

太长不看版
- 跳跃表是有序集合zset的底层实现之一, 除此之外它在 Redis 中没有其他应用。
- 每个跳跃表节点的层高都是 1 至 64 之间的随机数。
- 层高越高出现的概率越低,层高为i的概率为
。
- 跳跃表中,分值可以重复, 但对象成员唯一。分值相同时,节点按照成员对象的大小进行排序。
本篇解析基于redis 5.0.0版本,本篇涉及源码文件为t_zset.c,server.h。
什么是跳跃表
跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。
我们都知道在有序数组中进行查找,可以使用二分查找,将时间复杂度降为O(log n)。但是有序链表做不到,是因为有序链表获取某元素复杂度为O(n),无法通过二分的思想去跳过一些元素的访问。
例如下图要查找元素50,就必须 5 -> 6 -> 10 -> 30 -> 49 这样去找,而不能说先看 中心元素49小于50,则开始从中心右边开始查找,跳过元素5,6,10, 30的访问。

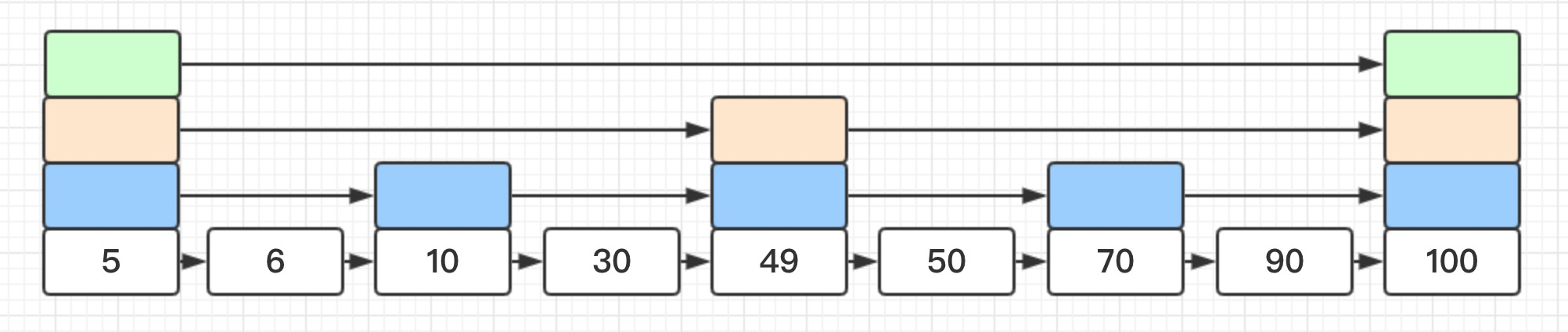
这时查找元素50变成了 5 -> 49,略过了中间元素6,10, 30。上图中通过首节点存储不同步长的指针将链表完美二分,但是实际上的跳表却类似与下面这张图的结构,大部分情况喜爱不是完美二分的:
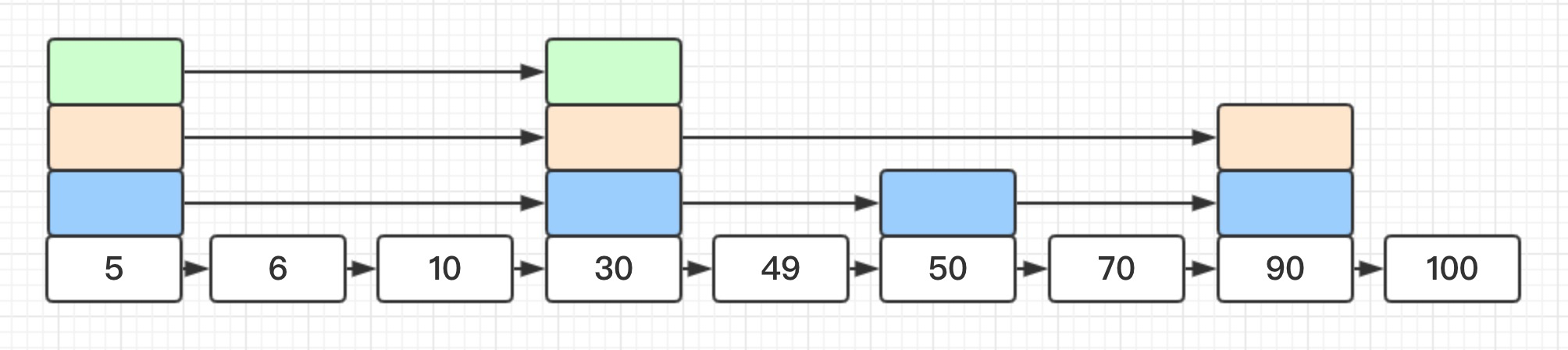
跳跃表采用了随机算法(层高越高概率越小)来决定层高,相同层之间通过指针相连。redis实现中某节点层高为i的概率为 。
为什么不采用最完美的二分结构?
