

本文从移动端构架设计、类设计、方法设计以及最佳实践等方面简单讨论了如何开发出高质量的代码。
本文同时发表于我的个人博客
Overview
高质量代码、架构设计以及重构等都是充满智慧且需要深厚功底和实战经验的话题,本不敢随意拿来讨论。只是最近在项目中对两个较大的模块做了一次重构,再加上补习了一下《代码大全》以及《重构》,因此尝试着做一次这方面的分享。代码设计本身也是一个仁者见仁、智者见智的话题,下述讨论如有不正确之处,请指正。
首先需要回答的问题是什么样的代码是高质量代码,其次才是如何设计出高质量代码。
从宏观上说,高质量代码无外乎于:可扩展性强、可维护性高、可读性好。 从实现的层面说,主要包含:划分层次合理、数据流向简洁明了、模块间通信合法、类有良好的封装和一致的抽象、实体内部高内聚、实体间低耦合等。
架构设计
对于终端开发来说,架构设计最经典莫过于 MVC,在此基础上又衍生出了像 MVVM 之类的架构。 之前看过一篇文章讨论是先分层再分模块,还是先分模块再分层的问题。虽然,这两种方式各有道理,但个人还是建议先划分模块,再在模块内部按 MVC 或其他架构分层,因为对于终端来说模块有更强的独立性,一个模块基本上也是由M、V、C 三部分构成。
关于 MVC、MVVM 等构架的文章已有很多,本文不再赘述。
以 MVC 为例,需要强调的是 M、V、C三者间的通信规则:
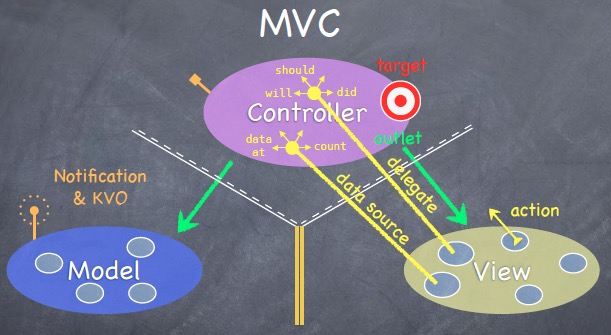
项目中,往往一个模块由一个人单独负责,这就导致不同的模块可能采用不同的架构,MVC、MVP、MVVM 以及其他变体构架可能在一个项目中同时存在,显得有些混乱。最好是能统一一下,一个项目只用一种构架。
类设计
在面向对象编程中,类的好坏直接影响代码的质量,那么什么样的类是设计良好的类? 同样,从宏观上说设计良好的类具有:良好的抽象与封装。
抽象与封装是两个关系非常紧密的概念。
代码大全对抽象的定义:抽象是一种能让你在关注某一概念的同时可以放心地忽略其中一些细节的能力。
具体到类上,抽象主要指接口的抽象,即对外宣称该类具有什么样的能力、能完成哪些工作。而类的具体实现对外界是个黑盒子,无需关心。 封装更强调的是隐藏细节,迫使外界无法了解类内部的细节信息。
良好的抽象
通过抽象接口可以简化外界对类的使用,使其无需关心类内部复杂的实现细节。 在设计接口时,需要注意的问题:
-
接口需要展现一致的抽象层次
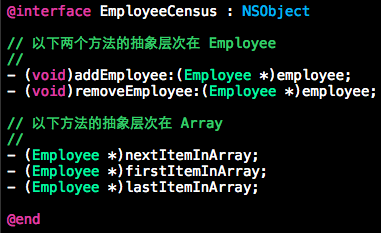
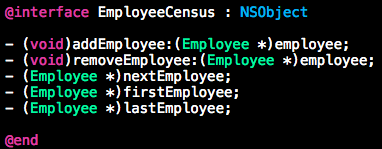
-
接口应隐藏细节 接口应该隐藏业务层无需关心的细节问题。在我们项目中,支持游客登录和 QQ 登录,而登录模块将这两种登录方式区分开来以不同的 notification 通知业务层相关的登录信息。然而绝大多数业务逻辑并不关心具体的登录方式,若在此基础上添加微信等其他登录方式,接口将更加难以维护。 因此,在登录模块重构后将这些细节信息都隐藏在登录模块内部,对外提供统一的回调接口。
-
高内聚 无论是在类层次还是方法层次,高内聚一直是我们追求的目标之一。对类来说,抽象与内聚关系十分紧密,类具有良好抽象的接口一般也意味着有很高的内聚性。
