4 Ram is Disk的缓存平台如何不怕宕机?
是否遇到缓存一宕 机就跑死数据库引起系统雪崩?频繁扩容迁移,无法落地得缓存服务如何无缝切换?如何轻松扩展和应对超级热门数据的高并发访问? Multi-Layered,Memcache的设计就是为了解决这些问题。
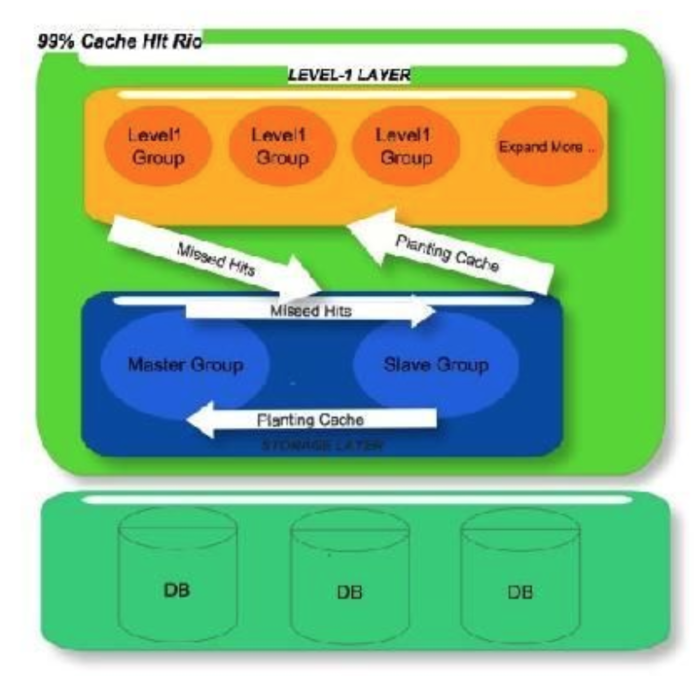
为了应对海量高并发读取和复杂缓存更新逻辑,我们引入了configserver和cacheService:
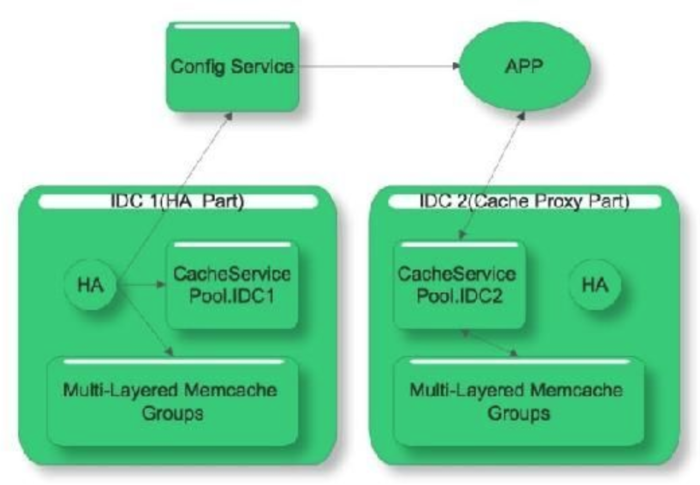
如何屏蔽后端资源扩容迁移变更对业务得影响,提供整体得数据解决方案,帮助业务快速迭代上线,我们还有很多路要走,Data As AService! 2014需要马上加油!
3.2.5 Plans in 2014
业务既要维护缓存还有拆分存储? ! HBase+Redis/Memcached的-体化存储方案就是要解决这些问题, 真正做到data as a service。 预热Memcached需要1天之久? Memcached的内存dump和内存同步,就是要解决这个问题,达到快速扩容和调整得目的。Redis全内存得 方案成本太高? !基于Flash的Redis存储,彻底解决存储成本问题。
另外借此机会也希望能再次能遇到志同道合之士,围绕数据为核心的服务体系,不管你 是SA/DBA/DevOPs还是C/JAVA数据开发方面得高手,愿意迎接支撑微博每秒千万级的请 求量,复杂分布式数据系统的各种挑战!