考虑一下,插入节点的情况。当中间插入一个节点,此时的二分结构会被打破,所以需要不断的进行调整。想想平衡树,红黑树复杂的再平衡操作,而此处的再平衡调整比之有过之而无不及。而使用随机算法进行层高选择的方法也可以实现O(logN)的平均复杂度,而且操作也相对简化的很多。
跳跃表(redis实现)的空间复杂度
相关定义
// 层高最大值限制
#define ZSKIPLIST_MAXLEVEL 64 /* Should be enough for 2^64 elements */
// 层高是否继续增长的概率
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
// 跳表节点定义
typedef struct zskiplistNode {
// 存储内容
sds ele;
// 分值,用于排序
double score;
// 后退指针
struct zskiplistNode *backward;
// 变长数组,记录层信息。层高越高跳过的节点越多(因为层高越高概率越低)
struct zskiplistLevel {
// 指向当前层下一个节点
struct zskiplistNode *forward;
// 当前节点与forward所指节点中间节点数
unsigned long span;
} level[];
} zskiplistNode;
// 跳表结构管理节点
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
// 长度
unsigned long length;
// 跳表高度(所有节点最高层高)
int level;
} zskiplist;
int zslRandomLevel(void) {
// 计算当前插入元素层高的随机函数
int level = 1;
// (random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF) 概率为1/4
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
层高为1概率为 1-p(不进while)
层高为2的概率为 p(进一次while) * (1 - p)(不进while)
层高为3的概率为 p(进一次while) * p(进一次while) * (1 - p)(不进while)
...
层高为n的概率为
层高的期望
在概率论和统计学中,数学期望(mean)(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。它反映随机变量平均取值的大小