在我们 QQ 阅读项目中,有一个非常重要的类:
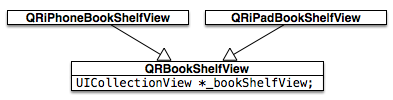
QRBookInfo,从名字看应该是一个用于表示书籍信息的类。其对外的接口应该有:id(唯一编号)、name(名称)、author(作者)以及 format(格式)等。但在现实中QRBookInfo类却包含了很多不属于它的信息,如:阅读进度、阅读时间、添加到书架时间以及在书架上分组 id 等,最终该类暴露给外界的属性有将近40个,沦落为一个大杂烩,很明显已经不具备高内聚特征了。如果要对该类进行重构,则可以通过 Extract Class(提炼类)的手法进行,将不属于该类的职责提炼到新的类中。从
QRBookInfo至少可以提炼出3个类:QRBook——用于描述书籍本身,抽象接口有:id(唯一编号)、name(名称)、author(作者)以及 format(格式)等;QRBookShelfItem——用于描述书架上每个项的信息,抽象接口有:id(书籍编号)、addTime(添加到书架时间)以及 categoryId(该书在书架上的分组编号)等;QRReadingItem——用于描述阅读信息,抽象接口有:id(书籍编号)、readTime(阅读时间)以及 readProgress(阅读进度)等。
项目中,还有个书架类:
BookShelfViewController,有5000多行代码,注册了20多个通知,已经到了几乎无法维护的地步,其中不仅包含了书架相关的逻辑,打开书的逻辑也全部扔在里面。后来在一个新项目中需要使用这个类时,稍微做一点小改动都无法正常工作。此次对书架进行重构时将打开书的逻辑全部移到其他类中,QRBookShelfViewController这个类只专注于处理书架相关的逻辑。高内聚作为管理类复杂度的一个重要原则,我们应该时刻把握这一利器。
-
尽量让接口可编程,拒绝隐藏的语义
来自代码大全:每个接口都由一个可编程(programmatic)部分和一个语义(semantic)部分组成。其中,可编程部分由接口中的数据类型和其他属性构成,编译器能强制性地要求它们(在编译时检查错误),而语义部分则由『本接口将会被怎样使用』的假定组成,而这些是无法通过编译器来强制实施的。
比如:在调用 methodA 前必须先调用方法 methodB,这一要求则属于 methodA 的语义部分。由于没有编译器的强制检查,这一隐藏语义很可能被调用者忽略,引起错误。
因此,接口设计时尽量不要包含语义部分,可以通过抽取新接口或添加 Asserts 等方法将语义接口转换为编程接口,确实无法避免也应在接口中通过注释说明其中的语义。如在上述例子中,可以添加新的接口methodC,在该接口中调用 methodB、methodA,从而消除 methodA 的语义。
-
谨防在修改时破坏接口的抽象 从前面讨论可知,一个类应该围绕一个中心职责,处理一个任务。在类设计之初可能有较高的内聚性,但在实际开发中,类会被不断扩展,不断加入新的功能和数据。类的内聚性和抽象性很可能在这个过程中被破坏。 经常在代码中可以看到一个类有截然不同风格、不同抽象的接口,这往往是被"篡改"的结果。另外还会看到有2个、3个、4个甚至更多个相同功能,只是参数不一样的接口。有的接口多出个 bool 型的参数,有的带个 block 类型的参数,有的带个 delegate 形式的参数,在这种粗暴式的背后往往隐藏着重复代码的危机。 在我们的登录模块中,登录接口有10个之多,登录回调也是五花八门,有 block、delegate 以及 notification。因此在业务层的类中经常看到这3种回调方式同时存在,维护成本极高。我相信,在设计之初绝非如此混乱,而是在日后开发过程中慢慢引入的。 因此在修改已有类接口时一定要三思,切不可图一时之便随意添加修改,否则久而久之很可能导致类失控。若因业务需要必须修改,最好将需求提给类的作者,由他来修改。
-
设计接口时尽量不要给调用者留坑 我们有一个基类 controller:
QRBaseViewController,其定义了一个接口,作用是让子类自定义 NavigationBar 上的item: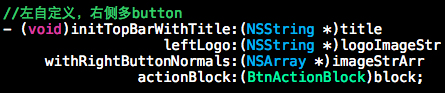

self调用其他子方法或属性,这样就出现了cycle retain。经过一番排查发现有6、7个类存在这样的问题。 (ps: 上面的actionBlock属性应该使用copy而不是strong)
良好的封装
抽象更多是强调这个类是什么,能做什么,而封装则是强制外界无法了解实现的细节。 良好的封装一般需要注意:
-
尽可能地限制类中各成员的可访问性 使可访问性尽可能低是促成封装的原则之一,在 Objective-C 中则是尽可能将类的数据成员、属性以及方法放到类的匿名分类中,使类的接口(.h文件)文件尽量简洁。
-
不要暴露类的数据成员 在 Objective-C 中,属性作为特殊的数据成员,可以暴露给外界,但在这么做之前请认真思考是否真的需要这么做。 但是,作为容器类的数据成员(Array、Dictionary、Set 等)一定不要轻意暴露给外界,因为这属于很底层的实现细节。一旦暴露了这些细节,封装将被严重破坏。
试想一下,若有一天需要将 Array 改为 Dictionary,影响范围有多大? 如果暴露的是容器的mutable版本,那么外界可以任意对该容器进行操作,你已失去各种控制、错误检查的能力,同时还可能有多线程问题。
-
私有实现细节一定不要暴露在头文件中 头文件应该是简洁明了的,仅用于向外界表达该类能做什么。简洁的头文件也能减少类的使用者在使用该类时的成本。
-
要格外警惕从语义上破坏封装性 语法上的封装可以通过 private、匿名 category 等方式实现,然而语义上的封装性更难以控制。以下是代码大全中列举的从语义上破坏封装性的例子:
- 不去调用类 A 的 InitialixeOpertaions()子程序,因为你知道 A 类的 PerformFirstOperation()子程序会自动调用它;
- 不在调用 employee.Retrive(database)之前去调用 database.Connect()子程序,因为你知道在未建立数据库连接时employee.Retrive(database)会去连接数据库;
- 不去调用类 A 的 Terminate()子程序,因为你知道 A 类的 PerformFinalOperation()子程序已经调用了该方法。