在redis实现中 p=1/4, 层高期望为E约等于1.33,所以节点的平均层高约等于1.33是个常数,从而得出跳跃表的空间复杂度为O(n)。
跳跃表(redis实现)相关操作
创建跳跃表
zskiplistNode *zslCreateNode(int level, double score, int ele) {
zskiplistNode *zn =
malloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = malloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
// 头节点层高为64(层高的最大限制)
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
上述代码中可以看到,头节点的层高数组直接为最大长度,因为每次查找都要从头部开始,而且整个跳跃表的高度是动态增加的,初始化时直接按照最大值申请高度,避免后续高度增加时为头节点重新分配内存。所以之前的跳跃表图例应该如下图所示:
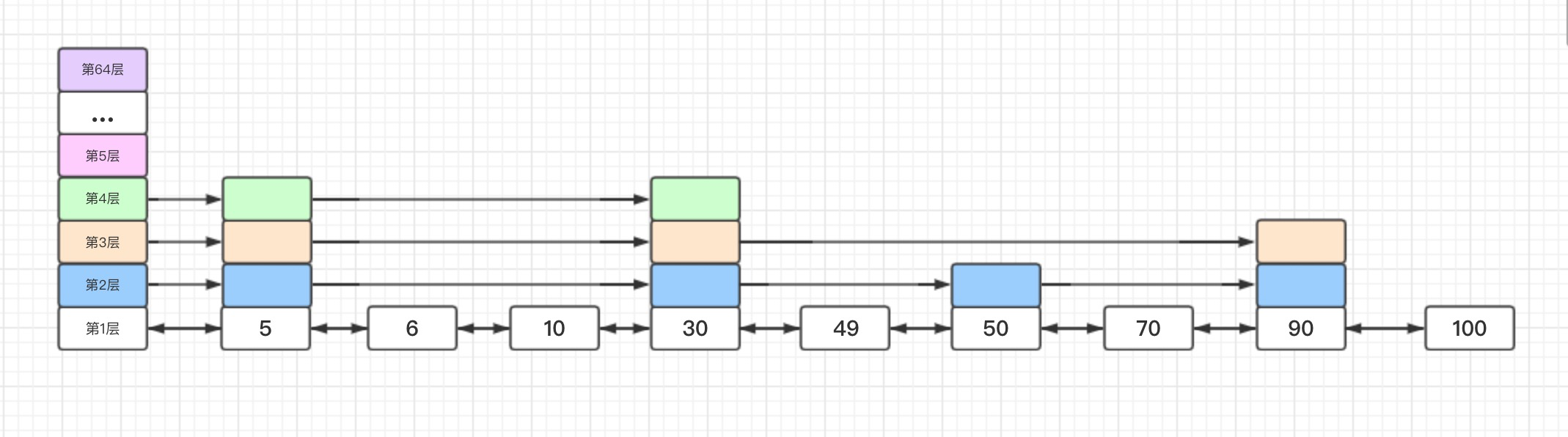
插入节点
int zslRandomLevel(void) {
// 计算当前插入元素层高的随机函数
int level = 1;
// (random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF) 概率为1/4
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
// update存放需要更新的节点
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
// 第一步,收集需要更新的节点与步长信息
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// score可以重复,重复时使用ele大小进行排序
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
// 第二步, 获取随机层高,补全需要更新的节点
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
// 第三步,创建并分层插入节点,同时更新同层前一节点步长信息
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
// 第四步,更新新增节点未涉及层节点的步长信息,以及跳表相关信息
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