上述例子的问题在于,其调用方不是依赖类的抽象接口,而是依赖于类的内部实现。当通过查看类的内部实现得知可以如何使用该类时,就不是针对接口编程,而是透过接口针对内部实现编程。这是一种十分危险的举动,类的封装性已被破坏,一旦类内部实现改变了,可能引起严重错误。
-
低耦合 两个类之间的关联程度称为耦合,低耦合一直是我们的追求。类的封装性直接影响到耦合程度,若类过多的将细节信息暴露出来,无疑会增加类与使用方间的耦合度。 理想情况下,类对于调用者来说是个黑盒子,调用者通过类的接口就能完成对该类的使用,而无需深入类内部了解实现细节,当然这首先需要该类有很好的抽象与封装。反之,若在使用一个类时需要了解其内部实现,则必然在两者之间形成很高的耦合。 抽象性与耦合间的关系也十分紧密,良好的抽象与封装一般也会有较低的耦合度。
项目中,有个用于表示书架分组的类:
QRCategoryViewController,该类不仅用于处理分组相关的业务逻辑,连用户分组数据的读取、存储也全在这个类中。而书架在决定显示哪些书时也需要知道当前分组信息,因此,在书架初始化时必须也初始化一个QRCategoryViewController实例,用于获取当前分组信息。这里,正是由于QRCategoryViewController类在抽象与封装上没有处理好,导致原本几乎没有耦合关系的两个类QRCategoryViewController与BookShelfViewController间高度耦合。在重构时,将分组数据的管理移到一个新类QRCategoryManager中,使QRCategoryViewController与BookShelfViewController间彻底解耦。
慎用继承,用好继承
作为面向对象三大特性之一的继承,重要性不言而喻,用好了能简化程序,反之会增加程序复杂性。 在决定使用继承之前,需要认真思考基类与派生类之间是否是"is...a"的关系,如若不是,那继承就不是正确的选择,此时可考虑"has...a"(包含)关系是否更合适。 代码大会中关于继承的几个经典描述:
- 继承的目的在于通过"定义能为多个派生类提供共有元素的基类"的方式简化代码。
- 基类即对派生类将会做什么设定了预期,也对派生类能怎么运作提出了限制。
- 派生类必须能通过基类的接口而被使用,且使用者无须了解两者之间的差异。
- 如果派生类不准备完全遵守由基类定义的同一个接口契约,继承就不是正确的选择。 (你做到了吗^-^)
项目中的书架类BookShelfViewController由于要同时适配 iPhone 和 iPad 两个版本,因此在代码中随处可见:if(IS_IPHOEN)...else这样的语句。
在重构的时候,将 iPhone 与 iPad 的UI逻辑抽取到两个子类,而它们共有的数据相关逻辑(如:云书架、章节更新等)放在基类。
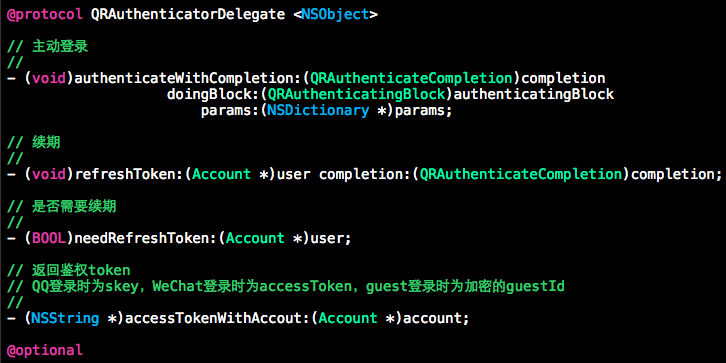
QRAuthenticatorDelegate:
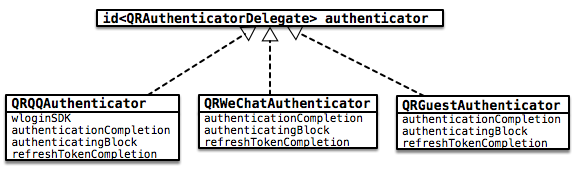
QRQQAuthenticator、QRWeChatAuthenticator 以及 QRGuestAuthenticator实现了 QRAuthenticatorDelegate。
由于 Objective-C 语言的动态性,其成员函数天生就具有虚函数的特征,当继承体系过于复杂,函数重载将进一步加大问题的复杂性。 继承在使用前一定要三思,或许包含、接口是更好的选择,使用不当会增加程序复杂性。
隔离错误
船体外壳装有隔离舱、建筑物都有防火墙,其作用都是隔离危险。 在防御式编程中同样需要隔离危险,在系统层面可以有专门的类用于处理错误、隔离危险(来自代码大全):
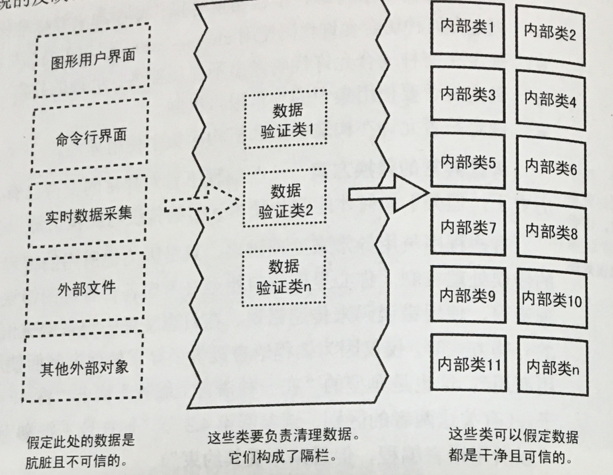
在程序中错误又可分为2类:
- 绝不应该出现的、意料之外的错误(之所以会出现可能是程序存在 bug);
- 不经常出现的、非正常情况。
对于上述2种错误应该分别使用断言(Assertions)和错误处理。回到前面那个问题,在类的公开接口中可以视情况使用错误处理或断言,而在类的私有方法中可以直接使用断言。 (ps: 断言主要用于在开发期间快速检测代码错误)
方法设计
『代码首先是写给人看的,其次才是让机器执行的』,在方法设计时更应考虑这一点。
起个好名字
命名是个技术活,对代码维护性、可读性至关重要! 需要注意的是,方法名应该强调方法是做什么的,而不是怎么做的。 除此之外,方法名在内存管理上也有约束: 任何以下列名称为前缀的方法,若其返回值为 object,则方法调用者持有该 object:alloc、new、copy以及mutableCopy。 还有一个更为严格的规则:任何以 init 为前缀的方法必须遵守下列规则:
- 该方法必须是实例方法;
- 该方法必须返回类型为
id或其所属class、superclass、subclass 的对象; - 该方法返回的 object 不能是 autorelese,即方法调用者持有返回的 object。
尤其是在 ARC 与 MRC 混用的项目中,必须遵守上述规则,详情可参看我之前的文章:Inside Memory Management for iOS。
高内聚
一个方法只做一件事!并通过方法名很优雅的表达出来! 但在实际中很多方法往往做了更多,有的方法长达100多行,甚至几百上千行。 低内聚的方法带来的后果有:
- 难以维护;
- 因为做的事太多,无法取一个好的方法名;
- 往往导致重复代码,试想一下,若 methodA 做了 task1 和 task2,methodB 做了 task1 和 task3,那 task1 相关的代码是不是就重复了。
将复合语句体抽取为子方法
将 if...else...、for、switch 等语句的 body 抽取为子方法,并通过好的方法名提高可读性。
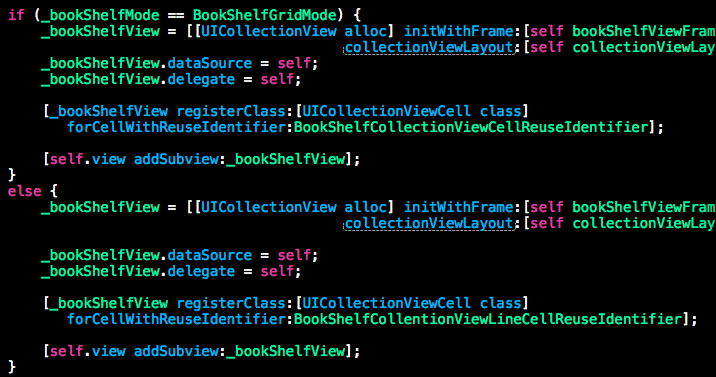
这两段代码做了同样的事情,都是根据用户选择加载 grid 或 line 模式的书架,但其可读性差异还是很大的。
复合语句体加大括号
经常会看到这样的代码:
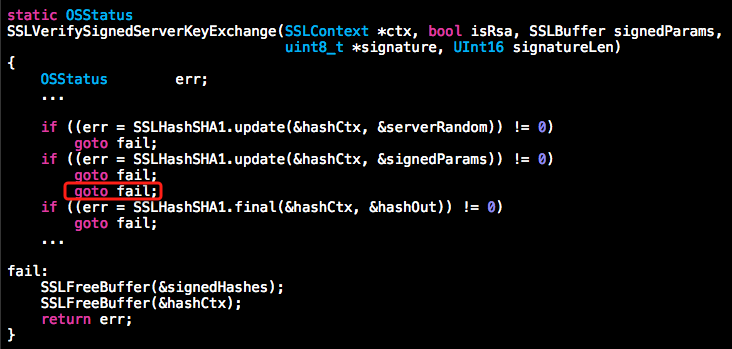
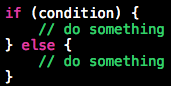
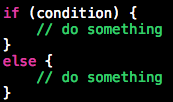
另外,关于 if 语句的格式规范问题,虽各有各的习惯,但强烈不建议做成下面这样(事实上大量 if 被写成这样,因为 Xcode默认代码补全就是这样的):