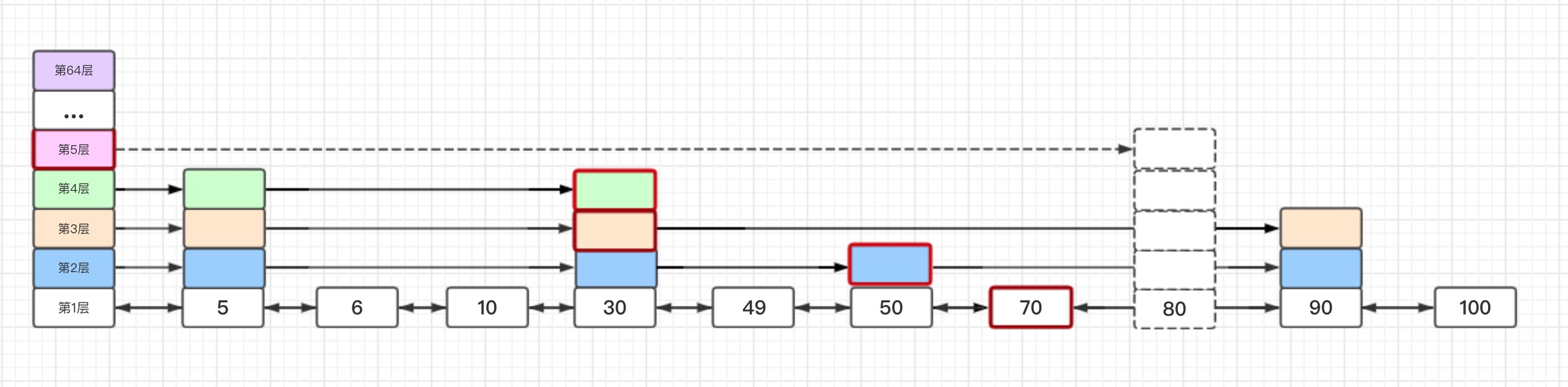
插入节点分为四步(举个栗子,边吃边看):
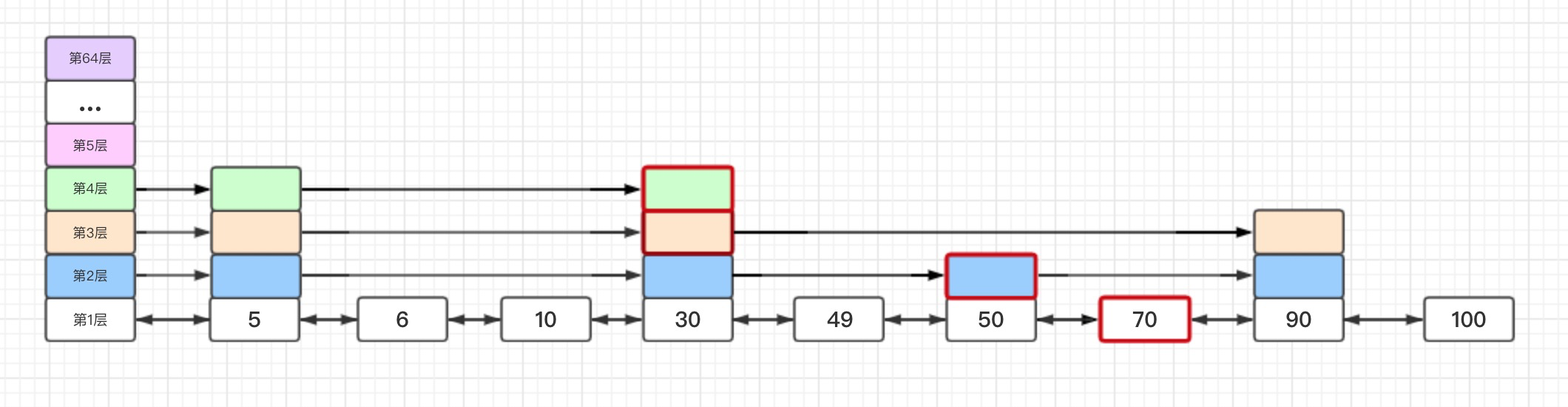
- 收集需要更新的节点与步长信息
- 将插入新增节点后每层受影响节点存在update数组中,update[i]为第i + 1层会受影响节点(红框框出来的就是例子中可能会受影响的节点)。
- 将每层头节点与会受影响的节点中间存在节点数存在rank数组中,rank[i]为头节点与第i + 1层会受影响节点中间存在的节点数(rank为[6, 5, 3, 3])。
- 获取随机层高,补全需要更新的节点,同时可能更新跳表高度
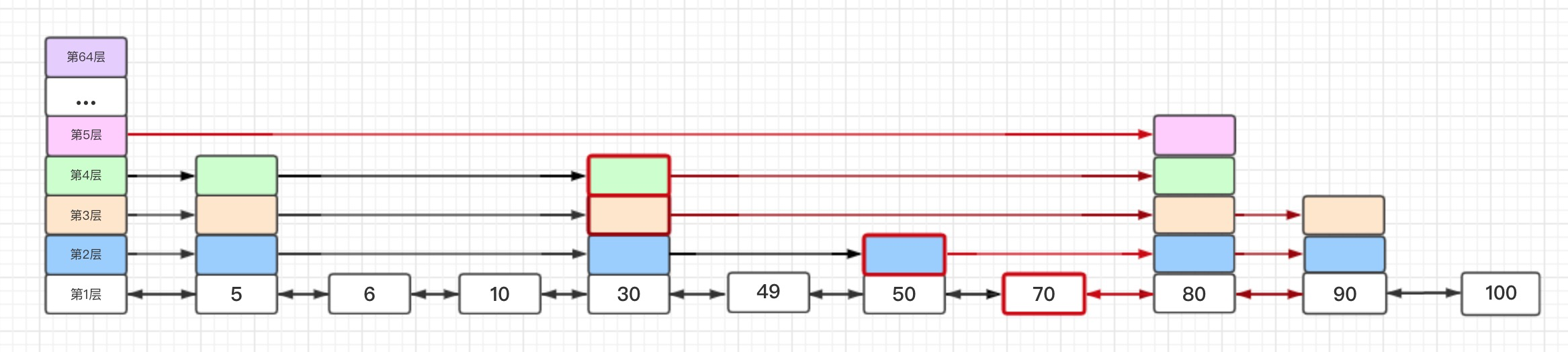
- 通过zslRandomLevel函数计算当前插入节点侧层高,层高越高出现的几率越小(我们指定了是5,实际是随机的)。
- 因为搜索需要更新节点是从跳跃表当前高度的那一层开始的,如果新插入的节点的层高比当前表高还高,那么高出的这几层的头节点也是需要更新信息的(第五层的头节点后继有人了,所以它也需要被更新)。
- 如果当前层高高于表高,则更新表高(表高从4变成5)。
-
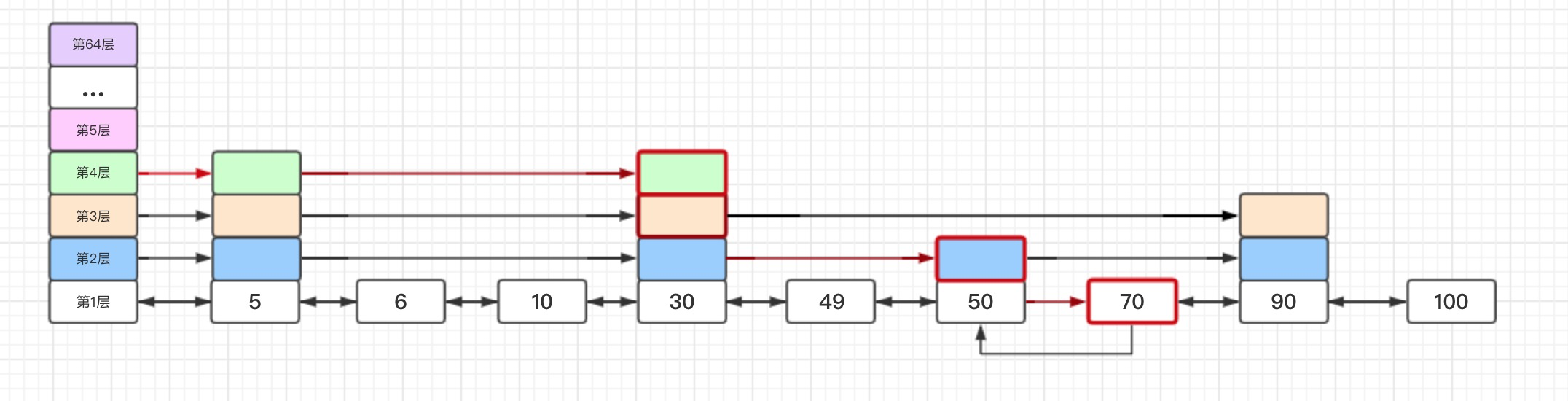
创建并分层插入节点,同时更新同层前一节点步长信息
- 创建节点,然后根据当前节点的层高,在每一层进行节点插入(和简单链表插入一样)。
- 更新下每层前一个节点(update[i]对应节点)与自身节点的步长信息。
-
更新新增节点未涉及层节点的步长信息,以及跳表相关信息与节点自身的相关信息
- 如果当前节点的层高比跳表高度低,那么高于当前节点层高的那些层中排在当前节点之后的节点步长信息都需要+1(因为在它和它的前一个节点之间插入了新元素)。
- 更新跳表长度与当前节点与第一层下一节点的后退指针(后退指针可以理解为只有底层链表有)。
查找节点
/* Find the rank for an element by both score and key.
* Returns 0 when the element cannot be found, rank otherwise.
* Note that the rank is 1-based due to the span of zsl->header to the
* first element. */
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0))) {
rank += x->level[i].span;
x = x->level[i].forward;