将复杂的条件表达式抽取为子方法或命名良好的赋值语句
如果条件表达式过于复杂为了提高可读性,若该表达式重复出现应该抽取为布尔方法,否则可以将其赋值给一个良好命名的变量。 我们书架有个规则,在 iPhone 上对于自定义的分组,若该分组下有书籍,则需要在书籍列表的最后面添加一个导入书的按钮。



中间变量
前面讲到复杂的布尔表达式可以转换为命名良好的中间变量,但并不意味着可以随意添加。多一个中间变量就多一份复杂,多一种状态,对于使用次数少的中间变量可以直接将表达式内联到语句中。
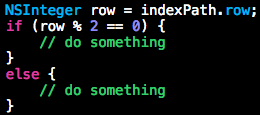
indexPath.row 含义清楚明确,没必要再定义中间变量 row。
对于类来说也是如此,为了解决某些问题往往会引入一些状态成员变量,这种做法无可厚非,但还是要谨慎。往往状态变量涉及什么时候 set、什么时候 reset,增加了类内部的复杂性,也增加了类内部方法间的耦合度。
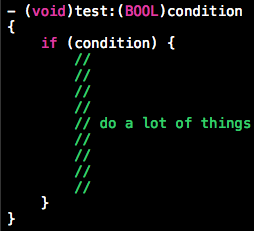
优先处理错误情况
若方法需要检查参数或其他条件,把检查操作放在方法开始部分,条件不满足时立即返回。
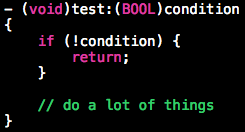
switch 语句不要有 default 分支
尤其是利用 switch 处理 enum 时,轻意不要写 default 分支,这样在漏掉哪个枚举值没有处理时,编译器会发出警告。但在有 default 分支时,是不会有警告的。
最佳实践
该小节主要讨论在开发过程一些值得注意的小点,不一定与设计有关。
充分利用泛型
LLVM 7.0从编译器层面支持泛型,系统中常用的容器都增加了对泛型的支持,无疑是一个重大利好。



合理使用 nullable、nonnull
同泛型,nullability 也是编译器 LLVM 支持的一个特性,用于描述接口中的值是否可以为 nil。 对于 nonnull 的接口,若传入的是 nil,编译器会发出 warning。同样,nullability对接口的自我说明能力比 warning 更有意义。
用好 Objective-C 的动态性
Objective-C 语言的动态性给我们带来了无限的想象空间,『只有想不到,没有做不到』。 典型的利用到 Objective-C 动态性的例子有:JSPatch、MJExtension、Swizzling、KVO 以及 AOP等等。
- JSPatch 用于热补丁,已经非常火,无须多言;
- MJExtension 主要用于将 json 自动转换成 Objective-C 的对象,能极大的提高开发效率;
- Swizzling 的使用就更加常见了,我们有一个典型的用途:通过 Swizzling UIViewController 的
viewWillAppear:方法以及 UIButton 的sendAction:方法,记录用户的操作路径,在 crash 时随 crash log 一起上报,通过该方法解决了不少疑难杂症的 crash; - KVO 用处很大,争议也很大,用好了可以简化代码,具体可以参考我之前的文章:KVO漫谈;