}
/* x might be equal to zsl->header, so test if obj is non-NULL */
if (x->ele && sdscmp(x->ele,ele) == 0) {
return rank;
}
}
return 0;
}
/* Finds an element by its rank. The rank argument needs to be 1-based. */
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span;
x = x->level[i].forward;
}
if (traversed == rank) {
return x;
}
}
return NULL;
}
redis实现中跳跃表和dict共同实现了zset,dict实现O(1)复杂度获取元素对应score,跳跃表用来处理区间查询的相关操作,同时因为score可以重复,所以跳跃表无需实现通过ele获取score(通过dict查)以及通过score获取ele(貌似也没有这个需求)。
一般查询需求有两个:
- 根据rank查询节点,主要是为了通过该节点指针进行遍历获取某个区间的节点数据。
- 根据score与ele(score可能重复,所以需要ele)获取节点的rank,进行count之类的数值计算。
删除节点
/* Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
// 被删除节点在第i层有节点,则update[i]为被删除节点的前一个节点
if (update[i]->level[i].forward == x) {
// 步长 = 原步长 + 被删除节点步长 - 1(被删除节点)
update[i]->level[i].span += x->level[i].span - 1;
// 指针越过被删除节点
update[i]->level[i].forward = x->level[i].forward;
} else {
// 被删除节点在第i层无节点,则 步长 = 原步长 - 1(被删除节点)
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
// 更新被删除节点下一节点的后退指针
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
删除节点与添加节点步骤类似,分为三步:
- 收集需要更新的节点。
- 删除节点所在的层链表移除节点(和简单链表移除节点一样),并更新前一节点的步长信息(update[i]所存节点)。
- 更新跳跃表高度与长度。