- AOP 主要用于将不相关的逻辑独立出来,如打 log 等,在登录模块重构时使用到 AOP 思想,具体可参考我之前的文章:AOP漫谈;
统一管理队列
GCD作为实现多线程的方式之一,结合 block 使用时简单方便。因此,在代码中经常存在大量dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{这样的用法。
虽然系统会控制 GCD 使用的线程数,但当线程被锁住时,还是会创建新的线程以供其他 block 使用,因此某一时段系统可能会创建出大量线程,最终会抢占主线程的资源,影响到主线程的执行。
因此,必要时可以统一管理这些队列,YYDispatchQueuePool 就是一个很不错的实现。
类的子方法按功能排列
虽然一直追求高内聚的类,但 UI 交互的类尤其是 UIViewController 一般功能都比较复杂,此时最好按功能排列方法,同一功能的方法放在一起。 如UIViewController的这些方法应该固定排在最前面:
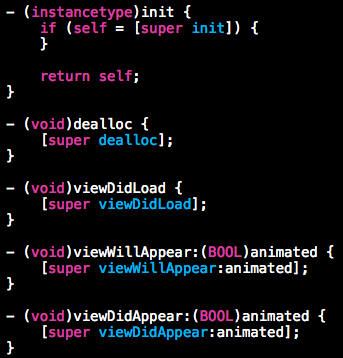
#pragma mark - 那就更好了。还可以通过 category 将不同的功能分到不同的 category 中。
另外,也不要将多个类放到同一个文件中。
正确使用 category
通过 category 可以扩展现有类的功能,在使用 category 时有几个点需要注意:
- category 独立于主类而存在,也就是说删除 category 不能影响主类(简单说就是不能在主类中引入 category 头文件);
- 不能因为在 category 中需要使用成员变量或属性,而将其添加到主类头文件中,此时可以通过 associated object实现;
- 不能在 category 中重写父类方法,当在主类与 category 中定义了同一个方法时,category 中的方法会覆盖主类的方法。比如:在主类与 category 中都定义了
dealloc方法,则主类中的dealloc方法将被覆盖。尤其是在没有源码的三方库中,更加不能这样做。
避免使用宏
首先需要表明的是,能够使用宏而不是硬编码,是一件值得鼓励的事情。 但宏的缺点也常常遭到诟病,主要有:非强类型、只是预编译期的文本替换,因为宏定义没有加括号而引发的错误屡见不鲜。 绝大多数情况下,宏都可以用 const 或者子方法代替。看个有意思的问题,下面这个宏定义有问题吗:



拒绝 warning
warning 代表程序存在病态,虽然有些 warning 看上去无关紧要,但 warning 一旦多起来,一些重要的 warning 可能也隐藏其中,难以发现。
对于那些真的觉得无关紧要的 warning,可以通过#pragma clang diagnostic ignored将其隐藏(当然并不推荐这么做)。
小结
在如今的移动互联网时代,很多项目都是被需求推着往前走,都在追求敏捷开发、快速迭代、小步快跑,对代码质量有所忽视。 俗话说:『磨刀不误砍柴工』,在动手之前多一点思考,在开发过程中少一点任性,就能写出质量更高的代码。 总之,高质量说来容易,做到难。不仅要有丰富的实战经验,扎实的功底,更要有一颗执著的心!
